

近年来,随着卫星遥感成像技术以及深度学习技术的不断发展,在轨遥感AI(artificial intelligence)平台成为智能遥感领域的重要发展方向。星载合成孔径雷达(SAR)系统中的SAR遥感图像处理(GMTIm)和地面目标指示(GMTI)在民用和军事应用中受到越来越多的关注[1]。
智能遥感图像相关领域主要包括星载SAR实时成像和图像的神经网络模型实时处理两大任务模块。目前,SAR成像的常用算法主要有CSA(chirp-scaling algorithm)[2]。CSA能够确保成像的准确度,而且可以适应不同的雷达扫描模式,例如,聚束模式(spotlight)、条带模式(stripmap)、扫描模式(scanSAR)[3]。并且CSA具有操作过程简单,计算复杂度低,成像效率高的优点。在SAR图像目标识别领域,深度学习表现出了突出的优势。卷积神经网络(CNN: convolution neural network)已广泛应用于在轨遥感平台[4]。在分析遥感图像的几何、纹理和空间分布特征时,CNN在计算效率和分类精度方面显示出其突出的优势[5]。循环神经网络(RNN: recurrent neural network)可用于时间变量相关的建模和预测,如LSTM(long short-term memory)[6]建立的水文模型。与此同时,混合神经网络(H-NN: hybrid neural networks)结合了CNN和RNN 2种网络模型特点,优势更为明显[7],并已经在遥感领域取得了巨大的成就。
SAR成像算法经过长期的发展基本已经成熟稳定,遥感领域中所应用的神经网络模型也主要以CNN和RNN为主,或者H-NN模型结构。针对遥感成像和智能处理中的大量并行计算,一般研究人员通常采用CPU+GPU的方案进行计算加速[8],但是星上工作环境对在轨AI平台低功耗的要求苛刻。根据多样化计算任务和工作环境的应用需求,我们借鉴领域专用架构(DSA: domain specific architecture)思想[9],将CSA与神经网络模型两类计算任务和异步计算过程进行统筹组织并协同处理,设计面向智能遥感图像处理的领域专用片上多处理器微架构(DS-CMP: domain specific chip multi-processors),实现CSA和神经网络模型的星上实时处理。目前,对于CSA和神经网络模型2类遥感任务,研究人员只研究各分立计算的加速方案。印度空间研究组织(IRSO)开发了基于DSP多处理器的SAR成像专用处理器(NRTP),可实现SAR的近似实时成像[10]。JPL(jet propulsion laboratory)采用VLSI+SOC的硬件优化方案,设计了机载SAR专用处理平台[11]。
针对神经网络模型的专用加速研究中研究人员提出了众多神经网络专用加速架构。Eyeriss[12]是一种直接针对卷积运算进行优化的神经网络加速器。ENVISION提出了一种基于DVAFS的能效可调CNN处理器[13]。DianNao处理器家族[14]包含了系列化的神经网络专用处理器:DianNao,DaDianNao,PuDianNao和ShiDianNao。DNPU[15]和Thinker[16]可用于H-NN专用加速。上述加速方案针对所属应用领域,各具优势,并且优势显著。但在轨遥感AI平台需要连续进行SAR成像和图像数据处理,此类分立加速方案并未考虑在轨智能系统中多遥感任务对系统级融合流水和同步并行计算的需求。
对SAR成像算法和神经网络模型的计算特征进行分析,并以此设计了一款应用于智能遥感AI平台的领域专用片上多处理器微架构DS-CMP(domain specific chip multi-processor)。DS-CMP芯片能够高效处理CSA和神经网络模型的联合计算任务,并满足星上在轨平台的低功耗要求。
1 智能遥感多任务算法分析智能遥感系统主要包括SAR实时成像和神经网络实时图像处理2类不同的计算任务。成像结束后, 神经网络模型对生成图像进行处理, 进行实时图像目标识别分类。CSA成像算法精度较高, 因此, 本文将采用CSA作为DS-CMP架构的主要研究对象。
1.1 CSA成像任务分析chirp-scaling算法(CSA)是SAR成像领域广泛使用的算法之一, 该模型可以实现多种雷达扫描模式。FFT(IFFT)过程进行16-bit量化操作, 相位操作执行单精度浮点运算时, 与全过程单精度浮点成像相比精度损失极低[17]。
规模为A×R的SAR成像计算负载总量如公式1所示。
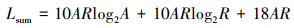
|
(1) |
如表 1所示, 我们对不同规模SAR成像过程的计算负载进行统计。表中统计了A×R规模的SAR成像过程中各类计算负载和计算负载总量。
| A×R | FFT(IFFT) | 相位相乘 | 负载总量 |
| 1 024×1 024 | 2.1×108 | 1.8×107 | 2.28×108 |
| 4 096×4 096 | 4.1×109 | 3×108 | 4.4×109 |
| 16 384×16 384 | 7.6×1010 | 4.8×109 | 8.08×1010 |
| 65 536×65 536 | 1.2×1012 | 1.2×1010 | 1.21×1012 |
目前用于遥感领域的神经网络模型主要分为深度卷积神经网络(DCNN)[18]和循环神经网络(RNN)2类[6]。
表 2列出了几种常见CNN基础模型的计算负载特征。从表 4中可以看出, 随着CNN模型不断加深, 计算负载总量相差达到数十倍。
| CNN模型 | 输入数据规模 | 计算负载量/ (MOPS) |
| AlexNet | 227×227 | 727 |
| ResNet | 224×224 | 4 000 |
| VGG-11 | 224×224 | 6 600 |
| VGG-16 | 224×224 | 16 000 |
| VGG-19 | 224×224 | 20 000 |
| 卷积模块 级数 |
特征图规模 | 卷积核数量 (单核通道数) |
| 1 | 224×224 | 64(1) |
| 2 | 112×112 | 128(64) |
| 3 | 56×56 | 256(128) |
| 4 | 28×28 | 512(256) |
| 5 | 14×14 | 512(512) |
| 隐层数 | 向量-矩阵运算 | 中间值累加 | 偏置量累加 | Element-wise | 激活运算 | 计算负载总量 |
| 32 | 8 192 | 8 064 | 128 | 128 | 160 | 16 672 |
| 64 | 32 768 | 32 512 | 256 | 256 | 320 | 66 112 |
| 128 | 131 072 | 130 560 | 512 | 512 | 640 | 263 296 |
如表 3所示, 卷积神经网络模型中, 随着特征图在模型中向后流动, 卷积核及核内通道数量迅速增加, 特征图尺寸急剧压缩。
对于RNN类网络, 如表 4所示, 以LSTM为例, 随着网络内隐层数量的增加, 计算负载总量差异达到十几倍。
从上述分析可知, 星上智能遥感系统需要规划多种计算资源和合理有效的计算调度策略, 确保实时完成智能遥感领域的系统级多重联合计算任务。
2 DS-CMP系统架构设计遥感智能系统需要进行在轨实时成像和智能处理, 领域专用CMP架构需要高效支持成像处理和以DNN为代表的智能处理。除了大量的计算单元外, 关键在于片上的数据组织和并行访问。
2.1 遥感图像带状Tile化处理方案星载遥感监测往往需要对大尺寸(例如16 384×16 384)遥感图像进行特征提取。在以往SAR成像及目标识别过程中, 由于图像尺寸很大, 尤其是神经网络模型中各级特征图规模逐级爆发式增长, 片内外数据访存带宽成为了智能系统多任务计算加速比的制约因素。
为了解决计算加速比天花板问题, 本文提出边成像边处理的系统级流水处理方案, 针对SAR图像的多处理任务采用带状Tile化并行流水计算策略。
根据Tile化计算策略, SAR回波Tile的成像结果直接送入神经网络模型进行处理, 在神经网络模型中, 多个图像Tile在模型内逐层流水处理, 不需等待1幅完整图像成像结束。将多个任务独立的并行计算流水组织为系统级并行计算流水, 建立SAR成像及图像处理的系统级流水线。采用带状Tile化方案, 多个连续SAR图像Tile在DS-CMP内并行流水处理, 直至1幅SAR图像的所有Tile在DS-CMP中成像及神经网络处理完毕。针对较大规模神经网络, 可灵活配置Tile尺寸或进行行数据递补方式以满足神经网络后端对特征图规模的计算需求。
采用带状Tile计算策略, 可以将成像和神经网络处理打通, 能够有效地将成像以及深度神经网络层间的数据依赖关系隔离在Tile内, 实现同一幅SAR图像成像和处理流程的跨层并行流水计算。
2.2 DS-CMP总体架构设计如图 1所示, DS-CMP架构内主要包括SAR成像处理器(SIP: SAR imaging processor)、神经网络处理器(NCP: neurocomputing processor)、同步组织buffer阵列以及参数缓存、IO和存储接口。在并行执行SAR实时成像和遥感图像智能处理的工作流程中, 计算数据由SIP向NCP持续传递。为了确保成像输出数据能够并行流水送入NCP内, 并避免数据交互过程中可能出现的数据秩序混乱, 设计了数据缓存与组织可同步执行的buffer网络阵列以及多路buffer路由模块, 用来完成NCP计算前的数据准备工作。设计了独立的参数buffer, 用来为计算过程提供相关计算参数, 从而保证计算单元的高效利用。

|
| 图 1 DS-CMP总体架构框图 |
SIP负责进行SAR实时成像, 顶层框架如图 2所示, 主要由SAR数据计算阵列、数据混洗存储buffer、指令寄存器和译码单元构成, 并行流水执行SAR成像计算。考虑到精度和硬件效率, 采用16位定点FFT运算和单精度浮点相位校正运算。阵列中设计了16×16规模的定点PE阵列用于FFT(IFFT)运算、2×16规模的FPE用于单精度浮点相位校正计算。单个处理器内设计有2个相同的异构计算阵列, 可同时执行2个块成像的计算任务。SIP内, 针对成像处理的数据流特征, 设计了专门的缓存结构。成像结束后, 图像数据送入buffer网络阵列中, 进行NCP计算前源数据的预组织处理。

|
| 图 2 SIP架构框图 |
NCP负责执行神经网络模型计算, 顶层框架如图 3所示。

|
| 图 3 NCP架构框图 |
主要包含3个关键部件: 神经计算阵列, 处理器内部buffer模块和资源控制组件。设计了4个8×9的异构PE神经计算阵列, 每个阵列内包含4种异构8-bit定点计算资源: PE、RPE、PPE和LPE。PE用于执行神经网络中的MAC运算, RPE用于对中间结果进行累加并执行ReLU激活操作。PPE在RPE的基础上增加了池化计算单元。LPE是对PPE进行功能扩展, LPE可进行中间值累加, ReLU函数运算, 池化操作以及查表运算(Sigmoid和Tanh等)。通过对操作数线性量化后微调, 8-bit定点量化的网络模型精度损失小于1%。以经典混合神经网络LRCN为例分析, 与16-bit定点量化方案相比, 8-bit定点量化的LRCN网络整体精度损失也仅有1.8%。NCP中设计了一种能够对源数据进行灵活截取和拼接的多bank存储结构, 如图 4所示, 每个bank用于缓存一行SAR图像数据(即同一行流水数据)。在FC和RNN计算过程中不需要进行数据拼接。获取计算指令后译码器对处理器内各部件进行调度。

|
| 图 4 Chip buffer通道内网络结构 |
智能遥感系统涉及的2类差异化工作任务中, 数据流单向流动: SIP→NCP。我们设计了一个用于图像Tile缓存和数据整合同步进行的buffer阵列网络, 如图 4所示, 网络内包含5个buffer阵列通道。图像数据通过桥梁送入NCP内。单个Buffer通道结构如图 4所示。bank分为拼接数据bank(BDB)和流水数据bank(SDB)。通过buffer内的各种路由模块负责数据访存过程中的bank资源分配和数据拼接流水。
SAR成像和神经网络计算整合处理过程作为系统级任务可进行并行流水处理。SAR成像采用Tile化多行处理, 行(列)间无数据依赖关系, 可进行多行(列)数据并行流水操作。成像输出数据满足神经网络特征图的Tile分割需求时, 图像数据即可送入NCP内进行处理, 神经网络(如VGG-11模型)子任务计算过程中, 计算结果逐级传递, 由于存在池化操作, Tile长度逐渐缩短, 单个Tile的数据规模减小, 需进行行间数据补偿满足卷积运算需求。
进行卷积神经网络计算过程时, 相邻图像数据块之间涉及2-D数据重用, 因此在图像数据进入NCP之前需进行数据缓存以及Tile间数据拼接组织预处理, 数据Tile拼接组织策略如图 5所示。SAR图像规模为m×n, 图像矩阵逐行分段写入同一个bank阵列内。buffer网络内实现数据Tile的首尾数据重用, 数据逐段送入同一bank中, 根据重用需求, 前一个数据段的最后2个数据需要拼接在后一个数据段的开头后送入NCP内, 确保卷积计算过程不会造成数据丢失。

|
| 图 5 图像矩阵列间拼接缓存策略 |
例如图 5中, 对第一行图像数据进行分段, 第一段数据为(D0, y~D0, y+i), 第二段数据为(D0, y+i+1~D0, y+j), 以此类推进行分段。2段数据按顺序送入SDB的Bank0中, 待拼接数据D0, y+i和D0, y+i-1送入BDB的Bank0中进入拼接队列。第一段数据送入NCP内, 与其他相邻bank内的第一段数据完成行拼接, 实现行数据重用后送入计算阵列; 第二段数据送入NCP前将数据从拼接队列中选取首尾拼接数据(D0, y+i和D0, y+i-1), 与第二段数据路由拼接后(拼接后数据: D0, y+i-1~D0, y+j)送入NCP内buffer中, 并与相邻bank内数据完成行拼接。后续数据访存过程以此类推, 直至计算结束。在FC/RNN计算过程中, 数据访存没有重用过程, 图像数据分段后并行流水送入NCP内进行计算即可。
2.4 DS-CMP系统任务流映射针对Tile化总体计算策略, 以及对Tile规模有效性持续保持的需求, 设计了一种带状Tile化的SAR图像多处理任务并行流水计算策略, 如图 6所示。

|
| 图 6 Tile化数据流组织及访存策略 |
成像过程中, Tile规模为16×32, 如图 7左上角部分所示, 对回波Tile空间进行逐行计算, 首先对第一级首个连续的7个Tile进行成像操作(IT-0-0~IT-0-6), 第二次对第二行7个连续Tile进行成像操作(IT-1-0~IT-1-6), 直至最后一行Tile(IT-m-0~IT-m-6)成像处理完成, 第一级成像计算结束, 成像结果逐行送入数据预组织buffer阵列内; 后续对第二级7个连续Tile(IT-0-7~IT-0-13)进行成像操作, 直至最后一行Tile(IT-m-7~IT-m-13)成像处理完成, 第二级成像计算结束; 以此类推, 完成全部成像过程, 各级成像结果逐行送入数据预组织buffer阵列内。神经网络处理过程不需等待完整SAR图像成像结束, 对大规模SAR图像数据采用Block化映射策略, 当前Block尺寸设为224×224(根据不同的应用, Block可灵活划分)。如图 7右半部分所示, 预处理buffer内的数据组织整理过程中, 对SAR图像Block进行第二次Tile化, 神经网络对Block内多个数据Tile执行层间流水处理, 不需等待单个图像Block数据全部缓存结束。以VGG-11为例, 在神经网络模型Tile化流水计算过程中, 第一级计算模块的输入数据划分为28个带状Tile(尺寸为8×224);前3级输入特征图带状Tile划分过程以此类推。由于不同卷积模块级的输入特征图尺寸差异较大, 因此每级输入特征图的带状Tile化方案不同。如图 7所示, 第四级特征图分为3个(2种尺寸)带状Tile, 第五级输入特征图同理划分。由于神经网络模型内全部采用3×3规模的卷积窗口, 因此Tile化卷积计算过程需要进行Tile内行间数据重用补偿, Tile内数据组织过程如图 8所示。

|
| 图 7 图像处理Tile计算空间划分 |

|
| 图 8 Tile内数据组织过程 |
多个Tile能够在多层网络间进行并行流水计算, 并且Tile内可并行执行多卷核/多卷积通道运算, 从而实现SAR图像在整个神经网络内的并行流水处理过程。从表 4中可以看出, 网络模型对特征图进行×2窗口规模进行池化操作后, 每级特征图的输出尺寸为原图像尺寸的1/4。因此, Tile化流水计算过程中, 经过n(≥2)级池化后, 特征图未达到最后一级, Tile尺寸已经不能满足计算要求。通过数据同步拼接, 在整体计算过程中必须始终确保Tile规模的有效性。
3 片上多处理器系统性能分析在Synopsys仿真平台下, 采用28 nm工艺技术, 芯片额定1.0 V电压条件下对DS-CMP进行逻辑综合和功耗分析。芯片仿真综合数据如表 5所示。在芯片性能评估过程中, 系统工作频率400 MHz, 采用CSA成像算法以及VGG-11经典网络模型作为在轨遥感AI平台的系统任务测试基准。
| 项目 | 数据 |
| 工艺库 | TSMC 28 nm HPC |
| 面积 | 4.27 mm×4.27 mm |
| 工作频率 | 400 MHz |
| 供电电压 | 1.0 V |
| 峰值功耗 | 1.87 W |
在饱和工作状态下, 对多幅SAR图像执行并行流水处理过程, 得出每幅图像的平均处理时间, 以及单幅图像处理过程的平均吞吐率。
3.1 DS-CMP架构性能分析通过不同规模成像过程对SAR成像处理器性能进行测试。成像过程采用Tile化流水计算过程, 多行(列)回波数据并行处理。从表 6中可以看出处理器的峰值吞吐率为115.2 GOPS, 随着成像规模的增加, 成像加速效果明显。16 384×16 384规模的SAR成像时间为8.2 s, 常规雷达(例如:高分-三卫星)执行16 384×16 384规模的数据采集时间为8 s, 因此所提出的处理器架构方案能够实现SAR实时成像处理。
| 成像规模 | 成像算法 | 主频/MHz | 功耗/mW | 成像时间/s | 峰值吞吐率/GOPS |
| 1024×1024 | CSA | 400 | 137 | 0.04 | 115.2 |
| 2 048×2 048 | 0.17 | ||||
| 6 472×3 328 | 0.68 | ||||
| 16 384×16 384 | 8.20 | ||||
| 30 000×6 000 | 5.54 | ||||
| 32 768×32 768 | 32.9 |
表 7统计了神经网络模型处理不同规模SAR图像的完整计算时间。从表 7中可以看出, 由于目前针对神经网络处理, 计算资源相对充裕, 因此与成像过程相比, 相同SAR图像规模的神经网络处理时间要普遍稍小于SAR成像时间。
| SAR图像规模 | 网络模型 | 主频/MHz | 功耗/W | 处理时间/s | 峰值吞吐率/ TOPS |
| 1 024×1 024 | VGG-11 | 400 | 1.13 | 0.04 | 9.77 |
| 2 048×2 048 | 0.16 | ||||
| 6 472×3 328 | 0.66 | ||||
| 16 384×16 384 | 7.90 | ||||
| 30 000×6 000 | 5.51 | ||||
| 32 768×32 768 | 32.3 |
遥感图像的多处理任务作为系统级任务, 实现实时计算过程需对整体系统任务进行协同调度。根据表 6和表 7分析可以看出, 在当前的配置下, SAR成像时间主导系统的全部任务处理时间。如表 8所示, 针对16 384×16 384规模, 多任务计算过程耗时8.6 s, 满足实时智能处理的需求。
| SAR图像规模 | 计算模型 | 主频/MHz | 功耗/W | 处理时间/s | 吞吐率/ TOPS |
| 1 024×1 024 | CSA→VGG-11 | 400 | 1.83 | 0.07 | 9.89 |
| 2 048×2 048 | 0.23 | ||||
| 6 472×3 328 | 0.75 | ||||
| 16 384×16 384 | 8.60 | ||||
| 30 000×6 000 | 5.73 | ||||
| 32 768×32 768 | 33.78 |
在星载SAR智能遥感处理过程中,面对不同的应用需要选择不同的神经网络模型,DS-CMP架构需要具备可差异化扩展实现的能力。本文采用CSA以及经典型经网络模型VGG-11作为DS-CMP架构的主要研究对象,同时也对规模较大或规模较小的神经网络模型(分别以VGG-19和AlexNet为例)进行了分析。根据当前DS-CMP架构的配置方案,处理较小规模的神经网络模型,智能遥感系统任务的处理时间能够满足星载实时性的需求,如表 9所示,SAR成像时间占主导,但是架构内的神经网络处理器阵列处于不饱和工作状态,此时DS-CMP处理架构的能效较低。相反,处理较大规模的神经网络模型,神经网络模型的处理时间成为系统任务处理时间的主导因素,此刻DS-CMP架构的资源配置方案已无法满足系统任务处理的实时性需求,如表 10所示,表明需要增加NCP规模。不同神经网络模型的规模差异较大,因此可以根据不同神经网络模型的计算负载区间,在确保星上智能遥感任务实时性需求和芯片高能效的前提下,合理确定DS-CMP架构内的处理资源配置,实现DS-CMP处理器。在上述的差异化扩展过程中,DS-CMP架构、多任务间的数据组织和流水处理过程不需进行重大调整。
| SAR图像规模 | 计算模型 | 主频/MHz | 功耗/W | 处理时间/s | 吞吐率/ TOPS |
| 1 024×1 024 | CSA→AlexNet | 400 | 1.83 | 0.07 | 9.89 |
| 2 048×2 048 | 0.23 | ||||
| 6 472×3 328 | 0.75 | ||||
| 16 384×16 384 | 8.40 | ||||
| 30 000×6 000 | 5.68 | ||||
| 32 768×32 768 | 33.73 |
| SAR图像规模 | 计算模型 | 主频/MHz | 功耗/W | 处理时间/s | 吞吐率/ TOPS |
| 1 024×1 024 | CSA→VGG-19 | 400 | 1.83 | 0.24 | 9.89 |
| 2 048×2 048 | 0.77 | ||||
| 6 472×3 328 | 2.36 | ||||
| 16 384×16 384 | 28.33 | ||||
| 30 000×6 000 | 19.28 | ||||
| 32 768×32 768 | 106.53 |
本文提出了一种可执行多任务协同并行处理的片上异构多处理架构(DS-CMP),该架构用于航天领域在轨遥感AI平台的多任务实时处理,如SAR成像和遥感图像目标识别。提出了一种针对分立计算任务Tile化的计算策略,支持在轨多任务同步并行流水计算,同一幅图像的成像计算过程和神经网络模型计算过程可并行流水执行。本文以目前星载SAR最常用的CSA成像算法以及VGG-11神经网络模型为例,对多任务协同处理架构进行评估,执行规模为16 384×16 384的遥感成像与处理综合计算任务耗时8.6 s,芯片整体功耗1.83 W,满足在轨遥感AI平台对实时性和低功耗的严格要求。
本文所设计的面向智能遥感领域的高能效DS-CMP架构,具有灵活的可扩展性。针对不同的成像规模区间和神经网络算法模型,确定SAR成像子处理模块和NCP阵列的合理规模,可以扩展衍生出系列化的智能遥感处理芯片,DS-CMP架构、多任务间的数据组织和流水处理过程不变。从而解决SAR成像模型和神经网络模型不同组合方式的处理需求。
| [1] | HUANG P, LIAO G, YANG Z, et al. A fast SAR imaging method for ground moving target using a second-order WVD transform[J]. IEEE Trans on Geoence & Remote Sensing, 2016, 54(4): 1940-1956. |
| [2] | WANG Z, LIU M, AI G, et al. Focusing of bistatic SAR with curved trajectory based on extended azimuth nonlinear chirp scaling[J]. IEEE Trans on Geoscience and Remote Sensing, 2020, 99: 1-20. |
| [3] | CHEN Q, YU A, SUN Z, et al. A multi-mode space-borne SAR simulator based on SBRAS[C]//Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 2012: 4567-4570 |
| [4] | KOMISKE P T, METODIEV E M, SCHWARTZ M D. Deep learning in color: towards automated quark/gluon jet discrimination[J]. Journal of High Energy Physics, 2017(1): 110. DOI:10.1007/JHEP01(2017)110 |
| [5] | XU X, LI W, RAN Q, et al. Multisource remote sensing data classification based on convolutional neural network[J]. IEEE Trans on Geoence & Remote Sensing, 2018, 99: 1-13. |
| [6] | KRATZERT F, KLOTZ D, BRENNER C, et al. Rainfall-runoff modelling using long short-term memory(LSTM) networks[J]. Hydrology & Earth System Sciences, 2018, 22(11): 6005-6022. |
| [7] | AWAIS M, LONG X, YIN B, et al. A hybrid DCNN-SVM model for classifying neonatal sleep and wake states based on facial expression in video[J]. IEEE Journal of Biomedical and Health Informatics, 2021, 25(5): 1441-1449. |
| [8] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E, et al. Image net classification with deep convolutional neural networks[J]. Advances in Neural Information Proceesing Systems, 2012, 25(2): 1-9. |
| [9] | HENNESSY J L, PATTERSON D A. Computer architecture: a quantitative approach[M]. 6th Edition. Cambridge: Morgan Kaufmann Publishers Inc, 2018. |
| [10] | DESOLI G. 14.1 a 2.9 TOPS/W deep convolutional neural network SoC in FD-SOI 28 nm for intelligent embedded systems[C]//2017 IEEE International Solid-State Circuits Conference, San Francisco, CA, 2017: 238-239 |
| [11] | LOU Y, CLARK D, MARKS P, et al. Onboard radar processor development for rapid response to natural hazards[J]. IEEE Journal of Selected Topics in Applied Earth Obaservations and Remote Sensing, 2016, 9(6): 2770-2776. DOI:10.1109/JSTARS.2016.2558505 |
| [12] | MOONS B, VERHELST M. A 0.3-2.6 TOPS/W precision-scalable processor for real-time large-scale ConvNets[C]//2016 IEEE Symposium on VLSI Circuits, Honolulu, HI, 2016: 1-2 |
| [13] | BERT Moons, ROEL Uytterhoeven, WIM Dehaene, et al. 14.5 envision: a 0.26-to-10 TOPS/W subword-parallel dynamic-voltage-accuracy-frequency-scalable convolutional neural network processor in 28 nm FDSOI[C]//Solid-State Circuits Conference, 2017 |
| [14] | CHEN Y, CHEN T, XU Z, et al. DianNao family: energy-efficient hardware accelerators for machine learning[J]. Communications of the ACM, 2016, 59(11): 105-112. DOI:10.1145/2996864 |
| [15] | SHIN D, LEE J, LEE A, et al. 14.2 DNPU: an 8.1 TOPS/W reconfigurable CNN-RNN processor for general-purpose deep neural networks[C]//IEEE International Solid-state Circuits Conference, 2017 |
| [16] | YIN S. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications[J]. IEEE Journal of Solid-State Circuits, 2018, 53(4): 968-982. DOI:10.1109/JSSC.2017.2778281 |
| [17] | YANG Chen, LI Bingyi, CHEN Liang, et al. A spaceborne synthetic aperture radar partial fixed-point imaging system using a field-programmable gate array-application-specific integrated circuit hybrid heterogeneous parallel acceleration technique[J]. Sensors, 2017, 17(7): 1493-1516. DOI:10.3390/s17071493 |
| [18] |
李林, 张盛兵, 吴鹃. 面向图像识别的深度学习VLIW处理器设计[J]. 西北工业大学学报, 2020, 38(1): 216-224.
LI Lin, ZHANG Shengbing, WU Juan. Design of deep learning VLIW processor for image recognition[J]. Journal of Northwestern Polytechnical University, 2020, 38(1): 216-224. (in Chinese) DOI:10.3969/j.issn.1000-2758.2020.01.027 |
