



2. 中国电子科技集团公司第二十八研究所 信息系统工程重点实验室, 江苏 南京 210007
随着互联网发展,网络上的文本资源越来越丰富,结构化的信息和知识更易于管理和使用,为此构建出了大规模的开放域知识库,比如Freebase[1]、Depdia[2]和PkuBase。通常,采用三元组的形式表示知识库中的知识,形如〈entity, predicate, entity〉,其中entity表示特定实体,predicate表示实体间的关系。知识库中包含大量的三元组,它们构成了一张庞大的关系图。面向知识库的智能问答是一个典型应用场景,被广泛应用于搜索引擎、智能聊天等实际领域中[3]。在面向知识库的问答系统中,查询一个以自然语言描述的问题,系统会在知识库中搜索对应的三元组,之后给出准确的答案。知识库问答包括2个子任务:①实体链接:检测出问题中的实体并链接到知识库中的特定实体;②关系检测:检测出问题中提及的关系(链)。关系检测步骤的准确率将会直接影响问答的质量。针对关系检测,以往的工作大致分为两类:将关系检测建模为分类任务;将关系检测建模为文本序列匹配任务。
将关系检测建模为分类任务[4-10]。知识库中会预定义一个关系集,基于分类的关系检测方法将每个关系视为一个类别,通过给问题分类确定与问题相关联的核心关系。例如文献[7]使用词汇映射的方法进行关系检测。之后文献[9]提出一种使用多通道卷积神经网络(CNN)提升分类方法的模型。基于分类的方法进行关系检测时不依赖于实体链接的结果,上一步骤的误差不会传递到这一步骤,但此类方法无法利用关系的语义信息,近年的研究中基于文本序列匹配的方法逐渐成为主流。
基于文本序列匹配的方法通过计算问题和关系的相似度,选择相似度最高的关系作为问题关联的核心关系。现有的方法大致可以分为2类:编码-比较型和交互型。基于编码-比较的方法先将输入问题和关系表示为向量序列,之后通过聚合操作将序列转化为定长的向量,使用一种距离计算公式来度量相似度,作为问题和关系的最终匹配得分[11-16]。例如文献[11]将关系视为单个标签,使用TransE学习的向量进行初始化。文献[12]提出的MCCNNs方法使用多通道CNN生成问题表示向量。文献[13]指出从多个粒度表示关系(关系粒度和词序列粒度)可以提升关系检测效果,提出的模型HR-Bi-LSTM利用双向长短期记忆网络(Bi-LSTM)学习不同层次的问题表示和不同粒度的关系表示。基于交互型的方法则假设文本的匹配度依赖于词级别局部的匹配度,先构建交互矩阵,之后对交互矩阵进行抽象表示,最后计算问题和关系的匹配得分。文献[17]提出的交互型方法使用注意力机制计算问题和关系的交互矩阵,之后利用多核CNN抽取特征计算相似度得分。由于关系自身存在语义,建模为文本序列匹配的模型可以识别出一些未见关系。
然而,文本匹配的关系检测方法存在如下问题:基于编码-比较的方法更重视全局语义信息,在聚合操作(最大池、平均池)将向量序列变为单个向量会丢失一部分文本的语义信息;基于交互的方法假设文本相似度基于序列局部相似度,因此交互型模型无法由局部匹配刻画全局信息,此类方法缺乏对全局语义的理解。
针对现有模型没有兼顾全局语义信息与局部语义信息的问题,本文提出一个新的关系检测模型,通过融合问题和关系的全局语义、局部语义信息进行关系检测,捕获多样化的特征来计算问题和关系的匹配度,提升关系检测精度。该模型主要分为2个部分:局部相似度度量模块和全局相似度度量模块。BERT[18]作为整个模型的文本编码层,获得问题和关系的向量化表示,局部相似度度量模块基于注意力机制,得到关系和问题之间的相似度权重后,使用Bi-LSTM分析差异,最后使用多层感知机计算Q-R局部相似度。全局相似度计算模块则使用BERT获得的句向量,将问题和关系句向量的余弦值作为Q-R的全局相似度。最终的匹配度等于全局相似度和局部相似度加权后的和。在广泛使用的SimpleQuestion和WebQSP数据集上评估所提出模型的性能,并与仅计算全局相似度或者仅计算局部相似度的模型进行对比分析,以验证本文提出的模型在关系检测任务上的有效性。
1 基于多语义相似性的关系检测模型 1.1 问题定义图 1为关系检测的步骤图,下面给出关系检测的形式化描述。

|
| 图 1 关系检测步骤图 |
给出知识库和一个问题,基于知识库的问答的第一步会检测出问题对应的实体,得到实体集合后,从知识库的三元组中选出与实体相联系的候选关系集合Cr={r1e1, r2e1, …, r|rn|en}, 简记为Cr={r1, r2, …, r|C|}。其中, ri表示候选关系集Cr中的一个关系(链), 在简单的问答数据集中表示单个关系,在复杂的问答数据集中表示关系路径(从问题中的实体到知识库中实体的关系路径可能为单个关系,也可能为关系链)。第二步为关系检测, 关系检测的目标是检测出与问题相关度最高的关系(链), 也即是说, 选出问题关联的核心关系(链)

|
(1) |
式中, S(ri, q)表示关系r和q的匹配得分, 也即是模型的计算目标。
1.2 关系检测模型本节将会详细描述关系检测模型的4个模块: 文本编码层, 全局相似度度量模块、局部相似度度量模块和整体输出层。每一模块的作用如下:
1) 文本编码层:使用BERT作为整个模型的文本编码层,将问题和关系中的每个标签转换为向量,该向量含有标签的上下文信息。BERT模型会在输入的文本前添加特殊的[CLS]标签,由于[CLS]标签自身无实际意义,在训练中能够学习到输入文本的全局语义信息,所以对应的向量可以作为文本的句向量使用。
2) 全局相似度度量模块: 使用BERT得到的句向量, 计算问题和关系句向量的余弦值作为全局相似度。
3) 局部相似度度量模块: 使用Soft Attention计算问题和关系之间的注意力加权, 而后使用Bi-LSTM提取差异, 最后使用多层感知机计算局部相似度。
4) 整体输出层: 输出最终的相似度计算结果。模型结构如图 2所示。

|
| 图 2 关系检测模型结构 |
1) 关系表示层
通常, 从词级别和关系级别来表示一个关系(链), 假设模型此时正在处理含有|r|个关系的关系链r={r1, …, r|r|}, 关系的表示为
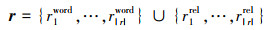
|
(2) |
式中, riword表示单个关系ri中的词部分, rirel表示单个关系ri中关系名称部分, 在本次研究中, 关系链中关系数量|r|≤2, 将所有标记的总数量记为|R|。以WebQSP中的一个关系链为例,关系链为{r1=film, r2=character_ note},将其表示为{film, character, note}∪{character_ note}={film, character, note, character_ note}。为了方便记录, 将上述关系表示记为r={r1, …, r|R|}。
2) 问题表示层
问题表示为词序列, 将问题中所有标记的总数量记为|Q|, 则问题q={w1, w2, …, w|Q|}。
3) BERT
使用预训练语言模型BERT将句子转换为向量序列, BERT首先从输入的文本数据中得到3个向量: 标记嵌入、位置嵌入和段嵌入。此外, 由于后续需要文本的句向量进行计算, 使用BERT的[CLS]和[SEP]标签。
1) 标记嵌入:使用BERT词表将输入BERT的每个标签转为定长向量, 得到标记嵌入。
2) 段嵌入:在BERT中用于区分不同的句子, 由于BEMSM的输入为单句, 所以这个值全设为0。
3) 位置嵌入:为了得到输入序列的顺序信息, BERT对出现在不同位置的词分别附加一个不同的向量用来区分。
问题序列q={w1, …, w|Q}和关系序列r={r1, …, r|R|}加上[CLS]和[SEP]标签, 变为q={w[CLS], w1, …, w|Q|, w[SEP]}和r={r[CLS], r1, …, r|R|, r[SEP]}后, 经过BERT结构, 输出为
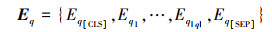
|
(3) |
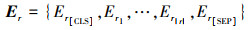
|
(4) |
这一模块的目的是计算问题和关系的全局相似度, 在训练过程中, BERT的[CLS]标签对应的向量通过学习包含句子的全局信息, 可以作为句向量使用。使用问题和关系的[CLS]标签对应的输出向量来计算全局语义相似度, 得到
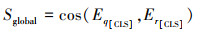
|
(5) |
局部相似度度量模块的目的是计算问题序列和关系序列的局部语义相似度。注意力机制的加入使该模块能够注意输入文本的局部语义信息。该模块输入为文本编码层的输出部分Eq和Er。其中Eq∈ 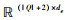
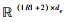
1) 局部差异提取:
之后, 进行局部差异提取, 局部差异提取层的目的是分析2个序列Q=(q1, …, q|Q|+2)与R=(r1, …, r|R|+2)的关联程度, 对Q中的每个词qi, 计算qi和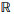
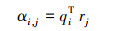
|
(6) |
利用Softmax公式计算Q关于R的注意力加权值, 以及R关于Q的注意力加权值, 得到
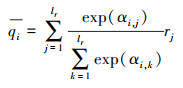
|
(7) |
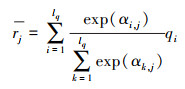
|
(8) |
得到文本编码层的输出Q和R, 以及注意力加权后的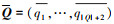

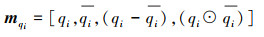
|
(9) |

|
(10) |
式中: -表示逐元素减法; ⊙表示逐元素乘法; mqi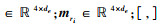
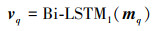
|
(11) |
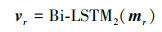
|
(12) |
式中, 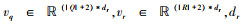
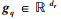

2) 局部相似度计算层:
差异计算层的输入是差异提取层输出的2个特征序列gq和gr, 目的是计算问题和关系的局部相似度
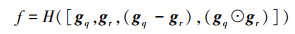
|
(13) |
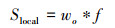
|
(14) |
式中: H代表一个3层的感知机; 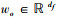
计算最终关系和问题的匹配得分, 权重由对比实验得出, 对比了全局相似度, 局部相似度权重分配为(0.25, 0.75), (0.5, 0.5), (0.75, 0.25)以及自动分配的结果, 最终选定(0.75, 0.25)这组权重为最终的分配
|
(15) |
为了验证模型有效性, 在SimpleQuestions和WebQSP数据集上进行实验, 相关的关系检测数据集在文献[20]和文献[13]中发布, 数据集的相关信息见表 1, 为了表示方便, 在后续将提出的模型记作BEMSM。
| 数据集 | 训练/验证/测试集规模 | 源知识库 | 关系数量 |
| SQ | 72 238/10 309/20 609 | Freebase | 6 701 |
| WebQSP | 3 116/-/1 649 | Freebase | 4 536 |
SimpleQuestions(SQ)[21]是一个简单问答数据集, 其关系检测数据中的每个问题只与知识库的一个三元组相关, 也就是说, 关系链的长度等于1。
WebQSP(WQ)[7]是一个复杂问答数据集, 包含的问题可能与知识库中的多个三元组相关, 数据集中包含的关系链长度小于等于2。
模型的超参数设置见表 2, 在实验中, BERT作为整个模型的文本编码层, 语言模型使用的是Google官方提供的预训练模型BERT-Base, 由12层的transformer编码结构组成, 隐藏层向量维度为768维, BERT模型包含1亿多参数量,输出词向量维度为768维。由于大部分关系名称不在BERT词表中, 需要扩展BERT的原始词表, 表中添加形如“place_ of_ birth”的关系名, 对应的向量为关系名包含单词向量的均值。训练模型时, 先训练只有全局相似度度量模块的模型, 之后, BEMSM加载BERT训练后的权重, 这部分权重不再更新, 后续继续训练10个epoch。将问题和关系的最大句子长度设置为30, 超过30的部分会被舍弃, 长度不足30的序列用0进行填充, 经过BERT处理后, 问题和关系的序列长度为32。在每个Bi-LSTM层后设置dropout, 防止模型过拟合。
| 参数类型 | 参数值 |
| BERT模型隐藏层维度 | 768 |
| LSTM的隐藏层 | 256 |
| LSTM层数 | 1 |
| 多层感知机每层参数 | [256, 128,64] |
| Dropout参数 | 0.3 |
| 批大小 | 64/32 |
| 学习率 | 2×10-5 |
| Loss函数中的边界阈值 | 0.1 |
| 句子最大长度 | 30 |
为了评估BEMSM模型在关系检测任务上的有效性, 沿用之前关系检测工作采用的评价指标, 使用精确率P来衡量模型的结果:
|
(16) |
式中: N是测试集中问题的数量; Nc是被准确识别出关系的问题数量。
2.3 实验结果 2.3.1 局部相似度模块和全局相似度模块的影响本实验的目的在于验证BEMSM模型中局部相似度度量模块和全局相似度度量模块对于整个模型的影响。
为了验证各个模块的效果,将BEMSM与单独的全局相似度度量模块、单独的局部相似度度量模块对比。除此之外,还对比使用GloVe词向量和Bi-LSTM为文本编码层的模型,在初始化时,不在GloVe词表中的词的向量从均匀分布(-0.5, 0.5)中随机采样生成,在训练过程中词嵌入层不更新。局部相似度度量模块和全局相似度度量模块的影响如表 3所示。
| 文本编码层 | 设置 | SQ/% | WebQSP/% |
| GloVe+Bi-LSTM | 全局相似度模块 | 92.74 | 84.60 |
| GloVe+Bi-LSTM | 局部相似度模块 | 93.56 | 84.29 |
| GloVe+Bi-LSTM | 全局+局部 | 93.70 | 85.75 |
| BERT | 全局相似度模块 | 93.69 | 85.81 |
| BERT | 局部相似度模块 | 93.74 | 85.99 |
| BERT | BEMSM | 93.92 | 87.81 |
从表 3中的数据可以看出,综合学习问题和关系的局部信息和全局信息对关系检测任务是有效的,单一的局部相似度度量模块和全局相似度度量模块得到的指标都低于综合模型,在WebQSP数据集上差异更明显, BEMSM模型获得精确率为87.81%,高于仅考虑全局相似性的85.81%和局部相似性的85.99%。
使用BERT作为文本编码层的模型所表现的性能也要优于GloVe词向量结合Bi-LSTM的文本编码层,使用BERT的所有模型准确率都有提升。在综合模型上,使用BERT模型的指标分别提升了0.2%和2.06%,这得益于BERT充足的预训练过程和优秀的表征能力,BERT能捕捉Bi-LSTM容易忽视的长距离依赖,进一步增强了关系检测模型的识别能力。
2.3.2 注意力机制对BEMSM模型的影响本实验的目的是验证注意力机制对模型的影响。由于全局相似度模块没有使用注意力信息,所以在局部相似度度量模块中分析注意力影响。将局部相似度度量模块与去掉注意力权重的模型进行对比实验。将注意力矩阵中的值设置为1来消除注意力的影响。同样在基于BERT的模型和基于GloVe结合Bi-LSTM的模型上进行上述实验。实验结果如表 4所示。
| 文本编码层 | 设置 | SQ/% | WebQSP/% |
| Bi-LSTM | 去注意力 | 93.15 | 82.41 |
| Bi-LSTM | 局部相似 | 93.56 | 84.29 |
| BERT | 去注意力 | 93.14 | 84.78 |
| BERT | 局部相似 | 93.74 | 85.99 |
从表中数据可以看出,去掉注意力权重的影响后,基于GloVe结合Bi-LSTM的模型和基于BERT的模型的准确度指标都有小幅度下降,在WebQSP数据集上更为明显(84.29%和82.41%, 85.99%和84.78%)。WebQSP数据集中,问题和关系的序列长度更长,注意力机制使模型能够将注意力关注到语义最相关的地方,所以影响更为明显。本文模型去掉注意力权重后,由于差异提取层不只依赖于注意力机制产生的结果,模型仍然能取得不错的效果。
2.3.3 模型整体表现将模型与近年的几个基准进行比较,这些基准属于基于文本序列匹配的关系检测方法,模型的输出为问题和关系的相似度得分,实验结果见表 5。
| 模型 | 关系输入粒度 | SQ/% | WebQSP/% |
| Bi-LSTM | words | 91.2 | 79.32 |
| BiCNN | char-3-gram | 90.0 | 77.74 |
| HR-Bi-LSTM | words+relations | 93.3 | 82.53 |
| ABWIM | words+relations | 93.5 | 85.32 |
| DAM | words+relations | 93.3 | 84.10 |
| BEMSM | words+relations | 93.9 | 87.81 |
1) BiLSTM:使用2个Bi-LSTM分别表示问题和关系,将最后一个时间步的输出作为句向量来比较相似度。
2) BiCNN[22]:使用3-gram表示问题和关系,比如“who”表示为#-w-h,w-h-o,h-o-#。使用CNN作为编码层,池化后计算相似度。
3) HR-Bi-LSTM[13]:使用词序列+关系名表示关系,使用HR-Bi-LSTM得到问题的抽象层次,将问题表示和关系表示通过聚合操作固定为相同维度向量后,将它们之间的余弦值作为相似度。
4) DAM[14]:基于transformer结构的模型,使用transformer结构得到关系和问题表示,经过聚合操作后,计算向量余弦值作为相似度得分。
5) ABWIM[17]:使用词序列和关系名来表示关系,通过注意力机制将问题和关系软对齐,之后使用CNN计算相似度得分。
BEMSM模型整体表现的实验结果见表 5,从实验对比结果可以看出,在SimpleQuestion数据集上,提出的模型取得了与基线相似的准确度,在WebQSP上,提出的方法比最好的基线方法高2.49%。实验结果验证了模型的有效性,BEMSM模型使用BERT作为文本编码层,可以捕捉到Bi-LSTM未能捕捉的长距离依赖,之后综合学习问题和关系的全局语义信息和局部语义信息进行关系检测,可以更全面地计算语义相关性,性能要优于只计算单语义信息的基线方法。
3 结论针对现有的关系检测方法无法兼顾问题、关系间全局语义和局部语义信息的问题,提出了一种基于多语义相似度的关系检测模型。该模型将BERT作为整个模型的文本编码层,使用Soft Attention和Bi-LSTM进行局部相似度计算;使用距离计算公式度量问题和关系句向量的全局相似度。最后综合这2种相似度得到整体的相似度。在SimpleQuestions和WebQSP基准数据集上进行实验,分析局部对比相似度模块和全局相似度模块的效果、注意力机制的效果以及模型整体效果,验证了BEMSM模型的有效性。
| [1] | BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, 2008 |
| [2] | LEHMANN J, ISELE R, JAKOB M, et al. DBpedia-A large-scale, multilingual knowledge base extracted from wikipedia[J]. Semantic Web, 2015, 6(2): 167-195. DOI:10.3233/SW-140134 |
| [3] |
徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J]. 电子科技大学学报, 2016, 45(4): 589-606.
XU Zenglin, SHENG Yongpan, HE Lirong, et al. Review on knowledge graph techniques[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589-606. (in Chinese) DOI:10.3969/j.issn.1001-0548.2016.04.012 |
| [4] | KWIATKOWKSi T, ZETTLEMOYER L, GOLDWATER S, et al. Inducing probabilistic CCG grammars from logical form with higher-order unification[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010 |
| [5] | LIANG P. Lambda dependency-based compositional semantics[EB/OL]. (2013-09-17)[2021-06-07]. https://arxiv.org/abs/1309.4408 |
| [6] | BERANT J, LIANG P. Semantic parsing via paraphrasing[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014 |
| [7] | BERANT J, CHOU A, FROSTIG R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013 |
| [8] | YAO X, VAN B. Information extraction over structured data: question answering with freebase[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014 |
| [9] | XU K, REDDY S, FENG Y, et al. Question answering on freebase via relation extraction and textual evidence[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016 |
| [10] |
胡宝顺, 王大玲, 于戈, 等. 基于句法结构特征分析及分类技术的答案提取算法[J]. 计算机学报, 2008, 31(4): 662-676.
HU Baoshun, WANG Daling, YU Ge, et al. An answer extraction algorithm based on syntax structure feature parsing and classification[J]. Chinese Journal of Computers, 2008, 31(4): 662-676. (in Chinese) DOI:10.3321/j.issn:0254-4164.2008.04.012 |
| [11] | DAI Zihang, LI Lei, XU Wei. CFO: conditional focused neural question answering with large-scale knowledge bases[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016 |
| [12] | DONG Li, WEI Furu, ZHOU Ming, et al. Question answering over freebase with multi-column convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2015 |
| [13] | YU Mo, YIN Wenpeng, HASAN K S, et al. Improved neural relation detection for knowledge base question answering[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 2017 |
| [14] | CHEN Yongrui, LI Huiying. DAM: transformer-based relation detection for question answering over knowledge base[J]. Knowledge-Based Systems, 2020(201): 106077. |
| [15] |
张仰森, 王胜, 魏文杰, 等. 融合语义信息与问题关键信息的多阶段注意力答案选取模型[J]. 计算机学报, 2021, 44(3): 491-507.
ZHANG Yangsen, WANG Sheng, WEI Wenjie, et al. An Answer selection model based on multi-stage attention mechanism with combination of semantic information and key information of the question[J]. Computer Science, 2021, 44(3): 491-507. (in Chinese) |
| [16] | QIU Yunqi, LI Manling, WANG Yuanzhuo, et al. Hierarchical type constrained topic entity detection for knowledge base question answering[C]//Companion Proceedings of the Web Conference, 2018 |
| [17] | ZHANG Hongzhi, XU Guandong, LIANG Xiao, et al. An attention-based word-level interaction model for knowledge base relation detection[J]. IEEE Access, 2018, 6: 75429-75441. DOI:10.1109/ACCESS.2018.2883304 |
| [18] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems, 2017 |
| [19] | MOU Lili, MEN Rui, LI Ge, et al. Natural language inference by tree-based convolution and heuristic matching[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016 |
| [20] | YIN Wenpeng, YU Mo, XIANG Bing, et al. Simple question answering by attentive convolutional neural network[C]//The 26th International Conference on Computational Linguistics, 2016 |
| [21] | BORDES A, USUNIER N, CHOPRA S, et al. Large-scale simple question answering with memory networks[EB/OL]. (2015-06-05)[2021-06-07]. https://arxiv.org/abs/1506.02075 |
| [22] | YIH T, CHANG Mingwei, HE Xiaodong, et al. Semantic parsing via staged query graph generation: question answering with knowledge base[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015 |
2. Science and Technology on Information Systems Engineering Laboratory, the 28th Research Institute of China Electronics Technology Group Corporation, Nanjing 210007, China
