



2. 西安石油大学 电子工程学院, 陕西 西安 710065
目标分配是作战对抗过程中的一个重要因素,是与国防相关的运筹学应用中出现的基本问题之一。目标分配问题的本质就是在作战过程中按照一定的要求,找到针对敌方目标分配的最佳解决方案,合理地将系统的武器单元分配给多个目标,降低系统执行任务的代价,获取最大的对抗收益[1]。目标分配是一种非线性组合优化和非确定性多项式完备问题。作为军事行动研究领域经典的约束优化问题,受到了各国研究人员的广泛关注,关于这方面的研究也取得了丰硕的成果。
武从猛、王公宝[2]将遗传算法生成的粗略解作为蚁群算法的初始信息素,结合蚁群算法中的并行、正反馈机制求解了水面舰艇编队防空武器的目标分配问题,缩短了目标分配的决策时间,提高了解的质量。Glotzbach等[3]针对水下无人武器的协同攻击问题,提出了异构无人舰艇编队的协同视线目标跟踪原理,构建了无人舰艇编队的整体控制结构,提出了自主舰艇编队目标视线协同攻击的控制准则和算法。田伟等[4]通过引入随机时间影响网络来分析打击目标与任务之间的关系,全面深入地分析了动态目标分配问题的约束条件,构建了联合火力打击的动态目标分配模型,结合远程对海打击的案例,通过仿真验证了该方法的有效性。Li等[5]采用了基于分解的多目标进化算法来解决基于资产配置最优的目标分配问题,通过重新设定配对限制和选择操作提高了算法的执行效率。Liang和Kang[6]采用自适应混沌并行克隆选择算法,结合混沌理论与并行种群分类的优点,实现了种群初始化和种群更新,解决了军舰编队防空应用的目标分配问题。王玮等[7]针对信息化作战条件下的海上编队目标分配问题,在多层防御模式下的目标分配模型基础上,提出了一种基于遗传算法的交互式方法,用来求解海上编队防空目标分配问题。Jia等[8]根据目标的位置和防御区域的半径进行防御区域分析,结合覆盖状态和覆盖层数,提出多阶段攻击规划方法,将传统的武器目标分配方法与多阶段武器目标分配方法进行比较,验证了所提方法的有效性。
现有的研究成果大多从参与对抗的一方角度出发进行分析,而实际的对抗是一个双方交互的行为。博弈对抗开始时,对抗双方都不知道对方会采取何种行动,在只考虑一方收益最大条件下获得的最优策略,必定是以对方采取某一特定策略为前提。若这一策略有损对方自己的利益,则对方并不会采取。此时,单方求解得到的最优策略并不具备存在条件。另外,交战双方各自的AUV都有自己的攻击力类型,根据攻击力的大小可分为高杀伤性类型和低杀伤性类型。因此,不同类型的AUV在进行对抗时,表现出来的博弈情形也会不同。虽然敌我双方交战时,各方都知道自己的AUV攻击力类型,但是并不清楚对方会选择哪种攻击力类型的AUV执行打击任务。这意味着当对抗真正开始时,对抗双方不能完全了解作战局势中的所有信息,并不清楚究竟会体现为哪种博弈形式。这种在进行博弈时,局中人对除了自己以外的其他局中人的类型、策略空间或收益函数等信息并不完全了解的情况下进行的博弈就属于不完全信息博弈。
本文针对AUV博弈对抗中的信息不完全问题,以不完全信息博弈理论为基础,利用海萨尼转换,通过引入虚拟参与人“自然”[9],先选择出AUV类型(高杀伤性AUV或低杀伤性AUV),从而将博弈过程中局中人的事前不确定性转变为博弈开始后的行动不确定性,将未知成本的不完全信息博弈转化为关于“自然”的行动不确定博弈。
1 面向不完全信息的AUV目标分配模型的构建 1.1 AUV博弈对抗中的不完全信息博弈AUV的博弈对抗是一种非合作形式、信息不完全、多阶段的动态博弈过程。在双方进行攻防对抗时,参与对抗的各方并不能完全了解与当前博弈相关的信息。虽然双方同时行动,但各方都没有机会观察到对方的行动选择,因此,不可能确切知道对手究竟会选择什么样的策略,属于不完全信息博弈问题。
贝叶斯博弈是关于不完全信息博弈的一种建模方式,也是不完全信息博弈的标准式描述。本文要寻找AUV博弈对抗不完全信息下的目标分配最优策略,实际上就是求解不完全信息博弈下取得的贝叶斯纳什均衡。
在一个贝叶斯博弈过程G={I, T, P, S, U}中,局中人i(i∈I)的一个策略是从局中人i的类型集Ti到其策略集Si(Ti)的一个映射。
设Ui表示除了局中人i的其他局中人采用策略S-i时,局中人i在类型为Ti时,选择策略Si时的期望效用收益,则有
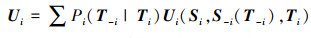
|
(1) |
式中:S-i(T-i)表示其他局中人在给定类型T-i时,策略S-i确定的行动组合。
在给定自己的类型和其他局中人类型的分布概率条件下,这种策略组合使得每个局中人的期望效用达到了最大。即,如果策略组合Si*(Ti)满足:
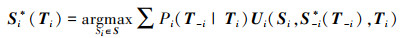
|
(2) |
则S*(Ti)=(S1*(T1), S2*(T2), …, Sn*(Tn))即为一个贝叶斯纳什均衡[10]。
本文以对抗双方的剩余生存概率和武器消耗量为评价指标,加入位置误差影响因子,建立了面向不完全信息的AUV博弈对抗目标分配模型。继而,以贝叶斯纳什均衡理论为基础,预先设置关于攻防策略类型的先验概率,选择出待分配的AUV类型,然后通过后验概率不断修正关于对方采用的目标分配策略类型的判断。
1.2 面向不完全信息的AUV目标分配模型的构建设不完全信息下的AUV博弈对抗目标分配模型用六元组集合描述,如(3)式所示
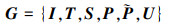
|
(3) |
I={A, D}为博弈局中人的空间,A为攻击方,D为防御方,这里的博弈空间中还引入了一个“自然(Nature)”作为虚拟参与人。
T={TA, TD}为AUV博弈对抗中A方和D方的目标分配策略类型空间。其中,TA为A方采取的策略类型集,TD为D方采取的策略类型集。TA对于攻击方A而言已知,但对于防御方D而言,其所选的策略类型为一个随机变量,即参与博弈对抗的局中人i(i∈I={A, D}),观测到“自然(Nature)”对于自己目标分配策略类型Ti的选择,而对于其他局中人选择何种策略类型局中人i并不知道。同理,TD对于防御方D而言已知,但对于攻击方A而言,其所选的策略类型为一个随机变量。但是,TA, TD的概率分布情况对于双方而言是共同知识,即局中人i(i∈I={A, D})具有其他局中人(用-i表示)选择类型的推断。
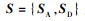
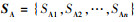

P={PA, PD}为参与博弈对抗的A、D双方对对方策略类型的初始判断概率,有
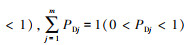
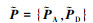
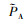

|
(4) |
式中:ShA(k)为A方在第k个战斗步之前的历史策略集合;SAi(k)为A方在第k个战斗步的策略;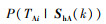

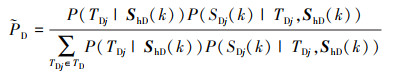
|
(5) |
式中:ShD(k)为D方在第k个战斗步之前的历史策略集合;SDj(k)为D方在第k个战斗步的策略。P(TDj|ShD(k))为D方在历史策略集ShD(k)的条件下, 对选取类型TDj的先验推断;P(SDj(k)|TDj, ShD(k))为D方在第k个战斗步时, 在采取历史策略集ShD(k)的前提下, 选取策略SDj(k)的概率。
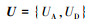
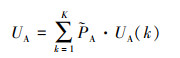
|
(6) |

|
(7) |
AUV博弈对抗目标分配一个战斗步的博弈树如图 1所示。

|
| 图 1 AUV博弈对抗目标分配一个战斗步的博弈树 |
从图 1可以看出, 在博弈对抗开始前, 引入了一个虚拟参与人, 我们称之为“自然”。它以PA1, PA2, …, PAn的概率对A方的AUV类型进行选择, 这个概率分布是A、D方的共同知识。接下来, 在A方选定类型下的AUV中选择合适的AUV对D方目标进行选择打击, D方在下一步观察到A方的攻击策略后, 对A方的类型进行概率修正, 并以此为基础对A方进行目标分配。双方就在这样的交互过程中完成目标分配策略的选择。
把AUV博弈对抗的目标分配过程看做是一个不完全信息的多阶段博弈过程, 整个博弈过程分为k个阶段, k∈N+, A方和D方关于目标分配的策略选择交互进行。在进行效用收益计算时, 如果第k个战斗回合的博弈结果达到了所在阶段的最优效果, 则该战斗回合的效用收益可以完全计入到博弈对抗的总效用收益, 即不存在博弈效用收益折扣。反之, 如果第k个战斗回合的博弈结果未达到所在阶段的最优效果, 则在计算博弈对抗的总效用收益时, 需要去除掉该战斗回合的效用收益折损, 即博弈效用收益具有折扣率。不失一般性, 本文中讨论的对抗双方在博弈过程中没有收益折扣, 即博弈收益没有折损。
定义决策变量δij来表征AUVi和目标AUVj之间的映射关系。攻击方的AUV编队由WA个AUV组成, 防御方的AUV编队由WD个AUV组成。即, 分配执行攻击任务的AUV总数量为WA, 分配执行防御任务的AUV总数量为WD。目标分配方案可以用决策向量矩阵δ表示, 分量δij=1时表示第i个AUV被分配给第j个攻击目标, δij=0时表示第i个AUV未分配给第j个攻击目标, 且满足
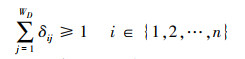
|
(8) |
选择敌方剩余威胁概率最小和AUV数量消耗最少作为评价目标分配策略效用收益的指标, 则第k个战斗回合下的目标分配策略效用收益为
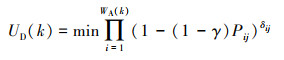
|
(9) |
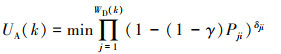
|
(10) |

|
(11) |
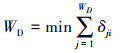
|
(12) |

|
(13) |

|
(14) |
UD(k)为第k个战斗回合对抗后D方的剩余生存概率, UA(k)为第k个战斗回合对抗后A方的剩余生存概率。WA为整个对抗过程中A方总的AUV消耗, WD为整个对抗过程中D方总的AUV消耗。WA(k)为第k个战斗回合时A方消耗的AUV数量, WD(k)为第k个战斗回合时D方消耗的AUV数量。KP是毁伤阈值。γ为位置误差影响因子, 定义为目标实际位置与探测到的位置的比值, 通过位置误差影响因子取值的不同, 来反映位置误差对AUV目标分配策略选择结果的影响。
2 不完全信息下目标分配贝叶斯纳什均衡策略求解本节针对不完全信息下AUV对抗目标分配的最优策略选择问题, 结合其离散化的特点, 在上述建立的不完全信息目标分配模型的基础上, 提出了以多目标离散粒子群为基础的面向不完全信息目标分配贝叶斯纳什均衡策略的求解算法。
AUV博弈对抗期间, 每个AUV被分配一次, 每个目标至少被一个AUV攻击。通过使用自然数编码的形式, 将自然数编码与分配给攻击目标的AUV编号相对应, 确立粒子与待求解目标分配策略之间的映射关系。每个粒子按照待攻击目标顺序排列的AUV标号组成, 其列向量上的数值与优化过程中分配给目标的AUV标号相对应。每个粒子都是一种可能的目标分配方案, 其长度等于待攻击目标的总数。
因为目标分配问题中的变量不具备连续的性质, 所以将适用于求解连续变量的基本粒子群算法中的粒子速度更新公式进行重新定义, 将粒子速度定义为粒子位置改变的概率[11], 使其适用于求解离散问题的情况。
粒子位置的更新由三部分组成, 分别为: 惯性部分、自我认知部分、社会认知部分, 如(15)式所示

|
(15) |
公式(15)中, ω→F1(Xik (t))为惯性部分, 表示粒子速度是一个以概率为ω的目标置换操作。
在进行目标置换操作时, 需引入一个中间变量Φ(t), 令Φ(t)=F1(Xik (t))。产生一个[0, 1]之间的随机数r1, 判断r1与ω之间的大小关系。若r1 < ω, 则对粒子进行置换操作。此时需要在[1, m]区间随机产生2个自然数a和b, 将a和b对应位置上的AUV标号进行互换。若r1≥ω, 则保持原粒子不变, 此时的Φ(t)为Φ(t)=Xik(t)。即
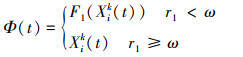
|
(16) |
粒子惯性部分位置置换过程如图 2所示。

|
| 图 2 粒子位置置换操作示意图 |
公式(15)中, 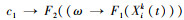
在进行目标交叉操作时, 需要引入第二个中间变量Ψ(t), 令Ψ(t)=F2(Φ(t), pid(t))。然后产生一个[0, 1]之间的随机数r2, 将r2与c1相比较, 如果r2 < c1, 则进行交叉操作。此时需要在[1, m]区间内随机产生2个自然数e和f, 将已经进行置换操作后的粒子e和f对应位置区间上的AUV标号与个体极值pi(t)中e和f对应位置区间上的AUV标号进行交叉操作。此时的Ψ(t)=F2(Φ(t), pid(t))。但如果r2≥c1, 则Ψ(t)=Φ(t)。即
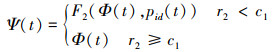
|
(17) |
粒子自我认知部分与个体极值的交叉过程如图 3所示。

|
| 图 3 粒子与个体极值的交叉操作 |
公式(15)中, c2→F3(c1→F2((ω→F1(Xik (t))), pid(t)), pg(t))为社会认知部分, 表示粒子的速度是一个以概率为c2的交叉操作, 粒子根据全局极值pg(t)调整自身的位置。令Xik+1 (t)=F3(Ψ(t), pg(t)), 产生一个[0, 1]之间的随机数r3, 将r3与c2相比较, 如果r3 < c2, 则进行交叉操作。此时需要在[1, m]区间随机产生2个自然数g和h, 将已经进行置换操作后的粒子Ψ(t)中g和h对应位置区间上的AUV标号与全局极值pg(t)中g和h对应位置区间上的AUV标号进行交叉操作, 此时Xik+1 (t)=F3(Ψ(t), pg(t))。但如果r3≥c2, 则Xik+1 (t)=Ψ(t)。即

|
(18) |
粒子社会认知部分与全局极值的交叉过程如图 4所示。

|
| 图 4 粒子与全局极值的交叉操作 |
在迭代过程中, pid(t)和pg(t)持续更新, 最终输出值pg(t)即为全局最优解。
算法程序流程图如图 5所示。

|
| 图 5 不完全信息下目标分配策略的贝叶斯纳什均衡求解 |
假设A方AUV编队由15艘攻击力不同的AUV组成,要对D方10个目标(这10个目标已经由传感器探测得到)进行攻击,按照毁伤能力的大小将AUV分为高杀伤性和低杀伤性2种类型。仿真参数如表 1所示。
| 参数 | 取值 |
| 毁伤阈值 | 0.9 |
| 初始高杀伤性类型AUV概率 | 0.5 |
| 初始低杀伤性类型AUV概率 | 0.5 |
| 外部种群入口阈值 | 25 |
| 交叉概率 | 0.82 |
| 变异概率 | 0.15 |
| 最大迭代次数 | 100 |
仿真中AUV的毁伤概率值是作为基础数据读取的,其取值不会对文中所提算法产生实质性影响。另外,由于获取实际的水下AUV毁伤概率参数存在较大困难,所以对本论文中的毁伤概率参数进行了模拟设定。设定每个AUV对不同目标的毁伤概率如表 2所示(表 2中上一行为A方对D方的毁伤概率,下一行为D方对A方的毁伤概率)。
| A方 | D方 | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 1 | 0.53 | 0.82 | 0.91 | 0.85 | 0.75 | 0.62 | 0.84 | 0.82 | 0.78 | 0.64 |
| 0.46 | 0.65 | 0.71 | 0.63 | 0.82 | 0.71 | 0.67 | 0.58 | 0.69 | 0.73 | |
| 2 | 0.76 | 0.81 | 0.91 | 0.75 | 0.91 | 0.78 | 0.80 | 0.64 | 0.60 | 0.83 |
| 0.87 | 0.92 | 0.82 | 0.78 | 0.84 | 0.69 | 0.75 | 0.82 | 0.79 | 0.64 | |
| 3 | 0.83 | 0.74 | 0.86 | 0.53 | 0.84 | 0.93 | 0.60 | 0.81 | 0.74 | 0.80 |
| 0.68 | 0.75 | 0.69 | 0.54 | 0.74 | 0.85 | 0.62 | 0.73 | 0.92 | 0.56 | |
| 4 | 0.43 | 0.75 | 0.84 | 0.62 | 0.73 | 0.75 | 0.54 | 0.68 | 0.67 | 0.85 |
| 0.83 | 0.81 | 0.92 | 0.84 | 0.86 | 0.83 | 0.60 | 0.78 | 0.65 | 0.67 | |
| 5 | 0.71 | 0.74 | 0.72 | 0.90 | 0.78 | 0.66 | 0.83 | 0.69 | 0.84 | 0.82 |
| 0.69 | 0.84 | 0.83 | 0.88 | 0.76 | 0.57 | 0.65 | 0.74 | 0.79 | 0.58 | |
| 6 | 0.82 | 0.60 | 0.56 | 0.92 | 0.57 | 0.73 | 0.62 | 0.87 | 0.75 | 0.64 |
| 0.56 | 0.58 | 0.61 | 0.84 | 0.74 | 0.65 | 0.57 | 0.63 | 0.82 | 0.75 | |
| 7 | 0.85 | 0.83 | 0.60 | 0.78 | 0.87 | 0.84 | 0.79 | 0.65 | 0.60 | 0.78 |
| 0.56 | 0.83 | 0.71 | 0.89 | 0.45 | 0.57 | 0.49 | 0.81 | 0.67 | 0.65 | |
| 8 | 0.81 | 0.72 | 0.62 | 0.91 | 0.88 | 0.67 | 0.78 | 0.90 | 0.84 | 0.58 |
| 0.51 | 0.62 | 0.91 | 0.87 | 0.52 | 0.65 | 0.84 | 0.93 | 0.86 | 0.75 | |
| 9 | 0.65 | 0.63 | 0.84 | 0.87 | 0.57 | 0.72 | 0.64 | 0.87 | 0.82 | 0.57 |
| 0.69 | 0.75 | 0.82 | 0.84 | 0.67 | 0.84 | 0.85 | 0.62 | 0.65 | 0.87 | |
| 10 | 0.83 | 0.84 | 0.88 | 0.80 | 0.73 | 0.72 | 0.87 | 0.78 | 0.91 | 0.67 |
| 0.59 | 0.67 | 0.79 | 0.75 | 0.83 | 0.77 | 0.81 | 0.90 | 0.87 | 0.85 | |
| 11 | 0.85 | 0.88 | 0.78 | 0.86 | 0.58 | 0.79 | 0.81 | 0.80 | 0.82 | 0.64 |
| 0.77 | 0.65 | 0.84 | 0.74 | 0.59 | 0.64 | 0.48 | 0.74 | 0.63 | 0.54 | |
| 12 | 0.84 | 0.87 | 0.89 | 0.67 | 0.84 | 0.89 | 0.56 | 0.75 | 0.64 | 0.85 |
| 0.82 | 0.69 | 0.71 | 0.75 | 0.68 | 0.86 | 0.74 | 0.84 | 0.76 | 0.83 | |
| 13 | 0.62 | 0.71 | 0.84 | 0.57 | 0.78 | 0.87 | 0.88 | 0.72 | 0.65 | 0.62 |
| 0.72 | 0.56 | 0.78 | 0.85 | 0.87 | 0.69 | 0.75 | 0.67 | 0.78 | 0.58 | |
| 14 | 0.93 | 0.85 | 0.79 | 0.67 | 0.83 | 0.81 | 0.64 | 0.85 | 0.84 | 0.86 |
| 0.69 | 0.84 | 0.81 | 0.75 | 0.85 | 0.62 | 0.79 | 0.75 | 0.86 | 0.57 | |
| 15 | 0.57 | 0.71 | 0.62 | 0.87 | 0.58 | 0.79 | 0.86 | 0.84 | 0.72 | 0.90 |
| 0.75 | 0.63 | 0.72 | 0.75 | 0.59 | 0.84 | 0.79 | 0.81 | 0.77 | 0.87 | |
在相同初始环境条件、不同种群规模和迭代次数下,采用基于MODPSO算法和基于NSGA-Ⅱ算法求解算例,分别运行50次后,得到的算法平均运行时间如表 3所示。
| 算法 | 迭代次数 | 种群规模 | ||
| 50 | 100 | 200 | ||
| MODPSO | 50 | 0.450 3 | 0.917 5 | 1.758 2 |
| 100 | 0.943 0 | 1.431 2 | 2.963 5 | |
| 200 | 1.473 3 | 3.189 3 | 5.987 2 | |
| NSGA-Ⅱ | 50 | 0.782 5 | 1.354 6 | 1.957 4 |
| 100 | 1.109 2 | 1.956 3 | 3.142 5 | |
| 200 | 1.562 9 | 3.201 7 | 6.563 1 | |
由表 3可以看出,在不同种群规模和迭代次数下,基于MODPSO算法的求解运行时间均小于基于NSGA-Ⅱ算法的求解运行时间。
在相同初始条件下,迭代次数都是100次时,采用基于MODPSO的算法和基于NSGA-Ⅱ的算法求解算例得到的适应度函数平均值曲线如图 6所示。

|
| 图 6 适应度函数平均值曲线 |
从图 6中可以看出,基于MODPSO算法的适应度函数平均值曲线在40代附近趋于收敛,基于NSGA-Ⅱ算法的适应度函数平均值曲线在40代处仍有下降趋势,尚未收敛。从求解快速性的角度上来讲,基于MODPSO的算法比基于NSGA-Ⅱ的算法更具优势。
不同种群规模下,分别采用2种算法得到的目标分配策略,A方和D方的剩余生存概率情况如表 4所示。(为了消除仿真模拟中的随机特性,对每种算法都进行了100次的独立试验,统计得到2种算法下对抗双方剩余生存概率的平均值)。
| 算法 | 种群规模 | ||
| 50 | 100 | 200 | |
| NSGA-Ⅱ | 0.253(A) | 0.259 (A) | 0.234(A) |
| 0.156(D) | 0.153(D) | 0.135(D) | |
| MODPSO | 0.173(A) | 0.189 (A) | 0.165(A) |
| 0.124(D) | 0.118(D) | 0.106(D) | |
由表 4可以看出,在不同种群规模下,基于MODPSO算法求解得到的A、D方的剩余生存概率值比基于NSGA-Ⅱ算法得到的A、D方的剩余生存概率值小,说明采用MODPSO算法得到的对抗双方目标分配策略方案对敌方的攻击力更强,对抗毁伤效果更好。由表 4中还可以看出,无论采用哪种算法,A方的剩余生存概率始终高于D方的剩余生存概率,因此,A、D双方的对抗结果为A方获胜。
3.2 贝叶斯纳什均衡解分布均匀性的SP测度评价SP测度是一种衡量所得到的非劣解在解空间均匀分布情况的指标。SP值越小,表明Pareto解分布越均匀。在群体规模为100,迭代次数为100的条件下,算法分别独立运行50次,SP测度值的统计结果如图 7所示:

|
| 图 7 帕累托最优解集的分布均匀性 |
由图 7所示的箱体图可以看出,基于MODPSO算法得到的箱体图区间比基于NSGA-Ⅱ算法得到的箱体图区间小。基于MODPSO算法得到的SP测度均值为0.040 6,方差为0.005 9,基于NSGA-Ⅱ算法得到的SP测度均值为0.070 3,方差为0.013 1。因此,基于MODPSO算法求解面向不完全信息的AUV对抗目标分配问题得到的Pareto最优解分布,相较基于NSGA-Ⅱ算法得到的Pareto最优解分布更加均匀和稳定。
3.3 位置误差对目标分配策略选择的影响1.2节中建立的面向不完全信息的目标分配模型中加入了位置误差影响因子,其值越大表示目标位置的测量值与实际值的偏差越严重。图 8给出了位置误差影响因子的取值在不同范围内,满足毁伤阈值0.9的条件下,对AUV对抗目标分配策略选择的影响。

|
| 图 8 不同位置误差影响因子下的AUV消耗 |
图 8中的横坐标为位置误差影响因子的变化情况,纵坐标为消耗的AUV数量。可以看出,当位置误差影响因子低于0.005时,其策略选择近似等于理想状态,此时分配10个AUV就可以达到作战预期。当位置误差影响因子在0.005~0.024 5时,需要增加AUV数量至12。当位置误差影响因子在0.024 5~0.027 4时, 需要增加AUV数量至14。当位置误差影响因子为0.027 5时,需要将编队中的15个AUV全部分配出去才能完成打击任务。若位置误差影响因子高于0.027 5时,即使将整个编队中的AUV全部分配对目标进行打击,也不能完成对目标的预期毁伤效果。位置误差影响因子取值越大,在进行目标分配时,达到同样的毁伤效果消耗的AUV数量越多。
4 结论本文对面向不完全信息博弈的AUV对抗目标分配决策问题进行了研究。把对抗双方看作博弈的局中人,将AUV对目标的映射关系作为局中人博弈可选的策略集合。基于贝叶斯纳什均衡的非合作博弈模型,建立了不完全信息下的AUV博弈对抗目标分配模型。根据AUV目标分配策略不连续的特点,提出了一种基于多目标离散粒子群的不完全信息目标分配贝叶斯纳什均衡策略的求解算法,用粒子位置代表目标的候选策略,将粒子速度定义为粒子位置改变的概率,以适应决策变量的离散特征。仿真结果表明,所建立的面向不完全信息的AUV博弈对抗目标分配模型能够较好地反映AUV的对抗局势,所得到的目标分配策略可以根据指挥官的决策偏好为其提供策略选择帮助。
| [1] |
欧峤, 贺筱媛, 陶九阳. 协同目标分配问题研究综述[J]. 系统仿真学报, 2019(11): 2216-2227.
OU Qiao, HE Xiaoyuan, TAO Jiuyang. Overview of cooperative target assignment[J]. Journal of System Simulation, 2019(11): 2216-2227. (in Chinese) |
| [2] |
武从猛, 王公宝. 遗传-蚁群算法在目标分配问题中的应用研究[J]. 兵工自动化, 2014, 33(4): 8-11.
WU Congmeng, WANG Gongbao. Application of genetic ant-colony algorithm in target assignment problem[J]. Ordnance Industry Automation, 2014, 33(4): 8-11. (in Chinese) |
| [3] | GLOTZBACH T, SCHNEIDER M, OTTO P. Cooperative line of sight target tracking for heterogeneous unmanned marine vehicle teams: from theory to practice[J]. Robotics and Autonomous Systems, 2015, 67: 53-60. DOI:10.1016/j.robot.2014.09.012 |
| [4] |
田伟, 王志梅, 段威. 基于随机时间影响网络的联合火力打击动态武器目标分配问题研究[J]. 指挥控制与仿真, 2020, 42(6): 38-46.
TIAN Wei, WANG Zhimei, DUAN Wei. Research on dynamic weapon target assignment problem in joint fire strike based on stochastic time influence network[J]. Command Control & Simulation, 2020, 42(6): 38-46. (in Chinese) |
| [5] | LI X, ZHOU D, PAN Q, et al. Weapon-target assignment problem by multiobjective evolutionary algorithm based on decomposition[J]. Complexity, 2018, 1: 1-20. |
| [6] | LIANG Hongtao, KANG Fengju. Adaptive chaos parallel clonal selection algorithm for objective optimization in WTA application[J]. Optik International Journal for Light and Electron Optics, 2016, 127(6): 3459-3465. DOI:10.1016/j.ijleo.2015.12.122 |
| [7] |
王玮, 刘兴林, 王军, 等. 信息化条件下海上编队区域防空目标分配方法[J]. 系统工程理论与实践, 2015, 35(4): 1011-1018.
WANG Wei, LIU Xinglin, WANG Jun, et al. Method of area antiaircraft weapon target assignment for the warship formation under informationized conditions[J]. Systems Engineering Theory & Practice, 2015, 35(4): 1011-1018. (in Chinese) |
| [8] | JIA Z, LU F, WANG H. Multi-stage attack weapon target allocation method based on defense area analysis[J]. Journal of Systems Engineering Electronics, 2020, 31(3): 539-550. |
| [9] |
朱弗登博格, 让梯若尔. 博弈论[M]. 北京: 中国人民大学出版社, 2010.
DREW Fudenberg, JEAN Tirole. Game theory[M]. Beijing: China Renmin University Press, 2010. (in Chinese) |
| [10] |
张彦革. 基于贝叶斯均衡和搜索算法的博弈模型研究[D]. 沈阳: 东北大学, 2010 ZHANG Yange. Research on game model based on bayesian equilibrium and search algorithms[D]. Shenyang: Northeastern University, 2010 |
| [11] |
叶文, 朱爱红, 欧阳中辉, 等. 基于混合离散粒子群算法的多无人作战飞机协同目标分配[J]. 兵工学报, 2010, 31(3): 331-336.
YE Wen, ZHU Aihong, OUYANG Zhonghui, et al. Multi-UCAV cooperation mission assignment based on hybrid discrete particle swarm optimization algorithm[J]. Acta Armamentarii, 2010, 31(3): 331-336. (in Chinese) |
2. School of Electronic Engineering, Xi'an Shiyou University, Xi'an 710065, China
