

2. 嵌入式系统集成教育部工程研究中心, 陕西 西安 710072;
3. 空天地海一体化大数据应用技术国家工程实验室, 陕西 西安 710072
航空航天合成孔径雷达(SAR)成像系统可以全天候获得大范围的高精度微波图像,并能够产生高附加值的相关产品,在遥感、环境监测、地理制图、战区监视、精确制导和侦察等方面具有广泛的应用[1]。对于SAR平台系统,SAR成像过程占据了大部分系统处理时间,并直接对系统的吞吐量和快速响应能力产生重大影响。SAR成像延迟将严重影响后续相关信息处理,例如内容分析、风险诊断和特征提取。星载/机载SAR在轨实时成像是最直接、最有效的实时成像方案。它不仅可以快速为SAR应用提供图像数据,同时能够显著减少空地间数据链路的通信压力。但是,在轨成像系统的工作环境恶劣,处理器的功耗受到严格限制。因此,实时和低功耗是星载/机载SAR成像处理器必须满足的2个基本条件。
SAR技术的扩展和进步大大提高了其实用性和应用范围。目前,研究人员对高分辨率和广域(HRWS)SAR成像的需求日益增长,特别是在海洋观测、地质调查和环境保护领域。1978年,美国发射了第一个名为Seasat-1的星载SAR,它是专门为海洋遥测而设计的卫星,旨在实现对全球海洋进行卫星监测,并辅助确定海洋遥感卫星系统的技术参数。2006年1月,日本发射了ALOS卫星[2]。它携带的PALSAR是一个L波段SAR传感器,该系统不受大气条件、云量和其他相关条件的影响,因此可全天候用于地面观测。2007年6月,Terra SAR-X由德国国家航天中心发射升空。它的X波段SAR雷达提供的几何精度比其他星载SAR传感器更高,能够提供高分辨率天气条件和广域雷达图像[3]。此外,对于民用和军事应用,SAR成像系统还可用于监视移动目标,包括地面移动目标成像及行动指引(GMTI/GMTIm:地面动目标指示/地面动目标成像)[4]。
SAR成像算法中较成熟和应用较广的算法有CS(chirp scaling)成像算法和距离多普勒(range doppler, RD)算法。CSA(chirp scaling algorithm)是SAR成像最常用的算法之一[5]。其成像过程包括大量的FFT/IFFT以及相对一定量的相位校正操作等,尤其是FFT / IFFT运算,其所占比例最高。FFT/IFFT具有特殊的运算规律,是一种适合进行定制硬件加速的算法。对于SAR实时成像, 设计用于FFT/IFFT的专用计算流程和访存策略具有极高的应用价值。因此,首先,我们提出了一种跨区域地址数据交叉放置和同步访问策略,以支持SAR块成像的FFT/IFFT并行流水处理。其次,基于存储优化策略,提出了一种由定点PE单元和浮点FPE单元组成的异构阵列结构处理器,该处理器可同步执行FFT/IFFT和相位补偿操作,从而实现在轨SAR实时成像。
DSP、CPU和GPU在FFT计算及SAR实时处理中各具优势。采用CPU系统具有良好的灵活性和可移植性[6]。但是,它们的计算效率很低,这是实时SAR应用系统的瓶颈。由于GPU强大的并行计算能力和可编程性,该方案充分利用了GPU强大的计算能力,能够有效提高SAR场景成像的质量[7-10]。GPU+CPU方法可以有效地结合2个处理器的优势来提高成像效率[11]。但是,此方案平均功耗高达150 W,限制了GPU在微型飞行器中的应用。高性能DSP在硬件上已经能够轻松实现许多复杂的理论和算法,因此促进了FFT和SAR技术的发展[12],但是对于低功耗应用,它仍然不是最合适的选择。FPGA飞速发展,已经成为实现数字信号处理最重要的技术之一。在这种架构中,CPU负责调度和任务管理,而FPGA充当协处理器,以实现计算加速[13]。Altera设计了一款FFT IP核,主频可以达到334 MHz,16位的1 024点的FFT计算仅需1.02 μs。但是,国外相关研究大多集中在小规模FFT计算,并不适合大规模SAR实时成像需求。随着商用FPGA存储容量和计算能力的快速发展,有研究将SAR实时成像系统通过FPGA(Xilinx Virtex-6)来构建[14]。但是其算法复杂度高,FPGA的开发周期较长。因此,以上解决方案,各具优点,但是对于大规模SAR成像中大点数FFT/IFFT计算,不能充分开发其并行特征。并且上述架构方案,不能满足在轨SAR实时处理系统的功耗约束和实时性需求。
在SAR实时信号处理系统的设计过程中,对速度,成本,功耗和灵活性之间进行权衡,本文提出了一种基于访存优化的异构阵列架构。在成像过程中提出了一种针对FFT/IFFT的存储调度和访问策略,有效支持SAR成像块内FFT/IFFT计算的同步数据供给,确保其并行流水计算过程。为了提高能效,提出了一种由定点PE单元和浮点FPE单元组成的异构阵列结构,分别用于FFT/IFFT和相位补偿操作。设计了一种针对SAR完整成像过程的异构计算阵列资源管理策略,支持FFT/IFFT和相位补偿操作的同步并行和流水线处理过程。
1 CSA模型 1.1 chirp scaling成像过程分析CSA是SAR成像最常用的算法之一。与其他算法相比,CSA具有操作过程简单、计算复杂度低、成像效率高的优点。另一方面,CSA改善了图像的保真度,尤其是相位信息的保存。而且,CSA可以适应不同的雷达扫描模式,例如聚束式、条带式、扫描SAR及滑动聚束式等[5]。CSA的成像原理如图 1所示。CSA可以根据功能分为3个模块,也可以根据操作顺序分为7个步骤。该成像算法逐步执行,并且在计算过程中,FFT/IFFT和相位补偿进行交替操作。如图 1所示,完整SAR成像过程需要进行4次傅里叶变换和3次相位补偿操作。

|
| 图 1 CS成像流程 |
从图 1中可以看出,CS算法涉及多次FFT/IFFT运算。成像过程中,首先进行方位向FFT运算,将回波数据变换到信号-多普勒域内,在多普勒域内对距离位移曲线进行校正。然后对数据方阵进行距离向FFT处理,将数据变换到二维频域内,执行数据压缩和位移校正。后续进行距离向IFFT处理,将数据送入图像-多普勒域,并执行方位向图像压缩。完成所有数据处理后,最后一步执行方位向IFFT变换,数据返回二维时域并结束成像过程。每一级的CS(chirp scaling)校正计算并行粒度较大,并且计算过程无数据依赖关系,针对此计算过程可充分挖掘其并行性,提高计算效率。因此,基于chirp scaling算法的SAR成像过程,其核心计算内容主要由FFT/IFFT处理和因子校正运算组成。并且研究发现,成像过程中执行较低位宽定点FFT / IFFT操作,其图像精度损失很小,但可以显著提高处理过程的吞吐量。在文献[15]中,详细评估了定点FFT/IFFT操作的CSA量化误差。分析结果表明,FFT/IFFT随着字长从12-bit增加到16-bit,CSA量化误差基本保持不变,并且15-bit或16-bit字长的成像质量非常接近单精度浮点成像质量。但是,相位补偿结果需要较高精度,必须使用浮点算术运算。
1.2 计算特征分析通过对FFT计算过程分析可以得知, N点FFT/IFFT可分解为2Nlog2N个实数乘法和3Nlog2N个实数加法。表 1分别列出了M×N规模成像过程中各步骤的计算量。
| 计算过程 | 步骤 | 乘运算 | 加运算 | 运算总量 |
| 方位向-FFT | 1 | 2NMlog2M | 3NMlog2M | 5NMlog2M |
| CS校正 | 2 | 4NM | 2NM | 6NM |
| 距离向-FFT | 3 | 2NMlog2M | 3NMlog2M | 5NMlog2M |
| RC校正 | 4 | 4NM | 2NM | 6NM |
| 距离向-IFFT | 5 | 2NMlog2M | 3NMlog2M | 5NMlog2M |
| AC校正 | 6 | 4NM | 2NM | 6NM |
| 方位向-IFFT | 7 | 2NMlog2M | 3NMlog2M | 5NMlog2M |
| 计算量统计 | 4NMlog2M+4NMlog2M+12NM | 6NMlog2M+6NMlog2M+6NM | 10NMlog2M+10NMlog2M+18NM | |
| 注: RC校正: 距离向补偿校正。AC校正: 方位向补偿校正。 | ||||
从表 1中可以得出FFT/IFFT计算量比例W如公式(1)所示。对于不同规模的成像矩阵, FFT(IFFT)的占比W略有不同, 如表 2所示。从表 2可以看出, W值基本都超过90%, 并且随着矩阵增大, 比值W最大可达到95%。因此, 针对FFT/IFFT计算特征, 优化其访存过程, 对FFT/IFFT操作进行加速将有效地减少成像时间并提高成像效率。
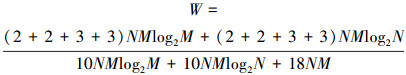
|
(1) |
| 成像规模 | FFT/IFFT计算量 | 相位补偿计算量 | 比值W/% |
| 256×256 | 107 | 106 | 89.8 |
| 1 024×1 024 | 2.1×108 | 1.8×107 | 91.7 |
| 4 096×4 096 | 4.1×109 | 3×108 | 93 |
| 16 384×16 384 | 7.6×1010 | 4.8×109 | 94 |
| 65 536×65 536 | 1.2×1012 | 1.2×1010 | 94.7 |
对CSA计算过程的数据组织方式和计算流水线进行合理设计, 需要对CSA所对应的数据流进行特征分析。CSA成像过程所对应的数据流图如图 2所示。

|
| 图 2 CS成像算法数据流图 |
计算过程中, 回波数据作为最原始数据进入成像计算过程, 并结合旋转因子进行首次的方位向FFT运算, 并将计算结果送入第二级运算过程。第二级计算过程引入CS校正因子, 与第一级计算结果进行相位相乘运算。第二级计算结果流入下一级, 第三级进行距离向FFT运算, 计算过程以及参数引入过程与第一级方位向FFT计算过程相似。后续计算过程中循环执行上述数据流动过程, 直至最后一级距离向IFFT计算结束, 完成全部成像计算过程。整个成像算法的计算过程中, 计算节点的位置固定, 数据流动方向无分支且流动方式保持一致。
2 SAR实时成像处理器设计 2.1 总体架构设计本文设计了一种用于SAR实时成像的高效异构处理器。所设计的SAR成像处理器顶层架构如图 3所示。本节介绍了整体硬件框图和功能模块。该架构由3个主要组件组成: 混合PE阵列, 交叉存储缓存模块和数据交互引擎。

|
| 图 3 SAR实时处理器顶层框架 |
基于前面的描述和讨论, 设计了一种异构阵列, 阵列中包括2种类型的计算单元, 分别称为PE和FPE。PE用于FFT/IFFT操作, PE单元支持12-bit, 14-bit和16-bit定点FFT/IFFT运算, 对于精度要求较低的SAR应用, 可以选择低位宽操作。FPE支持单精度浮点运算, 用于相位补偿操作。每个异构阵列包含16×16 PE和2×16 FPE。PE和FPE的数量比为8∶1的比例关系。为了满足SAR实时成像吞吐率的需求, 处理器内包含了2组相同的异构阵列, 它们可以并行执行不同块成像的处理过程。
为了向处理阵列提供足够的数据, 片上设计了3种类型的缓存区。针对一个处理阵列, 设计了一个用于16行PE和2行FPE的全局数据buffer(Buffer[A], Buffer[B]), buffer模块的规模为264 kB。每个全局buffer模块包含2个子缓存区, 每个子缓存区包含32个PE专用存储区和1个FPE专用存储区。在处理阵列内部还设计了旋转因子专用buffer(Local-TF buffer: 32 kB)和相位因子专用buffer(Local-PF buffer: 16 kB)。
为了组织片外RAM和片上buffer之间的数据传输, 我们设计了数据交互引擎。使用该数据交互引擎, 可以按照计算流程读取雷达回波数据, 并将最终计算结果写回到片外存储内。
2.2 成像运算数据访存过程优化策略在FFT/IFFT计算的数据读取过程中, 地址序列需要进行位反转操作。为了支持这种数据访问模式, 我们使用了多bank跨区域数据交叉放置策略, 如图 4所示, 以4 096点FFT操作为例。根据计算要求, 1行PE并行执行16个蝶形运算, 必须为1行计算资源同时提供32个数据, 因此, 需要进行并行数据发放。如图 5所示, 在第一个周期中, 从Bank0和Bank1同时访问了32个数据。在第二个周期中, 同时从Bank2和Bank3中读取数据。数据存储的Bank选择和地址分配必须满足FFT/IFFT处理流程中的数据读取策略。每个PE执行不同的蝶形操作, 其过程采用相似的数据放置和访问策略。

|
| 图 4 4 096点数据跨区域存储策略 |

|
| 图 5 基于跨区存储模式的基-4蝶形运算并行流水时序图 |
在相位补偿计算过程中, 数据读取没有特殊要求。因此, 计算过程仅需要并行访问数据即可。
2.3 存储交互及访问设计雷达成像是一个持续过程, 由于片上存储空间有限, 所有雷达回波数据都首先存储在外部存储器中。如图 6所示, 数据交互引擎从DRAM提取数据并将数据推入片上存储阵列。为了隐藏数据交互过程中数据传输的通信延迟, 我们采用了交替脉动技术。为了避免数据交互模块内的硬件资源竞争, 我们为交互系统的输入/输出接口各使用一个脉动交互模块。同时, 我们在输入端采用2个数据交互通道提取数据和参数。所提出的数据交互方式可以在250 MHz频率下提供8 GB/s的读写带宽, 以满足处理器的数据读取要求。

|
| 图 6 数据交互与访问模块设计 |
SAR成像处理过程中, 2个成像块分别分配给2个阵列进行并行处理。每个块内涉及FFT/IFFT和相位补偿操作, 因此在计算期间将PE分配给FFT/IFFT操作, 将FPE分配给相位补偿操作。
根据设计的数据映射和访问策略, 为了支持数据的并行访问, 资源控制器为每个数据区间分配存储bank和存储地址。当执行距离向FFT/IFFT时, 根据分布式交叉存储策略, 每一行数据都存储在4个bank区域中。
如图 7所示, 以1行1 024点为例(r=1 024)。执行FFT/IFFT时, 将根据分布式存储策略将1 024个点进行分段并存储在4个bank中。16个连续成像点作为一个数据段, 将0~15放置在Bank-0中, 16~31放置在Bank-1中, 32~47放置在Bank-2中, 并将48~63放置在Bank-3中, 重复上述操作, 直至256个数据段存储结束。1 024点的基-4 FFT/IFFT操作总共需要5级操作。计算过程进行跨bank并行数据访问。以第一阶段为例, 第一周期从Bank-0和Bank-1中读取数据0~31, 在第二周期从Bank-2和Bank-3中读取数据992~1 023。后4个级别的操作数据访问过程与第一个级别相似。

|
| 图 7 数据访问模式 |
在执行相位补偿操作过程中, 每个FPE在1个周期内执行1个点位的相位补偿操作, 并且1行中的所有FPE并行执行相位补偿操作。在相位补偿操作期间, 16个输入数据都在1个周期内从数据缓存区发送到1行FPE内, 并且16个输出数据在1个周期内写回到数据缓存区。可以看出, 1 024点相位补偿操作需要64个周期。如图 8所示, 为了满足相位补偿和FFT/IFFT之间并行流水线的任务饱和度和并行度, 资源控制器将每一行PE的开始工作时间设置为比上一行延迟64个周期。考虑到不同的成像矩阵大小, PE和FPE的数量配置为8∶1, 因此对于较大的成像阵列, FPE将处于短暂空闲状态。在FPE的处理过程中, 必须先等待PE完成FFT操作, 然后再开始处理下一帧图像。

|
| 图 8 SAR成像并行流水线 |
使用Synopsys工具, 在65 nm CMOS技术和1.2 V电源电压下实现SAR成像处理器。并且在评估过程中, 选择CS成像算法作为测试基准。
在本节中, 为处理器配置不同定点位宽PE和单精度浮点FPE。以不同的定点长度FFT/IFFT计算评估在200 MHz主频时处理器的性能。测试回波数据规模为16 384×16 384。在异构PE阵列上并行执行2个成像操作, 计算过程能够有效利用处理器的计算资源并提高吞吐量。当CSA在异构PE模式下处理时, 吞吐量能够达到每秒115.2 GOPS, 功耗为463 mW。如表 3所示, 当所有成像过程都使用单精度浮点单元时, 处理器的功耗高达713 mW, 其能效仅为定点/浮点异构成像模式的67%。如表 3所示, 16位定点FFT/IFFT的成像过程, 处理器消耗463 mW功率, 而12位定点FFT/IFFT的成像过程, 处理器消耗454 mW功率。由此可以看出, 当选择低位定点FFT/IFFT操作时, 处理器也可以减少少量功耗。
| 计算位宽/(bits) | 吞吐率/(GOPS) | 功耗/mW | 能效/(GOPS·mW-1) |
| 12 | 115.2 | 454 | 0.254 |
| 14 | 115.2 | 459 | 0.250 |
| 16 | 115.2 | 463 | 0.240 |
| 单精度浮点 | 115.2 | 713 | 0.16 |
合理的数据组织和访问优化策略能够确保计算资源的高利用率, 避免计算单元由于长时间的数据等待导致大量计算单元的长时间闲置。成像计算过程中, 计算资源利用率如表 4所示。
从表中可以看出, 一次完整成像过程可以分为流水线建立过程, 和流水线饱和计算过程。流水线建立过程大致耗时仅为0.013 s, 此过程中, 涉及片外数据读取, 以及流水线逐步充满过程, 因此计算资源并未满负载工作, 大部分计算资源处于闲置状态, 此过程计算资源的平均利用率仅为32.13%。流水线建立完成后, 计算资源进入满负载工作状态直至成像结束, 此过程计算资源的平均利用率为98.95%。由于流水线建立过程耗时极短, 因此完整成像计算过程中计算资源的综合利用率能够达到98.8%。由此可以看出, 通过合理的数据组织和访问优化策略, 1幅SAR图像整体成像计算过程中, 计算资源的综合利用率能够达到98.8%。
3.3 与其他成像加速方案对比对不同的成像规模进行测试, 表 5列出了不同尺寸雷达回波的SAR成像时间。对于普通的SAR雷达(例如中国的高分3号卫星, PRF: 2 000 Hz), 16 384×16 384 SAR原始数据的实时处理时间需要8 s。从表 5可以看出, 所提出的加速方案可以满足实时性要求。
| 架构模型 | 主频 | 功耗 | SAR成像算法 | 成像规模 | 成像时间/s |
| Proposed solution | 200 MHz | 463 mW | CS | 1 024×1 024 | 0.04 |
| 2 048×2 048 | 0.15 | ||||
| 6 472×3 328 | 0.68 | ||||
| 16 384×16 384 | 8.2 | ||||
| 30 000×6 000 | 5.54 | ||||
| 32 768×32 768 | 32.9 | ||||
| GPGPU[8] | >500 W | Omega-k | 30 000×6 000 | 8.5 | |
| CPU+GPU[11] | 345 W | CS | 32 768×32 768 | 2.8 | |
| Mobile-GPU[10] | 2.3 GHz | 5 W | CS | 2 048×2 048 | 3.2 |
| Microprocessor+FPGA[9] | 68 W | CS | 6 472×3 328 | 8 | |
| CPU+ASIC[13] | 100 MHz | 10 W | 1 024×1 024 |
表 5中还列出了其他相关研究的功耗和SAR成像时间。从表 5可以看出, 我们提出方案的功耗最小, 因为该方案可以完整实现全部SAR成像过程, 而无需额外配置MCU或CPU。文献[10]与本方案类似, Mobile-GPU架构使用较低的功耗(5W)以获得更好的实时性能。与文献[10]相比, 加速比达到21.33倍, 并且所提出架构的性能功耗比提高了230.4倍。从实时性能的角度来看, CPU+GPU成像实时性最好, 但其功耗过高, 超过300 W。本方案的实时性能仅为文献[11]的8.6%, 但性能/功率比提高了63.4倍。
4 结论本文提出了一种采用定/浮点同步并行加速技术的异构成像处理器, 该处理器用于航空航天领域SAR实时成像。在SAR成像过程中, 由于FFT/IFFT的计算量占比较大, 因此我们提出了一种针对FFT/IFFT的跨区域同步交叉访存策略, 该策略能够有效地支持FFT/IFFT并行流水计算过程, 确保计算流水线数据的持续供给。该处理器由2个18×16异构阵列组成, 可提供115.2 GOPS吞吐量。与低功耗GPU相比, 加速比为21.33倍; 与传统CPU+GPU加速方案相比, 性能/功率比提高了63.4倍。本文设计的加速方案, 单个处理器进行粒度为16 384×16 384的SAR原始数据处理需要8 s的时间, 并消耗463 mW。所提出的加速方案满足在轨SAR成像平台的实时性需求和功耗限制。该架构方案还具有良好的可扩展性, 通过扩展处理器阵列的规模, 能够满足更大尺寸SAR成像的实时性要求。
| [1] | GIERULL C H, VACHON P W. Foreword to the special issue on multichannel space-based SAR[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(11): 4995-4997. DOI:10.1109/JSTARS.2015.2507878 |
| [2] | Advanced land observing satellite-2 SAR mission[EB/OL].(2020-01-23)[2020-05-20]. https://directory.eoportal.org/web/eoportal/satellite-missions/a/alos-2 |
| [3] | Terra SAR-X add-on for digital elevation measurement[EB/OL].(2017-09-13)[2020-05-20]. https://directory.eoportal.org/web/eoportal/satellite-missions/t/tandem-x (Accessedon 13 September 2017) |
| [4] | YANG Lei, ZHAO Lifan, ZHOU Song, et al. Sparsity-driven SAR imaging for highly maneuvering ground target by the combination of time-frequency analysis and parametric Bayesian learning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 4: 1443-1455. |
| [5] | RANEY R K, RUNGE H, BAMLER R, et al. Precision SAR processing using chirp scaling[J]. IEEE Trans on Geoscience and Remote Sensing, 1994, 32(4): 786-799. DOI:10.1109/36.298008 |
| [6] | LI G, ZHANG F, MA L, et al. Accelerating SAR imaging using vector extension on multi-core SIMD CPU[C]//Geoscience & Remote Sensing Symposium, 2015 |
| [7] | WU Z, LIU Y, ZHANG L, et al. Highly efficient synthetic aperture radar processing system for airborne sensors using CPU+GPU architecture[J]. Journal of Applied Remote Sensing, 2015, 9(1): 097293. DOI:10.1117/1.JRS.9.097293 |
| [8] | PETERNIER A, MERRYMAN BONCORI J P, PASQUALI P. Near-real-time focusing of ENVISAT ASAR stripmap and sentinel-1 TOPS imagery exploiting OpenCL GPGPU technology[J]. Remote Sensing of Environment, 2017, 202: 45-53. DOI:10.1016/j.rse.2017.04.006 |
| [9] | LOU Y, CLARK D, MARKS P, et al. Onboard radar processor development for rapid response to natural hazards[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2016, 9(6): 2770-2776. |
| [10] | TANG H Y, LI G J, ZHANG F, et al. A spaceborne SAR on-board processing simulator using mobile GPU[C]//Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 2016: 10-15 |
| [11] | FAN Z, GUOJUN L, WEI L, et al. Accelerating spaceborne SAR imaging using multiple CPU/GPU deep collaborative computing[J]. Sensors, 2016, 16(4): 494. DOI:10.3390/s16040494 |
| [12] | YANG Zhijun, NIE Xiangfei, XIONG Wenyi, et al. Real time imaging processing of ground-based SAR based on multicore DSP[C]//2017 IEEE International Conference on Imaging Systems and Techniques, 2017: 1-5 |
| [13] | BIERENS L, VOLLMULLER B J. On-board payload data processor(OPDP) and its application in advanced multi-mode, multi-spectral and interferometric satellite SAR instruments[C]//Proceedings of the 9th European Conference on Synthetic Aperture Radar, Nuremberg, Germany, 2012: 340-343 |
| [14] | PFITZNER M, CHOLEWA F, PIRSCH P, et al. FPGA based architecture for real-time SAR processing with integrated motion compensation[C]//Proceedings of the 2013 Asia-Pacific Conference on Synthetic Aperture Radar, Tsukuba, Japan, 2013: 521-524 |
| [15] | CHEN Yang, LI Bingyi, LIANG Chen, et al. A spaceborne synthetic aperture radar partial fixed-point imaging system using a field-programmable gate array-application-specific integrated circuit hybrid heterogeneous parallel acceleration technique[J]. Sensors, 2017, 17(7): 134. |
2. Engineering Research Center of Embedded System Integration, Xi'an 710072, China;
3. National Engineering Laboratory for Integrated Aero-Space-Ground-Ocean Big Data Application Technology, Xi'an 710072, China
