



水下目标检测在海军沿海防御任务以及渔业、水产养殖等海洋经济中发挥着重要作用。但由于水下环境复杂,水下光学图像存在严重的退化问题,影响了算法的检测精度与可靠性。所以如何有效地优化水下目标检测算法,使其满足水下环境的实际应用场景,提高对水下目标的检测精度,需要进一步研究。
基于传统图像处理的目标检测算法时间复杂度高、检测精度较低,难以满足检测需求。随着卷积神经网络的不断迭代,国内外研究人员提出了许多基于深度学习的目标检测算法,其具有时间复杂度低、检测精度高和泛化性强的特点。基于深度学习的目标检测算法主要分为2类:①基于回归思想的单阶检测算法;②基于生成候选区域的双阶检测算法。双阶检测算法首先从输入图像中提取候选区域,然后利用这些候选区域实现目标分类与位置修正,如R-CNN[1]、Fast R-CNN[2]、Faster R-CNN[3]、Mask R-CNN[4]等。单阶检测算法直接利用卷积神经网络从输入图像中进行目标分类和位置修正,如YOLO(you only look once)[5-7]系列算法和SSD(single shot multibox detector)[8]算法等。与双阶检测算法相比,单阶检测算法由于在进行目标分类和位置修正前无需生成候选区域,极大降低了模型的计算成本,具有较高的实时性,更能满足水下目标快速检测的需求,所以许多研究人员针对基于单阶检测的水下目标检测算法展开研究。赵德安等[9]基于YOLOv3算法结合图像预处理提高了河蟹的检测精度;高英杰[10]基于SSD算法利用深度分离可变形卷积模块进一步提高了水下目标的检测精度;刘萍等[11]基于YOLOv3算法利用GAN(generative adversarial networks)模型实现了海洋生物的识别。但该类算法没有充分利用水下目标的特征,而且当不同尺寸目标存在遮挡、重叠问题时检测精度不佳,仍存在漏检和误检的问题。
一般基于深度学习的目标检测算法在提取特征时采用相同的权重学习特征图,导致模型不能反映图像不同通道特征的重要性。文献[12]提出的注意力机制为各通道特征赋予不同的权重,有选择性地增强显著性特征,使获取的特征图具有更多的有效信息。Woo等[13]提出的CBAM(convolutional block attention module)算法,利用空间信息与通道信息学习得到2个独立维度的注意力特征图,将其与输入特征图相乘自适应地进行特征细化,提高了模型的鲁棒性。Hu等[14]提出的SE-Net (squeeze and excitation networks)算法,通过显式建模通道维度的相关性,提高了模型的检测精度。在复杂背景下的水下图像目标检测任务中,特征提取模块需要对检测目标边缘特征有选择性地突出,以进一步提高模型的检测精度,所以本文在特征提取模块中引入了通道注意力机制。
针对上述水下目标检测中存在的问题,本文提出了一种基于通道注意力与特征融合的水下目标检测算法,该算法通过3个方面提高水下目标的检测精度: ①设计了基于通道注意力的激励残差模块,在提取特征时通过显式建模卷积特征通道之间的相互依赖性,调节各通道的权重,使特征提取模块有选择地增强特征信息,提高了网络对特征的可分辨性,有助于网络的回归预测与分类训练,提高网络对水下图像高频信息的提取能力;②设计多尺度特征融合模块,实现浅层特征与深层特征的深度融合,提高特征图的利用率,融合后的特征具有丰富的细节信息与语义信息,提高网络对水下不同尺寸目标的检测精度;③设计基于拼接和融合的数据增强方法,对同一批次内的不同训练图像进行拼接和融合,模拟水下目标的重叠、遮挡和模糊情况,提高模型对水下环境的泛化性能。
1 水下目标检测算法本文提出的基于通道注意力与特征融合的水下目标检测算法包括特征提取模块(feature extraction module)和多尺度特征融合模块(multi-scale feature fusion module),整体网络结构如图 1所示。首先通过特征提取模块获得特征图,然后利用多尺度特征融合模块获得多个不同尺度的特征图,最后对特征图进行解码得到最终的检测结果。

|
| 图 1 基于通道注意力与特征融合的水下目标检测算法 |
为进一步提高水下目标的特征利用率,本文对YOLOv3检测算法中的特征提取模块DarkNet-53进行改进,设计基于通道注意力的激励残差模块,替代特征提取模块DarkNet-53中的部分残差块,提出基于通道注意力的特征提取模块SE-DarkNet-53,如图 1中虚线框所示。SE-DarkNet-53模块由卷积层、残差块和激励残差模块组成,使用激励残差模块作为第一层,并分别在4个残差块后添加激励残差模块。通过激励残差模块对通道间的相关性进行建模,增强卷积层的特征提取能力,增强后的特征被后续卷积层有效利用,进一步增加网络对特征信息的敏感性,提高特征利用率。对于输入的水下图像,SE-DarkNet-53特征提取的具体过程如下:
首先通过卷积层对输入的水下图像x进行特征提取, 获得特征图fd, 如(1)式所示
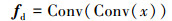
|
(1) |
式中,Conv表示卷积操作。
然后将获得的特征图fd输入基于通道注意力的激励残差模块(如图 2所示), 对获得的特征图的各通道分配权重, 突出不同通道特征图的显著性, 增强相关特征信息并抑制无关信息, 提高网络对特征的可分辨性。

|
| 图 2 基于通道注意力的激励残差模块 |
在基于通道注意力的激励残差模块中, 输入的特征图fd通过卷积层进行特征提取后获得特征图f, 如(2)式所示。

|
(2) |
特征图f将再经过4个步骤完成特征通道的权重分配[14]:
1) 特征图f通过Fsq(·)从空间维度压缩特征信息, 将各通道的特征信息转化为一个实数。通过(3)式所示的特征压缩过程可以得到统计量z∈RC, z的第c个元素计算方式如(3)式所示。
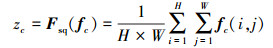
|
(3) |
式中:fc表示特征图f的第c个二维矩阵;下标c表示通道;H、W表示该特征图的高度和宽度;i, j表示在该特征图横纵坐标分别为i和j的点。
2) 通过激励操作Fex(·, W)为每个特征通道生成权重参数s, 权重生成过程为
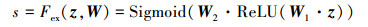
|
(4) |
式中: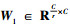
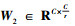
3) 通过特征加权操作Fscale(·, ·)将各特征通道的权重s与特征图f逐通道相乘, 实现特征图各通道的权重分配, 获得特征重标定的特征图, 记为fe。特征加权操作过程为
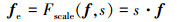
|
(5) |
4) 将特征优化后的特征图fe与输入特征图fd进行残差连接, 得到的特征图记为fE0, 残差连接操作如(6)式所示。
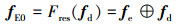
|
(6) |
式中:Fres(·)表示残差连接函数;⊕表示残差连接。
激励残差模块输出的特征图fE0将经过4组残差块和激励残差模块的组合, 各组合的输出结果为fE1, fE2, fE3, fE4, 每个阶段的输出分别输入到多尺度特征融合模块。残差块结构如图 3所示, 用Fresblock表示。对于每一组残差块和激励残差模块的组合, 输入特征图fE(i)经过残差块后得到特征图fr(i+1), 如(7)式所示。
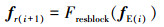
|
(7) |

|
| 图 3 残差块结构示意图 |
图 3中fE(i)为前一组激励残差模块的输出特征图, 首先fE(i)通过残差块, 输出特征图fr(i+1), 然后特征图fr(i+1)通过该组合中的激励残差模块进行特征提取, 并沿通道维度进行特征图的权重分配后获得特征图fE(i+1)。通过组合残差块和激励残差模块, 可以更好地拟合通道间的相关性, 使用全局信息来选择性地增强特征并缓解增加模型深度引起的梯度消失现象, 提高网络对水下图像细节信息的提取能力, 进而提高模型的检测精度。
1.2 多尺度特征融合模块对于小尺寸目标而言, 浅层特征包含它的一些细节信息。随着层数加深, 网络所提取特征中的细节信息会有不同程度损失, 此时通过深层特征检测小尺寸目标就变得很困难。因此, 为进一步增强模型对不同尺寸目标的检测性能, 本文提出了多尺度特征融合模块, 该模块设计了4种不同尺度的特征图用于检测水下图像中不同尺寸的目标, 如图 1中实线框所示。首先, 利用卷积块将特征提取模块获得的特征图fE4尺寸变为原图像的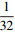

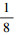
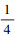

|
(8) |
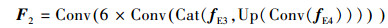
|
(9) |

|
(10) |
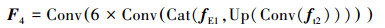
|
(11) |
式中:Conv表示卷积操作;Up表示双线性插值的上采样操作;Cat表示级联操作。
通过多尺度特征融合模块, 模型获得4种不同感受野的特征图, 这些特征图融合浅层特征的细节信息和深层特征的语义信息, 能够增强网络对不同尺寸目标的检测性能, 有效解决水下目标漏检、误检的问题。
1.3 数据增强海洋生物在单一图像中存在数量多且分布密集的现象, 如图 4所示。图中重叠是指相同类别的目标相互覆盖, 遮挡则表示不同类别的目标相互覆盖, 模糊是由于沉淀物与光照引起的。在分类任务中[15], 图像融合已被证明是有效的。自然图像分类中融合的关键思想是通过在训练图像之间进行像素融合, 增加训练样本的多样性, 进而提升网络的学习效果。受自然图像融合的启发, 本文设计了数据增强方法, 对训练样本进行像素融合的同时应用了有效的空间变换, 通过缩放和拼接图像的方式, 扩展了训练样本的分布。该数据增强方法使训练样本具有更加丰富的目标信息, 利于网络学习海洋生物在水下光学图像中常见的重叠、遮挡和模糊的现象。如图 5所示,该方法通过拼接4张不同的图像生成拼接训练样本, 然后进行图像融合生成融合训练样本。

|
| 图 4 海洋生物遮挡、重叠和模糊的情况 |

|
| 图 5 数据增强示意图 |
首先, 将4张不同图像进行缩放操作, 再将缩放后的图像依次按左上、左下、右下、右上放入矩形区域中, 以左上和右上的图像为例, 选取2张图像中长度最大且长度小于矩形最长边的图像, 将其固定, 再将另一张图像的长度裁剪为矩形最长边减去固定图像的长度, 宽度同理。拼接后的图像作为新的训练样本; 然后, 将该样本利用贝塔分布生成的融合系数进行图像融合[16-17], 生成的融合训练样本与原始训练样本尺寸相同。考虑到在训练时若全部使用生成的融合训练样本, 将造成网络无法学习正常水下环境中的目标, 导致检测效果较差, 本文使用阈值对融合训练样本进行控制, 生成训练样本时, 通过随机函数生成区间为[0, 1)的实数, 本文阈值设置为0.5, 当生成的实数大于等于0.5时生成普通训练样本, 反之生成融合训练样本。融合过程为
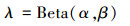
|
(12) |
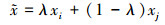
|
(13) |
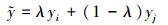
|
(14) |
式中:xi, xj是同一批次内不同的训练样本;yi, yj为样本对应的标签; λ是由参数为α, β的贝塔分布计算出来的融合系数;
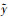
YOLOv3中使用的损失函数解决了目标分类与位置修正2个问题, 实现了端到端的检测, 同时加快检测速度, 故本文使用该损失函数, 如(15)式所示。
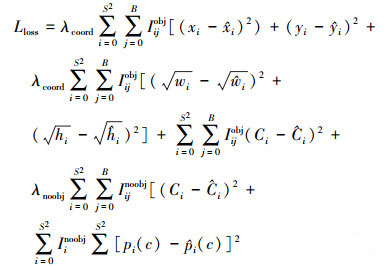
|
(15) |
式中:S表示图像的划分系数;B表示每个网格中所预测的预测框个数;C表示总类别数,c={0, 1, …, C};p表示类别概率;Iijobj表示第i个网格的第j个预测框是否负责预测该目标, 取值为0或1;Iijnoobj表示第i个网格的第j个预测框不负责预测该目标;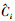

实验数据集使用URPC官网提供的水下光学图像数据集, 该数据集包括海参、海胆、海星和扇贝的水下图像以及对应图像的标注。URPC数据集共有37 463个目标标签, 海参类别目标5 246个、海胆类别目标19 458个、海星类别目标6 096个和扇贝类别目标6 663个。
2.2 实验环境及评价指标模型训练时采用的硬件平台是CPU为Intel(R)Xeon(R)Gold 5115 CPU @2.40 GHz, 内存为32 GB, GPU为NVIDIA TiTAN V 12 GB。软件平台为Windows7操作系统, 深度学习框架为Pytorch。模型训练时, 目标类别数为4, 输入图像尺寸为416×416, Batch-Size为8, Epochs为50, 初始学习率为10-3, 权重的衰减速率为5×10-4, 动量设置为0.9, 学习率调整策略为固定步长衰减, 迭代次数到达4×105与4.5×105时, 在前一个学习率的基础上衰减10倍。本文使用召回率、平均精度、平均精度均值以及单张图像推理时间来评估模型的有效性与实时性。
2.3 数据增强融合系数实验为验证数据增强方法的有效性, 测试不同Beta分布的融合系数在URPC数据集的性能, 本文使用7组不同的Beta分布进行实验, 使用URPC训练集与测试集进行训练与测试, 实验结果如表 1所示。
| 贝塔分布 | 平均精度均值 | 海参平均精度 | 海胆平均精度 | 扇贝平均精度 | 海星平均精度 |
| (0.2, 0.2) | 75.50 | 61.40 | 88.60 | 68.90 | 83.10 |
| (0.3, 0.3) | 74.28 | 58.30 | 88.40 | 67.70 | 82.70 |
| (0.4, 0.4) | 77.33 | 65.60 | 88.70 | 70.90 | 84.10 |
| (0.5, 0.5) | 77.13 | 65.10 | 88.80 | 70.30 | 84.30 |
| (0.6, 0.6) | 77.60 | 65.50 | 88.80 | 72.10 | 84.00 |
| (0.7, 0.7) | 76.03 | 61.80 | 88.70 | 69.10 | 84.50 |
| (1.5, 1.5) | 76.65 | 63.70 | 88.30 | 70.70 | 83.90 |
根据表 1结果可知, Beta(0.3, 0.3)效果最差; Beta(0.6, 0.6)的检测精度高于其他6组Beta分布, 相比Beta(0.2, 0.2)、Beta(0.4, 0.4)、Beta(0.5, 0.5)和Beta(0.7, 0.7)平均精度均值分别提高2.10%, 0.27%, 0.47%和1.57%;Beta(1.5, 1.5)所有类别平均精度均略低于Beta(0.6, 0.6), 相较于Beta(0.6, 0.6)平均精度均值下降0.95%。Zhang等[15]指出, 增加α, β的强度可以在训练样本的基础上生成更多的融合训练样本, 但这也使网络学习变得更加困难。随着α, β的增大, 真实数据上的训练误差增大, 泛化差距减小, 这隐式地影响了网络的学习效果。而且通过选择性实验可以看出, 当α, β=0.6时, 融合训练样本在网络训练时的训练误差与泛化差距保持相对平衡, 所以本文后续实验中数据增强方法融合系数设置为Beta(0.6, 0.6)。
2.4 实验结果分析为研究本文所提模型自身的特征提取能力、小目标检测性能和水下环境中的泛化性能, 首先针对不同模型进行消融实验, 然后和主流目标检测网络YOLOv4[18]与YOLOv5[19]进行对比实验。实验选取的基准模型为YOLOv3;模型1添加了激励残差模块; 模型2添加多尺度特征融合模块; 模型3添加激励残差模块和多尺度特征融合模块, 训练时未采用基于拼接和融合的数据增强方法; 模型4为本文模型, 训练时采用基于拼接和融合的数据增强方法。所有消融实验与对比实验基于URPC数据集进行测试, 模型的训练参数均相同。5种模型的消融实验结果如表 2所示。本文模型和网络YOLOv3、YOLOv4、YOLOv5的对比实验结果如表 3所示, 检测结果如图 6~7所示。
| 模型 | 平均精度均值/% | 召回率/% | 海参平均精度/% | 海胆平均精度/% | 扇贝平均精度/% | 海星平均精度/% | 推理时间/ms |
| YOLOv3 | 72.18 | 76.40 | 53.50 | 86.80 | 67.40 | 81.00 | 6.1 |
| 1 | 74.85 | 77.63 | 57.00 | 86.90 | 73.10 | 82.40 | 6.4 |
| 2 | 73.78 | 77.75 | 56.70 | 86.40 | 69.70 | 82.30 | 6.7 |
| 3 | 75.50 | 76.45 | 58.80 | 87.10 | 72.60 | 83.50 | 7.0 |
| 4 | 77.60 | 81.78 | 65.50 | 88.80 | 72.10 | 84.00 | 6.8 |
| 模型 | 平均精度均值/% | 召回率/% | 海参平均精度/% | 海胆平均精度/% | 扇贝平均精度/% | 海星平均精度/% | 推理时间/ms |
| YOLOv3 | 72.18 | 76.40 | 53.50 | 86.80 | 67.40 | 81.00 | 6.1 |
| YOLOv4 | 74.40 | 67.35 | 60.10 | 87.60 | 65.80 | 84.10 | 6.1 |
| YOLOv5 | 76.70 | 69.38 | 65.00 | 85.80 | 70.20 | 85.80 | 6.2 |
| 本文模型 | 77.60 | 81.78 | 65.50 | 88.80 | 72.10 | 84.00 | 6.8 |

|
| 图 6 目标密集的水下图像检测结果图 |

|
| 图 7 目标较小的水下图像检测结果图 |
从表 2可以看出, 模型1相比YOLOv3, 平均精度均值提高2.67%, 说明本文设计的激励残差模块突出了不同通道特征图的显著性, 提高了特征信息的相关性。模型2相比YOLOv3, 平均精度均值提高1.60%, 海参类别平均精度提高3.2%, 说明本文改进的多尺度特征融合模块能够有效融合细节信息及语义信息, 其包含的不同尺度特征图使模型能够准确地检测不同尺寸的水下目标。模型3相比模型1和模型2平均精度均值分别提高0.65%和1.72%。在不增加推理成本的情况下, 本文模型(模型4)相比未采用数据增强方法的模型3, 平均精度均值提高2.10%, 海参类别平均精度提高6.70%, 证明了基于拼接和融合的数据增强方法可以有效提高模型对水下环境的泛化能力。
从表 3可以看出, YOLOv4、YOLOv5相比YOLOv3, 平均精度均值分别提高2.22%与4.52%, 验证了其网络结构的优势性。本文模型相比YOLOv4与YOLOv5, 平均精度均值分别提高3.2%与0.9%, 在单类别平均精度中, 海参、海胆和扇贝目标的检测精度均优于YOLOv4和YOLOv5, 证明了本文模型对复杂的水下环境下出现的海洋生物目标具有较高的检测精度。本文模型通过激励残差模块, 在增强网络特征提取能力的同时缓解了网络层数较深时的梯度消失问题。同时, 通过多尺度特征融合模块与基于拼接和融合的数据增强方法, 利用其大尺度特征图具有较小感受野的特性与海洋生物频繁出现重叠与遮挡的现象, 使得网络在检测水下小尺寸目标时减少易出现的误检、漏检问题, 进一步提高了网络对水下环境中重叠、遮挡的海洋生物目标的泛化性能。
图 6a)和图 7a)标出的边界框均为真实标签框。图 6a)中共有40个目标且存在重叠、遮挡和模糊的情况, 进一步增加了检测难度。图 7a)中海胆尺寸较小, 并且由于水下环境的光照条件导致部分海胆目标较为模糊, 增加了检测难度。图 6和图 7的检测结果分别如表 4和表 5所示。
| 模型 | 海参/个 | 海胆/个 | 扇贝/个 | 海星/个 |
| 真实标签框 | 7 | 15 | 17 | 1 |
| YOLOv3 | 7 | 13 | 11 | 1 |
| YOLOv4 | 7 | 17 | 17 | 1 |
| YOLOv5 | 7 | 14 | 14 | 1 |
| 本文模型 | 6 | 16 | 16 | 1 |
| 模型 | 海参/个 | 海胆/个 | 扇贝/个 | 海星/个 |
| 真实标签框 | 0 | 9 | 0 | 0 |
| YOLOv3 | 0 | 4 | 0 | 1 |
| YOLOv4 | 0 | 8 | 0 | 1 |
| YOLOv5 | 0 | 7 | 0 | 0 |
| 本文模型 | 0 | 8 | 0 | 0 |
从图 6和表 4可以看出,在检测数量较多且存在重叠和遮挡的目标时,本文模型在水下复杂环境中获得了较准确的检测结果。对于海参目标,YOLOv3、YOLOv4与YOLOv5均检测到7个,而3种模型均出现误检的问题。相比之下,本文模型共检测到6个海参目标,仅漏检1个目标,无误检目标。对于重叠的海胆目标,YOLOv4共检测到17个,但存在误检多个海胆目标的情况,而本文模型仅误检1个,优于其他3种模型。对于扇贝目标,YOLOv4共检测到17个扇贝目标,但将检测结果和真实标签框对照,发现仍存在误检扇贝的情况,且4种模型均存在不同程度的漏检问题。而本文模型仅漏检1个扇贝目标,证明了本文模型对重叠和遮挡目标检测的有效性。
从图 7和表 5可以看出,在检测较为模糊的目标时,YOLOv3与YOLOv4均存在漏检海胆和误检海星的问题,YOLOv5漏检2个海胆目标,而本文模型仅漏检1个海胆目标,共检测到8个海胆目标,未出现误检目标的情况。综上所述,本文方法通过校对特征通道间的相关性,提高了网络生成特征的质量;通过多尺度特征融合模块与基于拼接和融合的数据增强方法,提高了网络对水下复杂环境下不同尺寸目标的检测精度。
3 结论本文提出一种面向于水下复杂环境的基于通道注意力与特征融合的水下目标检测算法,设计基于通道注意力的激励残差模块,改善通道之间的相关性,增强模型的表征能力;利用多尺度特征融合模块,有效地解决水下环境中小尺寸目标检测难的问题;通过基于拼接和融合的数据增强方法,增加训练样本的多样性,增强模型对水下环境的适应性。实验表明,本文算法与YOLOv3、YOLOv4和YOLOv5算法相比,平均精度均值分别提高了5.42%, 3.20%和0.9%,单类别平均精度最高提升了12.00%。本文算法在保证实时性的前提下,提高了水下目标的检测精度,下一步工作将继续研究高效的目标检测算法,使用轻量化注意力模块提高网络的特征提取能力,以应用于未来水下机器人的自主检测。
| [1] | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014 |
| [2] | GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015 |
| [3] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. Advances in Neural Information Processing Systems, 2015, 28: 91-99. |
| [4] | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017 |
| [5] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016 |
| [6] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017 |
| [7] | REDMON J, FARHADI A. Yolov3: an incremental improvement[EB/OL]. (2018-04-08)[2021-07-09]. https://arxiv.org/abs/1804.02767. |
| [8] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision, 2016 |
| [9] |
赵德安, 刘晓洋, 孙月平, 等. 基于机器视觉的水下河蟹识别方法[J]. 农业机械学报, 2019, 50(3): 151-158.
ZHAO Dean, LIU Xiaoyang, SUN Yueping, et al. Underwater crab recognition method based on machine vision[J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(3): 151-158. (in Chinese) |
| [10] |
高英杰. 基于"SSD"模型的水下目标检测网络设计与实现[J]. 电子世界, 2019, 566(8): 112-113.
GAO Yingjie. Design and implementation of underwater target detection network based on "SSD" model[J]. Electronic World, 2019, 566(8): 112-113. (in Chinese) |
| [11] |
刘萍, 杨鸿波, 宋阳. 改进YOLOv3网络的海洋生物识别算法[J]. 计算机应用研究, 2020, 37(增刊1): 394-397.
LIU Ping, YANG Hongbo, SONG Yang. Marine biometric identification algorithm based on improved YOLOv3 network[J]. Computer Application Research, 2020, 37(suppl 1): 394-397. (in Chinese) |
| [12] | JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks[J]. Advances in Neural Information Processing Systems, 2015, 28: 2017-2025. |
| [13] | WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision, 2018 |
| [14] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018 |
| [15] | ZHANG H, CISSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization[EB/OL]. (2018-04-27)[2021-07-09]. https://arxiv.org/abs/1710.09412 |
| [16] | YUN S, HAN D, OH S J, et al. Cutmix: regularization strategy to train strong classifiers with localizable features[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019 |
| [17] | LIN W H, ZHONG J X, LIU S, et al. Roimix: proposal-fusion among multiple images for underwater object detection[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, 2020 |
| [18] | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2021-07-09]. https://arxiv.org/abs/2004.10934 |
| [19] | GLENN Jocher. YOLOv5. Github Repository[EB/OL]. (2020-06-09)[2021-07-09]. https://github.com/ultralytics/yolov5 |
