



2. 西安工业大学 发展规划处, 陕西 西安 710021;
3. 陕西航天技术应用研究院有限公司, 陕西 西安 710100
多目标跟踪旨在预测图像序列中多个目标的位置,识别该图像序列中哪些运动物体是同一目标,将其一一匹配并给出各自相应的运动轨迹。在环境感知中多目标跟踪任务是CV(computer vision)中的一项重要研究技术,该任务在智能监控、无人驾驶、无人机巡检等多种军用和民用场景中应用广泛。
近年来,one-shot方法因其速度和准确性均衡而备受关注。2017年Xiao等[1]首先提出在同一卷积神经网络中处理行人检测和Re-ID任务的端到端框架。Wang等[2]在one-stage检测器中嵌入表观模型,跟踪准确度达到了62.1%,实现了端对端的联合检测和嵌入(JDE)框架。2020年Zhang等[3]基于JDE提出FairMOT,采用无锚框的DLA网络进行多层语义特征提取融合,使Re-ID信息同时包含网络中高维和低维语义信息,忽略了2个任务语义信息的差异。为了应对遮挡问题,2021年,Chaabane等[4]提出DEFT方法,将提取的外观信息用于关联匹配网络,使目标遮挡时具有较强的鲁棒性。同年Guo等[5]提出的TADAM网络采用时间感知和干扰注意力,实现多阶语义的融合,并通过记忆聚合模型来增强REID语义信息,使位置预测和嵌入关联之间协同,却忽视了其主干网络提取信息不足的问题。
在上述介绍的以JDE为主流目标跟踪框架的算法中,由于在跟踪过程中检测质量会影响跟踪性能,其中JDE的检测器对深层特征提取不充分,且忽略目标定位信息和ID信息共享嵌入学习的内在差异性,使得在跟踪过程应对不同尺度目标以及遮挡情况的效果不佳,对目标堆叠情况下的目标判别能力不强。由于注意力机制可对目标形成更好的关注以及获得更鲁棒的语义信息,对网络语义信息有极大影响,因此本文借鉴该思想并针对以上不足在原有的Darknet-53特征提取网络[6]末端加入空间金字塔注意力模块,扩大感受野并弥补CNN对不同尺度目标表征能力不足的问题;在YOLO检测头的分类回归分支和Re-ID特征学习分支应用不同权重的特征相关网络任务,弥补分支任务学习不均衡的矛盾,以应对跟踪过程存在遮挡的问题;在数据关联中将PCCs应用到原有度量运动特征相似度公式,使得目标的跟踪轨迹更加具有判别能力。本文针对JDE算法的不足提出了融合多阶语义增强的JDE多目标跟踪算法,增强了算法的准确度,进一步提升多目标跟踪性能。
1 JDE算法如图 1所示,本文使用基准JDE架构实现特征提取和检测分支共享特征的同步学习。JDE架构检测部分以YOLOv3[6]检测算法为基础,将表观模型嵌入检测网络中,共享主干特征提取网络权值。采用512个3×3卷积学习外观特征,以便模型可以同时输出回归信息、分类及对应的表观特征。基于级联匹配的方式进行跟踪,以卡尔曼滤波[7]轨迹预测、运动和外观特征相似度计算以及匈牙利算法[8]匹配为主完成跟踪任务。JDE中YOLOv3[6]的多分支学习方法提高了跟踪效率,但存在检测和Re-ID[9]特征学习不公平造成ID切换频繁且准确度降低的问题。本文针对此算法的不足提出了改进的目标跟踪算法,引入了注意力模块、特征相关网络以及PCCs-Ma相关度量公式,提高了算法的准确度,有效减少ID switch现象。

|
| 图 1 联合检测和嵌入模型 |
本文采用SPA、FCN和PCCs方法对JDE网络改进,故将基于JDE网络的改进模型称为SFP-JDE。
如图 2所示,第一部分是检测与特征提取,从左至右分别是Darknet-53和SPA[10](spatial pyramid attention)构成的主干特征提取网络、FPN[11]和2种特征相关网络组成的Neck模块、检测器的Re-ID[9]头和YOLO头。具体改进为:首先改进主干特征提取网络,将SPA模块嵌入Darknet-53主干特征提取网络末端。对不同尺度特征融合、重组,提取有效的多尺度特征,增强对不同大小目标的检测能力;其次,考虑到检测需要嵌入相同类别中具有相似语义的不同对象,Re-ID倾向于为2个对象学习区分语义。为了解决两者任务分支存在的差异冲突,本文在分类回归前和Re-ID外观特征提取之前嵌入FCN网络,促使各个分支的表观学习,充分实现了模块间的特征信息共享;最后,在线关联的运动亲和力计算中,引入PCCs相关系数将运动相关度量改进为PCCs-Ma公式,自适应不同轨迹卡尔曼滤波的观察值和预测值的关联程度,提高跟踪运动轨迹的判别能力。

|
| 图 2 本文算法框架示意图 |
注意力模块能够使模型更加关注显著信息,本文采用的SPA[10]模块引入空间金字塔结构等编码和解码操作。考虑全局平均池化会使浅层特征无法充分利用注意力机制,在通道方向引入结构信息,使其同时考虑网络结构正则化和结构信息。
在增强语义信息方面,本文将SPA[10]注意力模块与SPPNet[12]相比。SPPNet为了得到固定长度的特征向量,通过不同大小的卷积得到全局和局部的语义特征,并融合信息。SPA则使用更多的结构信息编码特征图,并且在不引入多余参数的情况下,能保留每个通道中的空间语义信息,两者均有扩大感受野的作用。为了证明SPA注意模块扩大感受野以增强语义信息的有效性,在3.3节进行了实验验证。
由实验结果得,注意力模块放在主干特征提取网络深层时效果最好,且与SPPNet实验对比,SPA既能表示原有特征丰富语义信息,又能扩大感受野,使主干网络继承全局平均聚集的优点,增强CNN的表征能力。为了在复杂环境下提高检测、跟踪性能,利用空间金字塔注意力模块,对输入层特征进行多尺度特征融合、重组,提升主干特征提取网络信息的鲁棒性,故本文在主干特征提取网络末端加入SPA模块增强对不同尺度目标检测,使用该模块提取有效特征并提高效率。
设主干特征提取网络Darknet-53由L层组成,每层输出一个特征图。其中l∈[1, L]是层数序列。本文将SPA布置在Darknet-53的最后一层(l=L), xl表示第l层的输出。整个模块的具体框架实现如图 3所示,具体步骤如下:

|
| 图 3 空间金字塔注意力(SPA)模型 |
步骤1 将xl∈RC×W×H输入SPA模块学习注意权重, 并多尺度学习xl中的每个通道的语义信息。空间金字塔结构S(xl)的输出可以表示为
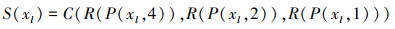
|
(1) |
式中:C(·)表示串联运算; R(·)是指将张量重新调整为向量;P(·, ·)表示自适应平均池化层。
步骤2 设S(xl)=v, v是3个汇集层的输出但非线性表达影响了注意机制的有效性, 故采用2个全连接的多层感知机层对v进行编码, 并生成一维注意力特征图。具体见(2)式
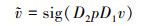
|
(2) |
式中:p为ReLU激活函数; D1和D2分别表示2个全连接层; sig表示sigmoid函数。当忽略BN和激活层时, 将(1)式代入(2)式中得到SPA模块ξ为

|
(3) |
式中:Ffc(·)表示全连接层; σ(·)是sigmoid激活函数。
步骤3 将特征图xl反馈给注意力权重可得SPA输出的一维注意图, 由(3)式可得
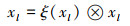
|
(4) |
式中,⊗为元素乘法。
2.2 FCN改进学习任务JDE的检测和外观特征提取2项任务存在内在区别, 从而导致学习模糊化, 造成整体性能降低。为了缓解两者内在矛盾, 将YOLOv3输出的特征表示为F∈RC×H×W。图 4为FCN网络, 分为3个模块, 图中下标符号~代表非, k为0或1。当k=0时, ~k为1, 此时的FCN网络为嵌入检测分支网络结构的权重分支。同理, 当k=1时, ~k为0, FCN网络作为嵌入外观特征分支网络结构的权重分支。本文将k=0/1的FCN网络分别嵌入检测分支和Re-ID特征提取之前, 实现任务的协同学习。

|
| 图 4 特征相关网络结构 |
模块1 首先采用Adaptiveavgpool获得特征信息F′∈RC×H′×W′; 其次将F′作为卷积层的输入得到2个学习任务的特征映射T0和T1; 最后将T0和T1重塑为{M0, M1}∈RC×N′, 其中N′=H′×W′。将特征图通道分为0/1。
模块2 特征层互相关权重计算公式为
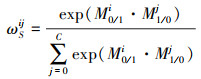
|
(5) |
式中, ωSij代表任务0/1的第i个通道对任务1/0的第j个通道的影响, 且{WS0, WS1}∈RC×C。
模块3 将2个任务与自身的转置矩阵相乘, softmax层计算WT0和WT1且{WT0, WT1}∈RC×C, 计算公式如下
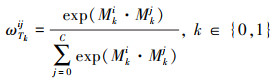
|
(6) |
式中:ωijTk为第i, j通道在通道注意力特征图中两者的关系。WT0和WT1表示任务的自相关权重图。
最终通过λ将模块2和3的相关权重融合, 得到{W0, W1}∈RC×C, 其中λ为训练参数。
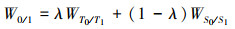
|
(7) |
根据(5)式在M0和M1的转置之间进行矩阵运算, 学习2个任务的共性并遵循softmax层输出互相关权重; 其次, 将M0和M1分别代入(6)式得到2个学习任务的自相关特征; 最后, 将(5)~(6)式代入(7)式计算融合特征相关值。为了增强每个任务的原始语义信息, 应用残差连接将增强后的特征与原始特征F融合。在FCN网络引入ELU激活函数[13]如图 5所示。

|
| 图 5 ELU激活函数 |
如图 5所示ELU让输入的负值能返回一些信息, 更大程度上保留有效信息, 并让整体输出值的均值维持在0附近, 收敛速度加快, 模型的泛化能力变强。在SFP-JDE中使用ELU激活函数能够提升网络特征学习能力, 从而利于提高2个任务学习的公平性并有效减少ID切换的次数。经实验测试, FCN网络使用ELU激活函数能够提升整体SFP-JDE网络架构对于目标的检测能力, 从而更有利于对重叠目标的检测与跟踪, 能有效降低IDS、增大MOTA。ELU激活函数的数学形式如(8)式所示。

|
(8) |
在线关联中卡尔曼滤波器[7]预测轨迹状态, 计算目标轨迹的外观特征和运动特征的相似度, 作为匈牙利算法[9]的相似代价矩阵来解决的轨迹匹配问题。设运动信息的距离为d1, 马氏距离为d(1)(i, j), 用ρdjyi表示目标轨迹的观察值和预测值向量的相关程度, 外观特征向量之间的距离为d2。传统方法采用马氏距离计算运动信息, 尽管马氏距离可以考虑到各种变量之间的联系, 但同时也放大了极小权值变量的作用。本文考虑到不同轨迹信息的有效性, 采用度量2个变量之间相关程度的PCCs融合马氏距离, 以减少信息冗余。
本文为了进一步测量矢量的距离并包含原有运动信息, 组合2个度量表征运动信息实现数据关联。马氏距离d1的基本计算公式如(9)式所示。
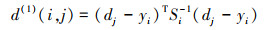
|
(9) |
式中, dj为物体的Bbox信息。ρdjyi的定义为

|
(10) |
式中, yi为目标跟踪的Bbox信息。
由于目标的预测值和观察值存在不相关的情况, 故由(9)式和(10)式得
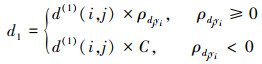
|
(11) |
式中,C的值趋于无穷大。
3 算法训练与实验结果分析实验平台主要由硬件和软件两部分平台构成,其中硬件平台主要配置包括:单卡NVIDIA RTX2060。软件环境为所搭建的深度学习平台,包括:Ubuntu16.04操作系统, Cuda10.2, Cudnn7.6, pytorch1.7.1 -gpu, OpenCV 4.5.1.48, cython-bbox0.1.3, scikit-lean0.24.1, python3.6等,针对本文中研究的行人多目标跟踪,训练基准JDE和SFP-JDE模型。
3.1 算法训练1) 数据集的构成
本文选用CUHK-SYSU[14]、PRW[15]、MOT17[16]3个多目标公共数据集,总共22 222张图片,均为同一个类别标注。数据集中的目标类别仅包含行人一类,同时已剔除训练集中与测试集重复部分。通过CUHK-SYSU[14]、PRW[15]数据集的测试集测试模型的检测准确率,通过MOT基准数据集中的MOT15[17]、MOT16[16]、MOT20[18]评估SFP-JDE多目标跟踪算法的性能。
2) 模型训练
由于JDE模型是在8张Nvidia Titan Xp显卡、批量大小为32的环境下训练。为了避免不公平的对比,将模型训练分为JDE模型训练和SFP-JDE模型训练。以本实验硬件环境训练基准JDE模型并加载预训练模型,训练JDE模型未使用预训练权重。根据硬件配置本实验batch-size为2,初始学习率为0.01,采用等间隔随机调整学习率,动量值0.9,衰减因子为10-4,使用SGD进行30个epochs的训练,图片尺寸被调整到864×480后再输入到网络中,且其余超参数保持不变。2个模型的训练损失变化如图 6所示。

|
| 图 6 30批次训练损失变化 |
本文SFP-JDE与基准JDE模型的检测性能相比,在测试过程中SFP-JDE的各个损失收敛速度更快,对类内目标准确分布且无漏检现象。在CUHK-SYSU、PRW数据集的测试上定量评估模型的检测平均准确率,基准模型针对行人的检测平均准确率为82.37%,而本文的检测器模型可达86.31%,相比提升约3.94%。
3.2 定性分析跟踪算法的非极大值最大重叠率为0.4,置信度阈值和IOU阈值最大余弦距离为0.5。以典型MOT16中的一个视频场景对本文算法定性分析,并和基准JDE算法对比目标跟踪效果。可视化结果分别如图 7~8所示,图片右上角为跟踪状态,右下角为目标的ID号。

|
| 图 7 基准JDE跟踪可视化结果 |

|
| 图 8 SFP-JDE跟踪可视化结果 |
从图 7中可以看到,51和91号目标在被遮挡后产生了ID switch现象,转换为一个新的轨迹标志号,而如图 8所示,采用了SPA注意力模块、FCN网络和皮尔逊相关改进关联度量的改进算法能够在目标被遮挡后仍然保持原有的标志号,这使得目标跟踪的准确度进一步提高,并且有助于保持目标轨迹的完整性。由可视化结果可见,本文算法对于复杂场景的行人多目标跟踪有较高的位置信息准确度、ID信息准确度,能够更有效地避免ID switch现象,并有助于生成目标运动的全局轨迹,取得了良好的效果。
3.3 定量分析在MOT challenge数据集上评估本文算法,其中MOTA为多目标跟踪准确度,IDs是在视频流跟踪过程中总共出现的ID切换次数,IDP为目标ID准确性,IDR为目标ID召回率,IDF1表征跟踪器的好坏。SPA模块的嵌入使得网络层数变多、网络更深,从而在构建特征金字塔时,使用更加鲁棒的信息,获得强语义信息以提高检测效果。本文首先探讨在网络的不同深度嵌入SPA模块对模型的影响。其次,为证明SPA的语义增强有效性,本文在最优位置使用同样具有扩大感受作用的SPPNet与SPA模块进行对比验证实验。在CUHK-SYSU、PRW测试集上通过检测平均准确率AP评价模型。JDE是一种one-shot方法,MOTA等指标与架构中检测到关联所有部分都有关系。通过表 1实验结果对比可得深层嵌入SPA最优,由相同深度的SPPNet实验结果可得SPA对模型提升比SPPNet高,故可得SPA模块嵌入到深层网络的检测效果最优。
| 浅层嵌入SPA | 中层嵌入SPA | 深层嵌入SPA | 深层嵌入SPP | AP |
| √ | 0.655 1 | |||
| √ | 0.844 0 | |||
| √ | 0.877 8 | |||
| √ | 0.848 5 |
本文主要研究多目标准确度及当存在目标遮挡情形时的标签切换问题,在MOT基准数据集的视频序列上做跟踪实验。表 2展示了在MOT数据集上SFP-JDE与基准JDE算法的量化指标对比。
| 数据集 | 算法 | MOTA/% | IDF1/% | IDP/% | IDR/% | IDs |
| MOT15 | JDE(864×480) SFP-JDE |
48.3 48.1 |
57.5 60.9 |
56.5 57.5 |
58.5 65.3 |
652 626 |
| MOT16 | JDE(864×480) SFP-JDE |
54.6 61.5 |
55.8 62.7 |
69.5 73.2 |
46.6 54.9 |
1 342 1 279 |
| MOT20 | JDE(864×480) SFP-JDE |
16.7 18.8 |
17.9 19.6 |
54.2 58.7 |
10.7 11.7 |
9 877 7 885 |
为进一步验证本文算法的有效性, 本文将JDE的改进算法与其他算法在MOT16基准数据集序列上进行对比分析。其中,TADAM为JDE改进算法;Deep SORT为非JDE算法。为保证相对公平的条件对比,本文将在相同实验环境下训练TADAM[5]模型。Deep SORT[19]算法为非JDE算法,使用原作者提供的POI检测器的检测文件做定量评估。上述算法定量评估测试结果如表 3所示。
由实验结果可以看出,本文的引入SPA模块、FCN网络以及改进运动度量方程的改进算法的MOTA高于基准JDE算法,ID准确率与ID召回率指标均有明显提升,ID switch现象大幅减少,轨迹ID稳定性明显提高。具体分析如下:
1) 由表 2分析可得,在最初的MOT挑战数据集MOT15上, 相较于原算法,本文算法IDF1指标有3.4%的提升,ID召回率明显提高。在MOT16数据集上显著超过基准JDE算法,MOTA和IDF1指标提高了6.9%。MOT20与上述数据集相比,更具挑战性,其数据集在3个非常拥挤的场景中拍摄,数据呈现高度、亮度多样性,故整体算法指标过低,但与基准JDE算法相比,本文算法MOTA指标提高2.1%,IDF1指标提高1.7%。
2) 由表 3可知,本文算法相较于Deep SORT[17]算法,MOTA指标提升将近10%,IDF1指标提高2%。与TADAM算法相比,MOTA提升4.4%,IDF1提升2.4%。
综上所述,本文算法相较原算法跟踪能力明显提高,判断目标轨迹是否是同一个目标的能力变强。
4 结论为了解决JDE将检测和嵌入共同学习造成在目标短时遮挡以及2个学习任务提取信息不足造成的ID切换问题,本文提出了SPA注意力模块、FCN网络以及利用相关度改进运动度量的多目标跟踪算法。注意力模块兼顾网络架构信息和正则化能够增强基础特征网络,获得更多的语义,从而提取深层有效特征;FCN有利于保留原信息,获得目标的检测信息与Re-ID外观特征不同的语义信息增强;PCCs-Ma改进运动特征相关度量,有利于强化跟踪过程中卡尔曼滤波的预测值与观察值之间的联系,提升了在短时遮挡场景下持续追踪目标运动轨迹的关联能力。实验结果表明,本文算法在行人目标短时遮挡复杂场景下能有效提升目标跟踪性能,使得目标跟踪定位更加准确。后续工作将会在模型中加入长短时间记忆感知的目标注意,以形成对目标更好的关注,进一步提升跟踪性能。
| [1] | XIAO Tong, LI Shuang, WANG Bochao, et al. Joint detection and identification feature learning for person search[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3415-3424 |
| [2] | WANG Zhongdao, ZHENG Liang, LIU Yixuan, et al. Towards real-time multi-object tracking[C]//Computer Vision-European Conference on Computer Vision, 2020: 107-122 |
| [3] | ZHANG Yifu, WANG Chunyu, WANG Xinggang, et al. FairMOT: on the fairness of detection and re-identification in multiple object tracking[J]. International Journal of Computer Vision, 2021, 129(11): 3069-3087. DOI:10.1007/s11263-021-01513-4 |
| [4] | CHAABANE M, ZHANG P, BEVERIDGE J R, et al. DEFT: detection embeddings for tracking[EB/OL]. (2021-02-03)[2021-11-01]. https://arxiv.org/abs/2102.02267 |
| [5] | GUO Song, WANG Jingya, WANG Xinchao, et al. Online multiple object tracking with cross-task synergy[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, 2021: 8132-8141 |
| [6] | REDMON J, FARHADI A. Yolov3: An incremental improvement[EB/OL]. (2018-04-08)[2021-11-01]. https://arxiv.org/abs/1804.02767 |
| [7] | KALMAN R E. A new approach to linear filtering and prediction problems[J]. Journal of Basic Engineering, 1960, 82: 35-45. DOI:10.1115/1.3662552 |
| [8] | KUHN H W. The hungarian method for the assignment problem[J]. Naval Research Logistics Quarterly, 1955, 2(1/2): 83-97. |
| [9] | ZHANG Xuan, LUO Hao, FAN Xing, et al. AlignedReID: surpassing human-level performance in person re-identification[J/OL]. (2017-11-22)[2021-11-01]. https://arxiv.org/abs/1711.08184 |
| [10] | GUO Jingda, MA Xu, SANSOM A, et al. Spanet: spatial pyramid attention network for enhanced image recognition[C]//2020 IEEE International Conference on Multimedia and Expo, London, 2020: 1-6 |
| [11] | LIN T Y, DOLLAR P, GIRSHICK R. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 936-944 |
| [12] | HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2014, 37(9): 1904-1916. |
| [13] | DJORK-ARNÉ C, UNTERTHINER T, HOCHREITER S. Fast and accurate deep network learning by exponential linear units(ELUs)[C]//International Conference on Learning Representations, San Juan, Puerto Rico, 2016: 1-14 |
| [14] | XIAO T, LI S, WANG B, et al. Joint detection and identification feature learning for person search[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3415-3424 |
| [15] | ZHENG L, ZHANG H, SUN S, et al. Person re-identification in the wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1367-1376 |
| [16] | MILAN A, LEAL-TAIXE L, REID L, et al. Mot16: a benchmark for multi-object tracking[J/OL]. (2016-03-02)[2021-11-01]. https://arxiv.org/abs/1603.00831 |
| [17] | LEAL-TAIXE L, MILAN A, REID I, et al, MOTChallenge 2015: towards a benchmark for multi-target tracking[EB/OL]. (2015-04-08)[2021-11-01]. https://arxiv.org/abs/1504.01942 |
| [18] | DENDORFER P, REZATOFIGHI H, MILAN A, et al. MOT20: a benchmark for multi object tracking in crowded scenes[EB/OL]. (2020-03-19)[2021-11-01]. https://arxiv.org/abs/2003.09003 |
| [19] | WOJKE N, BEWLEY A, PAULUS D. Simple online and realtime tracking with a deep association metric[C]//2017 IEEE International Conference on Image Processing, 2017: 3645-3649 |
2. Development Planning Service, Xi′an Technological University, Xi′an 710021, China;
3. Shaanxi Academy of Aerospace Technology Application Co., Ltd, Xi′an 710100, China
