

在微波通信、雷达探测、飞行器隐身等领域中, 常涉及到有限周期阵列[1]的设计和仿真。在使用矩量法(method of moments, MoM)[2]对这种问题进行仿真计算时, 由于阵列电尺寸通常很大, 使用多层快速多极子法[3](multilevel fast multipole algorithm, MLFMA), IE-FFT[4-5](integral equation fast Fourier transformation)以及自适应积分法[6-7](adaptive integral method, AIM)等加速算法来提升求解效率。与MLFMA和IE-FFT相比, 基于等效源的AIM精度更高并且非常适合于求解这种相对平坦的“准平面”问题。对于未知量为N的问题, AIM可以将时间复杂度和内存复杂度从O(N2)和O(N2)分别减少到O(NlogN)和O(N)。
然而, 利用AIM分析大型周期阵列的电磁特性时, 存在着2个不足。第一个是求解区域中存在大量的冗余栅格点[8-9], 这些栅格点对于远场互阻抗的计算并没有任何实质上的贡献, 反而会消耗大量计算资源, 从而堕化算法的真实效率。第二个则是, 随着未知量的增加, 近场矩阵的填充和矫正步骤也会占用大量时间, 这是因为AIM本质上并没有将远场和近场计算彻底分离。
为了克服上述2个问题, 本文提出了一种阵列自适应积分法。该方法共包括4个关键性技术, 分别为冗余点消除技术、零值屏蔽技术、块状对角预处理以及快速远场后处理技术, 它们分别从矩阵填充、近场矫正、迭代求解以及后处理4个方面来提升算法的计算效率。数值仿真结果表明, 本文提出的方法能有效降低内存需求量并提高总求解速度。此外, 该方法不仅适合于有限周期阵列, 还可以处理大型稀疏阵列。
1 算法原理 1.1 传统自适应积分法传统AIM是一种基于矩量法的快速算法, 它将稠密的阻抗矩阵Z根据近场门限划分为近场和远场2个部分

|
(1) |
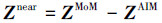
|
(2) |
式中:Znear和Zfar分别表示近场稀疏矩阵和远场压缩矩阵;ZMoM和ZAIM分别表示使用矩量法计算得到的准确近场矩阵和由离散格点产生的不准确近场矩阵。(1)式中的Zfar又可以进一步写成多个稀疏矩阵相乘的形式
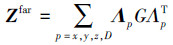
|
(3) |
式中, Λp是一个稀疏的投影矩阵, 而G则表示栅格点间的离散格林函数, 它属于3层Toeplitz矩阵。在迭代求解时, 一般使用它的傅里叶压缩形式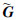
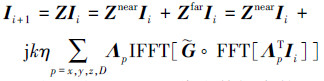
|
(4) |
式中:“°”表示哈达玛积;k代表传播常数;η表示本质阻抗;Ii代表迭代向量,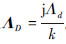
尽管AIM的性能优于矩量法, 但在求解大型周期阵列问题时, 为了保证精度, 往往需要大量栅格点对整个求解区域进行离散。在这些栅格点中只有一部分栅格点参与了远场近似计算, 其余的栅格点则由于没有基函数在其上展开对远场计算没有任何贡献, 它们被称作冗余栅格点。
如图 1所示的3×3平面阵列, 灰色椭圆代表实际的阵元, 每个阵元都可以看作是整个阵列的1个子区域。当使用矩形栅格点笼罩住整个阵列后, 只有子域中的栅格点(图中空心点)上定义了展开系数, 而阵元之间中心带叉栅格点则全部属于冗余栅格点。

|
| 图 1 冗余栅格点与子域栅格点 |
为了消除阵元间的冗余栅格点, 可以首先将整个阵列的阻抗矩阵Z划分为大小相等的M2个子矩阵块Zmn(m, n∈{1, 2, …, M}), 这里M代表阵元的个数, 当m≠n时, Zmn表示不同阵元间的互耦项。由于大型阵列中, 阵元间距一般都可以满足AIM的远场条件, 因此可以使用与(3)式类似的远场近似式来计算这些互耦项
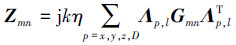
|
(5) |
式中,Λp, l代表阵元在子区域上的投影矩阵, 即图 1中1组空心点上展开系数。由于阵元具有一致性, 因此阵元的投影矩阵是完全相同的。这表明阵元之间的互阻抗Zmn将主要由Gmn来决定。从图 1中还可以看出, Gmn只与子域栅格点相关, 不包含冗余部分, 并且通过平移, 不同阵元的子域栅格点可以完全重合。因此Gmn仍旧可以保持3层Toeplitz结构, 采用文献[10]的符号可以记作T13(Nz, Ny, Nx), 这里Nx, Ny, Nz分别代表子域中x, y, z方向的栅格点个数。
其次, 若将每个阵元视作一个整体, 则根据阵元的等间距特性, 整个阵列就等同于1个二维矩形栅格区域, 阵列尺寸为Nu×Nv, 这个层面的格林函数矩阵Garray属于2层Toeplitz矩阵, 可记作T2Nx×Ny×Nz(Nu, Nv)。将2个层面的格林函数进行合并, 就可以得到总的格林函数
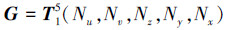
|
(6) |
与(3)式相比, G由3层变成5层Toeplitz矩阵, 它不仅最大限度地保留了子域栅格点, 而且剔除了阵元间的冗余栅格点, 此时整个阵列的阻抗矩阵Z就可以写作
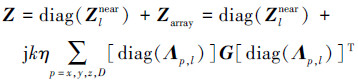
|
(7) |
式中,Zlnear表示修正后的阵元近场矩阵。投影矩阵和近场矩阵呈现出块状对角特性, 可以复用同一组Zlnear和Λp, l。
接下来, 为了解决大型阵列中近场矫正耗时长的问题, 本文使用了一种零值屏蔽技术来直接消除近场矫正步骤。它的原理是将G中与阵元自耦项有关的格林函数Gmm全部置零, 从而彻底阻隔远场近似计算对近场区域的干扰。
仅考虑包含3个阵元的线阵, 若将格林函数G的对角矩阵块全部置零, 此时其远场近似矩阵可以写作
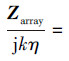
|
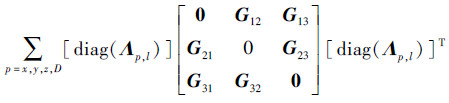
|
(8) |
在实际计算中, 如图 1所示可以通过对格林函数添加约束条件来实现置零操作, 即
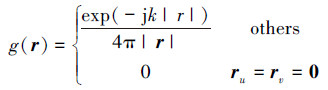
|
(9) |
式中:r=rlocal+rv+ru代表场源点间的位矢;rlocal表示子域栅格点间的位矢;ru, rv则代表阵元间沿着u, v 2个方向的位置矢量。将(8)式代入(7)式并改写可得
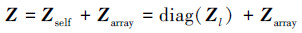
|
(10) |
式中, Zl代表由矩量法计算得到的自耦矩阵。与(7)式相比, 用Zl替换了Zlnear, 这表明不再需要对阵元的近场矩阵进行矫正。最终, 公式(4)可以改写成
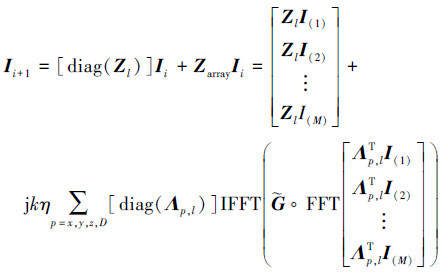
|
(11) |
式中, I(m)表示迭代向量Ii展开后的第m个子向量。从(11)式仍旧可以看出Λp, l和Zl被多次复用, 这极大地降低了阵列自适应积分法的内存需求量。此外, 若阵列的某些区域并不存在阵元, 等同于该区域的Λp, l和Zl为0, 在公式(11)中就表现为跳过这些区域的计算。这一特性使得本文提出的阵列AIM不仅适用于有限周期阵列, 还能在一定程度上处理稀疏阵列。
1.3 块状雅克比预处理和快速远场后处理为了进一步提升迭代求解时的收敛速度, 根据有限周期阵列的结构特性, 本文采用稳健的块状雅克比预处理。由(10)式可知, 近场矩阵Zself属于块状对角矩阵, 因此可以直接对该矩阵求逆得到预处理矩阵, 同时对(11)式两端乘以这个预处理矩阵可得
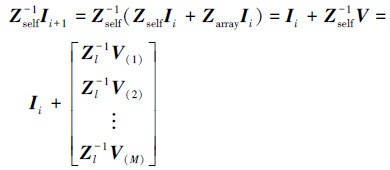
|
(12) |
式中,V=ZarrayIi, 它代表矩阵向量相乘时, 远场部分的结果, 也可以被分解为M个子向量。对比(12)式和(11)式可以发现, 从空间复杂度上看, Zl被Zl-1代替, 但其内存需求量并没有增加。而从时间复杂度上看, 近场部分的计算量被转移到了远场, 但矩阵向量相乘时的总体计算量也没有增加, 近场部分仅仅剩下1个迭代参量。这等同于给迭代向量附加1个单位矩阵, 而这个单位矩阵具有极强的谱聚特性, 从而能大幅改善矩阵的病态性, 加快求解的收敛速度。此外, 可以使用多线程并行技术来同时计算Zself-1V的不同部分, 从而一定程度上减少平均迭代时间。
另一方面, 与传统的AIM不同, 阵列AIM只需要1个阵元的剖分网格, 并将这个阵元作为参考阵元离散, 就可以得到Nl个基函数, 进一步就可以得到Λp, l和Zl-1。然而在计算阵列的远场散射时, 根据阵元所处的位置不同, 每个阵元对远场的贡献是不同的, 它需要每个阵元上具体的剖分网格, 这与阵列AIM的输入参量是相互矛盾的。
幸运的是, 这一问题可以通过补偿阵元间的波程差来轻松解决。首先, 令En(θ, φ)代表参考阵元上第n个基函数在(θ, φ)方向的散射场, 并将它视作元因子。其次, 阵列在(θ, φ)方向的散射总场可以写作
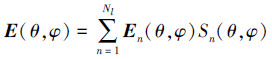
|
(13) |
式中,Sn(θ, φ)可以理解为阵因子, 它表示为
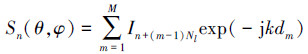
|
(14) |

|
(15) |
式中:dm表示第m个阵元与参考单元在(θ, φ)方向的波程差;du, dv分别表示阵元沿着u, v方向的间距, 而ΔNum, ΔNvm表示第m个阵元与参考阵元在u, v方向的序号差;In+(m-1)Nl则表示不同阵元上第n个基函数的电流项系数。从(13)~(15)式可知, 阵因子Sn(θ, Φ)只包括求解后得到的电流项激励和相位因子, 它们都是与基函数无关的参量, 而元因子En(θ, Φ)只与参考阵元有关。
综上所述, 一旦得到求解后的电流激励I, 就可以利用(13)~(15)式快速计算任意方向的散射电场。为了更好地理解阵列AIM, 图 2给出了该算法的计算流程图。

|
| 图 2 阵列AIM算法流程图 |
为了验证阵列AIM的算法精度和效率, 本文先计算了有限周期阵列和稀疏阵列的远场雷达散射截面(radar cross section, RCS), 并与MLFMA和传统AIM的计算结果作对比。随后针对稀疏阵列, 比较了阵列AIM和传统AIM在不同阵列尺寸条件下的性能参数, 以此来验证本文算法的高效性。本节所有算例均使用电场积分方程, 阵列平面位于xoy面, 入射平面波Ei沿-z轴方向传播, 极化方向沿x轴, 频率为300 MHz。算例的仿真平台为Intel Core i7 4790 3.6GHz台式机, 内存为32 GB。
2.1 算法精度验证第一个算例为4×4的金属球阵列。如图 3所示, 球半径为0.6 m, 阵列尺寸lu×lv=5.7 m×5.7 m, 阵元间距du=dv=1.5 m。经过剖分后, 每个阵元未知量为1 287, 从而整个阵列的未知量为20 592。图 4给出了由阵列AIM, 传统AIM以及MLFMA计算的得到的φ=0, π/2时俯仰面双站RCS, 3种方法计算得到远场RCS曲线基本一致。以MLFMA的计算结果为参考, 阵列AIM在φ=0和φ=π/2平面的相对均方根误差分别为0.88%和0.94%, 这表明阵列AIM在处理这种密集的有限周期阵列时具有较好的精度。

|
| 图 3 阵元为金属球的4×4平面阵列模型图 |

|
| 图 4 阵元为金属球的4×4平面阵列俯仰面双站RCS曲线 |
第二个算例是8×8圆锥稀疏阵列。图 5中,阵元间距du=dv=0.7 m, 阵列尺寸lu×lv=5.15 m×5.15 m。金属圆锥底面直径为0.25 m, 高度为0.5 m。与第一个算例不同, 阵列一共只有40个阵元, 在整个阵面呈现出稀疏分布, 其稀疏度为37.5%。

|
| 图 5 阵元为圆锥的8×8稀疏阵列模型图 |
图 6给出了阵列AIM计算得到的俯仰面双站RCS曲线, 并与MLFMA和传统AIM作对比。从图 6中可以看出, 3种方法得到的双站RCS能良好吻合。经过计算, 阵列AIM在φ=0和φ=π/2平面的相对均方根误差分别为1.24%和1.96%, 这表明阵列AIM也能有效处理稀疏阵列的散射问题。

|
| 图 6 阵元为圆锥的8×8稀疏阵列俯仰面双站RCS曲线 |
本节将主要分析稀疏阵列尺寸对阵列AIM性能的影响, 算例模型与图 5一致, 阵列的稀疏度为37.5%。共选取了3组不同的阵列尺寸, 分别为8×8, 16×16和24×24, 其对应的未知量分别为24 120, 96 480和217 080, 其余参数与2.1节一致。
从表 1中可以清晰的看出, 与传统AIM相比, 阵列AIM可以减少96%的内存消耗。并且阵列AIM的近场矩阵填充时间不会随着阵列尺寸的增大而发生变化, 尤其是阵列尺寸为24×24的情况下, 填充速度比传统AIM快3 300倍。这些因素使得阵列AIM的总时间要远小于传统AIM。
| 阵列尺寸 | 未知量 | 内存/MB | 填充时间/s | 总时间/s | |||||
| 阵列AIM | AIM | 阵列AIM | AIM | 阵列AIM | AIM | ||||
| 8×8 | 24 120 | 25.18 | 748.93 | 0.318 | 61.12 | 5.03 | 68.78 | ||
| 16×16 | 96 480 | 97.74 | 2 442.79 | 0.317 | 420.37 | 52.55 | 504.25 | ||
| 24×24 | 217 080 | 169.20 | 6 455.22 | 0.347 | 1 172.54 | 240.23 | 1 401.25 | ||
综上所述, 本文提出的阵列AIM不仅具有很好的计算精度, 而且在处理稀疏阵列时也具有较好的性能。
3 结论本文针对于大型有限周期阵列的特性, 提出了一种称作阵列AIM的方法。该方法使用5层Toeplitz矩阵和零值屏蔽技术解决了传统AIM中存在的冗余栅格点和远近场耦合问题。同时使用块状Jacobi预处理技术提升迭代求解的收敛速率, 并基于波程差补偿技术进行快速后处理。数值结果表明, 该方法具有良好的计算精度, 不仅适用于密集阵列, 也同样适用于稀疏阵列。其次, 在稀疏度相同时, 随着阵列尺寸的增加, 该方法的近场矩阵填充时间不发生变化且小于传统AIM, 特别地, 当阵列尺寸为24×24时, 近场填充速度可以提高3 300倍。此外阵列AIM的内存需求量也低于传统AIM。这充分说明了阵列AIM在仿真计算稀疏和非稀疏阵列上的高效性。
| [1] | LIU Lu, NIE Zaiping. An efficient numerical model for the radiation analysis of microstrip patch antennas[J]. ACES Journal, 2019, 34(10): 1473-1478. |
| [2] | HARRINGTON Roger F. Field computation by moment methods[M]. NewYork, NY, USA: MacMillian, 1968. |
| [3] | SONG Jiming, LU Caicheng, CHEW Wengcho. Multilevel fast multipole algorithm for electromagnetic scattering by large complex objects[J]. IEEE Trans on Antennas and Propagation, 1997, 45(10): 1488-1493. DOI:10.1109/8.633855 |
| [4] | FASENFEST B, CAPOLINO F B. A fast mom solution for large arrays: green's function interpolation with FFT[J]. IEEE Antennas and Wireless Propagation Letters, 2004, 3(1): 161-164. |
| [5] | SEO Seungmo, LEE Jinfa. A fast IE-FFT algorithm for solving PEC scattering problems[J]. IEEE Trans on Magnetics, 2005, 41(5): 1476-1479. DOI:10.1109/TMAG.2005.844564 |
| [6] | BLESZYNSKI E, BLESZYNSKI M, JAROSZEWICZ T. A fast integral-equation solver for electromagnetic scattering problems[C]//Proceedings of IEEE Antennas and Propagation Society International Symposium and URSI National Radio Science Meeting, Seattle, WA, 1994: 416-419 |
| [7] | BLESZYNSKI E, BLESZYNSKI M, JAROSZEWICZ T. AIM: adaptive integral method for solving large-scale electromagnetic scattering and radiation problems[J]. Radio Science, 1996, 31(5): 1225-1251. DOI:10.1029/96RS02504 |
| [8] | IOANNIDI Constantina, ANASTASSIU Hristos. Circulant adaptive integral method (CAIM) for electromagnetic scattering from large targets of arbitrary shape[J]. IEEE Trans on Magnetics, 2009, 45(3): 1308-1331. DOI:10.1109/TMAG.2009.2012607 |
| [9] | WANG Xing, ZHANG Shuai, LIU Ziliang, et al. A SAIM-FAFFA method for efficient computation of electromagnetic scattering problems[J]. IEEE Trans on Antennas and Propagation, 2016, 64(12): 5507-5512. DOI:10.1109/TAP.2016.2621028 |
| [10] | BARROWES Benjamin, TEIXEIRA Fernando, et al. Fast algorithm for matrix-vector multiply of asymmetric multilevel block-toeplitz matrices in 3-D scattering[J]. Microwave and Optical Technology Letters, 2001, 31(1): 28-32. DOI:10.1002/mop.1348 |
