

进入21世纪,世界各强国纷纷借助无人水下航行器(unmanned underwater vehicle, UUV)开展大规模的海洋研究[1]。声呐图像以其能够直观反映水下场景信息的优势,成为UUV实现自动目标识别(automatic target recognition, ATR)的重要途径。但同时,声呐图像分辨率低、有效特征难于提取,导致水下目标识别准确率较低。
水下目标识别在过去几十年的研究中,以人工设计并提取特征是主流方法[2-3]。人工设计特征需要具备专业领域知识,并在特征提取过程中不可避免地丢失一部分关键信息,造成传统的基于人工特征的声呐图像识别方法鲁棒性和泛化能力不足。
深度学习可以针对不同应用从训练数据中自主学习到新的有效特征表示,并且将传统方法的特征提取及分类步骤合并为一个端到端(end to end)的分类模型。在2013年Kamal等[4]利用深度置信网络(deep belief network, DBN)模型对水下多类别目标的回波数据进行分类。2017年,Ferguson等[5]利用深层神经网络对浅水环境水面船只辐射噪声进行识别。Williams[6]使用基本的卷积神经网络(convolutional neural network, CNN)对侧扫声呐图像进行分类实验,取得较高目标识别率。宋达[7]利用主动声呐探测的回波信号,使用时间序列样本和对应的时频图像作为数据集,对蛙人、空目标、氧气瓶等目标进行分类。李琛等[8]采用子通道特征级联的方法,在低信噪比条件下,使用多通道级联特征的深度神经网络识别方法准确率显著高于基于支持向量机(support vector machine, SVM)的识别方法。综合国内外研究现状来看,基于深度学习方法对声呐图像的识别研究还很少见。
本文在常规卷积神经网络模型的基础上,提出融合图像显著区域分割和金字塔池化的水下自动目标识别模型。在提高水下目标识别率的同时,加快目标图像预测速度。
1 卷积神经网络理论卷积神经网络(CNN)是深度学习领域中的一类重要方法,主要应用于图像和视频分析的各种任务上。近年来,卷积神经网络广泛地应用到图像分类、物体检测、自然语言处理、姿态估计和场景标记等诸多领域。
1.1 卷积神经网络基本结构卷积网络通常由卷积层(convolutional layer)、汇聚层(pooling layer)和全连接层(fully connected layer)交错堆叠而成,如图 1所示。其中,卷积层利用一定大小的卷积核对输入数据进行卷积操作,学习输入数据的特征;汇聚层对卷积结果进行下采样操作,实现小邻域的特征整合;全连接层对经过一系列卷积和汇聚操作后的特征进行组合和分类,最终完成图像识别任务。

|
| 图 1 典型的卷积神经网络结构 |
对于采用卷积-池化-全连接结构的卷积神经网络,用于训练和测试网络的所有图像大小必须一致。如果特征维数不统一,则会导致大部分图像的特征维数与设定好的全连接层输入数据维数不匹配,CNN无法正常执行运算而出现错误。
1.2 卷积神经网络特征学习的原理大量工作表明,通过CNN学习到的特征表达相比于传统的人工设计特征具有更强的判别性能,且具有非常优秀的泛化性能。近几年,一些研究工作借助特征可视化手段,希望理解卷积神经网络的特征学习过程。其中,Zeiler等[9]构建了一个8层的卷积神经网络,在经过ImageNet数据集训练后,利用Deconvnet[10]对卷积网络中各个层的特征图进行反卷积并可视化处理,再将可视化的结果与图像对应的像素块进行对比,结果如图 2所示。

|
| 图 2 卷积神经网络学习特征的可视化 |
从图 2中可以发现,卷积神经网络的浅层部分(如第2层)提取了图像中的颜色和边缘等低层次特征,第3层出现较为复杂的纹理特征,而卷积神经网络的深层部分(第4层和第5层)则提取到图像中物体较为完整的轮廓和形状特征。在经过多层处理后,初始的“低层”特征逐渐转化为“高层”特征表示,利用简单的分类器即可完成复杂的分类任务。总体来说,CNN经过训练后学习到的信息是具有辨别性的关键特征,而图像的背景信息几乎被忽略了。
2 声呐图像识别卷积神经网络建模尽管已经存在很多针对光学图像识别的CNN模型,但是Wolpert和Macerday提出的“没有免费午餐定理”指出,不存在一种通用的学习算法适合于任何领域的任务和问题。所以针对声呐图像识别问题,需要结合实际建立合理的卷积神经网络模型。图 3是本文针对声呐图像特点及数据集大小,设计和提出的卷积神经网络模型结构的示意图。图中标示了在模型结构设计中考虑的3个部分,从声呐图像识别的整个流程出发,分别在数据输入模块、特征提取模块以及特征分类输出模块,为提高声呐图像识别准确率做了改进工作。下面将分别对这3个部分的改进做详细阐述,给出每部分的设计思想以及实现细节。

|
| 图 3 针对声呐图像识别的模型结构设计框图 |
在1.2节中提到,CNN学习的主要是图像上具有辨别性的关键特征信息,而图像背景信息几乎被忽略了。如果直接将原始声呐图像作为CNN网络的输入,不但会因为图像尺寸较大引起后续繁重的运算量,增加网络训练和图像预测时间,还可能因为图像背景信息的干扰影响网络对目标的正确分类。
相对而言,人类视觉系统经过长期进化发展出一个重要特性,就是将有限的视觉处理资源优先分配到整个环境中大脑最感兴趣的目标或区域上[11]。本文借鉴人类视觉的这种特性,提出在网络输入层对原始输入图像作显著性分割,通过使CNN关注声呐图像中影响分类决策的重点区域,提高目标识别准确率和效率。
对于每幅声呐图像,依据区域显著性原则,将图像裁剪为尺寸任意的目标区域图像,再输入网络特征提取模块。以1幅快艇的声呐图像为例,本文采用基于流行排序(graph-based manifold ranking, GMR) 的显著性检测方法[12]对声呐图像进行目标区域检测,检测结果如图 4所示。图 4a)是原始声呐图像,图 4b)是对应的显著性图,灰度值越大在图中表现得越明亮。可以看到,水下目标所在区域被准确的凸显出来。

|
| 图 4 声呐图像目标区域检测 |
在完成图像显著性检测后,采用Otsu阈值分割方法,将显著性图转换为二值图像。图 5a)是图 4b)所示显著性图二值化处理后的结果,并使用最小外接矩形将二值图像分为目标区域和非目标区域,矩形框内为目标区域。参照二值图像分割结果,将原始声呐图像I中的目标区域裁剪出来,丢弃背景区域图像,裁剪结果如图 5b)所示。可以看到,裁剪后的图像相对原始图像尺寸小了很多。

|
| 图 5 声呐图像区域分割和裁剪 |
卷积神经网络具有非常灵活的结构,而网络的设计又缺少足够的理论支持,一般都是针对特定数据集对网络结构不断进行测试和优化,以期获得良好的性能。通过分析最近几年卷积神经网络的改进方法,本文总结了卷积模块设计的几条准则:
1) 在保证网络性能的前提下要尽可能地减少模型的参数量。考虑到本文实验用的声呐图像数据集中图像数量远远少于光学图像数据集,所以采用较少的网络层数,同时减少滤波器的数量,以降低网络的复杂度;
2) 避免使用较大的卷积核。较大的卷积核会引起模型参数量的增加,还会损失图像中的细节信息。声呐图像中的细节信息原本较少,所以在卷积层倾向于使用较小的卷积核去做目标特征提取;
3) 池化层会不断减小数据的空间大小,间接减少了参数数量,在一定程度上控制了过拟合。但由于池化层过快地减小了数据维数,同时会损失原始数据特征,所以在应用中需要减少池化层的使用。
2.3 特征分类模块改进常规的卷积神经网络在特征提取模块后会直接连接数个全连接层,然后输出分类结果。而本文设计的声呐图像识别模型,在特征提取模块和全连接层之间,加入一个金字塔池化层(spatial pyramid pooling, SPP),如图 3所示。在特征分类模块加入金字塔池化层有2点考虑:①解决输入图像尺寸大小不一的问题;②对于声呐图像有效信息少、目标尺寸差异大等特点,利用SPP层提取多尺度特征,并通过融合多尺度特征提高分类效果。
对于CNN输入图像尺寸必须统一的问题,空间金字塔池化[13]给出了更有效的解决办法。SPP方法的原理如图 6所示,从下往上是网络的输入到输出方向。以深度为256的特征映射组为例说明SPP层的处理过程,特征映射组的高度和宽度任意。进入SPP层,最左边蓝色窗格将特征映射组的每一通道分成16块,这样就将特征映射组分成16×256份;中间的绿色窗格和右边紫色窗格同理,分别将特征映射分成4×256份和1×256份。划分之后,对每一份分别做池化操作,特征映射组就被变换成256×21维的矩阵,在输入全连接层前将被拉伸为长度5 376的特征向量。这样就保证不论初始输入数据的维数如何,通过SPP层,数据在进入全连接层前都被统一到相同的维数,也就解决了显著性分割和裁剪导致输入特征提取模块的声呐图像大小不统一的问题。

|
| 图 6 空间金字塔池化方法原理 |
此外,不同于普通的池化层,空间金字塔池化层使用多种采样尺度。SPP的划分可以根据应用的需要而自由设定,例如图 6中是3级金字塔,采样窗口的尺寸分别为4×4, 2×2和1×1。通过对特征图进行多种窗口尺寸和步长的下采样,得到一系列尺度不一的新的特征图,将这些特征图的每个单元拼接起来融合成一个新的向量,既包含高层语义信息又包含空间信息。因此将该特征向量送入全连接层,可以提高目标识别准确率。
2.4 设计的声呐图像识别模型结构综合2.1至2.3节的设计思想,最终设计的声呐图像识别卷积神经网络模型采用6层结构(不含输入层),包括3个卷积层,1个金字塔池化层,1个全连接层以及1个输出层。每层滤波器数量随着网络层数加深逐渐增加,池化层采用均值池化,金字塔层采用最大下采样。
网络参数初始化采用He方法[14],连接权重按照 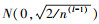
由于声呐图像采集实验成本高昂,水下目标识别领域至今没有一个公开和统一的声呐图像数据集。为了进行本文的图像处理和识别研究工作。首先搜集到一定数量的Echoscope声呐在数次海试中对水下不同目标的成像结果,然后对这些声呐图像进行筛选并分门别类,最终得到9类真实目标的声呐图像。这些水下目标包括工程基石、潜水员、水下机器人、快艇残骸、沉船、飞机残骸和坦克残骸等,每类数据选择一幅图像展示,如图 7所示。

|
| 图 7 声呐图像数据集 |
9类水下目标共有2 915张声呐图像。每一个水下目标样本,都将以图像形式输入深度学习模型。通过人工标注方式,对9类目标图像分别标记为0~8。在分类实验中,将数据集分为不存在交集的3个部分:训练集(training dataset)、验证集(validation dataset)和测试集(test dataset)。
3.2 声呐图像识别结果采用2.4节中给出的声呐图像识别模型,在经过显著性分割和裁剪的声呐图像上进行特征学习和分类。网络训练时,统计每一次迭代网络在训练集和验证集上的损失,以及在验证集的识别率,在训练完毕后绘制网络训练过程曲线。图 8是网络在训练集上的表现,从图中可以看出,训练集损失随着网络训练迭代次数增加整体上迅速下降,经过1 000次迭代后趋于0,只在个别数据上损失较大,说明模型已经收敛,对训练集数据拟合得很好。

|
| 图 8 网络模型在训练集上的损失随迭代次数变化 |
图 9是网络在验证集上的训练曲线,从图 9a)可以看出,在2 000次迭代后,损失函数值整体趋于稳定,仅在部分数据上损失较大;随着迭代次数增加,网络在验证集上的识别准确率在前2 000次迭代中迅速增高,之后趋于稳定,整体在0.8~1.0之间,说明模型的泛化能力较好,并没有出现过拟合的现象。综合模型在训练集和验证集上的表现,可以认为模型训练成功。

|
| 图 9 设计的CNN网络模型在验证集上的训练曲线 |
网络模型训练完成后,在测试集上对9类水下目标声呐图像进行分类实验。依据显著性裁剪的图像输入网络后,会通过Softmax分类器输出一组关于目标类别的分类概率,选择置信度最大的类别作为测试图像预测类别。通过将模型在测试集上的全部预测结果与图像真实类别的标签进行比较,计算目标图像总体识别准确率达到89.52%。此外,统计了实验中CNN对1 565幅声呐图像预测总时间,计算出网络处理1幅图像的平均时间为34.3 ms,说明识别模型具有良好的实时性。
3.3 网络改进的有效性验证设计的声呐图像识别网络模型不同于常规的卷积神经网络,输入数据经过显著性分割处理,且在全连接层前加入金字塔池化层。为了验证这种结构改进的有效性,将其同另外3种网络结构进行对比实验:网络A是通常的卷积神经网络,输入图像不做分割处理,且没有加入金字塔池化层。网络B仅对输入图像做显著性裁剪处理,没有金字塔池化层,为了避免网络运行出错,对裁剪后的图像强制缩放到同样尺寸。网络C不对输入图像做显著性分割,但是在全连接层前加入金字塔池化层,主要用来考察金字塔池化层的作用效果;网络D即在第2节设计的网络模型结构,对输入图像做显著性分割,且在全连接层前加入金字塔池化层。
在同一个声呐图像数据集上,对每种网络结构重复进行5次实验,取5次测试集上识别准确率的平均值作为最终的识别结果,列在表 1中。
| 网络结构类型 | 准确率/% | 单图预测时间/ms |
| A(不做图像分割和金字塔池化) | 78.08 | 59.4 |
| B(图像分割但不做金字塔池化) | 81.50 | 58.9 |
| C(图像不分割但做金字塔池化) | 84.91 | 48.3 |
| D(图像分割且金字塔池化) | 89.52 | 34.3 |
由表 1实验结果可见,本文设计的结合显著性分割和金字塔池化的网络模型对声呐图像数据集的识别准确率最高,比通常的卷积神经网络结构A的识别率高出11.44%。对比网络B和网络A,图像显著性分割使识别准确率提高3.42%;对比网络C和网络A,金字塔池化显著提高了识别率,原因有两点: ①3层的金字塔池化可以从卷积特征图中抽取到更多层次的特征,对特征做了进一步整合,加强了目标特征并具有更强鲁棒性;②金字塔池化的使用减少了全连接层参数,减轻了过拟合。
此外,统计并计算了不同结构设置下网络对单幅图像的测试时间,同样列在表 1中。从单幅图像的预测时间上来看,网络A和网络B的时间相近,因为它们的网络结构和输入的图像尺寸是一样的;而网络C因为使用了金字塔池化,减少了全连接层的计算量,所以预测时间有所减少;而本文设计的网络模型在单幅图像的预测时间上是最短的,约为网络A预测时间的一半,这得益于更小的图像输入尺寸以及金字塔池化层的运用。可见本文提出的深度学习方法能够从大量图像样本中自动提取充分的目标特征,且识别率高,预测速度快。
4 结论本文针对声呐图像特点,提出基于卷积神经网络目标声呐图像识别方法,设计了融合图像显著区域分割和金字塔池化的水下目标识别模型。利用显著性检测方法和金字塔池化层改进网络模型结构,结合交叉熵损失函数适用于多分类问题的优点以及Adam优化算法自适应调整学习率、加速网络收敛的优势,充分发挥卷积神经网自主学习图像特征的能力,有效提高水下目标识别准确率。在实测声呐图像数据集上的实验表明,所提方法在9类目标识别任务上能达到89.52%的正确识别率,高于未做改进的CNN网络,且单幅图像预测时间为34.3 ms,仅为常规CNN网络预测时间为一半。实验结果表明,本文设计的卷积神经网络模型在提高水下目标识别率的同时,加快了目标图像预测速度。
| [1] | KARRAS C, MARANTOS P, BECHLIOULIS C, et al. Unsupervised online system identification for underwater robotic vehicles[J]. IEEE Journal of Oceanic Engineering, 2018, 44(3): 1-22. |
| [2] | KUMAR N, MITRA U, NARAYANAN S. Robust object classification in underwater sidescan sonar images by using reliability-aware fusion of shadow features[J]. Oceanic Engineering, 2015, 40(3): 592-606. DOI:10.1109/JOE.2014.2344971 |
| [3] | MYERS V, FAWCETT J. A template matching procedure for automatic target recognition in synthetic aperture sonar imagery[J]. IEEE Signal Processing Letters, 2010, 17(7): 683-686. DOI:10.1109/LSP.2010.2051574 |
| [4] | KAMAL S, MOHAMMED K, PILLAI S, et al. Deep learning architectures for underwater target recognition[C]//2013 Ocean Electronics(SYMPOL), 2013 |
| [5] | FERGUSON L, RAMAKRISHNAN R, WILLIAMS B, et al. Convolutional neural networks for passive monitoring of a shallow water environment using a single sensor[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing, 2017 |
| [6] | WILLIAMS D. Underwater target classification in synthetic aperture sonar imagery using deep convolutional neural networks[C]//International Conference on Pattern Recognition, 2017: 2497-2502 |
| [7] |
宋达. 基于深度学习的水下目标识别方法研究[D]. 成都: 电子科技大学, 2018 SONG Da. Research on deep learning-based underwater target recognition method[D]. Chengdu: University of Electronic Science and Technology of China, 2018(in Chinese) |
| [8] |
李琛, 黄兆琼, 徐及, 等. 使用深度学习的多通道水下目标识别[J]. 声学学报, 2020, 45(4): 506-514.
LI Chen, HUANG Zhaoqiong, XU Ji, et al. Multi-channel underwater target recognition using deep learning[J]. Acta Acustica, 2020, 45(4): 506-514. (in Chinese) |
| [9] | ZEILER M, FERGUS R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Rision Springes, Cham, 2014 |
| [10] | ZEILER M, TAYLOR G, FERGUS R. Adaptive deconvolutional networks for mid and high level feature learning[C]//2011 International Conference on Computer Vision, 2011: 2018-2025 |
| [11] |
王靖宇. 基于视听觉信息的机器觉察与仿生智能感知方法研究[D]. 西安: 西北工业大学, 2016 WANG Jingyu. The Research of machine awareness and bio-inspired perception based on audio-visual information[D]. Xi'an: Northwestern Polytechnical University, 2016(in Chinese) |
| [12] | YANG C, ZHANG L, LU H, et al. Saliency detection via graph-based manifold ranking[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013 |
| [13] | HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2014, 37(9): 346-361. |
| [14] | HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification[C]//2015 International Conference on Computer Vision, 2015 |
| [15] | KINGMA D, BA J. Adam: a method for stochastic optimization[C]//Proceedings of International Conference on Learning Representations, 2015 |
