



2. 虚拟现实内容制作中心, 北京 101318
人脸模型重建在计算机图形学和虚拟现实领域具有重要的理论意义和实用价值。在最近十年,人脸模型研究取得了巨大的成功,使得这项技术在影视娱乐和多媒体社交中发挥了重要的作用。纹理作为人脸模型的重要部分,可以很好地表现人脸细节特征和像素信息,增加了人脸显示的逼真程度。纹理本质上是一张记录了色彩信息的图片,像素数据存储了二维图形的颜色分布信息。对于早期的人脸纹理探索,一些研究机构使用固定环境下的3D扫描设备来捕获纹理[1]。这种大规模的人脸纹理采集和获取通常需要复杂的扫描设备和可控的光照环境要求,这在实际应用中难以实施。目前人脸信息保存最好的载体是二维图像和视频,通过这种方式更易于实现人脸图像的采集和获取。随着相机和移动设备的快速升级,人们对人脸几何模型和纹理的真实度有着更高的要求。
在三维人脸重建中,关于人脸纹理的研究侧重于通过输入源获取人脸纹理图,并通过纹理映射技术将纹理图覆盖在几何模型的表面,逐个像素地控制模型表面各定点的颜色信息。但人脸的几何结构非常特殊,将三维模型以平面纹理图的形式进行映射会破坏网格原有完整性,这种形式的纹理映射结果会产生较大的像素失真。为了解决此类问题,吴斌等将三维模型表面参数化,然后对曲面进行分割,将分割的曲面在图像的投影区域与像素区域进行联合匹配,并通过插值算法建立起参数和纹理坐标的对应关系,这种过程被称为纹理扫描法[2]。曾成强等按照像素显示的先后次序,对逐个像素可见模型的表面区域进行纹理映射,也被称为逆向纹理映射[3]。但这2种方法主要针对光滑且连续的模型曲面,不适用于生物结构特殊的人脸曲面。人脸三维模型表面由非参数化的平面组成,对此,Bier等[4]提出了一种基于中间曲面的纹理映射方法,将纹理映射的过程分为2个子步骤,建立一个光滑可参数化的曲面包围盒,并在此曲面包围盒的基础上进行原曲面替代,可以较好地解决模型表面非参数化模拟问题。此外,还有一种常用的方法是UV纹理映射,它定义了一个基于二维纹理坐标系统的UV空间,用于确定将纹理信息分配到三维网格模型的对应顶点坐标上。
另一方面,人脸在表情、姿态等特征结构上具有不确定性,直接捕获的面部照片并不能代表人脸完整的纹理信息。尤其是不同面部视角下的自遮挡问题,会导致人脸纹理存在不可见区域。基于3D Morphable Model(3DMM)的研究在解决人脸形状重建的同时也给出了人脸纹理特征分布的参数模型,通过人脸数据库中的模型特征进行拟合以获取与目标人脸近似的纹理信息。一些研究人员仔细分析了人脸纹理的分布特征,在图像补全的层面上进行工作,利用深度神经网络和无监督训练进行人脸纹理的补全。Deepak等[5]提出了一种基于面部显示内容的编码器结构,采用了像素级的对抗性重建损失进行人脸纹理的补全工作。Liu等[6]提出了一种分步卷积(PCONV)策略,使用一个仅考虑有效像素的掩模来处理不规则的纹理缺失区域。此外,还有一些方法采用基于局部和全局的人脸特征鉴别器来提高图像质量,分别应用于面部中心区域或是纹理融合区域[7-8]。
基于多视角下的人脸图像进行高分辨率和高质量的纹理生成也存在巨大的挑战,这需要复杂的面部图像捕捉系统和处理流程。一些研究团队使用固定环境下的多视图成像系统来捕捉人脸纹理图像,例如多视图DSLR捕捉系统和3D扫描系统[9-10],这些方法得到的纹理样本较为丰富,但此类人脸信息数据集不公开,限制了实际应用。同时,当人脸纹理由同一个体多个随机角度的图像(或视频)生成时,由于环境光照、表情姿态和相机参数的差别,纹理合成时会出现明显的拼接痕迹。
总结来说,在人脸纹理补全和映射方面,研究工作较多,但目前的研究方法中仍存在着诸多不足。基于图像的人脸纹理映射无法处理输入图像的非目标区域纹理缺失问题。以多视角人脸图像为输入的处理方法,得到的结果在纹理拼接区域像素差异明显。已有的纹理融合方法只考虑不同纹理图像之间的像素填充和像素平滑,无法解决模型表面纹理的连续性和一致性问题。针对这些情况,本文提出一种纹理融合和补全的新方法,针对人脸不同角度下的模型映射结果进行优化。
本文以多视角下的人脸图像为输入,利用优化的图像算法和处理框架进行人脸纹理相关的仿真研究。参照光线投射的原理,设计一种人脸网格模型的可见面判别算法,在此基础上引入一种可见性权重完成不同像面的纹理融合。其次,基于投影原理利用弱透视投影变换获得模型网格顶点在像素坐标系下的投影点坐标,并利用最近邻插值算法计算网格顶点的纹理值。最后,针对耳部区域的纹理缺失和像素模糊问题,利用基于高斯模型的肤色概率方法和纹理融合带操作对耳部纹理缺失区域进行补全和优化,最终得到完整、纹理细节逼真的人脸纹理模型结果。
1 基于人脸模型的纹理投影映射人脸纹理能够表达几何结构难以展示的像素细节,例如肤色、皱纹、妆容和细小毛发等,提高了三维人脸模型的逼真度。图像作为纹理信息的通用载体,通过三维模型的顶点坐标与人脸图像之间的映射关系,将人脸图像各像素点颜色值映射到三维模型空间,即纹理映射技术,纹理映射可以有效避免立体模型像素扭曲失真的问题。
1.1 人脸几何重建基础对于纹理的投影映射和融合补全工作,三维人脸网格模型是其应用基础和显示媒介。基于图像的人脸重建研究已取得巨大成功,3DMM方法通过人脸图像与数据库的模型特征进行拟合以获取形状和纹理信息。一些基于深度学习的方法利用深度神经网络进行人脸重建,本质上仍是基于3DMM的特征参数优化。人脸样本经PCA进行特征降维,压缩至低维空间构建人脸形状模型。根据输入人脸与3DMM模型进行参数空间的特征拟合,得到其对应的参数模型。当输入的信息较少(例如仅有单张固定角度下的人脸图像),人脸样本的先验信息影响更大,导致重建出的人脸模型更趋向于数据库中的平均人脸。对于人脸多视角输入,可以从3DMM模型的强约束中得到更多补充信息,使得参数先验的约束更加平滑,得到的人脸几何特征更准确。
本文利用人脸多视角图像对三维人脸模型的重建过程进行联合优化,从不同角度下的特征点中优化人脸的身份和表情特征参数、模型的空间姿态及对应的相机参数,得到人脸模型的最优解。
1.2 人脸模型的可见面判别当人脸模型以顶点投影的方式对应到二维平面时,模型上部分点在投影平面不可见。纹理映射仅对投影平面上的可见点有效,因此传统的纹理投影过程会丢失部分信息,导致投影具有二义性。同时,以投影平面的像素点为光线入射点的计算量大,对设备要求较高。针对这些问题,本文基于光线投射的思想设计了一种人脸模型投影的可见面判别算法,以网格模型顶点为光线入射点,优化了投影过程。由图像平面上的某一像素点出发,做该点向空间的射线,计算此射线与物体表面的所有交点,通过计算入射点与各交点之间的深度值判断物体表面的可见性,光线投射的原理如图 1所示。

|
| 图 1 光线投射原理图 |
这种方式可以有效获取三维物体对应的投影可见面。在计算射线与三角面片的交点时,采用Moller-Trumbore算法[11],通过向量与面矩阵快速得到交点与面片三角形的重心坐标。射线的参数方程可以表示为
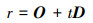
|
(1) |
式中:O是射线的起点,即网格模型的顶点;D是射线方向,即图像平面的法向量方向;t为参数。同时,三角形面片内任意一点p也可由其他3个顶点表示如下
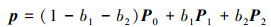
|
(2) |
式中,P0, P1, P2为模型表面三角形面片的3个顶点; b1, b2分别为P1和P2的分量系数,1-b1-b2为P0的分量系数。
令E1=P1-P0, E2=P2-P0, T=0-P0,根据克莱姆法则和矩阵运算最终可以得到
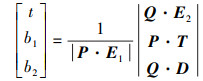
|
(3) |
式中,P=D×E2, Q=T×E1, 求解t, b1, b2的值并根据匹配的不同条件进行相交点所在平面的可见面判断。具体算法流程见表 1。
| 输入:人脸网格模型Fj |
| 输出:剔除不可见面后的人脸网格模型Fj′ |
| for 遍历顶点1→VerNum; |
| 获取顶点的坐标Ot,以图像平面法向量方向做线; |
| for遍历网格面片1→FaceNum |
| 根据当前坐标按(3)式求解对应顶点 |
| while t≥0, b1≥0, b2≥0; |
| 若b1+b2≤1 |
| 则判定射线与当前三角面片相交; |
| end while |
| 更新Ot |
| end for |
| 更新VerNum; |
| end for |
| 返回Fj并剔除不可见面片 |
在完成人脸网格模型的可见面判别后,需要将模型上的顶点投影到纹理平面,把投影点由图像平面坐标系转换到像素坐标系,从而得到对应的纹理坐标。但这种方式会出现离散取值的问题,本文根据模型中每个顶点的纹理坐标对图像平面的像素点做插值计算,获得模型顶点像素值。以图像平面邻近像素值对该网格模型顶点的像素坐标进行插值计算从而得到其对应的纹理值。
网格模型顶点坐标(xC, yC, zC)的弱透视投影为

|
(4) |
式中: f表示当前图像对应的相机焦距; (xI, yI)为经过弱透视投影变换后的二维坐标,即模型投影点坐标,其对应的纹理坐标可以表示为
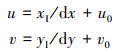
|
(5) |
u0和v0表示图像平面中心的像素坐标, dx和dy分别表示像素坐标系与图像坐标系之间的转换标量。
对于人脸模型的三角面片结构,已知三角面片中各顶点的纹理值,可以通过各顶点得到其三角形重心,并由此重心坐标进行顶点最近邻插值算法得到此三角面片的纹理值。人脸图像不同角度下的纹理投影映射结果如图 2所示。

|
| 图 2 各视角下的人脸模型投影映射 |
人脸的几何结构较为特殊,单张图像只能反映出某一特定角度下的人脸信息。对于不同角度下的人脸图像存在纹理信息的“互补”与“重叠”,常规方法的多视角纹理补全是在角度阈值上进行纹理有效区域的拼接缝合。不同视角下的人脸图像在光照环境与相机参数上存在一定的差异,上述方法容易导致纹理拼接区域出现纹理不匹配的情况(亮度差异、像素不连续)。针对此问题,本文提出一种基于可见性权重的人脸纹理融合方法,参照模型可见面的面片法向量与纹理图像平面的夹角计算可见性权重,以实现不同视角下三维人脸纹理信息融合的平滑过渡。同时,对于人脸耳部模型区域结构复杂、纹理缺失、投影效果不佳的问题,利用皮肤颜色空间的高斯模型和融合带进行耳部区域纹理优化。多视角人脸纹理融合与补全的处理流程如图 3所示。

|
| 图 3 多视角人脸纹理融合与补全流程框图 |
每个视角下的人脸图像均对应着当前视点下最佳显示区域的纹理像素信息。为了更清楚地展示角度自遮挡下人脸纹理恢复的有效区域,将不同视角下人脸图像的最佳可见区域显示在图 4中。基于此原理,本文提出了一种基于可见性权重的纹理补全方法。可见性权重与当前模型表面和纹理图像平面之间的角度有关。图 4a)是不同角度下的人脸图像,从左至右的人脸角度分别为30°, 15°, 5°(以人脸正视图为0°,向左偏转和向右偏转分别为对应正负的偏转角度),图 4b)是对应角度下人脸图像的最佳可见区域纹理。由此可见,模型可见面与纹理图像平面之间的夹角越大,则模型表面在此纹理图像上所获得的有效纹理值越小。

|
| 图 4 不同视角下人脸图像最佳可见区域的展示图 |
为了将不同角度下的人脸最佳区域纹理进行合理分配,本文根据模型表面法向量与纹理面法向量之间的夹角确定不同视角下纹理值的权重,并利用此权重计算不同角度下融合后的纹理值。对于人脸模型上的三角面片,定义一个空间法向量矩阵nFaceNorm用于存储人脸模型上的每个三角面片的法向量,将NFace记为模型的三角面片总数,IFace记为当前对应面片的索引。人脸网格模型表面三角面片的法向量计算流程如图 5所示。

|
| 图 5 人脸网格模型三角面片空间法向量的计算流程 |
对于当前网格模型的面片法向量n和对应纹理图像平面法向量nI1, nI2之间的夹角(如图 6所示),计算如下:
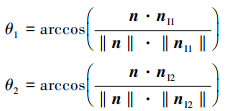
|
(6) |

|
| 图 6 网格模型面片法向量与对应纹理像面的夹角示图 |
将2个不同视角下的人脸图像纹理像面的可见性权重分别记为ω1Δp和ω2Δp,其分别表示为
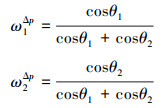
|
(7) |
可见,纹理可见性权重的大小和法向量与像面夹角之间呈反比,即夹角越大,对应的纹理可见性权重越小。加入可见性权重后,当前模型表面三角面片的顶点纹理值可以根据纹理图像中对应顶点索引处的像素点的颜色矩阵来计算,模型三角面片中顶点的最终纹理值记作Tcolor

|
(8) |
式中: T1colormatrix为像面1中对应像素点Δp的顶点颜色矩阵; T2colormatrix为像面2中对应像素点Δp的顶点颜色矩阵。融合后的人脸纹理显示参考3.2节。
3 耳部区域纹理优化对于耳部区域的纹理,主要存在2个问题: ①耳部轮廓周围一些区域会出现纹理缺失的现象;②近耳部区域会出现像素色差和纹理缝隙。针对上述问题,本文进行了耳部区域的纹理补全与优化。
3.1 耳部区域孔洞补全耳廓周围的纹理缺失现象,主要是由于三维网格模型中此区域的顶点与纹理图像中的非关联区域建立了对应关系。实际上,在三维人脸模型重建的过程中,这些位置由于立体结构复杂,模型特征不统一,导致出现网格孔洞,纹理关系错乱。耳部纹理的缺失如图 7中左图所示。

|
| 图 7 耳部纹理缺失区域补全优化后效果对比图 |
网格模型的孔洞问题,常规处理方法是利用孔洞的边界及邻域计算插值信息,进行孔洞填充。当孔洞区域偏大时,这种方法补全的效果会粗糙且平直。本文以径向基函数插值算法为基础,通过计算最近邻面片的法向量得到缺失网格的方向趋势,最后利用网格变形使修补的网格区域更加平滑。
另一方面,基于颜色空间的肤色区域检测会受到光照等外界环境因素的影响。本文在颜色空间的基础上使用一种基于高斯模型的肤色概率计算方法,在不同的颜色空间对皮肤区域的像素颜色数据进行统计,分析出皮肤的颜色值范围,并作肤色像素的判断条件。在YCbCr的颜色空间中,得到统计样本集Cb和Cr分量对应的均值μ和方差σ。对Cb和Cr分量分别构建高斯模型,对应如下:
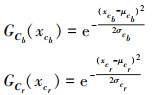
|
(9) |
式中:xcb表示像素x对应的在Cb上的分量;xcr表示像素对应的在Cr上的分量。纹理缺失区域的顶点像素P的肤色概率P(x)表示如下
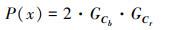
|
(10) |
通过计算像素点的肤色概率值得到连续的肤色概率信息,从而得到纹理缺失区域的皮肤颜色值。耳部区域纹理缺失区域补全后的对比如图 7所示。其中左图为补全前模型,右图为补全后模型。
3.2 耳部区域纹理优化人类耳部结构复杂独立,基于表面法向量的纹理融合方法无法适用。本节对耳部区域单独划分,并设定有效耳部融合带对各视角下纹理图像的融合权重进行重置,实现耳部区域的纹理优化。
在人脸网格模型中对耳部区域的边界进行划分,并以此边界线向外延展得到融合带。根据融合带所占模型表面网格的范围确定带宽,带宽过小会在衔接处出现色差与缝隙;带宽过大则会影响此区域可见性权重的纹理融合效果。融合带的纹理值由侧面图像和可见性纹理融合结果共同计算,对侧面视角下的图像映射结果与上节中的纹理融合权重分别设为ωe1和ωe2,融合带的顶点颜色值为对应权重下纹理图像的顶点颜色值的加权和,表示如下
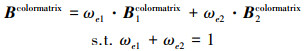
|
(11) |
Bcolormatrix表示融合带的顶点颜色矩阵,B1colormatrix为侧面视角下的图像顶点颜色矩阵,B2colormatrix为上节融合后的纹理顶点颜色矩阵。
利用泊松算法进行像素平滑,对融合带内外的像素值按照最小化泛函约束进行计算
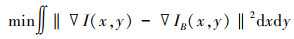
|
(12) |
式中,▽IB(x, y)和▽I(x, y)分别表示融合带与外部的纹理图像梯度。图像梯度反映了像素的细节差异和纹理变化特征,也在一定程度上影响着图像的清晰度。(12)式可以使融合带内外的图像梯度保持一致,实现融合带边界处的像素平滑过渡。
对ωe1和ωe2权重分配及融合带宽进行联合测试,获得耳部区域的纹理融合结果如图 8所示。当ωe1和ωe2取值为0.5时,对应的融合带宽为12。此时耳部区域的像素平滑自然,纹理融合效果更好。

|
| 图 8 不同权重值及带宽下的耳部纹理融合效果 |
本节针对耳部区域纹理缺失及融合效果不佳的问题做出改进。利用基于颜色空间的高斯肤色模型进行纹理像素补全;设计融合带重置纹理权重,通过最小化纹理图像梯度来平滑边界像素。最终实现耳部区域的纹理补全与优化,处理后的人脸纹理模型如图 9所示。其中,第一行是优化前的人脸纹理模型,第二行是优化后的人脸纹理模型。

|
| 图 9 纹理融合及耳部区域纹理补全优化后的效果对比 |
本文的主要工作是以多角度人脸图像为输入,进行人脸模型的纹理映射、融合与补全。纹理的投影映射以及纹理融合优化的最终显示结果都需要以三维人脸网格模型为媒介。为了创建适用于仿真的三维模型,本研究以3DMM为基础,利用FaceWareHouse人脸样本数据库为先验信息,生成各输入图像对应的三维人头脸网格模型。
仿真测试在CPU Intel 4.0 GHz,GPU NVIDIA 2080Ti,内存16G组成的系统环境中运行,开发平台为Matlab2018。
为了验证本文方法的有效性和优越性,在同样的配置环境下与OSTeC[12],SRTC-Net[13]以及商业解决方案Facegen进行对比。其中,OSTeC是一种无监督的3D人脸纹理完成方法,通过二维人脸生成器中基于可见区域的重构,在三维空间中进行转化,填充不可见的纹理区域,最后在纹理模版中进行不同角度的缝合。SRTC-Net是一个结合人脸形状重建和纹理补全的网络,通过2D图像和3D人脸模版之间的逐像素对应关系将2D图像转移到UV纹理图,然后使用图像修复网络来补全纹理图中的不可见区域。Facegen是目前应用较广的一种三维人脸模型商业解决方案,其基于3DMM原理进行人脸模型和纹理的重建。在仿真实验中,所有的测试图像均来自于H3DS[14]人脸数据集,并应用在上述几种对比方案中。为了客观地展示各方法的最终显示结果,从仿真中选取了10组测试图像,在相同的渲染条件下生成的结果如图 10所示。

|
| 图 10 纹理映射后的人脸模型结果对比 |
图 10a)为输入的人脸测试图像。图 10b)为OSTeC方法得到的结果,其只在面部区域恢复了人脸模型和纹理细节,但无法扩展到周围区域(如侧脸、额头及耳部区域)。此外,由于网格内边缘投影问题,OSTeC在嘴唇处出现了原图中不存在的纹理缝隙。图 10c)为SRTC-Net生成的结果,与OSTeC类似,生成的模型和纹理不完整;在人脸的鼻子区域出现了像素伪影,可能是UV纹理图是通过逐像素对应关系直接由二维图像转移到UV坐标中导致的。在鼻子立体度较高、网格表面法向量突变较大的情况下,此方法会导致纹理匹配不协调。图 10d)是Facegen的结果,其恢复了面部中心区域,但其他区域的纹理像素与原始输入图像差异较大,且在侧脸、额头区域有明显的纹理模糊,显示效果上有“动画脸”的特征。第五列为本文方法得到的纹理映射后的人脸模型。相比之下,本文方法恢复了完整的头面部区域纹理,并在侧面、耳部及前额毛发处的纹理信息优化较好,具有逼真的像素细节和纹理信息。
为了定量评估本文方法的有效性,在H3DS数据集上对不同方法得到的人脸纹理模型质量进行评估。利用峰值信噪比(PSNR)和结构相似性指数(SSIM)分别对人脸不同角度下的纹理映射结果进行对比,其中模型结果对比(见图 10)中的Facegen方法为商业解决方案,无法获取到有效的开源数据,因此在定量评估过程中选择UVGAN[7]作为对比方法之一,参数度量值结果如表 2所示。
| 方法 | 参数 | 人脸角度 | |||
| 0° | ±30° | ±60° | ±90° | ||
| UVGAN | PSNR | 23.9 | 22.5 | 21.1 | 20.4 |
| SSIM | 0.919 | 0.901 | 0.897 | 0.746 | |
| OSTeC | PSNR | 24.6 | 23.3 | 22.6 | 20.3 |
| SSIM | 0.928 | 0.917 | 0.845 | 0.769 | |
| SRTC-Net | PSNR | 24.1 | 23.4 | 21.5 | 19.7 |
| SSIM | 0.893 | 0.901 | 0.852 | 0.721 | |
| 本文方法 | PSNR | 24.9 | 23.7 | 22.8 | 20.8 |
| SSIM | 0.972 | 0.961 | 0.928 | 0.891 | |
分别计算了人脸正面(0°),左右侧脸(±30°, ±60°, ±90°)下的参数值,如表 2所示,本文方法在各角度下的参数值均优于其他评估方法。
5 结论本文针对三维人脸重建过程中人脸纹理存在的一些问题,提出了一种基于多视角下的人脸纹理融合与补全方法。根据纹理投影映射中可见面的面片法向量与纹理图像平面的夹角计算可见性权重,以实现不同视角下像素纹理信息的完美融合。同时,在颜色空间的基础上使用一种基于高斯模型的肤色概率计算,设定耳部融合带,实现了耳部区域的纹理补全与优化。最终生成了完整性较好、精细度较高的人脸纹理模型。与目前已有的方法相比,本文恢复的人脸纹理更加完整,纹理显示效果更好。本文工作可以应用于人脸及虚拟人研究,同时还可以为其他三维重建领域带来一些新思路。
| [1] | JAMES B, ANASTASIOS R, STEFANOS Z, et al. A 3D morphable model learnt from 10 000 faces[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2016 |
| [2] |
吴斌, 孙显, 王宏琦, 等. 一种三维建筑物模型自动纹理映射方法[J]. 遥感信息, 2017, 32(2): 5.
WU Bin, SUN Xian, WANG Hongqi, et al. A method of automatic texture mapping for 3D reconstruction model[J]. Remote Sensing Information, 2017, 32(2): 5. (in Chinese) |
| [3] |
曾成强. 纹理映射技术算法综述[J]. 甘肃科技纵横, 2014, 43(11): 40-44.
ZENG Chengqiang. A survey of texture mapping algorithms[J]. Gansu Science and Technology, 2014, 43(11): 40-44. (in Chinese) |
| [4] | BIER E A, SLOAN K R. Two-part texture mappings[J]. IEEE Computer Graphics and Application, 1986, 6(9): 40-53. DOI:10.1109/MCG.1986.276545 |
| [5] | DEEPAK P, PHILIPP K, JEFF D, et al. Context encoder: feature learning by inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016 |
| [6] | LIU Guilin, FITSUM A R, KEVIN J S, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of the European Conference on Computer Vision, 2018 |
| [7] | DENG Jiankang, CHENG Shiyang, XUE Niannan, et al. UV-GAN: adversarial facial UV map completion for pose-invariant face recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018 |
| [8] |
刘洋, 樊养余, 郭哲, 等. 单幅人脸图像的全景纹理图生成方法[J]. 中国图象图形学报, 2022, 27(2): 602-613.
LIU Yang, FAN Yangyu, GUO Zhe, et al. Solo face image-based panoramic texture map generation[J]. Journal of Image and Graphics, 2022, 27(2): 602-613. (in Chinese) |
| [9] | YAMAGUCHI S, SAITO S, NAGANO K, et al. High-fidelity facial reflectance and geometry inference from an unconstrained image[J]. ACM Transactions on Graphics, 2018, 37(4): 162. |
| [10] | LATTAS A, STYLIANOS M, GECER B, et al. AvatarMe: realistically renderable 3D facial reconstruction[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020 |
| [11] | MOLLER T, TRUMBORE B. Fast, minimum storage ray/triangle intersection[J]. Journal of Graphics Tools, 1997, 2(1): 21-28. DOI:10.1080/10867651.1997.10487468 |
| [12] | GECER B, DENG J, ZAFEIRIOS S. OSTeC: one-shot texture completion[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021 |
| [13] | ZENG X, WU Z, PENG X, et al. Joint 3D facial shape reconstruction and texture completion from a single image[J]. Computational Visual Media, 2022, 8(2): 239-256. |
| [14] | RAMON E, TRIGINER G, ESCUR J, et al. H3D-Net: Few-shot high-fidelity 3D head reconstruction[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021 |
2. Content Production Center of Virtual Reality, Beijing 101318, China
