



传统的推荐系统方法有基于协同过滤, 通过分析用户的历史交互数据, 猜测他们可能的共同爱好[1]。但是该方法有着冷启动和稀疏矩阵的问题。研究人员提出了许多解决方法, 譬如结合知识图谱、社会网络[2], 通过融合侧面信息到矩阵中填补一定的数据空缺, 但还是有较大的局限性。
在推荐系统中, 基于知识图谱的推荐方法有基于嵌入的方法和基于路径的方法。2016年Zhang等人提出了协同知识库嵌入(CKE)方法, 他将协同过滤模型与嵌入结合[3]。2018年Wang等人提出的深度知识感知网络(DKN), 他将实体嵌入和词嵌入分为2个不同的频道, 设计1个CNN模型将其结合[4]。2014年Yu等人提出了异构信息网络方法[5], 2017年Zhao等人提出了基于元图的推荐方法[6]。两者都是通过创建异构信息网络, 基于网络的潜在特征, 从中抽取元路径或者元图, 来代表用户和项目之间的关系。Wang等人同时结合基于嵌入和路径的方法提出了RippleNet[7]。Wang模拟水波纹传播方式, 对用户偏好进行模拟, 得到了非常好的效果。但RippleNet没有考虑到限定域知识图谱中的实体权重, 导致该模型无法得到不同权重实体的推荐结果, 没有将推荐重点放在重要程度较高的实体上, 从而降低了推荐准确度。
在复杂网络科学中, 国内外学者对节点传播能力的评估进行了大量研究, 目前常用的方法有度中心性[8]、介数中心性[9]、紧密度中心性[10]等。为了解决这个问题, 本文将运用复杂网络科学的方法, 把知识图谱中三元组的实体抽象为节点, 关系抽象为连边, 计算出复杂网络中实体的节点影响力, 并将其作为实体权重再放入RippleNet网络中进行计算。
1 联合复杂网络的Cn-RippleNet算法 1.1 构建基于知识图谱的复杂网络本文使用RippleNet中的电影和书籍知识图谱[7], 这个图谱数据文件是一个纯文本文件, 构成该文件的数据是实体——关系——实体的三元组。以电影知识图谱为例, 构建电影图谱复杂网络时, 将所有实体抽象为为网络的节点, 实体之间的关系作为连边, 表示节点之间的关联。建立的电影图谱复杂网络是一种无向非加权网络, 具有如下特征:
1) 网络规模巨大, 包含169 366个节点和333 543条边, 因此建立非加权网络以减少计算复杂度, 便于特征分析。
2) 只描述实体与实体之间的关联及关联间的距离, 忽略关系的方向。
因为以知识图谱构建的网络不一定是全连通网络, 导致某些节点无法参与计算其节点影响力, 所以需要消除冗余, 计算出电影知识图谱的最大连通子网。这里本文使用丁连红老师的基于集合运算的子网抽取算法(SNESO)[11]。该方法将电影知识图谱文件Graph作为输入, 经过子网抽取算法得到其输出最大连通子网的节点集合MaxSubNet。
算法过程如下:
1) 从电影知识图谱Graph中抽取1条拥有最大度值节点的三元组信息, 将三元组中的2个实体作为中心节点, 也就是作为最大连通子网的中心层SubNeti(这时i=1), 将此中心层加入MaxSubNet。
2) 寻找SubNeti集合的相邻节点, 即遍历Graph中的三元组(head, relation, tail), 判断其中的head, tail是否存在于SubNeti集合中。如果存在, 则表示对应head或者tail是集合SubNeti的相邻节点, 将这些相邻节点加进相邻节点集NeighborsSeti中。
3) 对比NeighborsSeti集和MaxSubNet集, 查看NeighborsSeti中是否有新的节点并不存在于MaxSubNet集中, 如果存在这样的节点, 则将NeighborsSeti并入MaxSubNet。并将SubNeti用NeighborsSeti与MaxSubNet的差集替换掉, 作为新的SubNeti, i=i+1。跳转到步骤2)。如果不存在新的节点, 则进行步骤4)。
4) 返回MaxSubNet。
此算法的关键步骤是对Graph三元组的遍历。从中心层出发, 每一次的遍历Graph, 都会得到当前层节点的所有相邻节点。由于度值较大的节点存在于最大连通子网的概率更高, 因此从度值最大的节点入手, 找到最大连通子网的概率更高。
找到最大连通子网的所有实体, 即MaxSubNet之后, 再根据MaxSubNet从电影知识图谱文件Graph中提取出最大子网的边的集合, 并且存储在GraphLink中, 最后由MaxSubNet和GraphLink生成如图 1所示结构的最大连通子网, 存储格式依然是三元组形式。可以看见, 中心层是由2个点构成, 层层扩散, 2个点的相邻实体作为第二层, 第二层的相邻实体作为第三层, 层层递归得到整个子网, 直到没有新的相邻实体为止。

|
| 图 1 最大连通子网的模型结构 |
节点影响力是指在复杂网络中对所有节点进行建模分析, 对网络中具有影响力或重要的节点进行排序。一个复杂网络通常包含有重要节点, 并且少部分重要节点一般都能影响网络中的大部分节点。在不同网络中, 研究人员都会从不同尺度、方向和实验条件下建立节点影响力的测量指标, 并尽量用最精确和快速的方式找到最有影响力的节点, 并对其进行排序[12]。
本文用已构建的最大连通子网作为一个复杂网络, 对所有三元组的节点进行影响力计算。本文分别使用使用度中心性方法[8]介数中心性[9]、紧密度中心性[10]对电影知识图谱网络的节点影响力进行计算, 寻找电影知识图谱中相对影响力较大的节点, 并从实验结果中分析哪种方法更加有效。
在度中心性中, 节点的度值是指连接某节点的其他节点的数量。度中心性则是根据单个节点度值大小和节点的总数来计算, 节点度值越大, 则度中心性也越大。在限定域知识图谱中, 大多数网络的度分布为幂律分布, 所以少数节点的度值较大, 而大量的节点度值较小。因此, 使用度中心性进行节点影响力计算, 能够准确区分不同度值的节点, 并赋予差异较大的权重。
由于以电影知识图谱构成的网络为无向网络, 因此具体计算公式如下
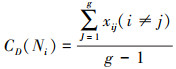
|
(1) |
在总数g为的节点所构成的无向网络中, 单个节点i的度中心性使用CD(Ni)表示。最终得到的结果是一个比例, 范围在0.0~1.0之间。0.0表示其与任何一个节点都没有关系, 1.0表示与每一个节点都有直接关系。计算出知识图谱网络中所有节点的度中心性后, 将其对应在图谱中的实体上, 采用字典存取方式保存, 记为C。介数中心性和紧密度中心性的保存方法同上。
1.3 联合复杂网络Cn-RippleNet模型RippleNet是模拟水波纹的传播方式, 以用户点击历史为种子, 并在限定域知识图谱上使用种子为初始点向外一圈一圈地扩散开来, 这个过程称为用户的偏好传播。该模型认为种子外圈的项目依然属于用户的潜在偏好, 因此在刻画时也要将其考虑。以下是对RippleNet模型进行改进的地方:
Cn-RippleNet的整体框架如图 2所示, 通过上部分实验得到当前Hop的Ripple set三元组中头部head的度中心性, 且作为对应head的权值。然后在对Ripple set进行embedding时, 将Ripple set的嵌入矩阵与head对应的权值矩阵中对应元素各自相乘, 得到带有权重的Ripple set embedding。之后按照RippleNet模型进行用户embedding和项目embedding计算, 根据Hop次数进行偏好传播的迭代, 最终得到带有实体权重的最终结果。

|
| 图 2 联合复杂网络Cn-RippleNet模型 |
Cn-RippleNet是模拟水波纹的传播方式, 以用户点击历史为种子, 模拟偏好传播, 对用户偏好节点添加影响力, 再将其作为用户embedding与项目embedding进行计算。在整个Cn-RippleNet模型中, 把用户u和项目v分别作为模型的输入, 把用户u可能会点击项目v的预测概率作为最终输出。每一个用户u, 都会根据其点击历史vu构建属于他的Ripple set, 其点击历史作为偏好传播的种子。然后沿知识图谱的关系向外扩充形成对应Hop的Ripple set Suk(k=1, 2, …, H)。Ripple set Suk是用户点击历史vu进行偏好传播后的三元组。Ripple set与项目embedding交互, 将用户u与项目v的信息相融合, 然后将这些信息组合起来形成最终的用户embedding。最后, 使用用户u和项目v的embedding来计算最终的预测概率ŷuv。
首先, 在知识图谱中表示用户历史点击数据vu, 由此来表示基于用户历史vu的偏好相关实体, 在RippleNet中, 通过循环递归的方法, 为用户u创建了偏好相关实体集, 如下所示
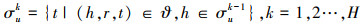
|
(2) |
这些实体可被视为用户在知识图谱中依据历史点击vu的偏好扩展。在给出相关实体的定义后, 本文定义用户u所有的K-hop Ripple set如下
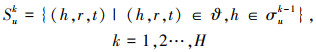
|
(3) |
在每一次Hop中, 都会将Ripple set中头实体的度中心性Ci作为权值与Ripple set的嵌入矩阵ei进行矩阵对应项乘积运算, 得到带有权重的hi。如下所示

|
(4) |
之后将项目v的项目embedding和用户u的Ripple set Su1进行计算。项目v分别与Su1中的头部hi和关系ri计算每个三元组(hi, ri, ti)的相关概率pi
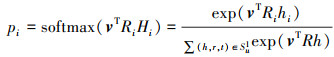
|
(5) |
相关概率可以看做项目v和头实体hi在关系空间中Ri的测度。因为不同种类的关系类型肯定会计算出不同相似性, 所以关系数据Ri也参与了相关概率的计算。获得相关概率后, 将Su1中的所有尾实体ti乘以相应的相关概率, 并且返回向量ou1。ou1可以看作是用户u对项目历史点击记录的第一次响应, 用来组成用户u的embedding。
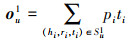
|
(6) |

|
(7) |
最后, 结合用户embedding和项目embedding, 输出预测的点击概率
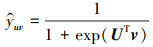
|
(8) |
在本文的实验中, 利用以下2个数据集进行实验: MovieLens-1M和Book-Crossing分别是在电影推荐和图书推荐中经常用到的数据集。其中电影数据集MovieLens-1M包含网站上真实用户的上百万个评分。Book-Crossing同样也包含百万本图书, 并且所有图书都在图书交流社区中获得用户的评分。本文采用RippleNet模型中为每个数据集所构造的知识图谱。
| 数据集结构 | MovieLens-1M | Book-Crossing |
| 用户 | 6 036 | 17 860 |
| 项目 | 2 445 | 14 967 |
| 关系交互 | 753 772 | 139 746 |
| 1-Hop的三元组 | 20 782 | 19 876 |
| 2-Hop的三元组 | 178 049 | 65 360 |
表 2中给出了Cn-RippleNet模型完整的参数设置, 其中d表示项目和知识图的嵌入维数, H表示Hop的次数,l表示学习率。
| 数据集 | d | H | λ1 | λ2 | l |
| MovieLens-1M | 16 | 2 | 10-7 | 0.01 | 0.02 |
| Book-Crossing | 4 | 3 | 10-5 | 0.01 | 0.001 |
本文将分别对每个数据集进行处理, 将整个数据集分为训练集、评估集和测试集3个部分。数据占比为6∶2∶2。每个数据集进行5次实验, 并以其平均值作为最终结果。
2.3 评价指标本文使用ACC(Accuracy)和AUC(Area Under Curve)作为实验的评价指标。AUC来源于ROC, 也就是ROC曲线图下半部分的面积。其值小于1。ROC曲线图用来判断二值分类器的优劣, 得到的曲线图横坐标为FPR(false positive rate), 纵坐标为TPR(true positive rate), 将这些坐标对连接起来就形成了ROC曲线图。最后计算AUC面积得到一个0.5~1的值, AUC越大分类效果就越好。
2.4 实验结果本文构建了电影和书籍的知识图谱, 使用基于集合运算的子网抽取算法构建了复杂网络。下图是最大联通子网的部分三元组数据。head表示头, rel表示关系, tail表示尾。为方便使用和统计, 实体和关系都使用序号来表示。
| head | rel | tail |
| 49 695 | 4 | 73 697 |
| 36 508 | 9 | 9 892 |
| 34 029 | 4 | 73 698 |
| 73 699 | 9 | 73 700 |
| 6 511 | 1 | 57 474 |
| 4 159 | 4 | 73 701 |
| 73 702 | 2 | 2 466 |
通过对节点影响力的计算, 得到了子网中每一个实体的度中心性。部分电影知识图谱实体的度中心性结果如下:
| 实体 | 度中心性 |
| 2 458 | 0.216 795 780 |
| 2 755 | 0.100 912 037 |
| 36 906 | 0.000 137 355 |
| 52 673 | 0.000 005 494 |
| 73 289 | 0.000 038 459 |
| 74 102 | 0.000 009 884 |
| 144 090 | 0.000 027 471 |
本文测试了不同参数时得到的结果, Cn-RippleNet模型在参数d=16, l=0.02, λ2=0.02的时候表现最佳, 得到的AUC和ACC都取得令人满意的结果。如表 5所示, 相比其他主流基于知识图谱的推荐模型, Cn-RippleNet在2个数据集上都取得了最好的性能。其原因在于Cn-RippleNet是将基于路径和基于嵌入的方法相结合, 利用知识图谱的侧面信息和节点影响力, 且对网络中的实体赋予了权重, 能够给予推荐系统更好的推荐, 得到更加准确的推荐结果。
| Model | MovieLens-1M | Book-Crossing | |||
| AUC | ACC | AUC | ACC | ||
| Cn-RippleNet | 0.930 | 0.856 | 0.755 | 0.691 | |
| RippleNet | 0.911 | 0.834 | 0.721 | 0.661 | |
| CKE | 0.796 | 0.739 | 0.674 | 0.635 | |
| SHINE | 0.778 | 0.732 | 0.668 | 0.631 | |
| DKN | 0.655 | 0.589 | 0.621 | 0.598 | |
| PER | 0.712 | 0.667 | 0.623 | 0.588 | |
| SSP-RippleNet | 0.902 | 0.812 | 0.713 | 0.642 | |
通过表 5的结果可以发现, 对比CKE的表现来看, Cn-RippleNet在AUC和ACC的评价指标下分别高出了13个百分点和12个百分点, 这是因为CKE是将知识图谱同协同过滤方法融合, 只是利用了图谱的结构知识特征, 没有考虑图谱的路径。DKN在电影和图书推荐方面表现不尽人意, 被Cn-RippleNet模型分别高出28个百分点和26个百分点。这是因为DKN更注重文本内容, 需要有多个实体才能保证预测的准确率。对DKN来说数据集的实体名字不够长, 就无法提供有用的信息, 得到的结果也更加不准确。Cn-RippleNet通过结合基于路径的方法, 得到了节点影响力克服了这个问题, 因此Cn-RippleNet也能在数据长度不够的情况下达到高性能。由于用户定义的元路径很难是最佳的, 所以PER在电影和书籍改编上的表现并不令人满意, 而Cn-RippleNet融合知识图谱实体的路径, 达到了更高的性能。在这2个数据集中, Cn-RippleNet的性能最好。对比RippleNet, 在MovieLens-1M数据集中, 改进后的Cn-RippleNet在AUC和ACC的评价指标下都高出了1个百分点, 而在Book-Crossing数据集中, 指标高出了2个百分点。这表明考虑节点影响力后的RippleNet的推荐效果更加准确。因此本文认为Cn-RippleNet在依据路径融合节点影响力的方法后效果更好。
在实验时, 考虑到RippleNet和Cn-RippleNet可能由于模型超参数的不同导致实验结果不严谨, 因此本文将添加1组对照试验, 将2个模型的超参数按照表 2设置, 并将RippleNet的实验结果记为SSP-RippleNet。通过表 5的结果, 发现在相同超参数下, Cn-RippleNet对比SSP-RippleNet的结果依然更优。在MovieLens-1M数据集中, AUC和ACC的指标分别高数3个百分点和4个百分点, 而Book-Crossing数据集中, AUC和ACC分别高出4个百分点和5个百分点。对比相同超参数的RippleNet模型, Cn-RippleNet依然能够取得更好的结果。
同时由图 3可以看出, Hop的值在2或者3时, 效果最佳, 说明Hop数对与性能的影响并不是越高越好。从图 4可以看出, 同样Dim也不是值越高效果越好, Dim在16时模型性能最优。表 6可以看出在这2个数据集下, 在度中心性、介数中心性、接近中心性的实验对比中, 度中心性的各项结果都优于其他。这表明在确定权重的方法中, 度中心性是最能体现2个数据集中网络节点的重要程度。因此对节点影响力的评价选择, 需要根据具体网络具体分析, 并且要通过实验来确定。

|
| 图 3 不同Hop的AUC值 |

|
| 图 4 不同Dim下的AUC值 |
| Node influence | MovieLens-1M | Book-Crossing | |||
| AUC | ACC | AUC | ACC | ||
| Degree Centrality | 0.930 | 0.856 | 0.755 | 0.691 | |
| Betweenness Centrality | 0.891 | 0.824 | 0.721 | 0.651 | |
| closeness centrality | 0.916 | 0.839 | 0.744 | 0.665 | |
本文提出了一种融合复杂网络节点影响力的Cn-RippleNet推荐模型。对领域知识图谱进行了网络化, 计算了知识图谱中实体的影响力, 并将其融入知识图谱的网络中, 使得推荐结果更加符合人们的偏好, 解决了RippleNet没考虑关键节点对推荐结果的影响的问题, 从而增加了推荐精度。实验表明, 通过节点影响力改进的Cn-RippleNet算法能够提高推荐算法的结果。下一步可以考虑将知识图谱的最大联通子网的关系细化, 对不同的关系赋予不同的权重。也可以考虑更加新颖的节点影响力算法。
| [1] | KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37. DOI:10.1109/MC.2009.263 |
| [2] | JAMALI M, ESTER M. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the fourth ACM conference on Recommender systems, 2010: 135-142 |
| [3] | ZHANG Fuzheng, JING Nicholas, LIAN Defu. Collaborative knowledge base embedding for recommender systems[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016: 353-362 |
| [4] | WANG Hongwei, ZHANG Fuzheng. DKN: deep knowledge-aware network for news recommendation[C]//Proceedings of the 2018 World Wide Web Conference, 2018: 1835-1844 |
| [5] | YU Xiao, REN Xiang, SUN Yizhou. Personalized entity recommendation: a heterogeneous information network approach[C]//Proceedings of the 7th ACM International Conference on Web Search and Data Mining, 2014: 283-292 |
| [6] | ZHAO Huan, YAO Quanming, LI Jianda. Metagraph based recommendation fusion over heterogeneous information networks[C]//Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017: 635-644 |
| [7] | WANG Hongwei, ZHANG Fuzheng, WANG Jialin. Exploring high-order user preference on the knowledge graph for recommender systems[J]. ACM Transactions on Information Systems, 2019, 37(3): 1-26. |
| [8] | FREEMAN L C. Centrality in social networks conceptual clarification[J]. Social Networks, 1978, 1(3): 215-239. DOI:10.1016/0378-8733(78)90021-7 |
| [9] | FREEMAN L C. A set of measures of centrality based on betweenness[J]. Sociometry, 1977, 40(1): 35-41. DOI:10.2307/3033543 |
| [10] | SABIDUSSI G. The centrality index of a graph[J]. Psychometrika, 1966, 31(4): 581-603. DOI:10.1007/BF02289527 |
| [11] |
丁连红, 孙斌, 时鹏. 知识图谱复杂网络特性的实证研究与分析[J]. 物理学报, 2019, 68(12): 324-338.
DING lianhong, SUN Bin, SHI Peng. Empirical study of knowledge network based on complex network theory[J]. Journal of Physics, 2019, 68(12): 324-338. (in Chinese) |
| [12] |
樊燕妮, 刘三阳, 白艺光. 基于多尺度中心性算法的复杂网络节点影响力研究[J]. 数学的实践与认识, 2020, 50(10): 159-167.
FAN Yanni, LIU Sanyang, BAI Yiguang. Identifying critical nodes in complex networks based on multi-scale centrality algorithm[J]. The Practice and Understanding of Mathematics, 2020, 50(10): 159-167. (in Chinese) |
