


2. 国防大学 联合作战学院, 北京 100192
决策是一个基于决策者认知、偏好从多个方案中确定最终方案的过程。随着问题研究的不断深入, 决策中的不确定性因素越来越多, 面向精确数据的数学模型渐渐无法满足决策的需求, 基于这种背景, 针对不确定性数据的决策问题研究成为现代决策理论发展的重要内容。
Zadeh[1]于1965年首次提出模糊集的概念, 通过模糊数表征专家的评估值, 解决了决策信息的模糊表达问题。随后, Torra[2]又提出犹豫模糊集的概念, 它允许隶属度可以是多个不同的值, 但犹豫模糊集将每一个隶属度的概率看作是相同的, 无法将专家的偏好信息表达出来。
为了弥补上述缺陷, 朱斌[3]将概率信息应用到犹豫模糊集中, 提出了概率犹豫模糊集(probability hesitant fuzzy set, PHFS)的概念。随后, Zhang等[4]又通过减弱概率信息需要满足的条件, 改进了PHFS的定义。得益于对概率信息的有效应用, 以及完善的数学表现形式, PHFS得到了学者的广泛关注, 也在集成算子、偏好关系理论以及决策方法等方面取得了一系列成果。其中, 在集成算子的研究中, 具有代表性的有归一化集成算子[4]、基于Einstein运算的集成算子[5]以及优先权集成算子[6]等。此外, 概率犹豫模糊偏好关系也有着较大的应用前景, Zhou等[7]提出了预期一致性指标用于评估概率犹豫模糊偏好关系的一致性程度; Li等[8]先后基于概率犹豫模糊偏好关系的加性一致性和Hausdorff距离, 提出了建立群体内部共识的算法, 并且在可乘传递性的基础上提出了概率犹豫积性偏好关系[9]。He等[10]将参考理想方法与PHFS相结合, 提出了3种决策方法来解决多属性决策问题。此外, 相关学者在概率犹豫模糊聚类方法[11]、区间概率犹豫模糊集[12]以及概率对偶犹豫模糊集[13]等领域也做了相关研究, 为概率犹豫模糊决策理论做了重要补充。
在PHFS的研究中, 距离测度是研究人员十分感兴趣的一个领域, 但是这方面的研究并不多。其中, Gao等[14]研究了概率犹豫模糊环境下的应急决策问题, 首次定义了概率犹豫模糊数(probability hesitant fuzzy element, PHFE)的汉明距离; Su等[15]研究了基于距离的PHFS熵测度, 并提出了传统的汉明距离与欧式距离; 方冰等[16]又在此基础上提出了改进的新型距离测度, 并对其有效性和合理性进行了数学证明。
事实上, 现有PHFS的距离测度大多是在犹豫模糊集基础上做简单推广, 并没有深入研究其内部规律。现有距离测度的问题主要体现在3个方面: 一是元素个数不同时, 需要通过一定的规则进行延拓补值, 这也导致了误差的引入; 二是PHFE的元素多是按照数值大小顺序重排; 三是距离测度计算时, 对隶属度和概率两者的考虑较为简单, 仅是对其进行某种组合以建立两者之间的联系。事实上, 概率犹豫模糊距离测度的定义要更为复杂, 需要考虑的因素更多。
为了解决现有概率犹豫模糊距离测度的不足, 本文定义了聚集性、离散性、模糊性和一致性4种特征, 并基于这4种特征提出一种新的综合特征距离测度, 很好地克服了传统距离测度的顺序重排和隶属度个数要求等限制条件。
本文首先介绍了PHFS的基本概念, 通过分析现有概率犹豫模糊比较法则的不足, 给出一种更为完善的比较法则, 之后分析了当前的概率犹豫模糊距离测度的缺陷, 并提出了新的综合距离测度, 然后给出了熵权法的属性权重确定方法以及基于TODIM的多属性决策方法, 最后通过仿真实例分析, 验证了本文方法的合理性和有效性。
1 概率犹豫模糊集本节简要介绍PHFS的基本概念。
定义1[17] 给定任意非空集合X, PHFS H定义为集合X到区间[0, 1]上的一个概率分布函数映射, 其数学表达式为
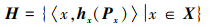
|
(1) |
式中:h(x)表示x属于某集合E的隶属度集合, 取值为[0, 1]上的子集; Px为h(x)中元素对应的概率解释, 同样为[0, 1]上的子集。hx(Px)为PHFE, 简写为h(P), 其数学表达式为
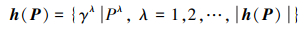
|
(2) |
式中:|h(P)|表示h(P)中元素的数量; 隶属度γλ表示x∈X属于PHFS H的可能性; Pλ表示γλ对应的概率, 且满足
本节主要分析现有概率犹豫模糊比较法则的不足, 并给出一种更为完善的比较法则。
2.1 传统概率犹豫模糊比较法则定义2 给定任意PHFE h(P)={γλ Pλ, λ=1, 2, …, |h(P)|}, 其得分函数[18]定义为
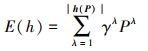
|
(3) |
在得分函数基础上, 离散函数[18]定义为
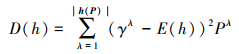
|
(4) |
则对于任意2个PHFEs h1和h2, 传统比较法则描述如下:
1) 如果E(h1)>E(h2), 则h1>h2;
2) 如果E(h1)=E(h2), 则进一步比较离散函数:
如果D(h1)>D(h2), 则h1<h2;
如果D(h1)=D(h2), 则h1=h2。
然而上述概率犹豫模糊比较法则存在一定的局限, 当两PHFE的得分函数与离散函数都相等时, 便无法对其进行比较, 通过例1进行说明。
例1 考虑最简单的情况, 给定两PHFE
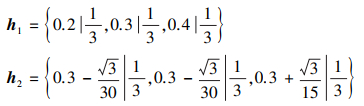
|
计算其得分函数和离散函数分别为
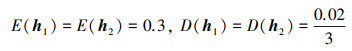
|
此时, 根据上述比较法则进行比较, 会得到h1=h2的结论, 显然不合理。
上述分析表明, 仅根据得分函数和离散函数并不能很好地解决PHFE的比较问题, 因此需要对现有的比较法则进行改进。
2.2 改进概率犹豫模糊比较法则实际上, PHFE中隶属度本身包含认知信息, 当隶属度为0.5时, 认为其模糊和不确定性最大, 此时, 决策者对方案最不确定; 当隶属度特别小或特别大时, 决策者对方案的判决都很确定。因此可以根据隶属度与0.5的接近程度来定义隶属度的模糊度, 将其纳入新的比较法则。
定义3 给定任意PHFE h(P)={γλ|Pλ, λ=1, 2, …, |h(P)|}, 则隶属度γλ的模糊度定义为
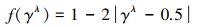
|
(5) |
于是可以得到h(P)中全部隶属度的模糊度, 实际上便得到了一个新的PHFE h(f)
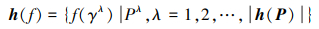
|
(6) |
容易得到, PHFE h(f)中的隶属度为h(P)中对应隶属度的模糊度。分别定义h(f)的得分函数和离散函数
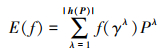
|
(7) |
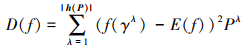
|
(8) |
根据模糊度定义可知, h(P)中γλ的模糊度越大, 则γλ描述的信息越不确定, 此时对应的PHFE应该越小, 这与客观认知相符。因此可以在得分函数、离散函数的基础上, 附加模糊度的概念, 定义新的比较法则, 给定任意2个PHFEs h1和h2, 其模糊度对应的PHFEs为h(f1)和h(f2), 则新的比较法则描述为:
1) 如果E(h1)>E(h2), 则h1>h2;
2) 如果E(h1)=E(h2), 则进一步比较离散函数:
如果D(h1)>D(h2), 则h1<h2;
如果D(h1)=D(h2), 进一步比较模糊度的得分函数;
3) 如果E(f1)>E(f2), 则h1<h2;
如果E(f1)=E(f2), 进一步比较模糊度的离散函数:
4) 如果D(f1)>D(f2), 则h1>h2;
如果D(f1)=D(f2), 则h1=h2。
3 概率犹豫模糊距离测度 3.1 传统概率犹豫模糊距离测度定义4 记PHFE h1, h2, d(h1, h2)为h1, h2之间的距离测度, 需要满足以下公理性条件[14]:
1) 非负性: d(h1, h2)≥0;
2) 交换性: d(h1, h2)=d(h2, h1);
3) 反身性: d(h1, h2)=0⇔h1=h2。
同时, 根据文献[14-15]可知, PHFE间距离计算的前提是元素个数相等, 当不满足这一前提时, 需要通过一定手段对元素个数较少的PHFE进行扩充, 如根据某种风险规则重复添加隶属度最大或者隶属度最小的元素, 并令其概率为0, 这也是大部分文献采用的方法[16]。
定义5 [15]给定任意两PHFE h1(p1) = {γ1λ|P1λ}和h2(p2)={γ2λ|P2λ}, 假设其元素个数均为l, 传统汉明(Hamming)距离定义为
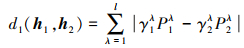
|
(9) |
传统欧式(Euclidean)距离定义为
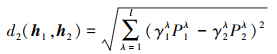
|
(10) |
定义6 文献[16]在上述距离测度的基础上进行改进, 定义了一种改进的汉明距离
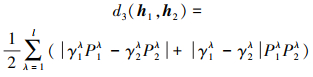
|
(11) |
相应的, 改进的欧式距离定义为

|
(12) |
但以上2种改进的距离测度都存在相同缺陷, 即要求PHFE的元素个数必须相等, 否则无法适用, 若不满足, 便需要通过一定方法进行元素的延拓补全, 这也导致了人为误差的引入。因此, 需要对现有的概率犹豫模糊距离测度做出改进。
3.2 新型概率犹豫模糊距离测度通过分析可知, 现有概率犹豫模糊距离测度的限制主要为2个方面: ①参与距离计算的PHFEs的元素个数必须相等; ② PHFE中的元素需按照隶属度大小重新排列, 隶属度相同的情况下, 按照概率值大小排列。这2个条件, 不仅人为引入了误差, 也限制了距离测度的应用范围和场景。因此, 本节通过定义新的概率犹豫模糊距离, 消除上述限制条件, 从而达到扩展距离测度应用范围的目的。
3.2.1 基于距离矩阵的PHFE距离测度本节通过引入距离矩阵构造新的距离测度, 其中, 距离矩阵中的元素由PHFE间的隶属度距离对构成。
定义7 记h1, h2为任意两PHFE, 两者元素个数分别为|h1|, |h2|, 则h1和h2之间的距离矩阵定义为
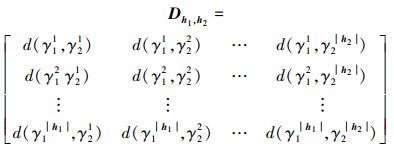
|
(13) |
式中, d(γ1i, γ2j)表示h1中第i个隶属度与h2中第j个隶属度的距离对, 根据(9)式的思路将其定义为
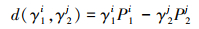
|
(14) |
则基于距离矩阵的距离测度可通过矩阵中元素的均值定义, 具体表达式为
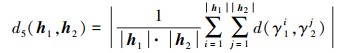
|
(15) |
分析(15)式可知, 参与距离计算的PHFEs的元素个数|h1|, |h2|不需要相等, 元素顺序也不需要降序排列。因此, 距离矩阵的引入很好地解决了现有距离测度的制约条件, 完全保留了PHFE的原始信息, 避免了人为误差的引入。
然而, 对新的距离测度需满足的三要素进行证明后发现, 本节基于距离矩阵的距离测度不满足反身性条件, 通过例2进行说明。
例2 分别采用文献[15]中的距离测度d1, d2, 文献[16]中的距离测度d3, d4, 以及本节基于距离矩阵的距离测度d5, 对若干个典型PHFE的距离进行计算, 不同测度的计算结果如表 1所示。
| 比较对象 | d1 | d2 | d3 | d4 | d5 |
| h1, h2 | 0 | 0 | 0.031 | 0.056 | 0 |
| h1, h3 | 1 | 0.707 | 0.595 | 0.543 | 0 |
| h1, h4 | 0.1 | 0.083 | 0.050 | 0.058 | 0.030 |
| h1, h5 | 0.2 | 0.165 | 0.100 | 0.117 | 0.060 |
| h1, h6 | 0.117 |
表中:
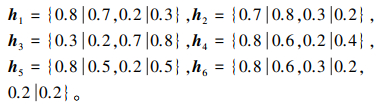
|
分析表 1, 可以得出以下结论:
1) d1~d4均无法度量h1与h6间的距离, 且根据d5(h1, h6)=0.117, 表明本节基于距离矩阵的距离测度d5解决了PHFE间元素个数不同条件下的距离计算问题;
2) 根据d5(h1, h2)=d5(h1, h3), 表明新的距离测度下元素是否进行顺序重排对计算结果没有影响;
3) d5(h1, h2)=0这一反例表明距离测度d5不满足上述证明过程中的反身性, 因此仍然存在一定的不足。
经过上述分析, 本节基于距离矩阵的距离测度虽然较好地解决了现有距离测度的限制, 但仍存在一定缺陷。同时现有距离测度在一定程度上均属于均值距离, 衡量的是PHFE的部分特征, 因此, 为了完善本节的距离测度, 还需要综合考虑其他特征参数。
3.2.2 PHFE综合特征距离根据上节可知, 基于距离矩阵的距离测度仅仅衡量了PHFE的部分特征, 为了进一步完善距离测度, 本节定义了4种PHFE特征: 聚集性、离散性、模糊性和一致性, 并基于以上4种特征定义新的PHFE距离测度。其中, 聚集性通过基于距离矩阵的距离测度表征, 离散性通过离散函数表征, 模糊性通过模糊度表征, 一致性与元素数量有关。
在仅考虑PHFE元素个数的前提下, 元素个数越少, 表明专家进行判断时, 观点越一致, 即不确定性越小。当元素个数为1时, 一致程度最大; 随着个数增加, 一致性程度逐渐降低。
因此, 将PHFE h的一致性定义为
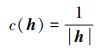
|
(16) |
式中, |h|表示PHFE h中的元素数量。
根据4种PHFE特征分别给出4种概率犹豫模糊特征距离的定义。
定义8 给定任意两PHFEs h1={γ1λ|P1λ}和h2={γ2λ|P2λ}, 元素个数分别为|h1|, |h2|, 且允许|h1|≠ |h2|成立, 分别定义h1, h2间的聚集距离、离散距离、模糊距离和一致距离为:
1) 聚集距离
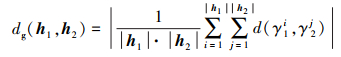
|
(17) |
2) 离散距离
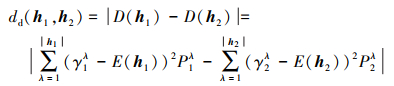
|
(18) |
3) 模糊距离

|
(19) |
4) 一致距离
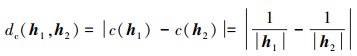
|
(20) |
式中:E(h1), E(h2)表示h1, h2的得分函数; f(γ1λ), f(γ2λ)分别表示h1, h2中隶属度对应的模糊度, 根据(5)式计算。
基于以上4种特征距离, 定义新的PHFE广义综合特征距离为
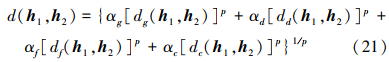
|
(21) |
式中, αg, αd, αf, αc为4种特征的权重, 满足αg+αd+αf+αc=1。
广义综合特征距离可以理解为一种广义闵式距离, 当p=1或2时, 分别转化为广义曼哈顿距离和广义欧式距离。
可以发现, 本节基于特征参数的综合距离克服了此前概率犹豫模糊距离中元素个数相等和降序重排的限制, 并且只有当全部特征距离都等于0时, 才可以得到两者相等的结论, 可以看作一种全距离。
3.2.3 PHFS综合特征距离在PHFE综合特征距离的基础上, 本节基于广义加权平均(GWA)算子给出PHFS综合特征距离的计算方法。
定义9 给定论域X={x1, x2, …, xn}, X上任意两PHFS A={<xk, hA (Pxk) >|xk∈X, k=1, 2, …, n}和B={<xk, hB (Pxk) >|xk∈X, k=1, 2, …, n}, 对应PHFE分别为hA (Pxk)={γAλ|PAλ, λ=1, …, hA(Pxk)|}和hB(Pxk)={γBλ|PBλ, λ=1, …, |hB(Pxk)|}, 假设X上各元素的权重为ω=(ω1, ω2, …, ωn)T, 则定义PHFSs A, B之间的广义加权平均距离为
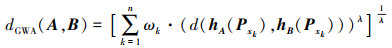
|
(22) |
式中, d(hA(Pxk), hB(Pxk))根据PHFE综合特征距离计算, dGWA(A, B)根据λ取值的不同有多种形式:
若λ=1, 得到加权平均(WA-based)距离
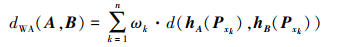
|
(23) |
若λ=2, 得到加权平方平均(WQA-based)距离
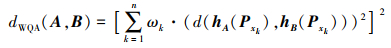
|
(24) |
若λ=-1, 得到加权调和平均(WHA-based)距离
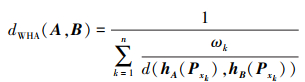
|
(25) |
基于以上, 便实现了PHFS综合特征距离的构造, 其基本流程如图 1所示。

|
| 图 1 概率犹豫模糊综合特征距离构造流程 |
属性权重是决策的重要内容, 熵可以度量信息的不确定性, 属性的熵值越小, 表明该属性提供的信息量越大, 在评价中所起的作用也越大, 相应的权重也越大。因此, 本文通过熵权法[19]来计算属性的客观权重, 具体描述如下:
假设有m种方案Ai(i=1, 2, …, m), 每种方案有n种属性Cj(j=1, 2, …, n), 对应属性权重为ω=(ω1, ω2, …, ωn)T, 且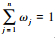
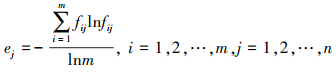
|
(26) |
式中,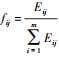
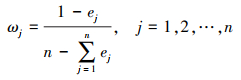
|
(27) |
由于本文主要对PHFS的距离测度进行研究分析, 并未对多属性决策方法进行深入研究, 因此, 仅在传统TODIM方法[20-21]的基础上, 基于本文所提出的综合特征距离, 提出一种概率犹豫模糊环境下的多属性决策模型, 具体步骤描述如下。
已知决策矩阵H=[hi(Cj)]m×n, 相关描述同第4节中一致。
步骤1 计算各属性下不同方案之间的两两比较关系, 得到比较矩阵Φj=[Φikj]m×m, Φikj的计算方法为:
若Cj为效益型, 则
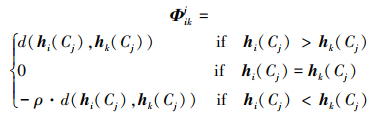
|
(28) |
若Cj为成本型, 则
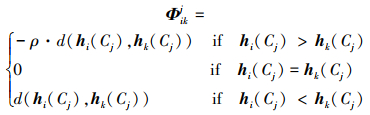
|
(29) |
式中:ρ为损失衰退参数, 用于模拟决策者心理, ρ≥1, 其取值是前景理论的体现, PHFE的比较和距离计算分别采用本文新的比较法则和PHFE综合特征距离。
步骤2 根据熵权法计算属性客观权重ω。
步骤3 集成各属性下的比较矩阵得到综合比较矩阵Φ=[Φik]m×m, Φik的数学表达式为
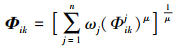
|
(30) |
式中, μ为集成参数, 一般取值为1, 得到加权平均(WA-based)比较矩阵。
步骤4 计算各方案的全局比较值ηi。
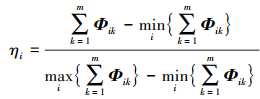
|
(31) |
步骤5 根据全局比较值对各方案进行排序, 即全局比较值最大的方案为最优方案。
6 实例分析 6.1 实例为了便于对比分析, 采用文献[22]中的实例对本文方法进行验证。
现有3位专家di(i=1, 2, 3)对5种汽车品牌(别克(x1)、丰田(x2)、福特(x3)、奥迪(x4)和特斯拉(x5))的安全性进行评估, 专家权重为(0.4, 0.4, 0.2), 通过制动系统a1、防抱死系统a2、稳定系统a3、辅助约束系统a4和车身材料a5进行评估, 5种属性均为效益型, 评估值通过PHFE表示。
参数设置: 聚集性、离散性、模糊性和一致性的权重分别为(0.4, 0.2, 0.2, 0.2);综合特征距离的特征集成参数λ=1, 即采用加权平均距离; 综合比较矩阵中的集成参数μ=1, 即采用加权平均比较矩阵; 衰退损失参数ρ=1。3位专家的评估结果分别见表 2~4。
| 品牌 | a1 | a2 | a3 | a4 | a5 |
| x1 | {0.6|0.25, 0.7|0.5, 0.8|0.25} | {0.5|0.6, 0.6|0.4} | {0.6|0.8, 0.7|0.2} | {0.3|0.4, 0.4|0.6} | {0.6|0.3, 0.7|0.3, 0.8|0.4} |
| x2 | {0.5|0.5, 0.6|0.5} | {0.4|0.3, 0.5|0.3, 0.6|0.4} | {0.5|0.2, 0.6|0.3, 0.7|0.5} | {0.6|0.6, 0.7|0.2} | {0.7|0.5, 0.8|0.5} |
| x3 | {0.8|0.5, 0.85|0.3, 0.9|0.2} | {0.3|0.2, 0.4|0.4, 0.5|0.4} | {0.5|0.2, 0.6|0.8} | {0.5|0.4, 0.6|0.6} | {0.6|0.3, 0.7|0.7} |
| x4 | {0.8|0.5, 0.85|0.3, 0.9|0.2} | {0.7|0.6, 0.8|0.2} | {0.6|0.4, 0.7|0.3, 0.8|0.3} | {0.5|0.5, 0.6|0.5} | {0.7|0.7, 0.8|0.3} |
| x5 | {0.65|0.5, 0.75|0.5} | {0.5|0.5, 0.6|0.5} | {0.7|0.3, 0.8|0.7} | {0.5|0.3, 0.6|0.3, 0.7|0.4} | {0.7|0.2, 0.8|0.2, 0.9|0.4} |
| 品牌 | a1 | a2 | a3 | a4 | a5 |
| x1 | {0.5|0.5, 0.7|0.5} | {0.7|0.7, 0.8|0.2, 0.9|0.1} | {0.4|0.3, 0.6|0.5} | {0.5|0.3, 0.6|0.4, 0.7|0.3} | {0.7|0.4, 0.8|0.6} |
| x2 | {0.5|0.4, 0.6|0.6} | {0.6|0.7, 0.7|0.3} | {0.6|0.3, 0.7|0.4, 0.8|0.3} | {0.6|0.5, 0.7|0.5} | {0.5|0.7, 0.6|0.2, 0.8|0.1} |
| x3 | {0.5|0.2, 0.6|0.3, 0.7|0.5} | {0.7|0.6, 0.8|0.2} | {0.3|0.4, 0.5|0.6} | {0.6|0.5, 0.7|0.2, 0.8|0.3} | {0.6|0.5, 0.7|0.5} |
| x4 | {0.7|0.4, 0.8|0.4} | {0.6|0.5, 0.7|0.1, 0.8|0.4} | {0.7|0.5, 0.8|0.3, 0.9|0.2} | {0.5|0.4, 0.6|0.6} | {0.7|0.2, 0.8|0.6} |
| x5 | {0.6|0.5, 0.7|0.4, 0.8|0.1} | {0.6|0.4, 0.7|0.6} | {0.4|0.5, 0.5|0.5} | {0.7|0.4, 0.8|0.4} | {0.6|0.2, 0.7|0.4, 0.8|0.4} |
| 品牌 | a1 | a2 | a3 | a4 | a5 |
| x1 | {0.6|0.3, 0.7|0.5, 0.8|0.2} | {0.6|0.4, 0.7|0.4} | {0.7|0.6, 0.8|0.4} | {0.65|0.4, 0.7|0.2, 0.75|0.4} | {0.6|0.2, 0.7|0.8} |
| x2 | {0.6|0.5, 0.7|0.3} | {0.5|0.3, 0.6|0.4, 0.7|0.3} | {0.5|0.3, 0.6|0.7} | {0.6|0.8, 0.8|0.2} | {0.55|0.4, 0.6|0.3, 0.65|0.3} |
| x3 | {0.5|0.3, 0.6|0.7} | {0.5|0.5, 0.7|0.5} | {0.6|0.5, 0.7|0.3, 0.8|0.2} | {0.6|0.2, 0.7|0.4, 0.8|0.4} | {0.7|0.4, 0.8|0.4} |
| x4 | {0.5|0.3, 0.6|0.4, 0.7|0.3} | {0.5|0.3, 0.6|0.3, 0.7|0.4} | {0.7|0.2, 0.8|0.6} | {0.6|0.4, 0.7|0.6} | {0.7|0.6, 0.8|0.4} |
| x5 | {0.7|0.5, 0.8|0.5} | {0.6|0.6, 0.7|0.4} | {0.5|0.2, 0.6|0.4, 0.7|0.4} | {0.7|0.8, 0.8|0.2} | {0.6|0.3, 0.7|0.7} |
步骤1 根据文献[23]的集成方法计算PHFS中各隶属度的总概率值, 得到综合评估信息如表 5所示。
| 品牌 | a1 | a2 | a3 | a4 | a5 |
| x1 | {0.5|0.2, 0.6|0.16, 0.7|0.5, 0.8|0.14} | {0.5|0.24, 0.6|0.24, 0.7|0.36, 0.8|0.08, 0.9|0.04} | {0.4|0.12, 0.6|0.52, 0.7|0.2, 0.8|0.08} | {0.3|0.16, 0.4|0.24, 0.5|0.12, 0.6|0.16, 0.65|0.08, 0.7|0.16, 0.75|0.08} | {0.6|0.16, 0.7|0.44, 0.8|0.4} |
| x2 | {0.5|0.36, 0.6|0.54, 0.7|0.06} | {0.4|0.12, 0.5|0.18, 0.6|0.52, 0.7|0.18} | {0.5|0.14, 0.6|0.38, 0.75|0.36, 0.8|0.12} | {0.6|0.6, 0.7|0.28, 0.8|0.04} | {0.5|0.28, 0.55|0.08, 0.6|0.14, 0.65|0.06, 0.7|0.2, 0.8|0.24} |
| x3 | {0.5|0.14, 0.6|0.26, 0.7|0.2, 0.8|0.2, 0.85|0.12, 0.9|0.08} | {0.3|0.08, 0.4|0.16, 0.5|0.26, 0.7|0.34, 0.8|0.08} | {0.3|0.16, 0.5|0.32, 0.6|0.42, 0.7|0.06, 0.8|0.04} | {0.5|0.16, 0.6|0.48, 0.7|0.16, 0.8|0.2} | {0.6|0.32, 0.7|0.56, 0.8|0.08} |
| x4 | {0.5|0.06, 0.6|0.08, 0.7|0.22, 0.8|0.36, 0.85|0.12, 0.9|0.08} | {0.5|0.06, 0.6|0.26, 0.7|0.36, 0.8|0.24} | {0.6|0.16, 0.7|0.36, 0.8|0.36, 0.9|0.08} | {0.5|0.36, 0.6|0.52, 0.7|0.12} | {0.7|0.48, 0.8|0.44} |
| x5 | {0.6|0.2, 0.65|0.2, 0.7|0.26, 0.75|0.2, 0.8|0.14} | {0.5|0.2, 0.6|0.48, 0.7|0.32} | {0.4|0.2, 0.5|0.24, 0.6|0.08, 0.7|0.2, 0.8|0.28} | {0.5|0.12, 0.6|0.12, 0.7|0.48, 0.8|0.2} | {0.6|0.14, 0.7|0.38, 0.8|0.24, 0.9|0.16} |
步骤2 计算属性权重。
| 品牌 | a1 | a2 | a3 | a4 | a5 |
| x1 | 0.658 | 0.616 | 0.564 | 0.524 | 0.724 |
| x2 | 0.546 | 0.576 | 0.664 | 0.588 | 0.639 |
| x3 | 0.700 | 0.520 | 0.534 | 0.640 | 0.648 |
| x4 | 0.694 | 0.630 | 0.708 | 0.576 | 0.688 |
| x5 | 0.694 | 0.612 | 0.612 | 0.628 | 0.686 |
根据(26)式计算各属性的熵值
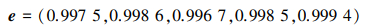
|
根据(27)式计算各属性的权重
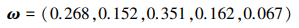
|
步骤3 计算综合比较矩阵。
以属性a1下x1, x2的评估信息为例进行说明
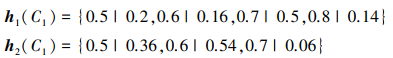
|
则根据新的比较法则
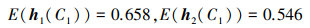
|
有h1(C1)>h2(C1), 则Φ121=d(h1(C1), h2(C1))。
分别计算得到dg=0.017 5, dd=0.005 5, df=0.144, dc=0.083 3。
则有
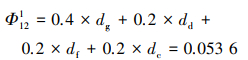
|
重复上述过程, 分别计算得到各属性下的比较矩阵为

|
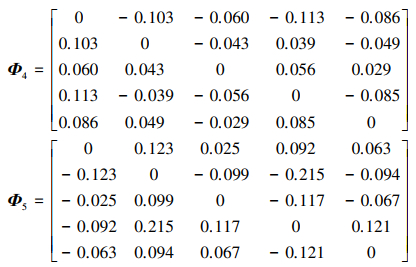
|
根据(30)式计算得到综合比较矩阵为
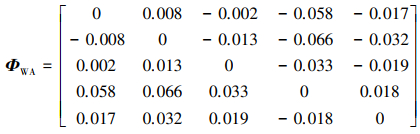
|
步骤4 计算各品牌汽车的全局比较值ηi。
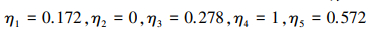
|
步骤5 根据全局比较值进行排序, 得到
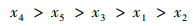
|
因此, 判定x4为安全性最好的汽车品牌, 判定结果与文献[22]中保持一致, 证明了本文算法的有效性。
6.2 参数敏感性分析本节分别对综合特征距离的特征参数权重、衰退损失参数以及距离集成参数进行敏感性分析。
6.2.1 特征参数权重敏感性为验证本文综合距离测度的有效性和全面性, 对距离测度的特征参数权重进行敏感性分析, 分别依次设置4种特征参数权重为0.7, 其余特征权重均为0.1, 对全局比较值进行求解, 得到的对比结果如图 2所示。

|
| 图 2 不同特征参数权重下综合距离评估结果 |
由图 2可知, 不同权重下的排序结果均为x4≻x5≻x3≻x2≻x1, 这表明本文综合距离测度具有一定的稳定性, 但对特征参数的侧重不同, 得到的结果也存在差别。如当一致距离的权重为0.7时, x3的全局比较值与其他3种权重下的全局比较值差距较大, 这是由于一致距离仅考虑评估信息中的元素个数这一参数, 没有涉及具体的数值大小, 因此在实际应用中应当仅作为辅助决策的工具, 而不是主要评估依据; 当模糊距离的权重为0.7时, x1与x3的全局比较值差距极小, 几乎难以区分, 且与聚集距离权重为0.7时计算得到的全局比较值差距更大。
上述分析可知, 本文综合特征距离具备一定的稳定性, 且对特征参数具有一定的敏感性, 在实际应用中应合理分配权重, 一般地, 将聚集距离和离散距离作为主要评估依据, 模糊距离和一致距离作为重要指标进行辅助决策。
6.2.2 衰退损失参数敏感性衰退损失参数ρ是前景理论的体现, 相比传统决策方法,能够充分考虑决策者规避损失的主管心理, 能够产生更有说服力的结果。因此, 有必要研究各汽车品牌在不同的衰退损失参数下的排序情况。由于本文采用熵权法计算属性权重, 没有考虑主观因素, 为使结论更让人信服, 本节参考了文献[4]的属性权重结果, 分别在2种属性权重下, 对衰退损失参数的敏感性进行分析, 图 3~4分别为不同属性权重下的全局比较值随ρ的变化情况。

|
| 图 3 全局比较值随衰退损失参数的变化图 |

|
| 图 4 全局比较值随衰退损失参数的变化图 |
1) ω=(0.268, 0.152, 0.351, 0.162, 0.067)
2) ω=(0.2, 0.2, 0.2, 0.2, 0.2)
分析图 3~4可知, 不同属性权重的情况下, 随着ρ逐渐增大, 排序结果未发生变化, 但呈现出随着全局比较值逐渐增大, 其他品牌与最优品牌间的差距逐渐减小的趋势。其中, 情景2)的排序结果为x4≻x5≻x1≻x3≻x2, 与情景1)排序结果不同, 这是由于不同的属性权重影响了x1与x3最终的排序结果, 同时x1与x3的全局比较值差距不断逼近0。通过上述分析, 表明本文多属性决策方法及距离测度对衰退损失参数的敏感性较低。
6.2.3 距离集成参数敏感性为研究特征距离集成参数λ的敏感性, 保持其他参数设置与6.1节中一致, 分别令λ为-1, 0, 1, 2, 构成加权调和平均距离、加权几何平均距离、加权平均距离和加权平方平均距离, 则图 5为不同集成参数下全局比较值的变化情况。

|
| 图 5 全局比较值随特征距离集成参数的变化图 |
由图 5可知, 当集成参数为0, 1, 2时, 排序结果均为x4≻x5≻x3≻x1≻x2; 但当集成参数为-1时, x2的全局比较值明显增大并超过x1, 且与x3的全局比较差值很小, 此时的排序结果变为x4≻x5≻x3≻x2≻x1。
上述分析表明, 本文的决策方法对特征距离集成参数较为敏感, 在解决问题时需要根据实际情况选择合适的特征距离集成参数, 否则可能会得到不同的判决结果。
6.3 比较分析 6.3.1 与现有距离测度对比分析为了验证本文改进距离测度的优越性, 采用6.1节中的实例, 分别采用现有距离测度, 即文献[15]中的d1, d2, 文献[16]中的d3, d4进行仿真实验, 对其排序结果进行对比分析, 仿真结果如图 6所示。

|
| 图 6 不同距离测度下的全局比较值 |
分析上图可知, 5种测度的排序结果一致, 均为x4≻x5≻x3≻x1≻x2, 但分析各品牌的全局比较值可以发现, 除x2与x4的全局比较值相同外, d1~d4的计算结果与本文距离测度结果有明显差别。如本文测度下x5的全局比较值为0.572, 而d1~d4的计算结果则更为接近, 聚集在0.85附近, x1与x3也有类似的情况。
分析原因可知, d1~d4在距离计算时, 当PHFE元素个数不等时, 采用风险规则进行扩充, 改变了数据的原始信息, 从而引入了人为误差, 而本文改进距离测度通过定义不同的特征距离, 很好地解决了这一问题, 使得最终的计算结果与现有测度有明显不同, 体现了本文改进测度的优越性。
6.3.2 与其他方法对比分析为了说明本文方法的有效性, 分别与文献[4]和文献[22]进行对比。其中, 文献[4]运用概率犹豫模糊加权平均算子(PHFWA), 同时利用PHFE得分函数进行比较分析, 属性权重为(0.2, 0.2, 0.2, 0.2, 0.2);文献[22]分别采用3种不同的对称交叉熵和总犹豫度进行决策分析, 采用基于离差最大化和广义对称交叉熵的模型求解属性权重。将上述方法与本文算法的计算结果进行比较, 如表 7所示。由表 7可知, 本文方法与其他文献的排序结果虽然存在部分差异, 但对x4和x5的决策结果一致, 即都将x4判为安全性最高的品牌。而在最差汽车品牌的选择上, 文献[22]中的3种方法均把x3判定为最差选择, 而本文的决策方法判定x2为最差汽车品牌, 这是由于文献[22]的符号距离主要是通过衡量PHFE的信息不确定度进行计算, 相比本文的综合距离测度, 并没有综合考虑元素中蕴含的其他信息, 对PHFE信息的表征不够准确。
需要说明的是, 文献[22]采用基于离差最大化和广义对称交叉熵的模型求解属性权重时,与本文的属性权重不同,供读者参考。
通过本节的仿真分析, 本文的决策方法具有以下优势: ①本文的综合特征距离测度在PHFE元素个数不等和不做顺序重排的情况下, 均可以进行距离计算, 相比传统距离测度, 避免了各种反直觉现象的发生, 同时多种特征也使得计算结果更加准确、全面; ②熵权法能够较为客观地确定属性权重, 与文献[4]相比减少了决策者的主观随意性; ③本文模型能够充分考虑决策者规避损失的心理, 更加符合决策者的实际经历, 因此能够产生更有说服力的结果。
同时本文方法也存在以下局限: 关于如何确定衰退损失参数、特征集成参数等并未深入研究, 虽然相比传统识别方法, 本方法在计算过程上更容易理解, 但计算过程仍然较为繁琐, 是否适应大规模数据背景下的计算需求还需进一步讨论。
7 结论本文对概率犹豫模糊集的距离测度进行了深入研究, 针对传统距离测度存在的缺陷, 综合考虑PHFE的聚集性、离散性、模糊性和一致性4种特征, 提出新的比较法则和距离测度, 释放了传统距离测度的元素个数和顺序重排等限制, 拓展了概率犹豫模糊距离测度的应用场景和范围, 并推广至广义综合距离测度, 然后基于TODIM方法提出了一种PHFS多属性决策方法, 通过与现有方法的分析比较, 验证了本文距离测度和决策方法的有效性和全面性。
| [1] | ZADEH L A. Fuzzy sets[J]. Information and Control, 1965, 8(3): 338-356. DOI:10.1016/S0019-9958(65)90241-X |
| [2] | TORRA V. Hesitant fuzzy sets[J]. International Journal of Intelligent Systems, 2010, 25(6): 529-539. |
| [3] |
朱斌. 基于偏好关系的决策方法及应用研究[D]. 南京: 东南大学, 2014 ZHU Bin. Decison making methods and applications based on preference relations[D]. Nanjing: Southeast University, 2014 (in Chinese) |
| [4] | ZHANG S, XU Z S, HE Y. Operations and integrations of probabilistic hesitant fuzzy information in decision making[J]. Information Fusion, 2017, 38: 1-11. DOI:10.1016/j.inffus.2017.02.001 |
| [5] | PARK J, PARK Y, SON M. Hesitant probabilistic fuzzy information aggregation using Einstein operations[J]. Information, 2018, 9(9): 226. DOI:10.3390/info9090226 |
| [6] | LI J, WANG Z X. Multi-attribute decision making based on prioritized operators under probabilistic hesitant fuzzy environments[J]. Soft Computing, 2019, 23(11): 3853-3868. DOI:10.1007/s00500-018-3047-7 |
| [7] | ZHOU W, XU Z S. Group consistency and group decision making under uncertain probabilistic hesitant fuzzy preference environment[J]. Information Sciences, 2017, 414: 276-288. DOI:10.1016/j.ins.2017.06.004 |
| [8] | LI J, WANG Z X. Consensus building for probabilistic hesitant fuzzy preference relations with expected additive consistency[J]. International Journal of Fuzzy Systems, 2018, 20(5): 1495-1510. DOI:10.1007/s40815-018-0451-1 |
| [9] | LI J, WANG J Q. Multi-criteria decision-making with probabilistic hesitant fuzzy information based on expected multiplicative consistency[J]. Neural Computing and Applications, 2019, 31(12): 8897-8915. DOI:10.1007/s00521-018-3753-1 |
| [10] | HE Y, XU Z S. Multi-attribute decision making methods based on reference ideal theory with probabilistic hesitant information[J]. Expert Systems with Applications, 2019, 118: 459-469. DOI:10.1016/j.eswa.2018.10.014 |
| [11] | WANG Z X, LI J. Correlation coefficients of probabilistic hesitant fuzzy elements and their applications to evaluation of the alternatives[J]. Symmetry, 2017, 9(11): 259. DOI:10.3390/sym9110259 |
| [12] | WU W, LI Y, NI Z, et al. Probabilistic interval-valued hesitant fuzzy information aggregation operators and their application to multi-attribute decision making[J]. Algorithms, 2018, 11(8): 120. DOI:10.3390/a11080120 |
| [13] | HAO Z N, XU Z S, ZHAO H, et al. Probabilistic dual hesitant fuzzy set and its application in risk evaluation[J]. Knowledge-Based Systems, 2017, 127: 16-28. DOI:10.1016/j.knosys.2017.02.033 |
| [14] | GAO J, XU Z S, LIAO H C. A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment[J]. International Journal of Fuzzy Systems, 2017, 19(5): 1261-1278. DOI:10.1007/s40815-017-0311-4 |
| [15] | SU Z, XU Z S, ZHAO H, et al. Entropy Measures for Probabilistic Hesitant Fuzzy Information[J]. IEEE Access, 2019, 7: 65714-65727. DOI:10.1109/ACCESS.2019.2916564 |
| [16] |
方冰, 韩冰, 闻传花. 基于新型距离测度的概率犹豫模糊多属性群决策方法[J]. 控制与决策, 2022, 37(3): 729-736.
FANG Bing, HAN Bing, WEN Chuanhua. Probabilistic hesitant fuzzy group decision-making based on new distance measure[J]. Control and Decision, 2022, 37(3): 729-736. (in Chinese) |
| [17] | XU Z S, ZHOU W. Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment[J]. Fuzzy Optimization and Decision Making, 2017, 16(4): 481-503. DOI:10.1007/s10700-016-9257-5 |
| [18] | Gao J, Xu Z, Liao H. A dynamic reference point method for emergency response under hesitant probabilistic fuzzy environment[J]. International Journal of Fuzzy Systems, 2017, 19(5): 1261-1278. DOI:10.1007/s40815-017-0311-4 |
| [19] |
邱菀华. 管理决策与应用熵学[M]. 北京: 机械工业出版社, 2002.
QIU Wanhua. Management decision and applied entropy[M]. Beijing: China Machine Press, 2002. (in Chinese) |
| [20] | ZHANG X, XU Z S. The TODIM analysis approach based on novel measured functions under hesitant fuzzy environment[J]. Knowledge-Based Systems, 2014, 61(1): 48-58. |
| [21] |
王应明, 阙翠平, 蓝以信. 基于前景理论的犹豫模糊TOPSIS多属性决策方法[J]. 控制与决策, 2017, 32(5): 864-870.
WANG Yingming, QUE Cuiping, LAN Yixin. Hesitant fuzzy TOPSIS multi-attribute decision method based on prospect theory[J]. Control and Decision, 2017, 32(5): 864-870. (in Chinese) |
| [22] |
朱峰, 徐济超, 刘玉敏, 等. 基于符号距离和交叉熵的概率犹豫模糊多属性决策方法[J]. 控制与决策, 2020, 35(8): 1977-1986.
ZHU Feng, XU Jichao, LIU Yumin, et al. Probabilistic hesitant fuzzy multi-attribute decision method based on signed distance and cross entropy[J]. Control and Decision, 2020, 35(8): 1977-1986. (in Chinese) |
| [23] |
刘玉敏, 朱峰, 靳琳琳. 基于概率犹豫模糊熵的多属性决策方法[J]. 控制与决策, 2019, 34(4): 861-870.
LIU Yumin, ZHU Feng, JIN Linlin. Multi-attribute decision-making method based on probabilistic hesitant fuzzy entropy[J]. Control and Decision, 2019, 34(4): 861-870. (in Chinese) |
2. College of Joint Operations, National Defense University, Beijing 100192, China
