



水下回收技术极大地提高了AUV续航能力,路径精确跟踪是实现水下回收的关键[1]。欠驱动AUV通过速度和姿态角耦合控制调整自身航行位置,从而实现路径跟踪控制。在回收的不同阶段,AUV的实际航行速度会产生较大变化,为路径精确跟踪带来困难[2-3]。
许多传统控制算法都曾被应用到AUV路径跟踪控制问题当中,Min等[4]设计了AUV路径点跟踪PD控制器,鲁棒性较差;张磊[5]采用遗传算法对模糊跟踪控制器进行了优化,算法性能对专家知识依赖较大;王宏健等[6]采用二阶滤波避免了反步法解析求导的复杂过程,能够实现AUV路径的精确跟踪,但系统鲁棒性较弱;王金强等[7-8]针对一种新型飞翼式AUV的位置跟踪问题,采用自适应神经网络对滑模控制器进行优化补偿,但未考虑AUV航速变化对路径跟踪控制的影响,且一组控制参数难以满足不同航行工况的控制需求。近年来随着相关技术进步,模型预测和强化学习等基于数据的算法同样被应用到AUV的跟踪控制当中。Shen等[9]采用滚动优化方法对AUV进行了路径优化与跟踪控制一体化设计;Sun等[10]采用深度强化学习方法设计了AUV三维路径跟踪控制器;Shi等[11]采用多逆伪Q学习算法设计了轨迹跟踪控制算法;姚绪梁等[12]采用模型预测控制与滑模控制方法对AUV直线路径进行了仿真跟踪。这些方法对AUV模型准确性依赖较低,对外干扰也具有良好的鲁棒性,但算法结构复杂,经大量运算才能得到最优控制律,难以直接应用到工程实践。若将传统算法与学习网络相结合,对多种航行工况进行离线训练,将训练后的学习参数应用于在线控制,可降低AUV实时优化的运算量,加快实时运动控制收敛速度,提高AUV在不同航速及外扰动下的路径跟踪性能。
1 跟踪导引律及姿态控制器设计欠驱动AUV具有左右对称性, AUV与水下回收装置处在同一深度上, 有利于AUV回收对接。AUV水平面路径跟踪控制原理如图 1所示, 已知一条AUV全局回收路径曲线S[3], 离散化路径点序列为P(p1, p2, …, pn), 其中pi(ξi, ζ0, ηi), i=1, 2, …, n, 路径点深度ζ0保持不变。AUV路径跟踪控制转化以下2个子问题组合控制: 即调整目标路径航向ψcmd的导引控制, 以及对ψcmd的航向角跟踪控制。

|
| 图 1 欠驱动AUV水平面路径跟踪控制原理图 |
为实现水平面路径跟踪, AUV需要保持在指令深度ζ0处航行, 控制原理如图 2所示。

|
| 图 2 AUV深度控制原理图 |
水平面路径跟踪示意如图 3所示, pi(ξi, ζ0, ηi)和pi+1(ξi+1, ζ0, ηi+1)为相邻的2个路径点, 两点连线即为期望路径, ψ0, ψ分别表示路径切线方向和AUV当前航向, εe表示AUV当前位置(ξ, ζ, η)距路径段pipi+1的位置偏移, 计算如(1)式所示。采用如(2)式的AUV目标路径航向导引控制律, 其中c0, c1, c2, ε0, εmax, ψmax均为大于零的常数, 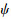

|
| 图 3 AUV路径跟踪示意图 |
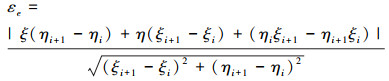
|
(1) |
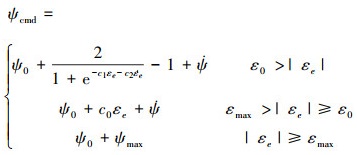
|
(2) |
AUV航向导引律(2)给出了AUV跟踪期望路径所需要的指令航向角度, 而对指令航向角的精确稳定跟踪是实现AUV全局路径跟踪的关键。AUV水平面偏航运动方程如(3)式所示:

|
(3) |
式中: ωy, 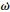

定义滑模面函数如(4)式, 其中cψ>0, ψe=ψd-ψ, ψd表示航向控制指令, 与(2)式中ψcmd数值大小相同。取航向跟踪控制律如(5)式所示, 则AUV航向跟踪误差ψe在有限时间内渐进收敛。

|
(4) |

|
(5) |
系统稳定性证明如下: 取李雅普诺夫函数为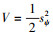
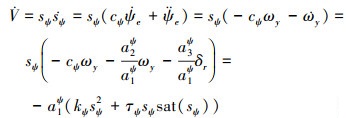
|
(6) |
式中: sat(·)为饱和函数。根据图 1, ψcmd是路径跟踪大回路导引控制器的输出, 而ψd是航向控制小回路的指令输入, 二者数值相同, 但控制含义不同。在设计航向控制器时, ψd常取为常值, 通过设置(5)式中的控制器参数, 调整控制性能, 然后实现对时变航向指令的跟踪。(6)式中, AUV的转动惯量参数a1ψ>0, 当sψ≠0时, 若取参数kψ, τψ均为大于零的正常数, 则
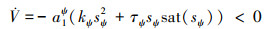
|
恒成立, 因此, 根据Barbalat引理, 对于运动方程(3)式、滑模切换面(4)式以及控制律(5)式组成的闭环系统, 系统具有渐进稳定性, 误差在有限时间内收敛。
1.3 AUV俯仰跟踪控制律AUV俯仰运动方程如(7)式所示, ωz,

|
(7) |
式中
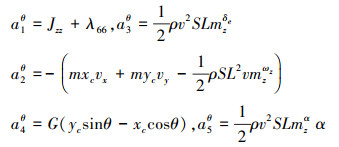
|
AUV回收路径指令深度为ζ0, 深度误差ζe=ζ0-ζ, 选取理想深度动态偏差特性为

|
(8) |
则可得到: 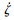

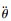
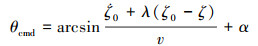
|
(9) |
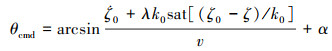
|
(10) |
记俯仰角误差θe=θd-θ, 滑模面如(11)式所示, 取俯仰跟踪控制律如(12)式所示, 则俯仰角误差θe在有限时间内收敛。
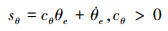
|
(11) |
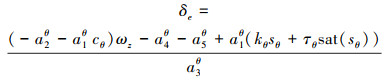
|
(12) |
系统稳定性证明: 取李雅普诺夫函数为V=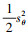
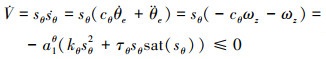
|
(13) |
与航向角控制同理, AUV艉部舵面无法直接实现深度控制, 只有通过图 2中的双回路, 在实现俯仰角指令θd的跟踪前提下, 实现深度控制, 因而θd也被认为是常值。根据Barbalat引理, 对于运动方程式(7)、滑模切换面式(11)以及控制律式(12)组成的闭环系统, 系统具有渐进稳定性, 误差在有限时间内收敛。
2 RBF网络Q学习参数优化由航向及俯仰运动方程(3)式和(7)式可知, 当航速保持恒定时, AUV运动状态的响应特性主要与舵角δr和δe变化有关, 舵角控制律(5)式和(12)式中, 除AUV自身状态变量ψ, wy, θ, wz等外, 滑模控制参数c(·), k(·), τ(·)的取值直接影响舵角变化过程, 参数的选取决定了系统控制特性。
在AUV回收对接中, 受转速指令、转向、浮潜运动以及时变扰流等影响, AUV航速难以保持稳定状态, 传统方法中同一组滑模控制参数不利于保证AUV全局路径跟踪控制性能。本节采用学习算法, 根据AUV航行状态反馈, 实时优化滑模控制参数, 提高系统性能。
2.1 Q学习算法参数定义应用Q学习算法进行AUV控制优化, 首要工作是根据滑模控制特点定义马尔科夫决策四元组E={S, A, P, R}, 即状态空间S、动作空间A、转移概率P和瞬时奖赏值R。以航向控制优化为例说明如下: 考虑到算法的通用性, 选取AUV前向速度、航向角误差及其导数作为系统状态量, 即s=[vx ψe

|
(14) |
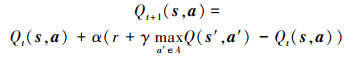
|
(15) |
为避免出现“维数灾”现象[14], 采用RBF神经网络建立系统状态s、动作a和Q值间的映射关系, 其中输入层为状态量s=[vx ψe
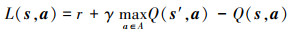
|
(16) |

|
(17) |
AUV当前状态s经过RBF网络正向传播得到所有控制参数对应的Q(s, a)值, 选取最大Q值对应的动作值a, 将其代入到航向及俯仰控制器, AUV运动状态发生改变, 得到AUV新的状态s′并计算瞬时奖励值函数r的大小, 根据(16)式和(17)式进行误差反向传播, 更新RBF网络连接权值。由于预先并不能获取Q(s, a)的期望值, 需要通过(15)式进行Q值的迭代, 所以将AUV新的状态s′输入至更新后的RBF网络, 选取最大Q值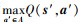
根据上述过程, RBF-Q学习优化控制原理如图 4所示, 图中同时给出了俯仰角优化控制原理, 定义的网络状态输入s=[vx θe

|
| 图 4 RBF-Q学习参数优化控制原理图 |
建立数值仿真环境, 依次进行AUV不同航速下的定深、定向控制仿真, 以及全局路径跟踪控制仿真, 将RBF-Q学习参数优化控制方法与传统滑模控制(SMC)方法进行对比, 分析算法特点。
仿真中采用了某AUV空间六自由度非线性模型, 舵角δr和δe限幅均为±15°, AUV航速区间为3.5~11 kn, 外部扰动主要体现在AUV速度分量vx, vy, vz上的噪声扰动。算法主要参数取值如下: 学习率α=0.5, 折扣系数γ=0.9, 航向及俯仰控制参数c(·), k(·)和τ(·)的取值个数为10, 综合考虑超调量、稳态误差及响应速度, AUV航速为8 kn时, 滑模控制律(5)式和(12)式中的最优参数取值如表 1所示, 其中Δ表示取值间隔。RBF-Q学习算法需要对AUV不同航速、航向角度指令和俯仰角度指令进行离线学习训练, 表 2给出了RBF-Q学习网络训练的取值范围, 为避免过拟合, AUV航速增加了一定幅值的随机噪声。
| 传统滑模控制参数 | Q学习优化参数范围 | ||||
| cψ | kψ | τψ | cψ, Δ=0.3 | kψ, Δ=0.5 | τψ, Δ=0.02 |
| 3 | 5 | 0.2 | [1.8, 4.5] | [3, 7.5] | [0.12, 0.3] |
| cθ | kθ | τθ | cθ, Δ=0.3 | kθ, Δ=0.5 | τθ, Δ=0.02 |
| 4 | 3.5 | 0.1 | [2.8, 5.5] | [1.5, 6] | [0.02, 0.2] |
| 指令参数 | 取值范围 | 取值间隔 |
| 航速vx/kn | [3.5, 11] | 1.5 |
| 航向角ψd/(°) | [-90, 90] | 2.5 |
| 俯仰角θd/(°) | [-40, 40] | 1.5 |
在回收过程中, AUV存在不同航速下的定深、定向航行状态, 选取工况为: 航向角ψ由0°定向30°, 深度ζ由175 m定深160 m, 无外扰动条件下, 选取AUV航速vx为8 kn和6 kn进行对比, 结果如图 5和图 6所示; 在6 kn航速下考虑时变扰动, 航向及深度指令不变, 仿真结果如图 7所示。

|
| 图 5 无扰动8 kn航速下AUV定向定深控制响应 |

|
| 图 6 无扰动6 kn航速下AUV定向定深控制响应 |

|
| 图 7 时变扰流, 6 kn航速下AUV定向定深控制响应 |
从图 5可以看到, 2种算法下AUV定向、定深响应曲线近似重合, 航向角ψ、俯仰角θ及深度ζ响应均具有较小的超调量和稳态误差, 表明在8 kn航速下, RBF-Q学习算法对滑模控制器的改善效果很小。但当AUV航速变化为6 kn时, AUV艉部舵效下降, 传统滑模控制器的深度响应曲线出现超调量约16.7%, 如图 6所示, RBF-Q学习算法将深度响应的超调量降低至6.6%, 在航向角响应中, RBF-Q学习算法比传统滑模算法响应时间缩短了10 s, 控制效果改善显著。随着外部扰动的增加, 如图 7所示, RBF-Q学习控制器在稳态精度、响应速度和超调量方面, 均比传统滑模算法具有更好的表现, 二者在航向稳态误差相差了约5.5°, 深度误差相差了约2 m, 但这些控制效果的改善存在一定的代价, 即RBF-Q学习算法根据AUV航速、跟踪误差及其变化率持续优化滑模控制器参数。在8 kn无扰动条件下, 控制参数基本无变化, 初始参数即在最优解附近。当航速减小为6 kn, 算法对控制器进行了短暂优化, 之后随着误差收敛优化过程结束, 达到稳定, 而扰动的增加, 使RBF-Q学习网络持续对参数进行优化, 以降低扰动影响。
3.2 AUV全局路径跟踪控制仿真为分析2种算法在AUV路径跟踪控制中的性能, 本节对先前研究成果[3]中的路径进行跟踪仿真, 该路径为水平面内的避障回收路径, 离散路径点个数为100, 航行深度设定为ζ0=120 m, 根据本文(1)式和(2)式进行跟踪导引, 依次采用传统滑模控制方法和RBF-Q学习参数优化控制方法对路径进行跟踪仿真, 结果如图 8和图 9所示。

|
| 图 8 回收海域有障碍物时, AUV路径跟踪控制曲线 |

|
| 图 9 AUV路径跟踪航向及深度控制响应 |
图 8给出了AUV在E-ξη平面内的航行轨迹, AUV的起点与规划路径起点不重合, 回收路径上存在多个障碍物, 外部扰动为时变海流。在路径的起始阶段, 传统滑模控制算法下的AUV轨迹更加接近期望轨迹, 随着学习网络的持续优化, 在路径中后段, RBF-Q学习算法控制下的AUV轨迹与期望轨迹基本重合, 而传统滑模控制算法下的AUV轨迹始终与期望轨迹存在偏差。图 9给出了AUV跟踪过程中航向角和深度响应曲线。为避开水中障碍并到达路径终点, AUV进行了多次转向运动, RBF-Q学习算法对时变航向指令具有准、更快的响应效果, 而且在深度保持控制中, RBF-Q学习算法的振荡幅值更小, 稳态控制精度更高。
4 结论AUV水下回收对接过程中, 航行速度受推进器转速、姿态变化以及时变扰流等因素影响难以保持稳定, 使艉部舵面的操纵性能发生改变, 导致同一组控制参数无法满足复杂环境下的姿态控制和路径跟踪控制性能要求。针对上述问题, 本文采用RBF网络Q学习算法对传统滑模控制参数进行优化, 根据AUV当前航速、指令误差及其变化律选择相应的控制参数, 经过大量离线训练获取学习网络权重参数, 将其应用到在线控制当中, 仿真结果表明RBF-Q学习算法能够有效改善AUV姿态控制和路径跟踪控制的性能, 在相同条件下, RBF-Q学算法比传统滑模算法具有更小的超调量和稳态误差, 响应速度更快。在后续研究中, 针对舵角控制输入中出现的非线性抖动问题作进一步优化, 逐步进行AUV路径跟踪控制的实航试验研究。
| [1] | RIDAO P, CARRERAS M, RIBAS D, et al. Intervention AUVs: the next challenge[J]. Annual Reviews in Control, 2015, 40: 227-241. DOI:10.1016/j.arcontrol.2015.09.015 |
| [2] | SHI Y, SHEN C, FANG H, et al. Advanced control in marine mechatronic systems: a survey[J]. IEEE/ASME Trans on Mechatronics, 2017, 22(3): 1121-1131. DOI:10.1109/TMECH.2017.2660528 |
| [3] | LI Z, LIU W, GAO L, et al. Path planning method for AUV docking based on adaptive quantum-behaved particle swarm optimization[J]. IEEE Access, 2019, 7: 78665-78674. DOI:10.1109/ACCESS.2019.2922689 |
| [4] | MIN J K, WOON-KYUNG Baek, KYOUNGNAM Ha, et al. Way-point tracking for a hovering AUV by PID controller[C]//15th International Conference on Control, Automation and Systems, BEXCO, Busan, Korea, 2015 |
| [5] |
张磊. 基于遗传算法优化的水下机器人路径跟踪模糊控制技术研究[D]. 杭州: 浙江大学, 2017 ZHANG Lei. Research on fuzzy control of underwater vehicle path following based on genetic algorithm optimization[D]. Hangzhou: Zhejiang University, 2017(in Chinese) |
| [6] |
王宏健, 陈子印, 贾鹤鸣, 等. 基于滤波反步法的欠驱动AUV三维路径跟踪控制[J]. 自动化学报, 2015, 41(3): 631-645.
WANG Hongjian, CHEN Ziyin, JIA Heming, et al. Three-dimensional path-following control of underactuated autonomous underwater vehicle with command filtered backstepping[J]. Acta Automatica Sinica, 2015, 41(3): 631-645. (in Chinese) |
| [7] |
王金强, 王聪, 魏英杰, 等. 未知海流干扰下自主水下航行器位置跟踪控制策略研究[J]. 兵工学报, 2019, 40(3): 583-591.
WANG Jingqiang, WANG Cong, WEI Yingjie, et al. Position tracking control of autonomous underwater vehicles in the disturbance of unknown ocean currents[J]. Acta Armamentarii, 2019, 40(3): 583-591. (in Chinese) DOI:10.3969/j.issn.1000-1093.2019.03.018 |
| [8] |
王金强, 王聪, 魏英杰, 等. 欠驱动AUV自适应神经网络反步滑模跟踪控制[J]. 华中科技大学学报, 2019, 47(12): 12-17.
WANG Jingqiang, WANG Cong, WEI Yingjie, et al. Path following of an underactuated AUV based on adaptive neural network backstepping sliding mode control[J]. Journal of Huazhong University of Science and Technology, 2019, 47(12): 12-17. (in Chinese) |
| [9] | SHEN C, SHI Y, BUCKHAM B. Integrated path planning and tracking control of an AUV: a unified receding horizon optimization approach[J]. IEEE/ASME Trans on Mechatronics, 2017, 22(3): 1163-1173. DOI:10.1109/TMECH.2016.2612689 |
| [10] | SUN Y, ZHANG C, ZHANG G, et al. Three-dimensional path tracking control of autonomous underwater vehicle based on deep reinforcement learning[J]. Journal of Marine Science and Engineering, 2019, 7(12): 443. DOI:10.3390/jmse7120443 |
| [11] | SHI W, SONG S, WU C, et al. Multi pseudo q-learning-based deterministic policy gradient for tracking control of autonomous underwater vehicles[J]. IEEE Trans on Neural Networks and Learning Systems, 2019, 30(12): 3534-3546. DOI:10.1109/TNNLS.2018.2884797 |
| [12] |
姚绪梁, 王晓伟. 基于MPC导引律的AUV路径跟踪和避障控制[J]. 北京航空航天大学学报, 2020, 46(6): 1053-1062.
YAO Xuliang, WANG Xiaowei. Path following and obstacle avoidance control of AUV based on MPC guidance law[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(6): 1053-1062. (in Chinese) |
| [13] |
严卫生. 鱼雷航行力学[M]. 西安: 西北工业大学出版社, 2005.
YAN Weisheng. Torpedo navigation mechanics[M]. Xi'an: Northwestern Polytechnical Press, 2005. (in Chinese) |
| [14] | SUN Y, CHENG J, ZHANG G, et al. Mapless motion planning system for an autonomous underwater vehicle using policy gradient-based deep reinforcement learning[J]. Journal of Intelligent & Robotic Systems, 2019, 96(3/4): 591-601. DOI:10.1007/s10846-019-01004-2 |
| [15] | HAGAN M T, DEMUTH H B, BEALE M H. Neural network design[M]. Beijing: China Machine Press, 2002. |
