



2. 西北工业大学 计算机学院, 陕西 西安 710129
传统的机械臂控制方法几乎都是按照人为预设轨迹来完成特定的任务目标。近些年来随着人工智能技术的发展, 将人工智能技术应用在机械臂控制, 实现复杂动态环境下的机械臂智能控制成为一个热门的研究方向。
智能控制的目标就是构建出一个能够自主学习适应新环境的系统, 强化学习[1]凭借着其自身特点是实现这一目标的关键技术。深度神经网络和强化学习相结合组成的深度强化学习在游戏决策任务上已经取得了非常大的成功。Google DeepMind团队最早提出深度神经网络与强化学习相结合的深度Q网络[1]在Atari游戏决策控制上获得了出色的表现, 从此开启了深度强化学习的时代。其后又逐渐涌现了能够处理连续动作空间问题的深度确定性策略梯度算法(DDPG)[3]、近端策略优化算法(PPO)[4]、异步优势演员评论家算法(A3C)[5]等强化学习算法模型。
深度强化学习在游戏行为决策任务上表现得非常成功, 并增强了强化学习的可解释性[6], 很大一部分决定性因素在于游戏环境中奖励函数通常能够直接给出, 并且能够直接用来优化。但是在机械臂控制环境中奖励设置往往是当智能体完成某一个任务目标时, 环境给予一个正反馈, 其他情况下没有反馈。由于智能体起初是随机地在环境中进行探索, 绝大多数探索步骤没有奖励回馈, 强化学习模型训练时很难收敛, 并且当智能体所处的环境发生动态变化时会极大加剧这一状况。为了解决以上2个问题, Schaul等提出了通用价值函数逼近器[8], 算法将目标状态作为计算奖励的中间媒介, 可以根据不同的目标对当前的状态进行估计, 获得状态-目标值函数V(s, g|θ), 使得智能体学习到从任意状态s到达任意目标g的策略。受到统一函数逼近器算法的启发, Andrychowicz等提出了后视经验重现算法(HER)[9], 算法可以与任意的离线策略强化学习算法模型相结合, 从失败中进行学习, 通过不断采样新目标g′来解决稀疏奖励问题, 同时也能够使得模型最终在环境E中学习到从任意状态s到达任意目标g的策略。Hester等提出了基于示范数据的深度Q网络算法模型(DQfD)[10], 解决了复杂动态变化环境和稀疏奖励导致传统强化学习算法难以收敛的问题。Vecerik等提出了基于示范数据的深度确定性策略梯度算法模型[11]填充了DQfD不能处理连续动作空间的缺陷, 在机械臂控制的仿真实验中有着不错的表现。但是这些算法依赖于精确的环境模型, 不能对所处环境自适应感知, 并且在大规模状态空间的训练过程中随机探索方案已经不太可行。
针对以上问题, 本文采用YOLO[12]目标检测算法感知当前环境状态, 将环境中目标感知模块与控制系统解耦, 直接利用机械臂上方的摄像设备捕捉并计算获得拾取目标位置信息, 接下来收集一系列仿真环境下人类操控机械臂的行为作为示范数据, 在仿真环境中对机械臂控制强化学习算法模型进行监督学习预训练, 即: 模仿人类行为学习到部分控制策略[13-14], 在此基础上结合DDPG与HER算法, 对仿真环境中的机械臂进行控制, 最终实现端到端的机器视觉-强化学习控制模型。
1 背景 1.1 马尔可夫决策过程强化学习是机器学习的一个重要分支, 主要有基于模型和不基于模型2种强化学习类型, 最常见的模型是马尔可夫决策过程, 一个马尔科夫决策过程由一个四元组组成, M=(s, A, psas′, R), s∈S表示状态空间, a∈A表示动作空间, psas′为状态转移概率, 表示在当前状态s下采取动作a转移到状态s′的概率。对于给定的任意目标g∈G, 定义奖励函数rg(si, ai), 当且仅当在状态si采取动作ai到达目标g时环境会给予一个正反馈, 在t时刻的状态回报定义为未来奖励的折扣和, 即: Rt=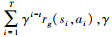

|
(1) |
在强化学习算法中使用状态值函数Vπ(s)来表示在当前状态s按照策略π进行探索的期望回报, 该值函数具体定义如(2)式所示
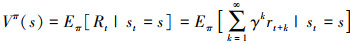
|
(2) |
深度强化学习算法即深度学习与强化学习相结合的产物, DQN[1]是一个非常具有代表性的非基于模型的深度强化学算法, 主要用来解决智能体在离散动作空间的决策问题。DQN中定义了一个策略网络Qe和一个目标网络QT, 策略网络用来估计状态行为值函数Q*, 行为决策方式如(3)式所示
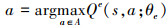
|
(3) |
实际训练中通常使用ε贪心策略给予智能体一定的随机探索概率, 使得智能体每次以概率ε随机选择动作, 以(1-ε)的概率策略πQe选择确定动作a。训练时在t时刻进行探索产生一条经验e=(st, at, rt, st+1)存储在经验池中, 为了使得训练样本间尽可能相互独立, 网络训练采用随机策略从经验池中抽取一个批次数据进行训练。定义损失函数: L=E(Q(st, at|θe)-yt)2, yt的定义如(4)式所示
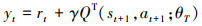
|
(4) |
式中
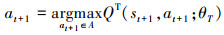
|
(5) |
由于E[max(Q)]>maxE[Q],上述估计Q值的方式会产生过估计, Hasselt等在文献[7]中重新对(5)式的行为选择重新进行定义

|
(6) |
在学习率为α时损失函数L的梯度以及参数θe的优化如下式

|
(7) |
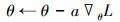
|
(8) |
根据时序差分更新策略, 经过t轮时间迭代后执行一次目标网络参数θT的更新: θT←θe。
传统的深度强化学习算法在解决较为简单的决策任务上具有非常好的效果, 但是处理复杂的控制任务时通常会存在稀疏奖励的问题, 导致模型难以收敛。因此通常在处理复杂的决策控制问题时会结合HER算法来加速模型收敛速度。
2 算法流程端到端的机械臂自主视觉感知控制算法主要由视觉感知算法模块和决策控制算法模块组成。
1) 视觉感知算法模块
视觉感知模块使用YOLO-v5算法, 不同于其他的两阶段系列目标检测算法, YOLO将物体检测作为一个回归问题求解, 算法将输入图像M划分成n×n的网格, 每个网格负责识别目标中心落在其中的对象, 经过一次神经网络F的计算推理, 便能输出图象中所有物体的位置信息O、类别信息C以及置信概率P, M×F→(O, C, P)。这是一个典型的结构化机器学习算法, 根据模型结构, 相应的其损失函数也包括三部分: 坐标误差coordError、IOU误差iouError以及分类误差classError。损失函数L的定义如(9)式所示
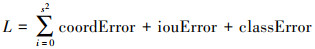
|
(9) |
在实验的单个目标识别中, 分类误差classError表示目标和背景分类误差。视觉感知网络使用在COCO数据集上预训练的权重来初始化, 在此基础上来训练我们标注的机械臂识别目标数据集。
通过目标识别能够确定当前目标相对于摄像机的具体位置信息(x1, y1, C)其中C为高度固定常量, 即载物台相对于机械臂夹口初始状态的高度。接下来使用透视变换算法将其转换为目标相对于载物台具体的坐标信息(x2, y2, C)。透视变换是把一个图像投影到一个新的视平面过程, 是一个非线性变换, 包括: 将一个二维坐标系转换为三维坐标系, 然后将三维坐标系投影到新的二维坐标系。变换过程如(10)式所示。
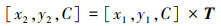
|
(10) |
式中,T为变换矩阵

|
(11) |
给出4个对应像素的坐标点即可求出变换矩阵T。变换结果如图 1所示。

|
| 图 1 透视变换得到目标相对于载物台的准确XOY平面坐标信息 |
2) 决策控制算法模块
决策控制模块采用DDPG强化学习算法, 为加速DDPG算法的收敛速度, 采用模仿学习的方式首先从人类手动控制的经验数据中进行预学习训练, 学习到部分初始的控制策略, 接下来使用DDPG算法让机械臂自主的在环境中学习。DDPG有2个网络结构: 一个行为网络(Actor)π1: S→A和一个评估网络(Critic)π2: S×A→R, 类似于DQN, Actor网络由决策估计μ(s|θμ)和决策期望μ(s|θμ′)组成, Critic网络由估计网络Q(s, a|θQ)和目标Q(s, a|θQ′)组成。Critic网络的工作就是评估在当前状态s, Actor网络所做出的决策a的好坏。对于任意当前输入状态st, 通过Actor网络选取行为at=μ(s|θμ)+Nt, 其中Nt为随机噪声, 执行此行为获得奖励rt, 接着再使用Critic网络对当前状态st采取行为at进行打分评估, 以此来不断优化Actor网络与Critic网络, 完成整体DDPG算法的优化收敛。优化目标如(12)式所示
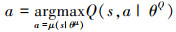
|
(12) |
优化过程如图 2所示。

|
| 图 2 DDPG算法整体优化过程 |
定义DDPG的Critic网络损失函数L如(13)式所示
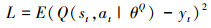
|
(13) |
式中

|
(14) |
Actor网络使用梯度上升的方式优化θμ, θμ梯度求解方式如(15)式所示。
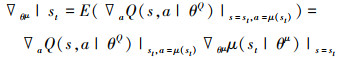
|
(15) |
经历k轮优化之后, 使用软更新[3]的策略优化目标网络中的参数, 如(16)~(17)式所示。
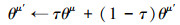
|
(16) |
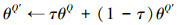
|
(17) |
在训练过程为了解决稀疏奖励问题, 引入了HER算法, DDPG网络输入的不仅仅是当前时刻的状态st, 还包括了要实现的目标gt, Actor网络策略被重新定义为: π: S×g→A, 当且仅当机械臂执行Actor网络输出的行为at到达的下一个状态st+1与gt相等时环境会给予一个奖励。Critic网络策略重新定义为: π: S×A×g→R。机械臂每历经一轮探索, HER算法便会从历史经验池中进行一次目标采样, 产生m条新的经验, 并且按照(18)式的规则重新计算奖励奖励值r, 将其放到经验池中。最终使得智能体学到了从任意状态s到达任意目标g的策略, 且解决了训练过程中稀疏奖励的问题。算法具体流程如算法1所示。

|
(18) |
算法1 IL-DDPG-HER算法
1. 初始化DDPG参数:θ, θ′, μ, μ′;
初始化YOLO网络参数m;
初始化迭代参数n1, n2, n3, n4;
初始化经验回放池R;
2. 创建YOLO目标定位训练数据集S;
创建模仿学习示范数据集D;
//训练YOLO目标定位神经网络
3. for episode=1 to n1 do
4.随机从样本集S中抽取一个批次b;
5.训练YOLO网络参数m;
6. end for;
//模仿学习部分
7. for episode=1 to n2 do
8.随机从样本D中抽取一个批次b;
9.监督学习训练DDPG网络参数θ, μ;
10. end for;
11. 模仿学习训练完成得到初始策略A;
//强化学习训练部分
12. for episode=1 to n3 do
13.for t=1 to T-1 do
14. 摄像设备捕捉输入图像i;
15. YOLO网络定位目标所在图像位置;
16. 透视变化算法获取目标坐标信息st;
17. 使用策略A获取行为at=A(st‖g);
18. 执行at得到新的状态st+1, 并获得奖励值rt;
19. 存储(st‖g, at, rt, st+1‖g)到R中;
20. HER算法重新采样新目标,计算奖励值存储到R中;
21.end for;
22.for t=0 to n4 do
23. 从经验回放池R中随机采样一个批次B;
24. 在B上对策略A进行优化;
25. end for;
26. end for;
3 实验设计与分析为验证提出的端到端的识别-控制算法模型, 采用OpenAI Gym Robotics的FetchPickAndPlace-v1机械臂三维空间控制实验仿真环境, 如图 3所示。实验首先通过人为控制机械臂完成相应的拾取-放置任务, 收集人类操作经验来让机械臂预学习, 接下来按照算法流程的奖励函数设计让其进行自主学习探索, 最终学习到自主决策的能力。整个流程可解耦为自主视觉感知和强化学习控制两部分。

|
| 图 3 机械臂三维空间控制仿真环境 |
仿真环境中摄像设备捕捉到载物台的图像数据, 接下来借助Roboflow工具标注创建YOLO目标检测网络训练所需数据集, 在仿真环境中训练了黑色块目标检测, 经过对象识别与定位训练之后, 算法模型便能够实现一般环境下黑块目标的识别与定位, 最后通过透视变化算法即可获取物体在载物台上具体位置坐标信息, 如图 4所示。由此以来拾取对象位置信息不再依赖于仿真环境主动提供, 直接由系统目标识别检测模块获得。实验在YOLOv5-s的预训练权重基础上对我们所识别定位的对象进行训练, 在100个批次训练后mAP值、准确率、召回率上都能够达到较好的预期效果, 如图 5所示。

|
| 图 4 YOLO目标检测输入数据 |

|
| 图 5 目标定位损失、目标识别损失、精确度、召回率、校验集目标定位损失、校验集目标识别损失,mAP 0.5以及mAP∈[0.5, 0.95] |
实验首先通过人为的收集决策序列τ1, τ2, …, τm, 每个决策序列由状态集和动作集组成: τi=(s1i, a1i, s2i, a2i, …, sni, ani), 将所有的状态动作序列对抽取出来构造出新的初始经验集合
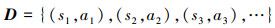
|
继而将状态s作为输入特征, 动作a作为输出的预测值, 在连续状态空间的机械臂控制任务上当成一个回归问题来求解, 使得模型在使用强化学习算法自主学习之前已经具备部分先验知识, 以此来加速强化学习算法的收敛速度。最后让机械臂自主的开始在环境中探索, 不断学习强化自身决策控制能力。实验对比分析了IL-DDPG-HER算法和DDPG-HER算法训练智能体执行任务的成功率, 如图 6所示。可以得到IL-DDPG-HER算法执行拾取-放置任务上的成功率收敛速度更快。

|
| 图 6 机械臂拾取-放置任务IL-DDPG-HER与DDPG-HER成功率实验对比分析 |
本文通过将计算机视觉技术与强化学习相结合, 使得智能体具备自主感知真实环境的能力, 这在机械臂拾取-放置任务有着非常重要的意义, 尤其是在适应动态变化环境上, 机器视觉-强化学习的端到端控制模型让智能体感知环境的能力与智能决策能力解耦, 在应对复杂变化的环境时, 可直接对环境感知网络进行重新训练, 而决策网络无需做任何改动。并且随着计算机视觉技术的成熟发展, 视觉感知模型的训练已经不再是往日的时间“消耗战”, 往往能够在普通设备上稍作训练即可满足普通的目标定位任务。
未来的视觉感知研究可以加入双目甚至多目摄像头, 或者是其它的深度感知传感器, 来完成3D空间任意位置的目标感知, 结合已经训练好的强化学习模型, 最终让智能体完成更加复杂的控制决策任务。
| [1] | LUMELSKY V, STEPANOV A. Dynamic path planning for a mobile automaton with limited information on the environment[J]. IEEE Trans on Automatic Control, 1986, 31(11): 1058-1063. |
| [2] | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[J]. Computer Science, 2013, 12(19): 5602. |
| [3] | LILLICRAP T P, HUNT J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J/OL]. (2019-07-05)[2021-10-22]. https://arxiv.org/pdf/1509.02971v6.pdf |
| [4] | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J/OL]. (2017-08-28)[2021-10-22]. https://arxiv.org/pdf/1707.06347.pdf |
| [5] | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//International Conference on Machine Learning, 2016: 1928-1937 |
| [6] | LI J, SHI H, HWANG K S. An explainable ensemble feedforward method with Gaussian convolutional filter[J]. Knowledge Based Systems, 2021(225): 107103. |
| [7] | VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double q-learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2016 |
| [8] | SCHAUL T, HORGAN D, GREGOR K, et al. Universal value function approximators[C]//International Conference on Machine learning, 2015: 1312-1320 |
| [9] | ANDRYCHOWICZ M, WOLSKI F, RAY A, et al. Hindsight experience replay[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 5055-5065 |
| [10] | HESTER T, VECERIK M, PIETQUIN O, et al. Deep q-learning from demonstrations[C]//Thirty-Second AAAI Conference on Artificial Intelligence, 2018 |
| [11] | VECERÍK M, HESTER T, SCHOLZ J, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[J/OL]. (2018-10-08)[2021-10-22]. https://arxiv.org/pdf/1707.08817v1.pdf |
| [12] | BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection[J/OL]. (2020-04-23)[2021-10-22]. https://arxiv.org/pdf/2004.10934v1.pdf |
| [13] | Wu Y H, Lin S D. A low-cost ethics shaping approach for designing reinforcement learning agents[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018 |
| [14] | CHRISTIANO P F, LEIKE J, BROWN T B, et al. Deep reinforcement learning from human preferences[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, 2017 |
2. School of Computer, Northwestern Polytechnical University, Xi'an 710129, China
