



2. 中国人民解放军 32127部队, 辽宁 大连 116100
近年来, 红外与可见光融合技术一直是研究的热点领域。红外成像是对景物的热辐射成像, 适宜在低光照、强闪光和浓雾烟幕等极端条件下使用, 缺点是容易丢失图像细节信息, 成像不符合人眼视觉偏好等。可见光成像是对物体的反射成像, 特点是具有丰富的色彩信息和大量的纹理细节, 符合人类视觉习惯, 但成像质量受制于光照和大气条件。将红外与可见光进行融合可以充分发挥二者优势, 弥补单波段成像弊端, 特别是在军事领域, 融合图像对于分辨假目标(诱饵), 提升全天候作战能力和提高精确打击能力等有着重要意义。
在传统的红外与可见光融合算法中, 比较有代表性的有:①基于多尺度变换(multi-scale transformation, MST)理论的算法, 包括基于交叉双边滤波器算法(cross bilateral filter, CBF)[1]、各向异性融合算法(anisotropic diffusion fussion, ADF)[2]等; ②基于梯度信息理论的算法, 如梯度转移融合算法(gradient transfer fusion, GTF)[3]、基于梯度结构相似性的多模态图像融合(GSF)[4]等; ③基于显著性理论的算法, 如潜在低秩表示算法(latent low-rank representation, LatLRR)[5]等; ④基于稀疏表示的算法, 如文献[6-7]所示等; ⑤上述算法的组合算法, 如多尺度分解算法(multi-scale decomposition, MSD)[8]等。
近年来, 随着深度学习算法的不断发展, 相关成果也应用在了红外和可见光图像融合领域, 取得了较好的效果。比较有代表性的有Prabhakar等[9]提出的基于卷积神经网络(convolutional neural network, CNN)的融合方法(deepfuse), 其最终的融合图像由一个3层的CNN解码重建而来, 能够适应多种融合任务, 但网络结构比较简单, 难以充分保留源图像中的信息, 融合质量一般。Zhang等[10]提出了基于卷积神经网络的通用图像融合框架(IFCNN), 利用2个卷积层从多个输入图像中提取显著的图像特征, 根据输入图像的类型选择适当规则进行卷积特征融合, 最后使用2个卷积层重构融合特征, 并生成融合图像, 其优势在于多任务通用, 但对于特定任务融合效果并非最优。Li等[11]提出了深度学习框架算法(deep learning framework, DLF), 利用牛津大学计算机视觉组(visual geometry group, VGG)提出的VGG网络进行图像融合, 其中的VGG-19网络在深度上胜过CNN, 但融合方法相对简单, 对于图像的深度信息挖掘不够, 而且随着网络的加深, 存在网络退化的现象。随后Li等[12]又提出了一种基于残差网络(residual network, ResNet)的红外和可见光图像融合框架, 旨在改善深度网络性能, 提高对图像细节信息的利用能力。文献[13]提出了一种将多尺度局部极值分解与ResNet152残差网络相结合的融合方法, 使用多尺度局部极值分解将源图像分解为近似图像和细节图像, 采用ResNet152网络提取显著性特征, 设计了基于显著特征图和能量显著图加权的融合规则, 取得较好效果, 但算法复杂, 时间开销较大。
针对深层网络退化与红外和可见光图像融合算法中的图像信息保留不完整等问题, 进一步挖掘残差网络性能潜力和拓展应用范围, 本文提出了一种基于拆分注意力残差网络(split-attention residual network, ResNeSt)[14]的红外和可见光图像融合算法, 这是一种端到端的网络模型, 输入红外和可见光图像, 在特征提取、权重计算和图像重建等过程后, 直接输出融合后的图像。
1 基于ResNeSt的红外和可见光图像图像融合算法 1.1 ResNeSt网络框架基于ResNeSt的红外和可见光图像融合算法框架如图 1所示。将红外图像和可见光图像分别送入训练过的ResNeSt-50网络进行特征提取, 得到各自的特征图; 对特征图使用零相位分量分析(zero-phase component analysis, ZAC)方法进行数据白化, 使其投影在同一子空间; 利用L1范数获得初始权重图, 然后使用双三次插值算法进行上采样并使用softmax函数进行权重归一化, 得到和原图像大小一致的权重矩阵;运用加权平均策略, 对原始红外和可见光图像进行加权平均, 得到最终的融合图像。

|
| 图 1 算法框架 |
在深度学习中, 神经网络的深度和宽度对于性能的影响非常明显, 但网络的层级不能通过简单的堆叠进行加深, 原因是随着网络的加深会发生网络退化的现象, 为此He等[15]提出了ResNet, 通过加入跳跃连接, 保证网络加深的最坏结果也不会比原网络性能更差, 这个过程不显著增加计算负担, 且网络依然可以通过反向传播进行训练学习, ResNet模块结构见图 2。通过对残差模块的反复堆叠, 可以产生深层的、无退化现象的残差网络, 以便从输入数据中提取更为丰富的特征。ResNet解决了网络退化问题, 但通过进一步研究发现, 其性能依旧有提升的空间, ResNet主要存在的不足为: ①感受野相对有限;②缺乏跨通道的信息融合, 即缺少上下文之间的交流[16-17]。

|
| 图 2 残差模块 |
为此, 本文使用ResNeSt对输入的源图像进行特征提取, 具体结构见图 3。ResNeSt将特征图划分为K个基群(cardinal), 基群内分为更细粒度R个切片(split), 并在基群内加入拆分注意力模块(split-attention block), 结构见图 4。每个基群的特征通过上下文信息确定的权重进行组合。ResNeSt在分支网络中使用了不同尺寸的卷积核, 可提供不同尺度的感受野, 拆分注意力模块中的全局池化层能够进一步扩展感受野, Dense模块中的全连接层增加了计算的非线性, 也能更好地拟合跨通道的相关性。

|
| 图 3 拆分注意力残差模块 |

|
| 图 4 拆分注意力模块 |
ResNeSt网络结构通过拆分共有KR个切片, 输入x经过切片的处理, 进行一系列的体征提取后得到{F1, F2, …, FKR}, 最后输出特征Ui=Fi(x), i∈{1, 2, …, KR}。而后将同一基群中的特征输入拆分注意力模块, 特征求和以获得联合特征表示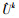
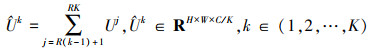
|
(1) |
式中:k表示第k个基群, j表示第j个切片。
之后, 通过跨空间维度的全局平均池化, 获得每个通道上的统计信息, 作为全局上下文信息, 记作sk, sk∈RC/K, 第c个通道上的信息可以表示为公式(2)。
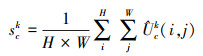
|
(2) |
而后, 再将第c个通道上同一基群中所有切片信息进行求和, 表示为Vck, 见公式(3)。
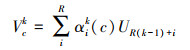
|
(3) |
式中, αik (c)表示赋值权重, 具体见公式(4)。
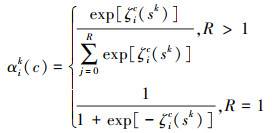
|
(4) |
如果每个基群的切片数R大于1, 使用softmax函数作为每个切片的权重, 如果R等于1, 则使用sigmoid函数作为切片的权重, ζic表示所用softmax或sigmoid函数。
最后将所有基群输出的特征进行拼接, 得到最后的特征V, V=Concat{V1, V2, …, VK}, 与ResNet中含有一个恒等映射相同, 在ResNeSt的最终输出里还包含了直接输入x, 所以最终输出可以表示为Y=V+x。
本文所用的拆分注意力残差网络ResNeSt-50在结构上与ResNet-50保持一致, 共有50层卷积, 分为16组残差结构, 见图 5。用拆分注意力残差模块替换原有残差模块, 得到ResNeSt-50网络, 网络通过ImageNet 2012数据集[18]进行预训练。

|
| 图 5 ResNet-50网络结构 |
激活函数在神经网络有效性和训练过程中起到非常重要的作用, 优化激活函数可以显著提升网络的综合性能。在ResNet-50网络的残差模块中, 前向神经网络与跳跃连接叠加后使用线性整流函数(rectified linear unit, ReLU)作为激活函数, ReLU函数见公式(5)。ReLU函数优势在于简单易用, 计算效率高, 网络收敛快, 但弊端在于当输入趋近于零或者为负时, 函数梯度为零, 网络无法反向传播, 不能继续“学习”。
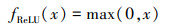
|
(5) |
在优化ReLU函数过程中, 提出了多种激活函数, 如带泄露线性整流函数(leaky ReLU)[19]、指数线性单元函数(exponential linear unit, ELU)[20]等, 文献[21]提出了一种平滑最大值单元函数(smooth maximum unit, SMU), 能够有效避免ReLU函数的缺陷, 在分类、目标检测和语义分割等应用领域被验证效果优于ReLU。SMU函数见公式(6)。
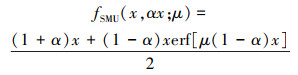
|
(6) |
其中, erf(x)为高斯误差函数, 见公式(7)
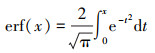
|
(7) |
式中,α, μ为超参, 本文中选取α=0.25, μ=0.5。
1.4 零相位分量分析和归一化经过ResNeSt网络模型输出的是多维特征向量, 运用ZCA方法可以将高维特征向量通过向量矩阵转换后进行去相关性操作[22], 同时, 保留主要信息, 忽略掉偏差大的信息。假设在ResNeSt网络模型提取的是m条n维的向量数据, 将数据组成n行m列的矩阵Y, ZCA白化计算过程如下:
① 计算矩阵Y的协方差矩阵Σ, 如公式(8)
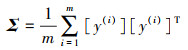
|
(8) |
② 对Σ进行奇异值分解, 得到向量U, 计算得到UTy, 即为数据经过坐标轴旋转之后得到的矩阵Z, 如公式(9)
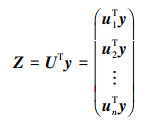
|
(9) |
③ 对Z进行PCA白化, 得到ZPCA, i
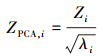
|
(10) |
式中,λi是Z协方差矩阵对角元素的值。
④ 将ZPCA, i左乘U, 得到经过白化后的特征图ZPCA。
将红外和可见光图像的特征图ZPCA通过一个大小为1×1的卷积核, 得到初始权重ωI(红外图像)和ωV(可见光图像), 这样一方面可以实现数据降维, 减少参数量, 实现对不同尺度特征进行尺寸的归一化, 另一方面也能起到跨通道特征融合的作用。
1.5 图像融合特征图归一化后运用softmax函数, 得到最终的权重图ω′I(红外图像)和ω′V(可见光图像), 如公式(11)所示
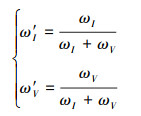
|
(11) |
归一化的特征图通过双三次插值算法缩放到与输入图像一致大小, 并按照各自权重通过加权平均算法得到最终的融合图像, 如公式(12)所示。
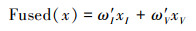
|
(12) |
在图像融合研究中, 需要使用经过配准后的红外和可见光图像作为输入数据, 但公开并配准的双光数据集选择非常有限, 本文采用TNO[23]中的40对红外和可见光图像作为主观视觉实验的输入数据, 同时, 为检验算法对于红外和彩色可见光图像的融合能力, 还选取了部分红外和彩色可见光图像对进行融合实验。在多指标客观评价中, 选取文献[24]的红外和可见光图像融合基准(visible and infrared image fusion benchmark, VIFB)中的21对图像进行测试, 其中TNO数据集示例见图 6, VIFB测试集示例见图 7。

|
| 图 6 TNO数据集示例 |

|
| 图 7 VIFB测试集示例 |
算法所用的ResNeSt-50网络已在ImageNet 2012数据集上进行了训练, 但为进一步优化网络性能, 使其在图像融合计算中更具针对性, 还对ResNeSt-50进行了迁移学习, 训练数据选自TNO数据集, 按照3∶1的比例划分训练集和测试集, 由于训练数据数量较少, 需要对训练集数据进行数据增广处理[25], 训练集中图像尺寸有280×280, 360×270, 595×328等多种, 为避免裁剪过小导致训练出的模型对于大尺寸物体识别能力不足, 统一按照180×180大小, 步长20进行裁剪, 经人工筛选后最终得到图像1 120对。迁移学习中使用Pytorch深度学习框架, 使用Adam优化器, 学习速率为2×10-4, 每批训练图像为8幅, 训练100轮。实验环境见表 1。
| 软(硬)件 | 版本(型号) |
| 操作系统 | Windows10 |
| CPU | i7-9700 3.00 GHz |
| GPU | NVIDIA 2060 SUPER |
| GPU显存 | 8 GB |
| 内存 | 16G |
| 加速环境 | CUDA v11.0、CuDNN v7.6 |
| 显卡驱动版本 | 27.21.14.6172 |
| MATLAB | R2020a |
| Pytorch版本 | 1.7 |
| Python版本 | 3.8.5 |
将训练后的网络在TNO数据集的测试图像上进行实验, 选取其中的6幅图像进行主观视觉对比, 对比对象分别是GSF算法[4]、IFCNN算法[10]、LatLRR算法[5]、VGG算法[22]、DLF算法[11]和ResNet算法[12]。输入图像和各算法融合后图像见图 8。

|
| 图 8 红外与可见光图像融合主观评价对比 |
如图 8c)所示,GSF算法在第4列中的交通标志边缘处融合失真, 出现高亮光晕, 标志牌中央的横杠几乎不可见, 第5列中对于红外图像信息利用不佳, 烟幕中的射手未能有效融合; 第6列中对于色彩的还原不准确, 整体偏灰白。如图 8d)所示,IFCNN算法在整体对比度上相对偏低, 导致纹理细节还原质量一般, 在第1列灌木丛和第3列地形起伏处尤其明显, 第5列色彩还原不够准确, 明显偏灰。如图 8e)所示,LatLRR算法处理后的图像整体过曝, 第3列上表现尤其突出, 第5列中烟幕遮挡下的射手未能有效融合显示, 丢失了红外图像的热信息; 在第6列上伪影明显, 观感不自然。如图 8f)所示,VGG算法在第5列中, 对于烟幕的融合效果不佳, 画面大面积过曝。如图 8g)~8h)所示,DLF算法和ResNet算法整体效果较好, 图像细节保留比较完整, 从第4~5列中的树木效果看, ResNet算法优于DLF算法, 其纹理更清晰, 在彩色图像融合上2幅图像均有不同程度失真, DLF算法偏灰, ResNet算法颜色较深。在图 8i)所示,本文算法在图像细节的提取和保留上表现最好, 纹理边缘清晰锐利, 在第3列中地形起伏处表现最为明显; 在对烟幕的处理上, 既保留了烟幕的轮廓, 也清晰显示了被烟幕遮挡的人; 同时, 本文算法对于色彩的还原最为准确, 相较其他算法表现优异。
2.3 多指标客观评价客观评价需要计算相关指标, 旨在定量模拟人眼视觉对图像质量的感知。相关指标种类繁多, 本文选取比较有代表性的4种: ①基于信息理论的峰值信噪比(peak signal-to-nosie ration, PSNR)[26], 其值越大说明融合图片和原始图片之间差别就越小, 细节保留越完整; ②基于结构相似性理论的结构相似性指数度量(structural similarity index measure, SSIM)[27], SSIM数值在[0, 1]之间, 数值越大代表和原来2幅图像越接近; ③基于图像特征的空间频率(spatial frequency, SF)[28], 空间频率数值越大越好, 越大图像质量越高, 观感更清晰; ④基于梯度的融合性能(gradient-based fusion performance, QAB/F)[29], QAB/F值越大图像质量越高, 保留的原始图像的信息也就越多。
在4种常用指标中, 只有SF的计算不依赖原始输入图像, 即只需计算融合图像的SF后进行比较即可, 其他3种指标都需要分别计算融合图像与原始输入的红外图像和可见光图像的指标数值, 再将2个数值以适当方式求和得到最终融合图像的指标数值, 具体实验结果如图 9所示。

|
| 图 9 7种算法的4项客观指标对比 |
实验结果表明, 在PSNR、SSIM和QAB/F 3项评价指标中, 本文提出的基于ResNeSt的融合算法表现最优, 对比其他6种算法分别至少提高了1.78%, 2.00%和3.10%, 在SF指标中排名第二, 仅落后LatLRR算法2.73%, 但对比传统ResNet算法, 也有6.52%的提升。同时, 为衡量各算法的执行效率, 还将融合图像时间开销进行了比较, 本文算法继承了传统ResNet算法执行效率高的优势, 在算法复杂度提高的情况下, 平均每对图像的融合时间相对ResNet算法小幅增加了4.5%, 全部21组融合图像客观评价结果平均值如表 2所示。
| 算法 | PSNR/dB | SSIM | SF | QAB/F | 时间/s |
| GSF | 57.971 | 0.628 | 0.047 | 0.613 | 11.276 |
| IFCNN | 58.261 | 0.622 | 0.040 | 0.553 | 33.638 |
| LatLRR | 56.133 | 0.600 | 0.050 | 0.433 | 198.515 |
| VGG | 57.926 | 0.611 | 0.044 | 0.653 | 28.679 |
| DLF | 58.443 | 0.650 | 0.025 | 0.429 | 9.977 |
| ResNet | 58.376 | 0.604 | 0.046 | 0.414 | 3.754 |
| 本文 | 59.484 | 0.663 | 0.049 | 0.673 | 3.923 |
为验证算法的合理性, 设计了3组消融实验, 实验1是使用ResNeSt网络进行特征提取, 内部使用ReLU函数作为激活函数; 实验2使用传统的ResNet网络进行特征提取, 在其内部使用SMU函数作为激活函数; 实验3使用ResNeSt网络进行特征提取, 并在内部使用SMU函数作为激活函数, 即本文完整算法。消融实验也分为主观视觉评价和多指标客观评价两部分, 选取了测试集中最具代表性的一组图像及其融合后图像进行具体说明, 消融实验图像融合结果见图 10。

|
| 图 10 消融实验示例 |
图 10a)为输入的红外图像, 图 10b)为输入的可见光图像, 图 10c)为实验1所得融合图像, 图像保留了烟幕中的战士, 能够呈现树干的纹理细节; 图 10d)为实验2所得融合图像, 也较好地完成了融合任务, 细节同样比较丰富, 战士的轮廓边缘也更锐利; 图 10e)为实验3所得融合图像, 效果最为理想, 树干的纹理清晰, 树丛细节保留更加丰富完整。表 3为消融实验4项客观评价指标对比, 4项指标中实验3均优于实验1和实验2, 表明算法的多处改进均能对最终结果产生正向优化。
| 组别 | PSNR | SSIM | SF | QAB/F |
| 实验1 | 57.891 | 0.594 | 0.043 | 0.660 |
| 实验2 | 57.599 | 0.609 | 0.043 | 0.651 |
| 实验3 | 58.476 | 0.617 | 0.045 | 0.664 |
本文充分利用深层网络对于图像特征提取的优势, 提出了基于拆分注意力残差网络的红外和可见光图像融合算法, 算法利用带有拆分注意力模块的深层残差网络分别提取红外和可见光图像多尺度特征, 通过后续的权重计算和图像重建, 得到融合后的图像。与经典的6种融合算法进行主客观对比, 本算法融合图像细节丰富, 既体现了红外图像中的热信息, 又保留了可见光图像的纹理细节, 在多项定量评价中表现突出。后续工作中, 将继续优化网络结构及超参寻优, 进一步提升融合图像质量, 同时, 针对配准的双光数据较少的实际, 还将着手建立更为丰富的数据集, 以方便开展后续研究工作。
| [1] | KUMAR S B K. Image fusion based on pixel significance using cross bilateral filter[J]. Signal Image & Video Processing, 2015, 9(5): 1193-1204. |
| [2] | BAVIRISETTI D P, DHULI R. Fusion of Infrared and visible sensor images based on anisotropic diffusion and Karhunen-Loeve transform[J]. IEEE Sensors Journal, 2015, 16(1): 203-209. |
| [3] | MA J, CHEN C, LI C, et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31: 100-109. DOI:10.1016/j.inffus.2016.02.001 |
| [4] | FU Z Z, ZHAO Y F, XU Y W, et al. Gradient structural similarity based gradient filtering for multi-modal image fusion[J]. Information Fusion, 2020, 53: 251-268. DOI:10.1016/j.inffus.2019.06.025 |
| [5] | LI H, WU X J. Infrared and visible image fusion using latent low-rank representation[EB/OL]. (2018-4-24)[2022-11-11]. https://arxiv.org/abs/1804.08992v4. |
| [6] |
裴佩佩, 杨艳春, 党建武, 等. 基于滚动引导滤波器和卷积稀疏表示的红外与可见光图像融合方法[J]. 激光与光电子学进展, 2022, 59(12): 56-63.
PEI Peipei, YANG Yanchun, DANG Jianwu, et al. Infrared and visible image fusion method based on rolling guidance filter and convolution sparse representation[J]. Laser & Optoelectronics Progress, 2022, 59(12): 56-63. (in Chinese) |
| [7] |
杨勇, 李露奕, 黄淑英, 等. 自适应字典学习的卷积稀疏表示遥感图像融合[J]. 信号处理, 2020, 36(1): 125-138.
YANG Yong, LI Luyi, HUANG Shuying, et al. Remote sensing image fusion with convolutional sparse presentation based on adaptive dictionary learning[J]. Journal of Signal Processing, 2020, 36(1): 125-138. (in Chinese) |
| [8] | ZHOU Z, WANG B, LI S, et al. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with gaussian and bilateral filters[J]. Information Fusion, 2016, 30: 15-26. DOI:10.1016/j.inffus.2015.11.003 |
| [9] | PRABHAKAR K R, SRIKAR V S, BABU R V. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//Proceeding of the 2017 IEEE International Conference on Computer Vision, 2017 |
| [10] | ZHANG Y, LIU Y, SUN P, et al. IFCNN: a general image fusion framework based on convolutional neural network[J]. Information Fusion, 2020, 54: 99-118. DOI:10.1016/j.inffus.2019.07.011 |
| [11] | LI H, WU X J, KITTLER J. Infrared and visible image fusion using a deep learning framework[C]//Proceeding of the 24th International Conference on Pattern Recognition, 2018 |
| [12] | LI H, WU X J, DURRANI T S. Infrared and visible image fusion with resnet and zero-phase component analysis[J]. Infrared Physics & Technology, 2019, 102: 103039. |
| [13] |
陈广秋, 王帅, 黄丹丹, 等. 基于多尺度局部极值分解与ResNet152的红外与可见光图像融合[J]. 光电子·激光, 2022, 33(3): 283-295.
CHEN Guangqiu, WANG Shuai, HUANG Dandan, et al. Infrared and visible image fusion based on multiscale local extrema decomposition and resnet152[J]. Journal of Optoelectronics·Laser, 2022, 33(3): 283-295. (in Chinese) |
| [14] | ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks[C]//Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022 |
| [15] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognitio[C]//Proceeding of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016 |
| [16] | JIE H, LI S, GANG S, et al. Squeeze-and-excitation networks[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020, 42(8): 2011-2023. DOI:10.1109/TPAMI.2019.2913372 |
| [17] | LI X, WANG W, HU X, et al. Selective kernel networks[C]//Proceeding of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020 |
| [18] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceeding of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2009: 248-255 |
| [19] | MAAS A, HANNUN A, NG A. Rectifier nonlinearities improve neural network acoustic models[C]//Proceeding of the 30th International Conference on Machine Learning, 2013 |
| [20] | CLEVERT D, UNTERTHINER T, HOCHREITER S. Fast and accurate deep network learning by exponential linear units(ELUs)[EB/OL]. (2015-11-23)[2022-11-11]. https://arxiv.org/abs/1511.07289. |
| [21] | BISWAS K, KUMAR S, BANERJEE S, et al. SMU: smooth activation function for deep networks using smoothing maximum technique[EB/OL]. (2021-11-23)[2022-11-11]. https://arxiv.org/abs/2111.0468223 |
| [22] |
马旗, 朱斌, 张宏伟. 基于VGG网络的双波段图像融合方法[J]. 激光与红外, 2019, 49(11): 7.
MA Qi, ZHU Bin, ZHANG Hongwei. Dual-band image fusion method based on VGGNet[J]. Laser & Infrared, 2019, 49(11): 7. (in Chinese) |
| [23] | TOET A. The TNO multiband image data collection[J]. Data in Brief, 2017, 15: 249-251. DOI:10.1016/j.dib.2017.09.038 |
| [24] | ZHANG X, YE P, XIAO G. VIFB: a visible and infrared image fusion benchmark[C]//Proceeding of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020 |
| [25] |
徐东东. 基于无监督深度学习的红外与可见光图像融合方法研究[D]. 长春: 中国科学院大学, 2020: 72-74 XU Dongdong. Research on infrared and visible image fusion based on unsupervised deep learning[D]. Changchun: Chinese Academy of Sciences, 2020: 72-74 (in Chinese) |
| [26] | JAGALINGAM P, HEGDE A V. A review of quality metrics for fused image[J]. Aquatic Procedia, 2015, 4: 133-142. DOI:10.1016/j.aqpro.2015.02.019 |
| [27] | WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans on Image Processing, 2004, 13(4): 600-612. DOI:10.1109/TIP.2003.819861 |
| [28] | ESKICIOGLU A M, FISHER P S. Image quality measures and their performance[J]. IEEE Trans on Communications, 1995, 43(12): 2959-2965. DOI:10.1109/26.477498 |
| [29] | XYDEAS C S, PV V. Objective image fusion performance measure[J]. Military Technical Courier, 2000, 56(4): 181-193. |
2. No. 32127 Unit of PLA, Dalian 116100, China
