



2. 陕西省机器人关键零部件先进制造与评估省市共建重点实验室, 陕西 宝鸡 721016;
3. 西北工业大学 机电学院, 陕西 西安 710072
随着制造企业的经营和发展, 会积累大量的制造实例, 这些实例蕴含着丰富的数据和知识资源, 反映了企业的制造能力和水平, 是企业工艺人员设计偏好和经验的关键体现。如何对这些资源进行有效的挖掘和重用, 是改善企业工艺设计水平和支持其创新的有效途径之一[1]。现实中, 要实现制造实例资源挖掘与重用, 首先要解决的问题就是确定具有较高重用价值潜力的实例资源。在众多制造实例中, 有一些机加工工艺过程具有典型性和代表性, 可称之为典型工艺路线[2-6]。与其他加工过程相比, 典型工艺路线包含了同类零件丰富的工艺设计规则和经验, 实现典型工艺路线的发现和重用具有很大的价值和意义, 可以为加工工艺规划提供更好支持。
对于典型工艺路线的发现, 当前研究主要包括以下2个方面: ①工艺过程的相似性度量是挖掘典型工艺路线的前提和基础。Liu等[2]建立了基于欧式距离的工艺路线相似性度量关系式。张辉等[3]建立了加工工艺路线的多级相似度计算模型。Kambhampati[7]开发了一种备选规划方案与目标对象间的距离计算方法。Fan等[8]定义工艺过程组成单元间的相似性以及工艺路线整体的相似性。Peng等[9]提出了一种基于改进欧氏距离公式的产品数据挖掘方法, 用于分析产品模块过程相似度。Wu等[10]基于过程构成要素的6个维度, 提出了一种评价产品制造过程相似度的客观计算方法。上述研究主要是对制造过程的全局相似性进行度量, 但对被排除在全局衡量指标之外的其他潜在相似元素却缺乏充分考虑。②除了制造过程的相似性度量之外, 机加工工艺路线的聚类分析也是实现典型工艺路线发现的另一个重要方面。在聚类分析领域, 最为经典的传统方法是K-means算法[11-12]。但是, K-means算法的一个显著缺点是必须首先指定簇的数量, 而且待聚类元素的初始位置会对聚类划分效果产生很大影响。针对K-means算法的缺点, 近年来有很多学者开始利用智能优化算法构建智能聚类模型[13-16]。基于群体智能算法的聚类分析方法一般都不会受到初始聚类条件设置的影响, 而且因为群体搜索的特性, 这一类方法往往具有较快的收敛速度和较优的全局搜索能力。
对于机加工艺路线的重用, 目前应用较为成熟的是基于实例推理(case-based reasoning, CBR) 的方法[17-19]。在基于CBR的工艺规划与重用方法中, 虽然可以将典型的工艺路线作为可重用对象, 通过推理生成新的加工方案, 但这需要大量的人机交互和反复修正, 从而降低了制造实例重用的灵活性和智能性。
本文提出了一种基于信息熵和PSO-Kmeans聚类的典型工艺路线发现与重用体系。该体系首先提出了一种基于多级最长公共子序列(longest common subsequence, LCS)信息熵的工艺路线相似性度量方法, 试图从多个层级对工艺路线间的相似度进行全面评判; 然后选择了群体智能算法中的粒子群优化算法(particle swarm optimization, PSO)对经典的K-means聚类算法进行优化改善, 建立了基于谱聚类思想和PSO-Kmeans算法的工艺路线智能聚类模型, 并进一步提取得到了各类簇中的典型工艺路线; 最后分析讨论了2种基于典型工艺路线的工艺重用途径, 尤其是重点探讨了其中基于智能优化排序的典型工艺路线间接匹配重用方法, 拓展了工艺重用的内涵并有效提升了重用灵活性。该体系为工艺过程实例的分析和重用提供了一个较为完整的思路。
1 基于多级LCS信息熵的工艺路线相似性度量方法本文使用基于信息熵的序列相似性度量方法来评价工艺路线间的相似性。与传统的序列相似性度量方法相比, 本文改善了编辑距离类方法[20-21]只重视局部字符一致性, 以及最长公共子序列方法[3, 22]过于强调序列全局相似性的缺陷。
1.1 多级LCS的获取LCS的获取是一个在两待比较序列中查找最长子序列的问题。LCS的定义如下: 若某个序列S={s1, s2, …, sr}同时是2条待比较序列M={m1, m2, …, mu}, N={n1, n2, …, nv}的子序列, 即满足(1)式; 当且仅当序列S的长度r取最大值时, 则称S为M, N的LCS。

|
(1) |
以上提取得到的是单级LCS。在提取S的过程中, 如果将S中每一个元素在M和N中的位置信息进行记录, 并对M和N中这些位置上的元素进行剔除, 就会形成2个新序列M′和N′。对M′和N′继续提取LCS, 可得到第2级最长公共子序列S′。依次类推, 直到新形成两序列不含有任何相同元素或至少一个为空, 就可得到多级LCS。
1.2 基于LCS信息熵的序列相似度评价基于信息熵的序列相似度计算是将待比较序列的LCS长度看作是一个随机事件, 当LCS长度越长时, 它对待比较序列的相似度值影响也就越大, 即可以用LCS的信息熵来评价待比较序列间的相似度。对于待比较序列M, N及其最长公共子序列S, 根据信息熵的定义可构建如(2)式所示的平均相似信息量评价函数。
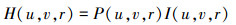
|
(2) |
式中, H(u, v, r)表示平均相似信息量评价函数, 它的本质是一个关于原序列长度的函数, 当S的长度r越大且越接近于原序列长度u和v时, 传递出的相似信息量就越大, 代表M和N间的相似度就越高; I(u, v, r)是计算信息熵时的相似信息量函数, 可通过(3)式进行计算; P(u, v, r)是计算信息熵时的概率函数, 可通过(4)式进行计算。
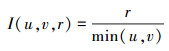
|
(3) |
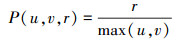
|
(4) |
对于待比较序列M和N, 可以提取它们的多级LCS并组成集合{Si i=1, 2, …, k}。其中, Si表示第i级LCS; l表示最大级数。对于每一级LCS, 都可以根据(2)式得到M和N的相似度评价结果, 则将基于各级LCS信息熵的相似度评价结果进行融合, 就可得到一个对M和N间相似性的综合评判。融合多级LCS信息熵的序列相似性评价模型见(5)式。

|
(5) |
式中:ssim(M, N)表示融合多级LCS信息熵的序列M和N的相似性评价结果; ri表示第i级LCS的长度, 即序列Si的长度。进一步, 对熵进行标准化处理, 得到基于熵的相似性度最终结果如(6)式所示。

|
(6) |
式中, Ssim(M, N)表示序列M和N的最终相似性度量值。
2 基于PSO-Kmeans聚类算法的典型工艺路线发现 2.1 基于谱聚类思想的聚类对象预处理考虑到本文的聚类对象是经过字符编码的工艺路线, 而工艺路线显示不是多维数据的表达形式, 使用经典的数据聚类算法比如K-means算法, 无法对其进行直接处理。而根据本文第1节所述, 机加工艺路线虽然不能以多维数据的形态进行表示, 但采用信息熵的方法, 可以计算其相似度。鉴于此, 有必要采用谱聚类思想先对聚类对象进行预处理, 使聚类对象依据其之间的相似度转变成能够被K-means等经典聚类算法识别的数据表达形式。应用谱聚类思想对机加工艺路线进行预处理的步骤如下:
step1 将聚类对象看作是无向权重图的节点, 两节点间的连接边全为二者根据信息熵方法计算得到的相似度, 这样就能形成一个相似度矩阵Wn×n。其中, n表示聚类对象的数量; W(i, j)表示第i条工艺路线与第j条工艺路线根据(6)式计算得到的相似度。同时, 考虑到同一节点与自身不存在连接边, 所以定义W的对角线元素均为0。
step2 按照(7)式所示, 构建对角度矩阵Dn×n
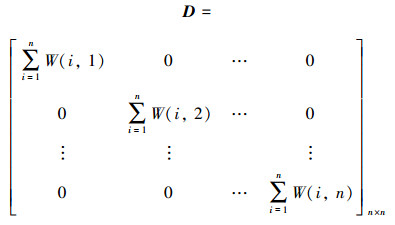
|
(7) |
step3 计算拉普拉斯矩阵(见(8)式), 并进行正交化(见(9)式)。

|
(8) |
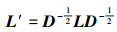
|
(9) |
step4 计算矩阵L′的特征值和特征向量, 并将特征值按照由小到大的顺序进行排列, 取前k1个特征值对应的特征向量排列成矩阵Zn×k1。
2.2 基于PSO-Kmeans算法的工艺路线聚类模型1) PSO算法的一些基本设定
在PSO-Kmeans聚类算法中, 每个粒子的位置包含k2个聚类中心(k2为设定的聚类簇数), 再考虑到聚类对象已经被转变成为一个k1维向量, 所以粒子位置就可以用k2×k1维的矩阵表示。第i个粒子的位置Xi可以表示成如下形式
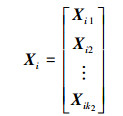
|
(10) |
式中, Xid(d=1, 2, …, k2)表示第i个粒子包含的第d个聚类中心的坐标, 它与聚类样本的维度相同, 是一个k1维向量。
本文按照PSO算法进行如下定义: 第i个粒子的运动速度为Vi, 其经历过的最好位置索引为Pi, 所有粒子经历过的最好位置索引为Pg, Vi, Pi, Pg与Xi在数据结构及表达形式上应该是一致的。关于对粒子经历过最好位置的索引, 需要依据适应度函数进行判定, 以第i个粒子的当前状态为例, 其适应度可通过(11)式进行计算。
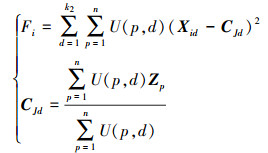
|
(11) |
式中:Fi表示Xi的当前适应度值, 值越小代表适应度越高; U是一个n×k2维的矩阵, 如果在当前聚类划分下, 第p个聚类样本属于第d个类簇, 则U(p, d)=1, 反之则为0;Zp表示矩阵Z的第p行, 是第p个聚类样本的特征向量; CJd表示在当前聚类划分下, 第d个类簇的理想中心位置, 它等于第d个类簇所属样本的均值。
在此基础上, 可构造每一代粒子的更新关系如(12)式所示。
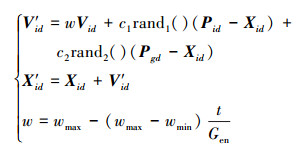
|
(12) |
式中:Pid和Pgd分别表示Pi和Pg中第d个聚类中心的坐标; Vid和V′id分别表示更新前、后的第i个粒子第d个聚类中心的运动速度; Xid和X′id分别表示更新前、后的第i个粒子第d个聚类中心的坐标; c1和c2分别表示加速常数; rand1()和rand2()分别表示2个在[0, 1]范围内变化的随机函数; Gen和t分别表示PSO算法的最大循环代数以及当前更新到的代数; w, wmax和wmin分别表示当前惯性权重、设定的最大惯性权重和最小惯性权重。w值较大时利于全局搜索, 较小时利于局部搜索, 设定惯性权重采用线性递减策略。
2) PSO-Kmeans算法的运行流程描述
聚类对象经预处理后转变成了向量的表达形式, 这样就可以用K-means算法对工艺路线进行聚类分析。本文采用PSO算法对K-means算法中的聚类中心添加扰动, 以增强其跳出局部极值和寻找最优聚类的能力, 算法具体步骤如下:
step1 初始化。设定算法运行相关参数, 并进行粒子群位置和速度的初始化。
step2 对于每个粒子, 依据(11)式计算其本代适应度值, 并与该粒子经历过最好位置Pid的适应度值进行比较。如果更好, 则更新Pid。
step3 对于每个粒子, 依据(11)式计算其本代适应度值, 并与粒子群经历过最好位置Pgd的适应度值进行比较。如果更好, 则更新Pgd。
step4 根据(12)式, 更新每一个粒子的惯性权重、速度和位置。
step5 以更新后粒子的位置为新聚类中心, 并在此基础上采用经典K-means算法[11]进行重新聚类, 生成新的聚类划分。
step6 判断PSO算法运行是否达到Gen。若是, 则中止PSO的迭代循环, 输出与Pgd对应的聚类划分结果为最终结果; 否则, 跳转step2。
2.3 典型工艺路线的发掘典型工艺路线是所属类别中工艺过程最具代表性的工艺实例, 这就决定了它和所属聚类簇中的其他工艺路线相比, 其平均相似度必然最高。因此, 可以通过计算每个聚类簇中所有数据对象与簇中其他数据对象间的平均相似度, 然后再取最大值的方式来获取典型工艺路线。某聚类簇cluster中任一工艺路线M对该簇的平均相似度计算公式为
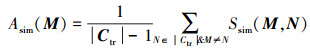
|
(13) |
式中:Asim(M)表示M相对于簇Ctr中其他元素的平均相似度值, M包含于Ctr中; |Ctr|表示簇Ctr中的元素个数。当簇Ctr中所有元素的平均相似度值都计算完毕后, 取其中最大值所对应的工艺路线为典型工艺路线。
3 基于典型工艺过程的工艺重用途径分析 3.1 典型工艺路线的直接修订重用法在已挖掘得到典型工艺路线的基础上, 可以将典型工艺中的工艺过程数据参数化, 通过修订典型工艺参数直接生成新工艺。此外, 还可以将典型工艺路线看作是某一类设计对象的典型实例, 在进行新工艺设计时, 调用典型实例并应用CBR技术, 经过工艺信息的抽取、筛选和修正, 最终辅助生成新工艺方案。
3.2 典型工艺路线的间接匹配重用法一般来说, 零件工艺过程设计的核心环节在于规划工艺路线, 而工艺路线的规划问题又可以被看作是加工操作选择问题和工序排序约束问题。对于工序排序约束问题, 需要根据事先定义的约束条件和排序目标函数来对加工操作次序的组织安排提供依据, 从而确保最终输出的工艺路线排序方案接近或满足最优解。在此过程中, 通常需要建立加工操作次序的约束条件和排序目标函数, 并调用智能优化算法来求解工艺路线决策问题。典型工艺路线的工序安排关系内含了丰富的工艺设计经验, 甚至在某种程度上可以代表同类零件加工方案中的工序位置安排关系。在运用智能优化算法不断迭代循环生成新的工序排序方案时, 可以将新方案与典型工艺路线进行相似性计算, 构建相似性越高则评价值就越小的目标函数f, 如(14)式所示。
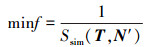
|
(14) |
式中:T表示加工对象所属类簇的典型工艺路线; N′表示优化迭代过程中每一代生成的某一工艺路线排序方案。显而易见, 当N′与T的相似度越高时, f值越小, 代表N′的适应度值越好。
4 实例分析 4.1 工艺路线的相似性度量以某企业产品的工艺实例为例加以验证。在企业实例库中, 随机选取轴类、套类、盘盖类和箱体类零件的工艺路线10条。提取这10条工艺路线的机加工序路径和几何演变序列, 见表 1。
| 编号 | 名称 | 工艺路线 |
| 1 | 传动轴 | 粗车→半精车→精车→粗铣→半精铣→精铣→磨 |
| 2 | 阶梯轴 | 粗车→半精车→精车→铣削 |
| 3 | 气缸套 | 铸造→粗车→半精车→镗削 |
| 4 | 导套 | 粗车→半精车→钻→镗削→磨 |
| 5 | 轴承盖 | 粗车→半精车→钻→车削(内圆)→铣削→钻 |
| 6 | 法兰盘 | 铸造→粗车→半精车→精车→钻→粗车(内圆)→精车(内圆) →钻 |
| 7 | 阀盖 | 铸造→粗车→半精车→精车→镗削(中心孔)→钻 |
| 8 | 闷盖 | 铸造→粗车→半精车→铣削→钻(扩) |
| 9 | 角形轴承箱 | 铸造→铣削→铣削→粗镗→精镗→铣削→钻→铣削→钻 |
| 10 | 阀体 | 铸造→铣削→铣削→铣削→粗镗→精镗→粗镗→钻(攻螺纹)→钻(攻螺纹) |
根据第1节所述, 对于任意2条待比较工艺路线, 可以提取它们的多级LCS, 并利用(6)式定义的信息熵方法度量它们之间的相似度。实例所选10条工艺路线两两间的相似性度量结果如图 1所示。由图 1可知, 排除实例自身与自身的相似度完全一致的情况外, 基本同类零件的工艺过程相似度明显大于非同类零件的工艺相似度, 这与经验认知一致。

|
| 图 1 工艺路线的相似性度量结果 |
以表 1中的10条工艺路线聚类为例进行说明。依据4.1节所示的相似度度量结果, 构建无向权重图的边权矩阵如下
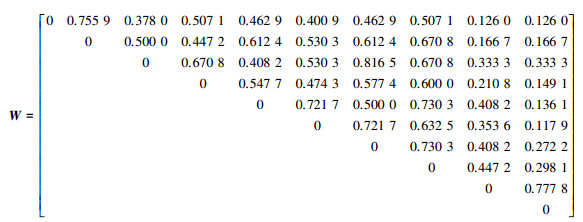
|
进一步, 按照(7)式构建对角度矩阵如下
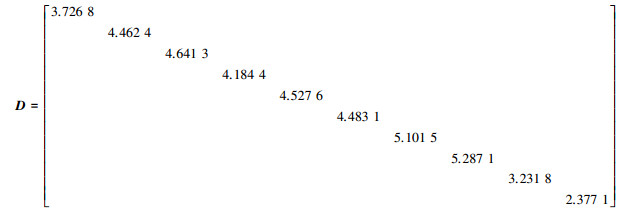
|
已知矩阵W和D, 根据(8)式计算拉普拉斯矩阵, 并按照(9)式进行正交化处理, 正交化的拉普拉斯矩阵如下

|
计算矩阵L′的特征值和特征向量, 并将特征值按照由小向大的顺序进行排列, 取前k1个特征值对应的特征向量排列成矩Z。在谱聚类方法中, k1一般与聚类簇数k2相同。而k2的取值可以依据待聚类对象间的感官差异性, 依据经验选取, 同时也可以利用肘部准则[23]进行精确选取。前者适用于小规模聚类, 后者比较适用于大规模聚类。因为实例的数据规模为10, 属于小规模聚类, 所以按照工艺人员的感官经验设定k1=k2=3。因此, 可计算得到具体的Z矩阵如下
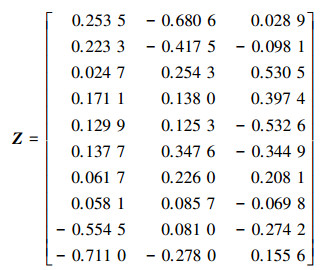
|
利用PSO-Kmeans算法对矩阵Z进行聚类划分。根据待聚类数据的规模、特点, 并参考PSO算法在常见应用中的参数设置, 设定PSO-Kmeans算法的相关参数如下: 粒子数Num=50, 最大循环代数Gen=200, 加速常数c1=c2=1.2, 最大惯性权重wmax=0.9, 最小惯性权重wmin=0.4。在此基础上, 对粒子群进行初始化, 并运行PSO-Kmeans算法, 得到聚类划分结果为: [3 3 2 2 2 2 2 2 1 1]。该结果说明实例中零件9和10的工艺路线属于类簇1;零件1和2的工艺路线属于类簇3;剩余其他6个零件的工艺路线属于类簇2。算法运行结束后的最佳适应度值为1.128 5, 其收敛过程如图 2所示。

|
| 图 2 PSO-Kmeans算法的最佳适应度值收敛曲线 |
根据PSO-Kmeans算法的聚类划分结果, 结合(13)式分别计算各个零件的工艺路线对所属类簇的Asim值, 得到如图 3所示结果。由图 3可知: 类簇1的典型工艺路线为零件9或10;类簇2的典型工艺路线为零件8;类簇3的典型工艺路线为零件1或2。

|
| 图 3 各类的平均相似度计算结果 |
本文介绍了2种典型工艺的重用途径, 其中直接修订重用是工艺人员在典型工艺路线的基础上, 通过分析、筛选和修订以辅助生成新工艺, 这种方式主要依靠工艺人员主观推动, 且实现过程较为简单, 本文不做详细论述。重点对典型工艺路线的间接匹配重用实例进行讨论。
间接匹配重用需要构建优化排序模型, 考虑到遗传算法在各类序列问题中应用地最为广泛且通用性最好, 所以本文以遗传算法为例构建优化排序模型。以图 4所示零件为例, 基于遗传算法的间接匹配重用流程如下:

|
| 图 4 示例零件 |
step1 基因编码。分析图 4所示零件, 其主要包含5个加工特征, 即左右端面、ϕ105外圆、ϕ60外圆以及ϕ40中心孔。通过工艺分析可知, 左端面的加工方法为: 粗车; 右端面的加工方法为: 粗车→精车; ϕ105外圆的加工方法为: 粗车→半精车→精车; ϕ60外圆的加工方法为: 粗车→半精车; ϕ40中心孔的加工方法为: 钻→粗车(内圆)→精车(内圆)。经过工序合并, 得到该示例零件待排序的工序数量为6个, 即粗车、半精车、精车、钻、粗车(内圆)、精车(内圆)。如果将每种工序抽象成一种基因, 则本实例的染色体由6个基因组成。
step2 初始化种群。根据染色体长度确定种群规模并进行初始化。
step3 确定目标函数。分析该零件的结构与4.2节得到的类簇2中零件最为接近, 所以选择类簇2的典型工艺路线依据(14)式构建优化目标函数。
step4 复制操作。设置复制概率, 并依据概率将上代种群中比较优秀的染色体复制到下代种群中。
step5 交叉操作。首先, 随机选择2个染色体作为父代染色体, 并在每一个父代染色体中随机产生两个交叉位置; 然后, 在其中一个父代染色体中取出交叉点之间的基因, 再将取出基因按照它们在另一父代染色体中前后关系进行重新排序; 最后再插回到两个交叉点之间以形成新的染色体。
step6 变异操作。根据预设的变异率, 选择一些染色体, 在其内部直接进行2个基因位置的交换, 从而形成新染色体。
根据图 4所示的示例零件仅包含6个待排序的工序, 依据遗传算法在实际应用中的参数设置经验, 取染色体种群规模为10, 复制概率为10%, 交叉概率为70%, 变异概率为5%, 遗传循环迭代次数为100。根据上述步骤, 对工艺路线的遗传排序过程进行编程。算法运行4次, 搜索得到的最佳染色体见表 2所示。
| 算法运行次数 | 最优染色体 | 目标函数值 |
| 1 | 粗车→半精车→精车→钻→粗车(内圆)→精车(内圆) | 1.825 7 |
| 2 | 粗车→半精车→精车→钻→精车(内圆)→粗车(内圆) | 1.825 7 |
| 3 | 粗车→半精车→钻→精车→精车(内圆)→粗车(内圆) | 1.825 7 |
| 4 | 粗车→半精车→精车→钻→粗车(内圆)→精车(内圆) | 1.825 7 |
由表 2可知, 算法运行第1次和第4次得到的结果最符合工艺设计经验认知, 是最佳排序方案。第2和第3次运行结果虽然不是最佳, 但这是因为本文没有构建排序约束规则, 仅仅只是从与典型工艺路线的相似度角度建立了评价目标函数, 而这会导致个别工序优先关系不满足工艺约束关系, 但目标函数值已经达到最佳的方案产生。对于算法运行出现了结果2或3这类情况, 工艺人员可以结合自身经验进行简单判断和调整, 或者在设计时加入排序约束规则, 使其达到最优。
5 结论本文提出的典型工艺路线发现与重用体系是智能制造背景下, 开展工艺规划业务的可行探索, 同时也更接近知识工程领域的研究重点和新兴研究方向。应用实例表明, 所提出的体系在加工工艺规划中具有一定的应用潜力。同时, 该方法作为不同加工工艺路线之间的共性知识和数据的挖掘和重用方式, 对推动智能制造背景下的工艺知识管理及其设计创新具有一定的参考价值。诚然, 该研究仍处于初级阶段, 存在一些不足和局限性。例如, 本文虽然提取了包含丰富工艺设计规则和知识、经验的典型工艺路线, 但却缺乏对这些规则和知识作进一步挖掘和建模; 机加工艺人员的主观意图是影响工艺相似性检索与重用的重要因素, 而这也没有被充分考虑。如何优化和改进制造实例挖掘和重用系统, 建立典型工艺路线的工艺规划知识模型, 实现设计者主观意图和规划知识驱动的智能重用, 将是本文后续研究的重点方向。
| [1] | LI Chunlei, LI Liang, WANG Xiaoye. Similarity measurement of the geometry variation sequence of intermediate process model[J]. Journal of Mechanical Science and Technology, 2021, 35(7): 3089-3100. DOI:10.1007/s12206-021-0631-z |
| [2] | LIU Shunuan, ZHANG Zhenming, TIAN Xitian. A typical process route discovery method based on clustering analysis[J]. International Journal of Advanced Manufacturing Technology, 2007, 35(1/2): 186-194. |
| [3] |
张辉, 裘乐淼, 张树有, 等. 基于智能聚类分析的产品典型工艺路线提取方法[J]. 计算机集成制造系统, 2013, 19(3): 490-498.
ZHANG Hui, QIU Lemiao, ZHANG Shuyou, et al. Typical product process route extraction method based on intelligent clustering analysis[J]. Computer Integrated Manufacturing Systems, 2013, 19(3): 490-498. (in Chinese) DOI:10.13196/j.cims.2013.03.44.zhangh.021 |
| [4] | ZHOU Danchen, DAI Xuan. A method for discovering typical process sequence using granular computing and similarity algorithm based on part features[J]. International Journal of Advanced Manufacturing Technology, 2015, 78(9/10/11/12): 1781-1793. |
| [5] |
李春磊, 莫蓉, 常智勇, 等. 融入多维制造信息的产品典型工艺路线发现方法[J]. 机械工程学报, 2015, 51(15): 148-157.
LI Chunlei, MO Rong, CHANG Zhiyong, et al. Multi-dimensional manufacturing information based typical product process route discovery method[J]. Journal of Mechanical Engineering, 2015, 51(15): 148-157. (in Chinese) |
| [6] | LI Chunlei, MO Rong, CHANG Zhiyong, et al. A multifactor decision-making method for process route planning[J]. International Journal of Advanced Manufacturing Technology, 2017, 90(5): 1789-1808. |
| [7] | KAMBHAMPATI Subbarao. Mapping and retrieval during plan reuse: a validation structure based approach[C]//Proceedings of AAAI Conference, 1990: 170-175 |
| [8] | FAN Wuyang, ZHANG Yongjian, WANG Lin, et al. Typical machining process mining of servo valve parts based on self-adaptive affinity propagation custering[C]//Proceedings of IEEE International Computers, Signals and Systems Conference, Dalian, China, 2018: 674-678 |
| [9] | PENG W P, ZHANG T, ZHANG Q H, et al. Mining and analyzing process similarity of product module for DPIPP based on PLM database[C]//Proceedings of IOP Conference Series: Materials Science and Engineering, Geelong, Australia, 2019: 012004 |
| [10] | WU Zhongyi, LIU Weidong, ZHENG Weijie, et al. Manufacturing process similarity measurement model and application based on process constituent elements[J]. International Journal of Production Research, 2021, 59(14): 4205-4227. DOI:10.1080/00207543.2020.1759838 |
| [11] | HARTIGAN J A, WONG M A. Algorithm as 136:a K-means clustering algorithm[J]. Journal of the Royal Statistical Society, 1979, 28(1): 100-108. |
| [12] | ZHAO Yanping, ZHOU Xiaolai. K-means clustering algorithm and its improvement research[J]. Journal of Physics Conference Series, 2021, 1(1873): 012074. |
| [13] | KHAN Zahid, FANG Sangsha, KOUBAA Anis, et al. Street-centric routing scheme using ant colony optimization-based clustering for bus-based vehicular AD-Hoc network[J]. Computers & Electrical Engineering, 2020, 86(1): 106736. |
| [14] | CUI Guorong, LI Hao, ZHANG Yachuan, et al. Weighted particle swarm clustering algorithm for self-organizing maps[J]. Journal of Quantum Computing, 2020, 2(2): 85-95. DOI:10.32604/jqc.2020.09717 |
| [15] | CHENG Fengxin, SHAO Caixing. Research on artificial fish swarm clustering algorithm in urban internet of vehicles[C]//Proceedings of IEEE International Conference on Smart Internet of Things, Beijing, China, 2020: 328-332 |
| [16] | WANG Limin, WANG Honghuan, HAN Xuming, et al. A novel adaptive density-based spatial clustering of application with noise based on bird swarm optimization algorithm[J]. Computer Communications, 2021, 174: 205-214. DOI:10.1016/j.comcom.2021.03.021 |
| [17] | CHANG H C, DONG L, LIU F X. Indexing and retrieval in machining process planning using case-based reasoning[J]. Artificial Intelligence in Engineering, 2000, 14(1): 1-13. DOI:10.1016/S0954-1810(99)00027-8 |
| [18] | JIANG Zhigang, JIANG Ya, WANG Yan, et al. A hybrid approach of rough set and case-based reasoning to remanufacturing process planning[J]. Journal of Intelligent Manufacturing, 2019, 30(1): 19-32. DOI:10.1007/s10845-016-1231-0 |
| [19] | LI Shengqiang, ZHANG Hua, YAN Wei, et al. A hybrid method of blockchain and case-based reasoning for remanufacturing process planning[J]. Journal of Intelligent Manufacturing, 2021, 32(5): 1389-1399. DOI:10.1007/s10845-020-01618-6 |
| [20] |
赵作鹏, 尹志民, 王潜平, 等. 一种改进的编辑距离算法及其在数据处理中的应用[J]. 计算机应用, 2009, 29(2): 424-426.
ZHAO Zuopeng, YIN Zhimin, WANG Qianping, et al. An improved algorithm of levenshtein distance and its application in data processing[J]. Journal of Computer Applications, 2009, 29(2): 424-426. (in Chinese) DOI:10.3969/j.issn.1001-3695.2009.02.007 |
| [21] | BERGER Bonnie, WATERMAN Michael S, YU Yunwilliam, et al. Levenshtein distance, sequence comparison and biological database search[J]. IEEE Trans on Information Theory, 2021, 67(6): 3287-3294. DOI:10.1109/TIT.2020.2996543 |
| [22] | BABA Kensuke, NAKATOH Tetsuya, MINAMI Minami. Plagiarism detection using document similarity based on distributed representation[J]. Procedia Computer Science, 2017, 111: 382-387. DOI:10.1016/j.procs.2017.06.038 |
| [23] |
施蓉鑫. 基于网络表示学习的社交网络分类系统[D]. 西安: 西安电子科技大学, 2019 SHI Rongxin. Social network classification system based on network representation learning[D]. Xi'an: Xidian University, 2019 (in Chinese) |
2. Shaanxi Key Laboratory of Advanced Manufacturing and Evaluation of Robot Key Components, Baoji 721016, China;
3. School of Mechanical Engineering, Northwestern Polytechnical University, Xi'an 710072, China
