



知识图谱(knowledge graphs, KG)将知识以三元组的结构进行组织和存储。如今以YAGO、DBpedia和Freebase为代表的各种大规模知识图谱的出现极大地促进了知识图谱在各种Web应用程序中的运用, 也极大地加速了搜索引擎[1]、推荐系统[2]和问答系统[3]等下游应用的发展。
从零开始构建一个大规模的知识图谱是一项非常复杂而且富有挑战性的任务, 这不仅涉及到顶层的本体构建和设计, 还要进行大量的实体、关系和属性抽取任务[4]。此外, 单个知识图谱往往规模较小, 很难满足不同任务的需要。所以将多个较小规模的知识图谱融合成一个规模较大的知识图谱的知识融合技术就显得十分重要。知识融合面临的一个巨大难题是不同知识图谱通常有着数目庞大的等价实体, 而这些实体往往有着不同的表示形式, 尤其是知识融合往往涉及到多语言的知识图谱, 因此直接通过实体名来寻找相同含义的实体存在很大的局限性, 于是实体对齐技术应运而生。该技术能够判断来自不同知识图谱的实体对是否代表真实世界的同一个对象[5]。
基于嵌入的实体对齐技术是如今实体对齐研究的主要方向。该方法试图将知识图谱的实体表示嵌入到低维向量空间中, 并通过计算向量间的距离来判别是否为对齐的实体对。TransE[6]作为著名的嵌入模型曾广泛应用在实体对齐任务中, 并在此基础上衍生出了性能更优的MTransE[7]和IPTransE[8]等实体对齐模型。随着图神经网络(graph neural network, GNN)引入实体对齐领域, 尤其是图卷积网络(graph convolutional networks, GCN)[9]的出现, 其聚合邻域信息的能力十分契合实体对齐任务, 并能迅速提升实体对齐的效果。以GCN-Align[10]为首的基于GCN的模型成为了现在主流的实体对齐模型。随着预训练模型的兴起, RDGCN[11]、NMN[12]、RNM[13]等通过加入预训练的词向量初始化模型将实体名的语义信息嵌入到实体表示, 极大提升了GCN模型对齐的表现。
知识图谱中的三元组可以分为2类, 关系三元组和属性三元组(实体-属性-属性值), 表 1展示了部分属性三元组的示例。目前主流方法较少研究属性的嵌入表示, 相比实体的数量, 属性的数量往往庞大得多。以DBP15K中文数据集为例, 该数据集的关系三元组数和属性三元组数分别为153 929和379 684, 属性三元组的数量几乎是关系三元组的2.5倍。不仅如此, 考虑到不同的实体即使是相同的属性也存在不同的属性值, 所以属性值的数量也会远远大于实体的数量, 这无疑大幅度增加模型的训练量和训练的资源消耗。
针对上述属性嵌入的困难, 本文根据实体和属性的三元组结构关系设计了一个属性权重更新网络(attribute weight updating network, AWUN), 主要创新如下:
1) 采用了一种特殊的属性嵌入方法: 利用实体嵌入近似构造属性嵌入。这种属性嵌入方法在考虑实体和属性之间结构信息的同时避免了大量属性值的嵌入。
2) 采用了一个属性权重更新模块: 在训练中不断更新每个实体各个属性权重; 通过一个属性聚合方法将属性嵌入聚合到实体嵌入中, 强化了实体嵌入的表示。
通过与11个基线模型进行对比以及消融实验的分析, 证明本文提出的AWUN模型利用属性信息显著地提升了实体对齐的效果。
1 相关工作 1.1 基于嵌入的实体对齐近年来, 基于嵌入的方法已经成为实体对齐的主要方法。该方法将不同知识图谱的实体嵌入到相同的低维空间中, 通过计算不同的实体嵌入之间的距离衡量对齐程度。其中TransE模型[6]是基于嵌入的对齐模型代表之一, TransE的理念为通过头实体与关系的和近似等于尾实体的约束训练嵌入表示, 然而TransE在捕获复杂的关系信息时效率低下, 并且难以考虑全局信息。后续, 在TransE的基础上诞生出了JAPE[14]、IPTransE[8]、BootEA[15]等改进模型。其中JAPE模型在TransE的基础上通过使用一种skip-gram[16]机制嵌入属性信息; IPTransE采用一种基于路径的TransE模型训练知识嵌入并使用一种迭代策略扩展对齐种子; BootEA模型在平移嵌入的基础上设计了一种重复抽样算法进行对齐, 并使用约束条件减少迭代时的误差积累。
1.2 基于图卷积网络的实体对齐不同于TransE的基础框架, GCN通过邻域信息聚合的性质在实体对齐任务中展现出强大的潜能。Wang等[10]提出了实体对齐的GCN-Align模型, 通过多层GCN网络辅助训练实体的结构信息强化实体嵌入表示; 随后高速门(highway gate)[17]的引入有效控制了GCN跨层之间的噪声, 显著提升了对齐表现; RGCN[18]和RDGCN[11]模型都在GCN的基础上考虑了关系信息, 其中RDGCN利用对偶图构建关系嵌入, 使用图注意力网络(graph attention networks, GAT)[19]强化关系表示, 最后融合进实体的嵌入表示; AliNet模型[20]在GCN的基础上采用门控机制和注意机制聚合多跳邻居的信息。然而, 聚合多跳邻居也可能带来一些附加的噪声, 这可能会降低对齐的性能; NMN模型[12]在考虑AliNet的缺点后, 通过领域采样和领域聚合的方式为每个实体选择信息最丰富的邻居, 同时考虑了拓扑结构和邻域相似度估计2个实体的相似度, 带来了优秀的对齐效果。
此外, 国内外的研究也聚焦于属性信息对实体对齐的帮助, Attr模型[21]使用改进的TransE来训练属性的嵌入表示; MultiKE模型[22]从多视图角度考虑实体对齐, 使用卷积神经网络训练属性和属性值; HMAN模型[23]使用带高速门和全连接层的前馈神经网络嵌入属性信息。
不同于这些属性嵌入模型, 本文通过实体嵌入和实体属性结构关系构建属性嵌入, 因此对数据集中属性值的缺损并不敏感, 也不需要额外训练属性嵌入, 即使是缺少属性值数据的DBP15K数据集也有良好的对齐表现。
2 属性权重更新网络AWUN模型的整体框架如图 1所示, 首先利用结构嵌入聚合实体的结构信息并利用实体的结构嵌入构造属性嵌入, 再利用属性权重更新模块更新属性的权重, 最后通过属性聚合模块将属性嵌入聚合到实体嵌入完成实体对齐。

|
| 图 1 AWUN模型的整体框架 |
本文使用基于预训练的GloVe词向量[24]进行实体的初始嵌入。GloVe通过一种无监督学习算法从大量语料库中训练单词的嵌入表示。GloVe公开了多种不同训练集训练的词向量嵌入表示,可以作为其他领域的预训练模型使用。首先将DBP15K数据集中的多语言实体名转换成英语实体名, 再利用基于开放语料库预训练的GloVe词向量对实体进行初始嵌入。利用预训练的词向量初始化实体保留了实体名的语义信息, 实验证明该方法高效提升了实体对齐的准确率[25]。
2.2 结构嵌入本文采用带高速门的双层GCN网络嵌入实体的结构信息。GCN网络可以聚合实体之间的领域结构信息, 而高速门可以控制跨层间积累的噪声[26]。对于每一层GCN的输入X(l), 其输出X(l+1)可以表示为
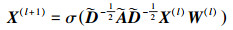
|
(1) |
式中:X(l)是本层实体嵌入的输入; 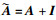


属性嵌入相比实体嵌入存在以下难点:
1) 属性数量庞大, 训练难度较大;
2) 数据集中属性多数采用英语缩写命名, 难以像实体嵌入一样直接用词向量初始化。
考虑到上述问题,本文未选择使用GloVe词向量对属性进行初始嵌入,参考RDGCN[11]的关系嵌入构造方法, 利用实体嵌入构造属性嵌入, 同时也可以免去单独训练属性嵌入带来的训练成本。具体而言, 对于实体e, 其第i个属性的嵌入表示xia为

|
(2) |
式中:Hi表示拥有属性i的所有实体集合;xke表示实体集合Hi中的第k个实体的嵌入表示。
2.4 属性权重更新模块在现实的知识图谱中每个实体往往都有着大量的属性, 然而不同属性对实体对齐的贡献各不相同。为了能够给予每个属性一个合适的权重, 本文采用了一个属性权重更新模块, 该模块会给每个属性一个初始权重, 并在每轮训练中利用图注意力网络更新属性的权重。
根据属性的共同实体数量以及属性出现次数, 构建出第i个实体ei的第j个属性的权重wij初始化公式为
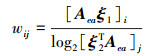
|
(3) |
式中:Aea表示[实体-属性]邻接矩阵;ξ1, ξ2分别表示维度不同且元素全为1的列向量。
本文使用GAT的注意力机制更新属性的权重。对于实体ei的第j个属性,每轮训练后的权重w′ij更新为
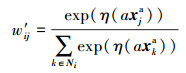
|
(4) |
式中:xja表示实体ei的第j个属性嵌入; η表示激活函数LeakyReLU; Ni表示实体ei所有邻居属性的集合; a表示输出为标量的全连接层。
2.5 属性聚合模块获得了属性的嵌入表示和权重信息后, 本文利用一个特殊的GCN聚合每个实体的属性嵌入信息。对于每个实体ei, 聚合属性信息的第l层实体嵌入输出Xe(l)可以表示为
|
(5) |
式中:Aea是[实体-属性]邻接矩阵; Dea是Aea的度矩阵; σ是激活函数ReLU; Xa(l)是本层属性嵌入的输入;W(l)是一个可训练参数矩阵, 其形状取决于本层输入向量和输出向量的维度。
为了同时包含实体的结构嵌入信息和属性嵌入信息, 对结构嵌入和属性聚合模块的GCN输出进行拼接操作
|
(6) |
式中:X′是拼接后的最终嵌入表示; Xe_s是实体的结构嵌入; Xe_a是属性聚合模块GCN的嵌入输出; θ是权重参数; “‖”表示向量的拼接操作。
2.6 实体对齐训练为了训练出适合的实体嵌入表示, 将数据集中已经预先对齐的实体对(对齐种子)选出一部分作为训练集, 采用基于边界的损失函数L作为训练目标, 如(7)式所示
|
(7) |
式中:γ是边界参数; E+表示对齐种子集合; E-表示对齐负例集合; ‖x, y‖表示向量x和y之间的距离。
因为基于嵌入的实体对齐将对齐任务转换为寻找距离最近实体的任务, 对于待对齐的知识图谱G1和G2, 在实体对齐过程中计算每个实体与其候选对齐实体之间的距离, 将距离最近的2个来自不同知识图谱的实体对ei和ej作为对齐的实体对{(ei, ej) ei∈G1, ej∈G2}。
3 实验 3.1 数据集和实验设置为了评估模型的性能,并与其他实体对齐模型进行对比, 实验的数据集采用DBP15K的3个跨语言数据集(ZH-EN、JA-EN、FR-EN), 这3个数据集节选自大规模知识图谱DBpedia, 包括英语、汉语、日语和法语的版本。每个数据集提供已对齐的15 000个跨语言实体对作为实验的训练集和测试集, 且已被广泛用于实体对齐。本文采用的DBP15K数据集的详细信息如表 2所示。
| 数据集 | 语言 | 实体数 | 关系数 | 属性数 | 关系三元组数 | 属性三元组数 |
| DBP15K(ZH-EN) | 汉语 英语 |
66 469 98 125 |
2 830 2 317 |
8 113 7 173 |
153 929 237 674 |
379 684 567 755 |
| DBP15K(JA-EN) | 日语 英语 |
65 744 95 680 |
2 043 2 096 |
5 882 6 066 |
164 373 233 319 |
354 619 497 230 |
| DBP15K(FR-EN) | 法语 英语 |
66 858 105 889 |
1 379 2 209 |
4 547 6 422 |
192 191 278 590 |
528 665 576 543 |
本文提出的AWUN模型采用深度学习框架TensorFlow构建并在Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz CPU和Nvidia Tesla T4 GPU上训练。为了与其他模型进行对比, 本文采取的训练集和测试集划分与先前的研究保持一致, 表 3提供了AWUN模型的详细超参数。
| 超参数 | 参数值 |
| 实体嵌入维度 | 300 |
| 属性聚合维度 | 400 |
| 属性选取数目 | 2 000 |
| 最大训练轮数 | 300 |
| 对齐种子比例/% | 30 |
| 聚合参数θ | 0.2 |
| 边界参数γ | 1.0 |
| 训练优化器 | Adam |
| 学习率 | 0.001 |
本文采用Hits@k和MRR作为实体对齐效果的评价指标。其中评价指标Hits@k衡量在前k个候选实体列表中存在正确的对齐实体比例, Hits@k越高, 表示模型对齐的效果越好。按照惯例, 本文k取值1和10。MRR是平均倒数排名, MRR越高, 结果越优。
为了体现AWUN模型的对齐效果, 本文选择了几种有竞争力的实体对齐模型作为基线, 包括3种基于TransE[6]的模型: MTransE[27]、IPTransE[8]和BootEA; 4种基于GCN的模型: GCN-Align[10]、MuGNN[28]、AliNet[20]和非迭代的MRAEA[29]; 1种尾对齐模型DAT[30]; 3种基于GloVe初始化的GCN模型: RDGCN[11]、HGCN[31]和NMN[12]。
3.3 实验结果表 4显示了不同模型在DBP15K的3个跨语言数据集上的实体对齐效果。评价指标Hits@1直接反映了对齐的准确性, 因此相比评价指标Hits@10更能体现模型实体对齐的性能。
| 模型 | DBP15K(ZH-EN) | DBP15K(JA-EN) | DBP15K(FR-EN) | ||||||||
| Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | |||
| MTransE | 0.308 | 0.614 | 0.364 | 0.279 | 0.575 | 0.349 | 0.244 | 0.556 | 0.335 | ||
| IPTransE | 0.406 | 0.735 | 0.516 | 0.367 | 0.693 | 0.474 | 0.333 | 0.685 | 0.451 | ||
| BootEA | 0.629 | 0.848 | 0.703 | 0.622 | 0.854 | 0.701 | 0.653 | 0.874 | 0.731 | ||
| DAT | 0.545 | 0.649 | 0.580 | 0.588 | 0.664 | 0.620 | 0.643 | 0.680 | 0.660 | ||
| GCN-Align | 0.413 | 0.744 | 0.549 | 0.399 | 0.745 | 0.546 | 0.373 | 0.745 | 0.532 | ||
| MuGNN | 0.494 | 0.844 | 0.611 | 0.501 | 0.857 | 0.621 | 0.495 | 0.870 | 0.621 | ||
| AliNet | 0.539 | 0.826 | 0.628 | 0.549 | 0.831 | 0.645 | 0.552 | 0.852 | 0.657 | ||
| MRAEA | 0.635 | 0.882 | 0.729 | 0.636 | 0.887 | 0.731 | 0.666 | 0.912 | 0.764 | ||
| RDGCN | 0.708 | 0.846 | 0.746 | 0.767 | 0.895 | 0.812 | 0.886 | 0.957 | 0.911 | ||
| HGCN | 0.720 | 0.857 | 0.768 | 0.766 | 0.897 | 0.813 | 0.892 | 0.961 | 0.917 | ||
| NMN | 0.733 | 0.869 | 0.781 | 0.785 | 0.912 | 0.827 | 0.902 | 0.967 | 0.924 | ||
| AWUN | 0.751 | 0.883 | 0.796 | 0.805 | 0.924 | 0.848 | 0.915 | 0.974 | 0.938 | ||
实验结果表明, 本文提出的AWUN模型在DBP15K的3个数据集上对齐效果都明显优于其他的基线模型, 与NMN模型相比对齐效果也有一定提升。具体来说, 在上述所有基于TransE的模型中, BootEA有着最佳的对齐效果, 因为其采用了一种引导策略,通过迭代扩展对齐的种子, 这表明迭代策略可以明显提升实体对齐效果。对于不使用词向量初始化的GCN模型, MRAEA优于其他模型, 这表明该模型能够有效地捕获关系和复杂图中的隐藏语义, 对提升实体对齐效果有一定的积极作用。在3种基于词向量初始化的GCN模型中, NMN表现最好, 其优势可能来自它的邻域匹配模块。本文提出的AWUN与上述表现最好的基线模型NMN相比, Hits@1在3个数据集中分别提升了1.8%, 2%和1.3%;MRR也分别提升了1.5%, 2.1%和1.4%。这证实了属性权重更新模块可以有效提高实体对齐性能。最后, 从图 2的种子敏感度分析可以看出, AWUN在不同的训练集数量上都能保持对齐效果的平稳, 即使是10%划分的训练集上依然有不错的表现, 体现了模型较强的鲁棒性和稳定性。

|
| 图 2 不同对齐种子比例对实体对齐的影响 |
为了评估AWUM的各个模块有效性, 本文在AWUM上构建了几个消融实验, 其中AWUN(-a)表示AWUN模型去除所有属性信息相关的模块, 此时AWUN(-a)相当于一个带高速门的双层GCN网络; AWUN(-w)表示AWUN模型去除属性权重更新模块, 此时模型将以相同的权重考虑所有属性嵌入信息。
从表 5结果可以看出, AWUN(-a)的对齐效果和AWUN(-w)相比有着显著的下降, 这证明属性信息能为实体对齐提供十分积极的帮助。此外, 增加了属性权重更新模块的AWUN在AWUN(-w)的基础上对齐表现有了更进一步提升, 在原有的基础上Hits@1指标分别继续提升1.9%, 1.3%和1.0%, 这表明实体的不同属性信息对实体对齐的贡献各不相同, 合适的属性权重能提升实体对齐的性能。
| 模型 | DBP15K(ZH-EN) | DBP15K(JA-EN) | DBP15K(FR-EN) | ||||||||
| Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | Hits@1 | Hits@10 | MRR | |||
| AWUN(-a) | 0.708 | 0.841 | 0.757 | 0.773 | 0.893 | 0.816 | 0.897 | 0.962 | 0.920 | ||
| AWUN(-w) | 0.732 | 0.862 | 0.780 | 0.792 | 0.909 | 0.833 | 0.905 | 0.964 | 0.928 | ||
| AWUN | 0.751 | 0.883 | 0.796 | 0.805 | 0.924 | 0.848 | 0.915 | 0.974 | 0.938 | ||
提出了一种基于属性权重更新网络的跨语言实体对齐模型AWUN。该模型一方面利用实体嵌入构建属性嵌入, 避免了属性嵌入的单独训练; 另一方面, 通过使用一种基于图注意力网络的方法为每个实体的属性构建合适的属性权重, 根据权重值将属性嵌入聚合到实体嵌入中。在DBP15K的3个跨语言数据集上进行实验, 并与11种较先进的基线模型进行了比较。实验结果表明, AWUN取得了最佳的实体对齐效果。后续将尝试研究更高效的属性嵌入以及更合适的属性聚合方法, 进一步优化实体对齐的表现。
| [1] | XIONG C, POWER R, CALLAN J. Explicit semantic ranking for academic search via knowledge graph embedding[C]//Proceedings of the International Conference on World Wide Web, Perth, 2017: 1271-1279 |
| [2] | CAO Y, WANG X, HE X, et al. Unifying knowledge graph learning and recommendation: towards a better understanding of user preferences[C]//Proceedings of the 28th International Conference on World Wide Web, San Francisco, 2019: 151-161 |
| [3] | HUANG X, ZHANG J, LI D, et al. Knowledge graph embedding based question answering[C]//Proceedings of the 12th ACM International Conference on Web Search and Data Mining, Melbourne, 2019: 105-113 |
| [4] |
徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J]. 电子科技大学学报, 2016, 45(4): 589-606.
XU Zenglin, SHENG Yongpan, HE Lirong, et al. Review on knowledge graph techniques[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589-606. (in Chinese) |
| [5] |
庄严, 李国良, 冯建华. 知识库实体对齐技术综述[J]. 计算机研究与发展, 2016, 53(1): 165-192.
ZHUANG Yan, LI Guoliang, FENG Jianhua. A survey on entity alignment of knowledge base[J]. Journal of Computer Research and Development, 2016, 53(1): 165-192. (in Chinese) |
| [6] | BORDES A, USUNIER N, GARCIADURAN A, et al. Translating embeddings for modeling multi-relational data[J]. Advances in Neural Information Processing Systems, 2013, 26(1): 2787-2795. |
| [7] | CHEN M, TIAN Y, YANG M, et al. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment[C]//Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, 2017: 1511-1517 |
| [8] | ZHU H, XIE R, LIU Z, et al. Iterative entity alignment via joint knowledge embeddings[C]//Proceedings of the Twenty-sixth International Joint Conference on Artificial Intelligence, Melbourne, 2017: 4258-4264 |
| [9] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[C]//Proceedings of International Conference on Learning Representations, Toulon, 2017: 1-14 |
| [10] | WANG Z, LV Q, LAN X, et al. Cross-lingual knowledge graph alignment via graph convolutional networks[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, 2018: 349-357 |
| [11] | WU Y, LIU X, FENG Y, et al. Relation-aware entity alignment for heterogeneous knowledge graphs [C]//Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, 2019: 5278-5284 |
| [12] | WU Y, LIU X, FENG Y, et al. Neighborhood matching network for entity alignment[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, 2020: 6477-6487 |
| [13] | ZHU Y, LIU H, WU Z, et al. Relation-aware neighborhood matching model for entity alignment[C]//Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, 2021: 4749-4756 |
| [14] | SUN Z, HU W, LI C. Cross-lingual entity alignment via joint attribute preserving embedding[C]//Proceedings of the 16th International Semantic Web Conference, Cham, 2017: 628-644 |
| [15] | SUN Z, HU W, ZHANG Q, et al. Bootstrapping entity alignment with knowledge graph embedding[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, 2018: 4396-4402 |
| [16] | MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26(1): 3111-3119. |
| [17] | SRIVASTAVA R K, GREFF K, SCHMIDHUBER J. Training very deep networks[J]. Advances in Neural Information Processing Systems, 2015, 28(1): 2377-2385. |
| [18] | SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks[C]//European Semantic Web Conference, Cham, 2018: 593-607 |
| [19] | VELIKOVI P, CUCURULL G, CASANOVA A, et al. Graph attention networks[C]//International Conference of Learning Representation, Vancouver, 2018: 1-12 |
| [20] | SUN Z, WANG C, HU W, et al. Knowledge graph alignment network with gated multi-hop neighborhood aggregation[C]//Proceedings of AAAI Conference on Artificial Intelligence, Palo Alto, 2020: 222-229 |
| [21] | TRISEDYA B D, QI J, ZHANG R. Entity alignment between knowledge graphs using attribute embeddings[C]//Proceedings of the 2019 AAAI Conference on Artificial Intelligence, Honolulu, 2019: 297-304 |
| [22] | ZHANG Q, SUN Z, HU W, et al. Multi-view knowledge graph embedding for entity alignment[C]//The 28th International Joint Conference on Artificial Intelligence, Macao, 2019: 5429-5435 |
| [23] | YANG H W, ZOU Y, SHI P, et al. Aligning cross-lingual entities with multi-aspect information[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, 2019: 4431-4441 |
| [24] | PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, 2014: 1532-1543 |
| [25] | XU K, WANG L, YU M, et al. Cross-lingual knowledge graph alignment via graph matching neural network[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Firenze, 2019: 3156-3161 |
| [26] | RAHIMI A, COHN T, BALDWIN T. Semi-supervised user geolocation via graph convolutional networks[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics, Melbourne, 2018: 2009-2019 |
| [27] | CHEN M, TIAN Y, YANG M, et al. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment[C]//Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, 2017: 1511-1517 |
| [28] | CAO Y, LIU Z, LI C, et al. Multi-channel graph neural network for entity alignment[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Firenze, 2019: 1452-1461 |
| [29] | MAO X, WANG W, XU H, et al. MRAEA: an efficient and robust entity alignment approach for cross-lingual knowledge graph[C]//Proceedings of the 13th ACM International Conference on Web Search and Data Mining, Houston, 2020: 420-428 |
| [30] | ZENG W, ZHAO X, WANG W, et al. Degree-aware alignment for entities in tail[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi'an, 2020: 811-820 |
| [31] | WU Y, LIU X, FENG Y, et al. Jointly learning entity and relation representations for entity alignment[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing, Hong Kong, 2019: 240-249 |
