


2. 西北工业大学 软件学院, 陕西 西安 710072;
3. 西安工业大学 计算机科学与工程学院, 陕西 西安 710021
随着移动应用的日益普及和快速发展,移动应用测试正面临严峻的挑战[1-4]。首先,移动应用存在基于Android、iOS、Windows Mobile以及Mobile Web等平台的多样化开发模式,但却缺乏支持多平台应用的通用化测试方法与测试工具。其次,移动设备品牌、型号众多,操作系统版本繁杂,其面临严重的碎片化问题,并很难达成有效且全面的测试。并且,移动设备提供了更加丰富的人机交互方式,例如,手势、语音,以及重力、加速度、光等多种传感器,使得其输入复杂,加剧移动应用测试难度。最后,移动市场竞争日益激烈,移动应用版本更新频繁,开发厂商普遍缺乏足够的时间、人员、设备、工具等测试资源。
为应对上述测试难题,学术界与工业界持续投入对移动应用自动化测试方法的研究。当前的自动化测试方法主要包括:基于脚本的测试方法通过构建自动化测试框架将人工编写的测试脚本转换为模拟的事件流实现对测试动作在移动应用上的模拟执行[5-6];基于录制回放的测试方法将人工测试的过程进行录制进而通过回放重用该执行过程[7-8];基于模型的自动化测试方法通过对被测应用进行定义和遍历将应用的功能行为构建成为一种有限状态机模型实现测试用例的自动生成[9-10];另有通过挖掘已有测试用例并对比应用功能的相似性实现测试用例的重用[11-12]。此外,随着机器人技术的发展,一些采用机械臂执行移动应用测试的方法被提出[13-14],即利用机械臂替代传统模拟事件流的测试执行,提供一种更真实的测试手段;同时,解决移动应用与外部交互的测试问题,如利用机械臂对拍照应用进行防抖动测试[15]。基于机器人的测试可作为一种完全的黑盒测试方法支持跨平台、跨设备的应用测试。
从上述各类测试方法研究中可以看出移动应用测试通常紧密围绕于GUI状态的判断,进而引导测试动作交互完成测试。然而,当前的自动化测试却始终面临一个关键性的问题即移动应用状态空间的爆炸[16]。在移动应用中通常存在大量的同构GUI,即GUI的外观(文本、图像、颜色、大小)不同,但功能、结构以及内在逻辑关系相同的GUI。例如,购物类应用每个商品的展示页面,其GUI结构相同但内容不同。在开发层面,它们均通过同一代码段加载实现。显然,对移动应用中的每一同构GUI进行探索或测试是十分低效的。甚至,当应用存在大量的同构GUI时,将最终导致应用状态空间的爆炸,引发测试的失败。
因此,在自动化测试方法中,同构GUI的识别与精简对提升测试效率至关重要。而当前测试方法在同构GUI的判断上,一方面通过分析GUI布局文件获取由GUI组件构成的GUI树,从而比较相似度;另一方面直接通过对GUI或GUI元素图像进行像素比较完成相似判断。但是采用上述方式仍然使得GUI的判断与GUI属性相关联,即使在GUI发生微小的变化时也会引发判断的失效。例如,一个列表中内容的重新排序,或者在版本更新后GUI元素的位置或样式发生略微变动均会影响判断。然而,在人工测试中,因为可以进行充分抽象化的GUI比较,所以并不受限于这些影响。
针对上述问题,本文提出一种基于GUI视觉信息的相似度抽象判断方法,即从视觉角度出发通过提取GUI结构框架,保留GUI元素类别、布局等关键信息,剥离GUI元素样式、内容等非必要属性信息,以实现一种从布局结构出发的高度抽象化的移动应用同构GUI判断。
1 同构GUI视觉判断方法移动应用同构GUI视觉判断方法的处理过程如图 1所示。当从被测应用获取到当前的GUI图像时,首先通过GUI视觉抽象处理识别GUI图像中的组件元素并生成GUI结构框架,完成对GUI结构的提取;其次,利用一个自编码器模型得到GUI框架的视觉特征;最后,通过与GUI特征库中已知被测应用的GUI特征进行相似度计算判断该GUI是否为同构GUI。倘若其为非同构GUI(即一个新的GUI)则将该特征加入特征库中并继续执行对该GUI的测试。倘若该GUI为同构GUI,则跳过该GUI的测试(说明之前已测试同类型GUI),优化测试过程。本节将给出移动应用同构GUI视觉判断方法各处理部分的详细实现。

|
| 图 1 移动应用同构GUI视觉判断处理过程 |
移动应用GUI通常由丰富的组件元素构成,因此在移动应用GUI的视觉判断研究中,首先解决对GUI组件元素的视觉定位与识别。GUI界面从布局结构上通常为一个树形结构,由容器类组件包含基本组件所构成。然而,从视觉角度出发,使用者更关注于界面上直观的基本元素以及其所能执行的操作。因此在GUI元素的视觉识别上将聚焦于对基本组件元素的识别。此外,在一个GUI图像中,容器类组件一般自身并未有明显的视觉特征,而是由基本组件所组合而成。因此,识别基本组件并未丢失掉容器类组件的视觉表示信息。
本文采用目标检测技术完成对GUI组件元素的视觉识别。首先,在移动应用GUI目标检测数据集的准备方面,基于已有的大型GUI界面数据集RICO[17]开展,其具有涵盖多个类别的6万幅移动应用GUI截屏,且每个截屏配备一个GUI层次结构文件(包含GUI中各组件所属类及位置信息)。在充分考虑组件特性和视觉特征的前提下,将识别组件类别分为文本、图像、图形按钮、文字按钮、文本框、多选框、复选框、切换按钮、拖动条。进而利用RICO提供的GUI层次结构文件,编写转换程序,完成其向目标检测所需标注文件的过滤与转换,通过自动化的标注方式完成移动应用GUI目标检测数据集的建立。
其次,开展目标检测算法对GUI组件元素的识别训练。为进一步降低单个模型检测出现的漏检等问题并优化识别精度,本文基于移动应用GUI目标检测数据集分别训练3种目标检测模型(YOLO[18]、SSD[19]、RetinaNet[20]),并采用并行投票策略完成GUI组件元素识别。
最后,依据GUI组件元素识别结果生成GUI结构框架图,抽象表示出GUI结构。GUI框架图常用于GUI的设计与开发中[21-22],是一种对GUI结构的表示方法。本文针对GUI组件元素类型,以不同的颜色标识其类别,生成GUI框架图。将GUI表示为GUI框架图的目的在于:①剥离掉GUI元素样式、大小、形状的差异性,提取GUI的结构表示信息;②可以简化图像对比的计算复杂度。GUI结构框架生成过程如图 2所示。

|
| 图 2 移动应用GUI结构框架生成 |
在生成GUI结构框架后,利用构建自编码器模型继续提取GUI结构视觉特征。自编码器(AutoEncoder)是一种经典的无监督学习方法,其面向高维复杂数据处理,通过使用反向传播算法让目标值等于输入值。例如,自编码器可以通过编码器生成图像的特征向量,再通过解码器依据特征向量生成目标图像。通过比较原图像与生成图像的差异,无监督地完成图像特征向量的准确生成。
传统的自编码器容易造成数据在固定空间内的堆叠,导致关键信息的丢失,因此本文采用一种卷积自编码器[23]尽可能保留图像特征。即在自编器的结构上利用卷积层替代全连接层从而更好地完成图像特征的提取。
本文定义的卷积自编码器结构如图 3所示,包括编码器和解码器两部分。编码器由卷积层和池化层组成,负责完成对输入GUI框架图的压缩。经过4组卷积与池化层后的隐藏层即为可提取的GUI框架图特征向量。解码器与编码过程相对,通过4组卷积层和上采样层,对压缩数据进行复原重建输入图像。自编码器经过反复编码与解码的迭代训练,逐步提高自编码精度,直至解码后的数据和输入数据的差距逐渐减少并趋于平稳。当完成自编码器的训练,编码器则可以提取任意输入GUI框架图视觉特征。下面给出本文卷积自编器的详细设计。

|
| 图 3 基于卷积自编码器的GUI视觉特征提取 |
1) 数据预处理
GUI框架图在输入到卷积自编码器之前,首先进行归一化处理以提高自编码器模型训练性能,加速收敛。采用Min-Max标准的归一化方法,把原始数据从[0, 255]归一化到标准的[0, 1]范围内,如(1)式所示。
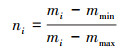
|
(1) |
式中:ni为规范化的第i个数据, 值为[0, 1]之间;mi为未规划前的数据;mmin为原数据中的最小值;mmax为原数据中的最大值。
2) 编码器设计
编码器包括卷积层和池化层, 对输入数据进行特征提取和压缩。编码器由4个卷积和4个池化构成。卷积层的功能用于提取和融合输入图像特征, 它不识别整个图像而是通过局部感知来捕获图像中的每个特征, 然后在更高层次上对本地信息进行综合运算得到全局信息。利用生成的GUI框架图作为输入数据, 其维度为128×128×3。编码器4个卷积, 依次使用64, 32, 16, 8个大小为3×3的卷积核, 步长默认为1, 填充设置为相同。此外, 选择ReLU(校正线性单元层)作为激活函数, 进行卷积层线性运算到GUI结构视觉特征输出的非线性映射。
在卷积层提取到GUI框架特征后, 输出特征将被传送到编码器的池化层进行特征选择和信息过滤。池化层用于对特征图进行下采样处理, 在保留重要信息的前提下快速降低特征维度以减少计算量, 并避免过拟合提高模型的容错性。经过第一层卷积后, 数据维度由原来的128×128×3变为128×128×64。池化操作不改变数据的深度, 所以池化后的数据维度为64×64×64。池化层对每层卷积结果进行2×2最大池化操作, 步长为2。经过4层卷积和池化操作, 得到隐藏层的压缩表示。
3) 解码器设计
编码器对GUI结构视觉特征进行提取和压缩后, 进一步使用解码器对特征进行反卷积操作以获得与输入数据相同的大小。解码器由4个上采样和4个卷积构成。采用的反卷积操作由第一步上采样和第二步正常的卷积操作组成, 即通过上采样将特征图像扩大, 再进行卷积操作而完成反卷积过程。上采样采用最近邻插值方法进行, 即寻找插入位置的最邻近数据作为其数据插入。解码器中上采样每层使用大小为2×2, 步长为2的操作, 卷积层依次使用8, 16, 32, 64个大小为3×3的卷积核, 步长设置为1, 填充设置为相同, 与编码器的卷积层相对应。
4) 损失层
损失层用于确定在训练过程中如何减少网络预测结果和实际结果之间的差异。损失函数值越小, 模型拟合越好。在本文的卷积自编码器中, 采用均方根误差作为损失函数计算输入GUI框架原图与重建框架图之间的差异。损失函数如(2)式所示。
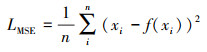
|
(2) |
式中:n为输入的图片数量;xi为输入第i个图片;f(xi)为重建的第i个图片。在训练过程中, GUI框架原图像和重建图像之间的差异将不断减小, 直到模型收敛。完成训练后, 原图像的压缩编码数据即为GUI结构的视觉特征。
1.3 移动应用GUI相似判断提取到GUI框架的视觉特征后, 进一步通过计算GUI框架特征的距离度量判断GUI相似情况。本文采用JS散度进行GUI特征的距离度量。
JS(Jensen-Shannon)散度是机器学习中经常用来衡量随机分布之间相似度的方法。任意2个GUI随机分布使用以2为底的对数, JS散度范围为[0, 1], 即GUI相似度范围在[0, 1]之间。JS散度越小GUI越相似, 即JS散度值为0时, 2个GUI完全一样, JS散度值为1时, 2个GUI没有重叠的地方。JS散度定义为(3)式。
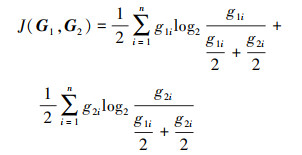
|
(3) |
式中:J(G1, G2)为2个GUI相似度值;G1和G2为2个GUI特征集合;n为GUI分布数量即每个GUI特征向量个数,本文取n=512;g1i为G1的GUI集合中第i个随机值;g2i为G2的GUI集合中第i个随机值。
GUI相似判断算法如算法1所示。g1作为已知GUI结构特征, g2为当前探索到某一GUI特征。利用JS散度计算出各维度的相似情况, 并通过阈值判断是否相似。最后, 返回与g2相似的GUI信息(相似GUI, 相似度, 是否同构)。
在计算JS散度时, 某一特征数据为0时为避免计算错误, 将其设置为一个极小值10-7。此外, 因JS散度越小GUI越相似, 为直观体现相似性结果, 用1减去散度作为相似判断结果。
算法1 GUI相似判断
输入: 已知GUI特征向量集合G, 当下的GUI特征向量g2
输出: 相似GUI信息P < GUI, 相似度, 是否同构>
1 Jsm=0
2 for each g1 in G do
3 j←getJSDivergence(g1, g2)
4 if j>threshold then
5 P←getJudgeInfo(g1, j, 1)
6 return P
7 else if j>Jsm then
8 Jsm=j
9 P←getJudgeInfo(g1, j, 0)
10 end if
11 end for
12 return P
至此, 通过视觉技术生成GUI结构框架, 利用自编码器提取GUI框架特征, 再比较GUI框架特征相似度完成同构GUI的视觉判断。
2 实验验证分析为验证本文提出的移动应用同构GUI视觉判断方法的有效性, 分别开展GUI视觉特征提取的准确性验证, 同构GUI判断的有效性验证以及同构GUI判断对比验证。
2.1 移动应用GUI视觉特征提取验证为验证GUI视觉特征提取的准确性, 从RICO数据集中选取1 000张GUI并生成其GUI框架图作为特征提取数据集,其中, 800张作为训练集, 200张作为测试集。卷积自编码器输入128×128×3结构的图像数据, 首先进行归一化处理, 其次经过编码器的卷积、最大池化和解码器中的上采样、卷积处理, 最后再经过一次卷积后恢复为输入的图片尺寸。使用Adam优化算法作为网络优化参数, 优化训练。批处理大小(batch_size)设置为32, 迭代轮次(epochs)设置为2 000。训练环境采用NVIDA GeForce GTX 2080 GPU, 基于pycharm训练平台的keras深度学习框架。在模型训练结束后, 输入测试集进行GUI框架视觉特征提取验证。最后提取的每张图像压缩后的数据大小为8×8×8=512个特征。卷积自编码器模型结构如表 1所示。
| 层级 | 输出维度 | 参数规模 |
| Conv2D | (128, 128, 64) | 1 792 |
| MaxPooling2D | (64, 64, 64) | 0 |
| Conv2D_1 | (64, 64, 32) | 18 464 |
| MaxPooling2D_1 | (32, 32, 32) | 0 |
| Conv2D_2 | (32, 32, 16) | 4 624 |
| MaxPooling2D_2 | (16, 16, 16) | 0 |
| Conv2D_3 | (16, 16, 8) | 1 160 |
| MaxPooling2D_3 | (8, 8, 8) | 0 |
| UpSampling2D | (16, 16, 8) | 0 |
| Conv2D_4 | (16, 16, 8) | 584 |
| UpSampling2D_1 | (32, 32, 8) | 0 |
| Conv2D_5 | (32, 32, 16) | 1 168 |
| UpSampling2D_2 | (64, 64, 16) | 0 |
| Conv2D_6 | (64, 64, 32) | 4 640 |
| UpSampling2D_3 | (128, 128, 32) | 0 |
| Conv2D_7 | (128, 128, 64) | 18 496 |
| Conv2D_8 | (128, 128, 3) | 1 731 |
模型的训练结果如图 4所示。模型的损失函数, 在训练集和测试集上分别收敛于0.02和0.03, 模型精度分别为0.83和0.81。

|
| 图 4 模型训练结果 |
GUI框架原图和由卷积自编码器重建框架图像对比如图 5所示, 重建图像与原图像越相似说明GUI特征提取的越准确。从图 5中可以直观地看到, 重建图像与原图具有较高的相似度, 因此本文的卷积自编码器能够准确地提取GUI框架视觉特征。

|
| 图 5 GUI框架原图与重建图对比 |
为进一步验证同构GUI判断的有效性, 额外选取包含同构GUI的100张GUI进行实验。其中, 前50张作为已知GUI, 后50张为需要判断的GUI。图 6a)所示为真实值, 对角线表示对应的图像为同构GUI, 其他区域为非同构GUI。对角线上网格的大小代表该同构界面的数量, 同构界面数量越多网格越大。利用文本方法将后50张GUI分别与前50张GUI进行共计2 500次判断计算。

|
| 图 6 GUI相似度判断验证结果 |
图 6b)所示为前后2组GUI之间的相似度计算结果, 设置相似度阈值为0.9, 大于为同构GUI, 小于为非同构GUI。图中颜色越深, 表示相似度值越高。对比图 6a)中同构GUI的真实值, 在图 6b)中可以明显看出大于0.9的同构GUI和真实值GUI所在位置基本一致, 而小于0.9的非同构GUI所在位置总体为浅色和白色所覆盖。对角线同构界面的颜色明显, 且网格大小与真实值相近。因此, 实验表明本文方法能够依据视觉信息正确判断同构GUI。
然而, 结果仍然存在一些误差的原因主要在于: 一方面, 在方法层面, 视觉判断方法依赖于目标检测等视觉处理模型精度, 例如GUI组件的类别错误检测或漏检均会影响相似度计算结果; 另一方面, 在GUI的特性层面, GUI具备丰富的视觉特征和灵活的设计风格, 应用界面内容的多样化会影响同构判断。
2.3 对比验证另外, 分别与传统的3种图像哈希算法进行对比实验。哈希算法为图像分配唯一的哈希值, 并通过对比图像的哈希值判断相似度, 结果越接近则图像越相似。选择差值哈希算法、感知哈希算法、均值哈希算法3种基于哈希的图像相似度比较算法进行对比验证。通过构建GUI灰度图像并计算比较哈希值完成。
利用准确率、精确率、召回率、F1值进行结果的评估分析。各方法表现如图 7所示。

|
| 图 7 对比验证结果 |
对比实验结果表明,尽管4种方法的准确率均大于0.9,但本文方法达到最高的准确率0.987 2。而在精确率、召回率、F1值评价指标上,本文方法均达到0.8以上,其效果远优于其他方法。本文因采用对GUI的高度抽象进而再相似比较,相较于其他方法有效屏蔽了GUI样式、内容等属性所带来的干扰影响,能够更为精准地捕捉同构GUI。
2.4 讨论上述实验验证表明,本文提出的基于视觉的移动应用同构识别方法已经达到了较高的识别精度。利用视觉判断同构GUI与传统非视觉的判断方法(例如,GUI树比较判断)相比较存在如下优劣:①视觉判断方法通过应用GUI外在视觉表示信息进行判断,而非视觉方法则依赖于应用内部组件组成信息。因此,视觉判断方法可以作为一种支持跨平台或黑盒测试的通用方法,而非视觉判断方法则更针对单一平台应用或白盒测试;②视觉判断方法是针对GUI抽象结构的判断,而非视觉判断方法则是精确的GUI组件及属性比较。尽管视觉判断方法受到目标检测等视觉算法精度的影响,但却可以屏蔽GUI组件属性微小改动而带来的判断失效影响;③视觉判断方法拥有更高的使用成本。视觉判断方法需要进行多种视觉算法的计算与训练,需要更高的计算与时间投入。综上分析,本文提出的视觉判断方法是对现有同构GUI判断的补充与增强,促进其在跨系统平台,设备非侵入以及纯黑盒机器人测试等场景下的使用。
3 结论本文提出了一种基于视觉的移动应用同构GUI视觉判断方法,通过利用目标检测技术以纯视觉方式获取GUI组件元素从而生成GUI结构框架,并引入卷积自编码器完成对GUI结构视觉特征的提取,最后通过散度计算比较GUI结构视觉特征来判断GUI相似度,形成一种高度抽象化的GUI判断分析。实验表明本文方法能够准确地识别同构GUI,促进解决移动应用自动化测试所面临的状态空间爆炸问题。此外,该方法因为不依赖于移动应用内部信息,可灵活应用于现有的自动化白盒与黑盒测试中。
本文方法仍然存在一些可改进之处。首先,部分应用存在灵活的界面表达方式,进一步复杂化同构界面的自动化判断。除了GUI结构上的比较,加入语义信息将会增强对此类多样化界面的判断。其次,采用视觉方法识别GUI存在一定的精度误差,将视觉判断方法与非视觉判断方法相融合将促进同构界面判断效果的增强。后续,仍可持续深入移动应用GUI在同表示含义,同行为模式上的视觉特征判断方法研究,进一步强化移动应用测试中的GUI自动化分析与理解。
| [1] | KONG P, LI L, GAO J, et al. Automated testing of Android apps: a systematic literature review[J]. IEEE Trans on Reliability, 2018, 68(1): 45-66. |
| [2] | TRAMONTANA P, AMALFITANO D, AMATUCCI N, et al. Automated functional testing of mobile applications: a systematic mapping study[J]. Software Quality Journal, 2019, 27(1): 149-201. DOI:10.1007/s11219-018-9418-6 |
| [3] | LINARES-VÁSQUEZ M, BERNAL-CÁRDENAS C, MORAN K, et al. How do developers test android applications?[C]//2017 IEEE International Conference on Software Maintenance and Evolution, 2017: 613-622 |
| [4] | RUBINOV K, BARESI L. What are we missing when testing our android apps?[J]. Computer, 2018, 51(4): 60-68. DOI:10.1109/MC.2018.2141024 |
| [5] | Appium-automation for apps[EB/OL]. (2018-10-05)[2021-08-18]. http://appium.io/dols/cn/about-appium/intro |
| [6] | Eyeautomate-visual script runner[EB/OL]. (2019-02-08)[2021-08-12]. https://eyeautomate.com/eyeautomate |
| [7] | AMALFITANO D, RICCIO V, AMATUCCI N, et al. Combining automated GUI exploration of android apps with capture and replay through machine learning[J]. Information and Software Technology, 2019, 105: 95-116. DOI:10.1016/j.infsof.2018.08.007 |
| [8] | GUO J, LI S, LOU J G, et al. SARA: self-replay augmented record and replay for android in industrial cases[C]//Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2019: 90-100 |
| [9] | GU T, SUN C, MA X, et al. Practical GUI testing of Android applications via model abstraction and refinement[C]//2019 IEEE/ACM 41st International Conference on Software Engineering, 2019: 269-280 |
| [10] | SALIHU I A, IBRAHIM R, AHMED B S, et al. AMOGA: a static-dynamic model generation strategy for mobile apps testing[J]. IEEE Access, 2019, 7: 17158-17173. DOI:10.1109/ACCESS.2019.2895504 |
| [11] | BEHRANG F, ORSO A. Test migration between mobile apps with similar functionality[C]//2019 34th IEEE/ACM International Conference on Automated Software Engineering, 2019: 54-65 |
| [12] | PAN M, XU T, PEI Y, et al. GUI-guided test script repair for mobile apps[J]. IEEE Trans on Software Engineering, 2022, 48(3): 910-929. |
| [13] | CRACIUNESCU M, MOCANU S, DOBRE C, et al. Robot based automated testing procedure dedicated to mobile devices[C]//2018 25th International Conference on Systems, Signals and Image Processing, 2018: 1-4 |
| [14] | MAO K, HARMAN M, JIA Y. Robotic testing of mobile APPS for truly black-box automation[J]. IEEE Software, 2017, 34(2): 11-16. DOI:10.1109/MS.2017.49 |
| [15] | BANERJEE D, YU K. Robotic arm-based face recognition software test automation[J]. IEEE Access, 2018, 6: 37858-37868. DOI:10.1109/ACCESS.2018.2854754 |
| [16] | NASS M, ALÉGROTH E, FELDT R. Why many challenges with GUI test automation(will) remain[J]. Information and Software Technology, 2021, 138: 106625. DOI:10.1016/j.infsof.2021.106625 |
| [17] | DEKA B, HUANG Z, FRANZEN C, et al. RICO: a mobile app dataset for building data-driven design applications[C]//Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, 2017: 845-854 |
| [18] | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[J/OL]. (2020-04-05)[2021-08-12]. https://arxiv.org/abs/2004.10934 |
| [19] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision, Cham, 2016: 21-37 |
| [20] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 2980-2988 |
| [21] | CHEN C, SU T, MENG G, et al. From UI design image to GUI skeleton: a neural machine translator to bootstrap mobile GUI implementation[C]//Proceedings of the 40th International Conference on Software Engineering. 2018: 665-676 |
| [22] | MORAN K, BERNAL-CÁRDENAS C, CURCIO M, et al. Machine learning-based prototyping of graphical user interfaces for mobile apps[J]. IEEE Trans on Software Engineering, 2018, 46(2): 196-221. |
| [23] | MASCI J, MEIER U, CIRESAN D, et al. Stacked convolutional auto-encoders for hierarchical feature extraction[C]//International Conference on Artificial Neural Networks, Berlin, Heidelberg, 2011: 52-59 |
2. School of Software, Northwestern Polytechnical University, Xi'an 710072, China;
3. School of Computer Science and Engineering, Xi'an Technological University, Xi'an 710021, China
