



2. 西安邮电大学 电子工程学院, 陕西 西安 710121
基于卷积神经网络CNNs的智能算法已广泛应用到自动驾驶、智能监控和移动虚拟现实等领域。然而,此类智能算法在获得较高精度的同时,也具有极高的计算复杂度和巨大的参数量,导致采用对功耗和计算资源敏感的边缘计算设备实现此类算法时,通常无法满足实时性和低功耗的应用需求。因此本文将探索可适应于终端场景的高能效CNN加速器设计方法。
采用基于参数量化CNNs的轻量化方法可以极大降低神经网络的参数数量、访存量和计算复杂度[1],从而为将CNNs的计算任务映射到边缘计算设备上提供了可能。因为CNNs中不同层的冗余度存在很大差异,而基于混合精度量化策略可针对不同层的参数变化范围调整数据位宽,得到在保证量化精度操作情况下表示参数的最小数据位宽[2],从而确定最优的量化位宽。所以如果CNNs中各卷积层的参数均采用最优的量化位宽时,混合精度量化算法可在精度损失和压缩率之间达到最佳平衡。然而混合量化CNNs可能引入不规则的算法运算操作(如奇数位宽的乘法运算),而已有仅支持特定统一参数位宽或特定几种参数位宽的CNN处理器,由于未能最大限度地利用混合量化提供的计算并行度,阻碍了处理器性能进一步提升。因此需要设计可灵活且高效支持混合量化CNNs的运算操作,才能真正提高加速器针对混合精度CNNs的计算效率。
与此同时,由于CNNs具有丰富的计算并行性,可以增加计算单元的数量以提高计算并行度。然而混合量化CNNs中不同层的参数位宽会导致不同层之间的访存特性具有较大差异,如果采用固定的数据划分和访问模式[3],则会造成巨大的片上缓存资源浪费并增加数据移动量。如果将缓存不同类型参数的片上缓存区统一划分,并根据不同类型参数的存储需求来划分缓存区尺寸,则会提高片上存储器的利用率[4]。同时,由于CNNs邻近层之间的参数存在一定的关联性,如上一层卷积的输出特征图可能是下一层卷积的输入特征图,邻近层之间同类型的参数规模变化较小;同时,基于残差结构的CNNs通过跨层信息融合以提高精度,因此可通过设计灵活的参数访问模式以提高参数的复用性并减少数据移动量,从而提高计算效率。
不同CNNs的模型结构和计算模式均存在较大差异,并且不同应用场景可提供的计算资源及对处理器的性能和功耗等要求也不同。采用面向特定应用领域体系结构(domain-specific architectures, DSA)[5]和可重构计算技术方法,既可获得很高的效能又具备一定的灵活性,可以兼顾嵌入式智能终端系统对高性能、低功耗以及高灵活性的要求,从而满足应用场景对CNN处理器的可定制性和可扩展性要求。然而,随着可重构加速器灵活度的提高,其设计空间探索(design space exploration, DSE)的范围将变得十分巨大,因此需要一种可高层次表达CNNs和可重构平台特性的算法映射表达方法,以降低映射复杂度,提高可重构效率和处理器的通用性,从而可加速不同类型的CNN模型。
针对上述问题,本文采用软硬件协同优化和可重构计算方法,针对混合精度CNNs计算和访存特性,设计可支持混合位宽的可重构运算单元、可支持多种数据复用以及减少数据移动数量的缓存器,以及设计了一种表达混合CNNs计算、访存以及计算模式的宏指令集和可重构处理器架构。本文主要贡献如下:
1) 提出具有可定制性和可扩展性的CNN处理器架构,以及可有效表达混合精度CNNs模型计算的宏指令集(macro instruction set architecture, mISA)。通过高层描述被加速的CNNs模型计算、访存和控制等数据流特征,并设计对应的可重构处理器结构以提高计算效率。
2) 提出可支持混合位宽并行乘加运算的可重构微处理单元(reconfigurable micro-processing element, RmPE)和可重构多核计算引擎架构(compute engine, CE)。根据被加速的混合精度CNNs模型的结构特点和目标平台的资源限制,计算引擎通过重构阵列结构和数据流模式以提高计算资源利用率。
3) 提出可适应可重构CNNs计算特性的弹性片上数据缓存策略。通过动态配置地址及片上互联模式减少非必要数据移动的延时和功耗开销;通过基于Tile的动态缓存划分策略提高片上存储资源利用率。
1 相关工作为了满足不同CNN模型中各卷积层对于运算位宽的多样化需求,提高CNN加速器的计算效率,目前针对混合精度CNNs计算模式以及可重构CNN处理器体系结构方面开展了大量研究。
1.1 混合精度CNNs计算模式目前已有大量基于ASIC或可重构平台(如FPGA)的面向混合精度CNN加速器设计。Judd等[6]提出的Stripes处理器支持可变精度的激活数据,Lee等[7]提出的UNPU处理器支持可变精度的权重数据,但是2种架构都只支持一种运算数据位宽的改变,因此没有最大限度提高混合精度CNNs的计算效率;Sharify等[8]提出的Loom处理器采用串行乘法单元以支持多精度的卷积运算,然而由于需要并串转换电路,需要消耗大量芯片面积和功耗;Sharna等[9]提出的基于位级融合的Bit Fusion处理器,利用2 bit数据运算单元的融合和分解支持不同运算数据位宽,但是由于基础运算单元处理位宽的限制,对于存在较多非二次幂位宽参数的混合精度CNNs,该架构的加速效率会受到限制。
虽然基于ASIC的方法可通过定制化运算单元实现混合精度CNNs模型加速, 但是此类方法无法应用到基本运算单元固定的可重构平台,如基于DSP的FPGA等。已有基于FPGA的CNNs加速器通常采用匹配CNNs模型中最大的数据位宽的计算模式,所以对于量化后存在大量低数据位宽的CNNs则无法充分利用FPGA平台中的DSP等计算资源,从而降低了加速器的计算效率,因此需要一种自适应多精度计算的高效处理单元。为了提高FPGA平台针对低数据位宽运算的并行度,可将多个低位宽数据合并为一个高位宽数据,通过复用DSP以提高计算并行度[10],其能够根据不同运算位宽调整运算并行度,但是运算单元的并行度受到符号位的限制, 无法充分复用DSP资源。
1.2 可重构CNNs处理器体系结构虽然CNNs具有计算类型较少并且计算流程固定的特点,但是不同CNNs或是同一模型中的不同卷积层的数据流和数据访存等方面具有不同的特性。已有学者提出基于模板或自动化设计方法[11-14],此类方法首先对算法和可重构平台的资源进行抽象描述,然后通过优化算法确定加速器体系结构和具体可重构配置的参数。如Ma等[11]首先设计了可实现CNNs运算的基本操作单元库,然后通过自动化地组合不同运算单元以适应不同的CNNs模型;Wei和Guo等[12-13]分别提出了基于性能和计算资源利用率约束的自动化设计优化方法,从而提出针对不同CNNs的计算效率。然而此类方法的优化策略复杂度将随着搜索空间的增加而快速提高,因此当CNNs模型复杂度较高时,通常很难得到最优的处理器的体系结构和映射策略。同时,Azizimazreah等[14]通过配置和重构“物理”基本单元,构建“逻辑”运算单元和缓存单元,从而降低重构延时并提高加速器的可定制性和可扩展性,然而其直接将各卷积运算转换为可重构加速器的配置信息,因此映射复杂度较高。
2 面向混合CNNs的可重构处理器 2.1 可重构CNNs处理器结构为了提高CNNs的运算效率,本文设计了一种可支持混合精度运算的多核处理器,结构如图 1所示。由支持可变精度的卷积、激活、池化等操作的计算引擎,可支持弹性划分与动态重组的缓存单元以及可支持乱序发射的控制单元组成,而计算数据和控制数据通过片上总线接口单元与外部完成数据交换。

|
| 图 1 可重构CNN处理器架构 |
其中,控制单元(command engine, CMDE)包含指令存储、PC寻址单元、寄存器堆以及译码单元,通过PC访问指令存储,经译码模块产生相应的控制信号,进而控制片上数据通路和数据缓存。计算引擎由用于完成特定特征图tile块卷积运算的二维RmPE阵列,以及用于池化和激活等标量运算的专用计算单元组成。片上弹性缓存包含多个相互独立的存储块(bank),通过专用Crossbar总线将弹性缓存与计算引擎中对应的数据缓存单元连接起来。
2.2 宏指令集设计为了将不同结构混合精度CNNs高效地映射到可重构计算平台,根据CNNs中计算类型较少并且计算流程固定的特点,本文提出一种控制通路简单、可提高数据级并行度的宏指令集。该指令集由10条32 bit指令组成,指令字段划分方式如图 2所示,根据32 bit数据表示的含义将其细分为3个字段:功能,寄存器和参数。其中,由4 bit数据组成的function表示指令类型,由10 bit数据组成的registers表示用于控制计算过程的变量或索引,而由18 bit数据组成的parameters表示如量化的CNN模型的特征等信息。指令集分为4类:配置、运算、访存和循环控制。配置指令(config_*)用于实现在每个卷积层运算前对该层的存储划分以及计算特性描述;运算指令compute用于启动tile级运算;访存指令load/store控制计算引擎与弹性存储之间的数据交互,循环控制指令add、beq、jmp负责控制计算任务的循环过程。

|
| 图 2 宏指令集格式 |
该宏指令包含2个32 bit通用寄存器,用于缓存特征图块的索引,并暂存一些标量数据,例如用于循环控制的变量值。如图 2所示,r1(a)表示参数a存储在寄存器r1中,r1(a/b)表示参数a或b存储在寄存器“r1”中,寄存器r2以类似的方式起作用。宏指令的参数(parameters)用于配置或控制可重新配置的计算引擎和弹性片上缓冲区。例如,根据存储单元阵列的行和列中的RAM数量,特征图的通道数,填充的大小以及相关的缓冲区类型,使用“bank_config”来配置划分缓冲区方法等。表 1列出了宏指令集中各参数缩写的含义。
| 参数缩写 | 含义 |
| K_size | 卷积核的大小 |
| Padding | Tile化过程中填充的数据量 |
| Stride | 卷积步长 |
| I_width/O_width | 输入特征值/输出特征值的数据位宽 |
| W_width | 权重的数据位宽 |
| P_size | 池化核的大小 |
| P_stride | 池化步长 |
| Pool | 池化操作的类型 |
| A_method | 激活操作的类型 |
| B_row/B_col | 缓存阵列的宽/高 |
| Tif/Tof | 在通道维度分块后的输入特征图/输出特征块数量 |
| Tiy | 一个Tile块的高度 |
| W/I/O | 缓存区用于缓存权重/输入特征图/输出特征图 |
| Tile_channel | tile_config中配置r1寄存器的立即数 |
| Tile_row | tile_config中配置r2寄存器的立即数 |
| K/T | 在通道/行维度划分后特征图数量 |
| W/F | 缓冲区用于缓存权重/特征图 |
| m/n | 输出/输入特征图的块索引号 |
| PM | 输出通道方向的计算并行度 |
| C/A/P | 计算类型为卷积/激活/池化 |
| k/t | 权重块/特征块的块索引号 |
| Imm | 立即数 |
| PC | 程序存储器地址 |
混合精度量化算法通过调整不同卷积层中特征值和权重的位宽,以实现CNNs的精度和压缩率之间最优平衡。其量化后的CNNs各层的参数位宽量为确定值,因此根据乘法分割原理,将多个低位宽数据拼接为一个高位宽数据运算的模型可表达如(1)式所示, 其中x为乘数位宽, y为被乘数位宽, p为并行度,b为乘法器的最大运算位宽。在确定可重构平台中的乘法器位宽后, 可利用(1)式确定特定运算数据位宽和乘法操作的最大并行度。
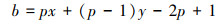
|
(1) |
根据上述并行乘法的分析, 结合已有可重构计算资源的特性(如FPGA平台中的DSP), 本文设计可支持2~8 bit内任意精度并行乘加运算的可重构微处理单元(reconfigurable micro-processing element, RmPE), 其架构如图 3所示。RmPE内部采用权重复用的计算模式, 可根据输入特征和权重的位宽确定运算并行度, 并且通过控制编码与解码操作动态可重构RmPE单元。并行输入特征与权重在运算并行度的控制下分离符号位与数据位, 数据位输入乘法运算单元进行并行乘法运算, 符号位输入异或门进行符号计算。不同运算并行度下解码出的乘法运算结果输入对应累加器, 对卷积过程中的部分和进行累加, 而计算出的符号位则会作为累加器执行加法或减法运算的标志。卷积运算结束后, 累加结果统一截断至8 bit以降低激活运算的复杂度。

|
| 图 3 RmPE架构 |
为了适应不同类型的混合精度CNNs的数据位宽, 本文通过定义RmPE中对应的可重构参数, 从而可根据不同混合精度量化网络模型定制计算单元的规模, 在提升计算性能的并提高计算资源利用率, 表 2列举了RmPE中的可重构参数及其含义。
| 参数名 | 描述 |
| #IWPE | RmPE的输入宽度, 其大小可表示为DSP最大运算并行度与对应输入特征数据位宽的乘积 |
| #IWDSP | DSP输入运算数据位宽 |
| #OWDSP | DSP输出运算结果位宽 |
| #Pm | DSP乘法运算并行度最大值 |
| #OWPE | RmPE的输出宽度, 其大小为8倍的计算并行度 |
本文采用文献[11]提出的计算单元组织方式, 根据被加速的混合精度CNNs模型的结构特点和目标平台的资源限制, 将多个RmPE组成的二维阵列构成计算引擎(compute engine, CE)。计算引擎的整体设计如图 4所示, 包括采用阵列结构的卷积运算单元和串行处理卷积结果的池化和激活单元。计算引擎采用流模式处理运算数据, 计算流程中的数据通路选择由控制单元管理, 卷积运算单元从输入缓存和权重缓存中读取数据进行卷积运算, 产生的并行卷积结果通过重组, 以串行数据流模式输入激活或者池化单元, 最终运算结果以并行方式存入输出缓存。

|
| 图 4 计算引擎硬件结构 |
由于RmPE在卷积处理单元中按照阵列方式进行排列, 因此可通过调整阵列结构以适应不同混合精度CNNs模型的计算特性。如图 4的虚线框中给出的nPEx, nPEy以及nPEz分别表示计算阵列的3个维度。可根据被加速的混合精度CNNs的结构特点和目标平台的资源限制, 通过重构阵列结构和数据流模式以提高计算资源利用率。
4 面向弹性缓存的重构与划分机制为了解决卷积运算不同类型数据在混合精度CNNs各层间存储量差异巨大的问题, 本文采用文献[14]提出的弹性存储结构(elastic buffer, EB), 将片上存储单元划分为多个独立的bank, 不再设有特定的输入缓存、权重缓存以及输出缓存, 只提供对应的数据输入输出接口, 接口数目根据加速系统中计算引擎的数目定制, 以保证数据访问并行度。在每层运算开始前, 控制器根据各bank的状态和bank划分策略, 以动态重组的方式将bank指定为特定的计算引擎缓存单元。计算引擎通过待运算数据的索引(如特征图的tile编号等)访问对应的bank。其中卷积计算单元中的输入、输出、权重数据按照图 5所示的方式进行tile划分。在图 5a)中, 输入和输出特征数据的tile在行方向上的尺寸等于特征图宽度, 在列方向上的尺寸决定了tile的组数, 每组包含全部输入或输出通道, 计算过程中, tile的划分方式会随着运算量的改变而改变, 因此弹性存储内部以特征图尺寸对特征数据进行存储, 以支持不同tile尺寸的重构。图 5b)中权重块在行方向上的数据量对应该层单个卷积核的数据量, 列方向的尺寸对应输入通道的分组, 每组包含全部输出通道的卷积核。

|
| 图 5 tile划分方法 |
为了简化存储单元的重构逻辑, 片上数据存储位宽采用4 bit和8 bit模式, 通过多个bank的组合即可实现不同tile尺寸的重构, 以输入特征数据为例, 行和列方向上的bank数目可分别表示为Nbankr=C×IWf/Wbank和Nbankc=R×N/Hbank, 因此在每层运算前, 通过Nbankr和Nbankc即可确定该层的输入特征数据的存储划分方式。
弹性存储需要根据计算引擎中RmPE阵列的nPEx, nPEy以及nPEz 3个维度进行重构, 以减少计算引擎因等待数据引起停顿, 从而提高计算单元的利用率。因此, 构建输入特征存储区域的存储块在位面方向的数目需要匹配nPEz, 从而为RmPE阵列提供nPEy行的并行输入; 构成权重以及输出特征存储区域的存储块在位面方向的数目需要匹配nPEz, 从而满足RmPE阵列在输出通道方向上的并行度。
5 验证与分析 5.1 建立验证系统本文选择经典CNNs-VGG-16和包含残差结构并且结构复杂的ResNet-50, 验证本文提出的混合精度CNNs可重构处理器性能。采用文献[2]提出的混合精度量化算法量化VGG-16和ResNet-50模型, 量化参数位宽变化范围及准确率如表 3所示, 其中准确率为针对ImageNet数据集的图像分类结果。从表 3可以看出量化后网络模型的精度损失均小于1%, 2种网络量化后的权重位宽分布在2~8 bit之间。同时, 根据文献[15]对于激活数据量化敏感度分析, 激活值量化位宽的改变会对网络准确率造成很大影响, 因此在混合精度量化后的ResNet-50和VGG-16网络中, 激活数据的位为特定几种数据位宽, 其中针对VGG-16模型选择4或8 bit, 而针对ResNet-50模型选择4, 6或8 bit。
| 模型 | 权重位宽/bit | 激活值位宽/bit | 原始模型准确率/% | 量化后模型准确率/% |
| VGG-16 | 2~8 | 4、8 | 71.7 | 71.6 |
| ResNet-50 | 2~8 | 4, 6, 8 | 76.1 | 75.2 |
根据nPEx方向上对RmPE数目的分析, 卷积处理单元在3个方向上的尺寸共有4种可能性, 按照(nPEx, nPEy, nPEz)的方式标记, 分别为(4, 7, 12), (5, 7, 10), (6, 7, 8), (7, 7, 7), 因此需要为2种混合精度网络各设计4种卷积处理单元进行性能比较, 为了方便描述, 依照CNNs模型以及卷积处理单元在nPEx方向上的尺寸对加速器分别标记为: ResNet4, ResNet5, ResNet6, ResNet7。表 4展示了针对混合精度ResNet-50模型, 本文设计的4种结构的混合精度CNN加速器, 在Ultra96-V2开发板上的计算吞吐率、计算效率、推理延时以及资源使用量等。其中计算性能最优的是ResNet4, 其计算性能和计算效率分别达到了219.56 GOPS和0.653 GOPS/DSP, 其吞吐率甚至超过了使用更多计算单元的ResNet5, 并且在DSP数量相同的情况下, ResNet4的计算性能要优于ResNet6, 这是由于混合精度ResNet-50模型在nPEx方向上的计算并行度处于饱和状态, 不需要很多RmPE即可在特征的行方向上获得较高的并行计算能力。然而, 针对运算并行度不高的模型(如VGG-16), 不同类型计算阵列在特征行方上的并行计算能力差别不大, 因此可通过减少nPEx并增加nPEz来提高计算效率。可以看出, 针对特定的混合精度CNN模型, 可通过改变计算阵列在不同维度的尺寸和对应的片上缓存划分策略, 达到最优的计算效率。然而, 针对不同类型的混合精度CNN模型, 则需要不同的重构方法才能获得最优性能。
| RmPE阵列结构 | ResNet4 | ResNet5 | ResNet6 | ResNet7 |
| DSP | 336(93%) | 350(97%) | 336(93%) | 343(95%) |
| LUTs/kB | 51.25(74%) | 53.04(77%) | 51.28(74%) | 52.01(75%) |
| FFs/kB | 78.01(57%) | 81.22(58%) | 78.02(56%) | 79.56(57%) |
| BRAMs/36kB | 210(97%) | 212(98%) | 212(98%) | 202(93%) |
| 运算次数/GOP | 8.24 | 8.24 | 8.24 | 8.24 |
| DSP数量 | 336 | 350 | 336 | 343 |
| 推理延时/ms | 37.53 | 38.28 | 42.15 | 44.79 |
| 计算性能 | 219.56 | 215.26 | 195.49 | 183.97 |
| 计算效率 | 0.653 | 0.615 | 0.582 | 0.536 |
本文设计的混合精度CNNs处理器与其他FPGA平台的加速器[10-14]的对比结果如表 5所示。其中存储资源部分的Xilinx FPGA采用36 kB的存储块, 而Intel FPGA采用20 kB的存储块; 表中的DSP资源的Xilinx FPGA的DSP运算位宽为27×18 bit, Intel FPGA的DSP运算位宽为18×18 bit; 表中逻辑资源的Xilinx FPGA为LUTs, Intel FPGA为ALMs。为了公平地对比性能, 表 5中所有的计算性能均在batch size为1时测得。本文的混合精度CNN处理器在计算性能方面, 比使用了更多DSP资源的固定位宽加速器[13]提高了111.4 GOPS, 同时可获得更高的准确率。文献[11-12]使用与本文类似的脉动阵列结构加速卷积运算, 当FPGA上的DSP资源用量处于饱和状态时, 虽然本文的混合精度CNN处理器在片上资源较少的Ultra96-V2平台上的计算性能较低, 但是在计算效率方面分别提高了3.2倍和1.6倍, 说明本文提出的并行计算单元RmPE对计算效能的提升作用。同时, 将本文提出的可重构CNNs处理器映射到片上资源较多的ZCU102平台上, 针对ResNet-50网络的计算性能可达913.8 GOPS, 计算效率达到0.40, 其性能和计算效率均高于文献[11], 说明了本文提出的处理器具有较好的可扩展性和可定制性。文献[10]使用了与本文类似的并行乘法单元加速混合精度CNNs, 在吞吐率和计算效率方面均优于其他设计, 而本文利用分离符号位与使得本文的混合精度CNN处理器在DSP的使用效率方面相较于文献[6]提高了6.7%。
| 加速器 | [10] | [11] | [12] | [13] | [14] | 本文 | ||
| FPGA | Virtex7 VC709 |
Aria 10 GX 1150 |
Aria 10 GT 1150 |
Zynq XC7Z030 |
Virtex-7 485T |
Ultra96-V2 | Ultra96-V2 | ZCU102 |
| 频率/MHz | 200 | 240 | 232 | 150 | 150 | 150 | 150 | 200 |
| CNNs | VGG-16 | ResNet-50 | VGG-16 | VGG-16 | VGGNet-D | VGG-16 | ResNet-50 | ResNet-50 |
| 检测精度 | - | - | - | 67.7% | - | 71.6% | 75.2% | 75.2% |
| DSP | 2877(80%) | 3036(100%) | 3000(99%) | 400(100%) | 2800(100%) | 343(95%) | 336(93%) | 2315(92%) |
| BRAMs | 1765(60%) | 2356(87%) | 1668(61%) | 203(77%) | 7275(89%) | 54.5(40%) | 204(97%) | 743(82%) |
| 计算性能 | 1713.0 | 599.6 | 1171.3 | 105.2 | 809.0 | 216.6 | 214.0 | 931.8 |
| 计算效率 | 0.59 | 0.20 | 0.39 | 0.26 | 0.29 | 0.63 | 0.64 | 0.40 |
为了解决将基于混合精度CNNs的智能算法在已有通用计算平台上实现,无法满足终端设备对实时性和低功耗的应用需求的问题。本文设计了支持多精度并行乘加运算的可重构微处理单元,可根据混合CNNs模型结构重构多核处理器。根据不同混合精度CNNs定制片上资源,在计算过程中重构计算单元并行度和片上缓存单元的划分方式,提高处理器的计算效率。本文设计的CNN处理器在Ultra96-V2上推理VGG-16和ResNet-50时计算性能分别达到216.6和214 GOPS,计算效率为0.63和0.64 GOPS/DSP,实现了对嵌入式硬件平台上计算资源的高效利用。
| [1] | ZHAO R, HU Y, DOTZEL J, et al. Improving neural network quantization without retraining using outlier channel splitting[C]//International Conference on Machine Learning, 2019 |
| [2] | WANG K, LIU Z, Lin Y, et al. HAQ: hardware-aware automated quantization with mixed precision[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019 |
| [3] | MA Y, CAO Y, VRUDHULA S, et al. Performance modeling for CNN inference accelerators on FPGA[J]. IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems, 2019, 39(4): 843-856. |
| [4] | AZIZIMAZREAH A, CHEN L. Shortcut mining: exploiting cross-layer shortcut reuse in DCNN accelerators[C]//2019 IEEE International Symposium on High Performance Computer Architecture, 2019 |
| [5] | HENNESSY J, PATTERSON D. A new golden age for computer architecture: domain-specific hardware/software co-design, enhanced[C]//ACM/IEEE 45th Annual International Symposium on Computer Architecture, 2018 |
| [6] | JUDD P, ALBERICIO J, HETHERINGTON T, et al. Stripes: bit-serial deep neural network computing[C]//2016 49th Annual IEEE/ACM International Symposium on Microarchitecture, 2016 |
| [7] | LEE J, KIM C, KANG S, et al. UNPU: an energy-efficient deep neural network accelerator with fully variable weight bit precision[J]. IEEE Journal of Solid-State Circuits, 2018, 54(1): 173-185. |
| [8] | SHARIFY S, LASCORZ A D, SIU K, et al. Loom: exploiting weight and activation precisions to accelerate convolutional neural networks[C]//2018 55th ACM/ESDA/IEEE Design Automation Conference, 2018: 1-6 |
| [9] | SHARMA H, PARK J, SUDA N, et al. Bit fusion: bit-level dynamically composable architecture for accelerating deep neural network[C]//2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture, 2018: 764-775 |
| [10] | YIN S, TANG S, LIN X, et al. A high throughput acceleration for hybrid neural networks with efficient resource management on FPGA[J]. IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems, 2018, 38(4): 678-691. |
| [11] | MA Y, CAO Y, VRUDHULA S, et al. Automatic compilation of diverse CNNs onto high-performance FPGA accelerators[J]. IEEE Transations on Computer-Aided Design of Integrated Circuits and Systems, 2018, 39(2): 424-437. |
| [12] | WEI X, YU C H, ZHANG P, et al. Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs[C]//Proceedings of the 54th Annual Design Automation Conference, 2017 |
| [13] | GUO K, SUI L, QIU J, et al. Angel-eye: a complete design flow for mapping CNN onto embedded FPGA[J]. IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems, 2017, 37(1): 35-47. |
| [14] | AZIZIMAZREAH A, CHEN L. Polymorphic accelerators for deep neural networks[J]. IEEE Trans on Computers, 2022, 71(3): 534-546. DOI:10.1109/TC.2020.3048624 |
| [15] | DONG Z, YAO Z, ARFEEN D, et al. HAWQ-v2:hessian aware trace-weighted quantization of neural networks[J]. Advances in Neural Information Processing Systems, 2020, 33: 18518-18529. |
2. School of Electronic Engineering, Xi'an University of Posts and Telecommunication, Xi'an, 710121 China
