



2. 西北工业大学 民航学院, 陕西 西安 710072;
3. 中航油彭州管道运输有限公司, 四川 成都 610202
无人机航拍不仅可以从一般人类的视角观察场景,更可以利用无人机飞行的优势,从空中或者其他人类难以到达的特殊视角观察场景和目标。使用无人机航空影像对目标场景进行观察,具有多视角、多方位、覆盖范围大、机动性强、效率高等特点,能够快速、高效地完成对目标场景的视频识别与观测任务,广泛应用于军民用领域,军事领域包括威胁目标空中监视、目标搜索、目标打击,民用领域包括交通监测、灾难营救、管线巡检、区域勘测、边境巡逻等方面。
随着深度学习技术的迅猛发展,针对传统图像的目标检测,国内外学研究人员提出了一系列性能优良的深度学习模型。Yolo算法[1]采用一个单独的CNN模型实现end-to-end的目标检测,首先将输入图片尺寸归一化,然后将数据送入CNN网络,最后处理网络预测结果得到检测的目标。FasterRCNN[2]通过区域候选网络提取待检测区域,通过卷积神经网络对待检测区域进行识别与分类。南京大学周志华等[3]提出深度随机森林模型,使用多粒度扫描获取图像特征向量,多层随机森林层层迭代的结构实现目标识别与分类。
相比于传统图像的目标检测,无人机航空影像的目标检测方法更具有挑战性,首先,传统图像中的目标受重力作用具有统一的方向,而无人机航空影像中的同一类目标往往会具有多个不同的旋转方向,如果不对旋转目标进行处理直接进行特征提取,将会使同一类目标具有不同特征,增加了目标检测的难度;其次,无人机航空影像由无人机在几十米至数百米的高空拍摄,使得成像中的目标尺寸远远小于传统识别任务中的目标尺寸,小尺寸目标对检测模型精准性的要求会更高;此外,航拍影像中的目标易发生尺度变化、光照变化和遮挡干扰以及相机抖动等影响,这些特点增加了目标检测的难度。
针对上述无人机航空影像的特点,本文提出一种基于深度去噪自动编码器模型的无人机航空影像目标检测方法,在训练过程中首先通过选择性搜索的方法获得原始图像中的感兴趣区域,根据径向梯度具有旋转不变性的特点,对感兴趣区域提取其径向梯度特征为特征向量,使用反向传播算法计算深度去噪自动编码器模型参数,从输入深度去噪编码器的特征向量中提取精简后具有强表征能力的向量,得到旋转不变特征向量进行目标识别检测。实验证明本方法能够有效完成无人机航空影像具有多旋转角度和噪声影像的目标检测问题。
1 本文方法 1.1 旋转不变特征针对无人机航空影像中具有多旋转角度的目标,为了进行有效、高精度的识别检测,本文提出一种基于深度去噪自动编码器模型的目标检测方法,首先对于无人机航空图像采用选择性搜索[4]的方法提取感兴趣区域,对采集到的感兴趣区域提取径向梯度特征,由于无人机航空图像径向梯度特征具有旋转不变性,将径向梯度特征输入深度去噪自动编码器模型进行训练,使用反向传播算法计算模型参数,将深度去噪自动编码器模型生成的编码(code)送入softmax分类器对目标所属分类进行检测识别。
在无人机航拍过程中,飞机采用多角度、多方向的拍摄方式,使得被拍摄的地面目标具有多个旋转角度。常用的图像特征如方向梯度直方图(HOG)特征和卷积特征。方向梯度直方图特征通过计算和统计图像局部区域的梯度方向直方图来构成特征,首先将图像分成小的连通区域,称为细胞单元,采集细胞单元中各像素点的梯度直方图。把这些直方图组合起来就可以构成特征描述器,但由于HOG特征没有选取主方向,因此不具有旋转不变性。卷积特征由卷积神经网络使用卷积核对原图像进行卷积操作得到,通过多层卷积神经网络可以提取具有较强表征能力的卷积特征,但通用卷积特征没有对旋转目标进行处理,因此不能很好检测多旋转角度的目标。径向梯度特征通过计算目标图像径向与切向的梯度值,具有很好的旋转不变性,因此引入径向梯度特征作为旋转不变特征。

|
| 图 1 径向梯度特征旋转不变性示意图 |
如图所示, r向量与t向量是一对基于切点p的正交向量, c点为感兴趣区域图像的中心, 向量r的方向由c点指向p点, 向量t为p点的切向向量, p点的径向局部坐标系为prt, 则对应p点的梯度向量为g表示为(gTr, gTt)。当目标向左旋转θ角度后, p点旋转到对应的p′点, Rθ表示旋转矩阵, 在旋转后的径向局部坐标系p′r′t′下有

|
(1) |
旋转后新位置点p′处的梯度向量g′可以在旋转后的径向局部坐标系p′r′t′下表示为(g′Tr′, g′Tt′), 则有
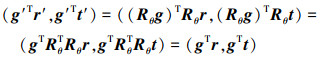
|
(2) |
因此, 当目标围绕图像中心旋转一定角度时, 图像上每个点的梯度向量是不变的, 特征向量具有旋转不变性, 利用径向梯度向量, 得到旋转不变特征描述符, 记为f={f1, f2, f3, f4, …, fk}, 将提取到的旋转不变特征送入深度去噪自动编码器模型进行学习、识别。
1.2 深度去噪编码器模型 1.2.1 模型结构深度去噪自动编码器是一种无监督的神经网络模型, 他可以学习到输入数据的隐含特征, 为编码(coding)阶段, 也可以用学习到的新特征重构出原始输入数据, 为解码(decoding)阶段。由于飞行过程中机体振动的因素, 所拍摄影像会受到特征干扰, 在特征层面可以将受噪声干扰图像的深度特征看作由未受噪声影响图像的深度特征和高斯白噪声组成, 因此通过使用带有噪声的原始输入数据训练模型, 可以使得模型能够有效识别检测受到噪声扰动的影像目标。相比于深度编码器, 深度去噪自动编码器能够高精度识别带有噪声的数据, 具有良好的鲁棒性。深度去噪自动编码器直观上可以用于特征降维, 类似于主成分分析PCA, 但是相比于PCA其性能更强, 因为神经网络模型可以提取更有效的新特征, 并且能够识别带有噪声干扰的图像数据。本文算法流程为, 深度去噪自动编码器模型对输入的原始径向梯度特征进行降维, 将学习到的降维特征送入有监督学习, 能够有效对无人机航空影像进行目标检测。深度去噪自动编码器模型分为编码器、生成器、解码器3个模块, 物理结构由输入层、多个隐藏层、输出层构成。输入数据经过多层编码器进行降维, 中间瓶颈层会得到最低维度特征, 实际为生成编码的生成器, 生成的编码经过多层解码器进行解码, 在训练过程中通过反向传播算法使得输入层和输出层尽可能接近。
实现过程如下, 首先对无人机图像数据提取径向梯度特征, 所得到的径向梯度特征记为f={f1, f2, f3, f4, …, fk}。如图 2所示, 本文构建的深度去噪自动编码器模型共有6层, 第一层为输入层, 输入特征数据; 最后一层为输出层, 输出特征重构结果; 输入层输出层之间共有4个隐藏层, 其中第三个隐藏层为瓶颈层, 瓶颈层输出最具表征能力的低维特征向量, 称为编码(code), 编码作为分类器分类的判据; 由输入层到瓶颈层的过程为编码过程, 特征向量的维度会逐层降低, 每层输出的特征表征能力越来越强; 由瓶颈层到输出层的过程为重构过程, 重构使得输入层的输入数据和输出层的输出数据尽可能接近。

|
| 图 2 深度去噪自动编码器结构示意图 |
将特征向量f输入到深度去噪自动编码器模型的输入层, 加上相应的特征白噪声作为第一个隐藏层的输出, 其中Nz={n1, n2, n3, n4, …, nk}, 有ni~N(μ, σ2), 白噪声服从均值为μ方差σ2的高斯正态分布, 第一个隐藏层输出的特征向量记为X(1)=(x1, x2, x3, …, xk), 其中x=f+Nz, 即xi=fi+ni。
在编码过程中, 所得到新的特征向量送入第二个隐藏层, 得到该层隐藏层特征表示X(2), 计算公式为

|
(3) |
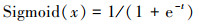
|
(4) |
其中Sigmoid(*)函数为编码器常用的激活函数, W2和b2表示输入层特征向量和生成隐藏层特征向量X(2)之间的权重矩阵与偏置矩阵, 将第二个隐藏层生成的特征向量X(2)输入第三个隐藏层, 获取该层特征向量表示
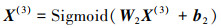
|
(5) |
X(3)是编码器整个编码过程所获得的编码(code), 在识别过程中会将所得编码使用监督学习方法的分类器模型进行类别检测。
解码过程与编码过程相似, 通过多层解码器使用激活函数对所得编码X(3)特征向量进行重构, 得到解码器的输出, 编码X(3)经过第一层解码器, 得到解码器第一层的重构向量Y(1)
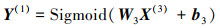
|
(6) |
将Y(1)输入第二层解码器, 得到输出的重构向量Y(2):
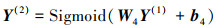
|
(7) |
深度去噪自动编码器模型通过反向传播算法调整参数, 使得模型的输入数据f与输出Y(2)尽可能一致。
1.2.2 训练过程深度去噪自动编码器可视作由多个自动编码器通过集成学习方式堆叠起来, 共有1个输入层, 4个隐藏层(第一个隐藏层为随机高斯白噪声叠加层), 1个输出层(可见层)。在训练过程中, 因为随机高斯白噪声模型已经固定, 将输入层和第一层隐藏层看作一个可见层, 首先训练第一个自动编码器, 即输入层和噪声层组成的可见层, 第二层为隐藏层, 使用反向传播算法计算每层参数, 得到W2和b2, 然后以第二层隐藏层的输出作为下一个自动编码器的输入, 训练第二个自动编码器, 依次训练直到最后一个自动编码器, 完成训练后, 由于深度编码器将第三层隐藏层输出的编码作为分类特征, 送入softmax分类器进行类别判断。
自动编码器通过训练使得输入X与输出Y尽可能相近, 所有重构误差可以由输入数据和输出数据之间的交叉熵表示
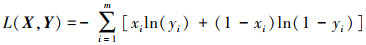
|
(8) |
由于自动编码器模型参数为随机初始化确定, 得到重构误差后使用反向传播算法迭代结算参数集θ={W, b}, 过程如下
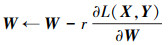
|
(9) |
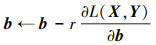
|
(10) |
其中, r为模型的学习率, 取值范围为0到1之间。使用反向传播算法迭代解算模型参数, 训练过程中先对参数θ={W, b}进行随机初始化, 然后将输入数据输入自动编码器, 编码器输出重构数据, 计算重构误差以及重构误差对参数θ={W, b}的偏导, 根据(9)至(10)式, 迭代计算, 当重构误差很小的时候, 参数{W, b}收敛为定值, 该值即为所求系统参数。
2 实验验证 2.1 实验环境与数据集为了验证所提算法的有效性, 本文在无人机航空影像数据集:UAV123数据集和慕尼黑航空影像数据集上, 对深度去噪自动编码器模型的目标检测性能进行了评估。模型运行环境为Inter(R) Core(TM) i9-9900K CPU, 2080Ti GPU, 内存为64 GB的台式机工作站, 操作系统为Ubuntu 18.04。
UAV123数据集[5]是国外学者Matthias在ECCV会议上发布的无人机航空影像数据集, 该数据集由123个无人机摄像头所记录的影像组成, 数据覆盖了多种场景, 如公路、海滩、港口、田野、建筑物等, 目标有行人、船只、汽车, 飞行器和建筑物, 图像尺寸为1 280×720, 实验中的主要研究目标为车辆、船、人等。
慕尼黑航空影像数据集[6]由德国宇航院DLR提供的一个公开航空图像数据集, 研究目标为具有不同旋转方向的地面车辆。包含20幅图像, 覆盖慕尼黑市, 大小为5 616像素×3 744像素。慕尼黑数据集是由DLR 3K高清航空摄影相机在1 000 m高空采集的, 地面采样距离约为0.13 m, 训练数据目标为地面车辆, 标注的车辆总数为3 418, 测试集中有5 799辆, 图像中每辆车占尺寸约为40像素×20像素。
2.2 目标检测性能评价指标对于目标检测问题, 性能可能包括4种预测结果:TP(true positive)将正样本预测为正样本; FP(false positive)将负样本预测为正样本; TN(true negative)将正样本预测为负样本; FP(false negative)将负样本预测为正样本。
本文采用了几种常用的性能评价指标, 精确率(precision), 召回率(recall), F1调和值(F1 score), 用来定量评价所提无人机航空影像目标检测方法。
1) 精确率, 表示正确识别出的障碍物占总识别障碍物总数的百分比
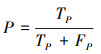
|
(11) |
2) 召回率, 表示正确识别出的障碍物占测试集中所有障碍物的百分比, 召回率高表示漏检的障碍物越少, 计算公式为

|
(12) |
3) F1调和值, 精确率和准确率的调和值, 综合了精确率和召回率的结果, 当F1较高时则能说明实验方法比较有效
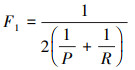
|
(13) |
本文利用选择性搜索方式获取无人机航空图像的感兴趣区域, 对每个感兴趣区域提取径向梯度特征, 对每个感兴趣区域提取600维度径向梯度特征, 输入至深度去噪编码器模型, 模型网络结构的第一层输出600维特征向量, 编码过程中, 第二层主动加入噪层输出为600维带有高斯白噪声的特征向量, 其中μ=0, σ2=0.01, 第三层输出100维特征向量, 瓶颈层输出20维编码, 解码过程中模型第五层输出100维重构向量, 第六层输出层得到600维度特征向量。将数据集75%的图像数据作为训练集, 25%的图像作为测试集, 对模型进行测试, 其中每一层隐藏层参数在训练过程中学习率r为0.002, 当输入数据与输出数据的重构误差绝对值小于0.8时, 训练完成得到该层参数集θ={W, b}。
本研究利用训练后的深度去噪自动编码器模型, 对慕尼黑航空数据集进行目标检测, 并和2种基本的航空影像目标检测方法进行了比较:
1) 深度随机森林[3]由多粒度扫描和级联森林两部分组成, 多粒度扫描对原始数据进行特征提取, 将提取到的特征向量作为输入送入级联森林, 级联森林每一层的输出与原始特征向量聚合后, 作为输入送入下一层, 最后一层对类向量取均值, 选最大值为最终预测结果。实验中参数设置, 深度随机森林共4层, 每层由2个随机森林组成, 每个随机森林包含100个随机树。
2) 聚合信道特征检测器[7]以滑动窗口检测为基础, 在特征金字塔的每个尺度下进行滑动窗口检测, 对每个检测窗口, 根据检测窗口在航拍影像数据中的相对位置, 提取出多通道特征图在对应位置的特征值, 作为聚合后的特征向量; 对每个检测窗口的特征向量, 采用以二叉决策树作为弱分类器的增强决策树, 判定该检测窗口是否为待检测目标, 若判定检测窗口为待检测目标, 则同时输出检测置信度; 使用非极大值抑制算法合并相似检测窗口, 得到目标的最佳外接矩形。实验中参数设置, 聚合信道数量为3通道, 学习率为0.01。
3) 精准车辆检测网络[8]由2个卷积神经网络模型组成。一个网络用来预测地面目标包围盒的精确位置, 该网络卷积层数量为6层, 另一个网络通过学习目标图像属性特征, 推断每个目标的分类和方向, 卷积层数量为9层, 将2个卷积神经网络的特征进行融合, 得到车辆的位置和属性。实验中参数设置, 迭代次数为500, 学习率为0.01。
为了进一步测试算法性能, 在UAV123数据集上对比了本文与其他2种常用目标检测方法的性能, 如下:
1) 基于特征的低空目标快速检测方法[9]。在预处理阶段对图像特征点和相关特征描述符进行滤波, 然后对滤波后的特征点和特征描述符进行匹配, 得到目标检测结果。实验中参数设置, 迭代次数为1 000, 学习率为0.01。
2) 基于改进Faster RCNN的航拍影像检测方法[10]。在目标检测阶段, 采用一个超区域建议网络结合层特征映射提取类车辆目标, 用强分类器代替区域建议网络后的弱分类器来验证候选区域, 通过负样本挖掘减少错误检测率, 提高目标检测效果。实验中参数设置, 迭代次数为500, 锚框的比例为1:1, 1:2和2:1。
由表 1和表 2可知, 相比其他几种方法, 本文方法取得了最好的检测效果。在德国宇航院的慕尼黑航空数据集上, 深度去噪自动编码器的精确率达到93.46%, 召回率91.04%, F1值0.92的效果; 在UAV123数据集上本文方法精确率为91.25%, 召回率85.68%, F1值0.88。说明所提方法能够有效检测带有噪声干扰的无人机图像数据, 具有良好的鲁棒性, 在无人机航空图像多旋转方向目标检测任务上达到良好的效果。
| 方法 | 精确率/% | 召回率/% | F1值 |
| 深度去噪自动编码器 | 93.46 | 91.04 | 0.92 |
| 深度随机森林 | 86.61 | 81.44 | 0.84 |
| 聚合信道特征检测器 | 62.65 | 43.84 | 0.52 |
| 精准车辆检测网络 | 91.98 | 74.73 | 0.82 |
| 方法 | 精确率/% | 召回率/% | F1值 |
| 深度去噪自动编码器 | 91.25 | 85.68 | 0.88 |
| 深度随机森林 | 80.54 | 76.23 | 0.78 |
| 低空目标快速检测方法 | 77.93 | 64.19 | 0.70 |
| 改进Faster RCNN | 89.30 | 78.30 | 0.83 |
为了研究所提方法不同参数对检测性能的影响, 在慕尼黑航空数据集上开展了对比实验。本文方法设置实验参数学习率r为0.002, 重构误差为0.8,实验所得精确率为93.46%,召回率为91.04%,F1值0.92。对比实验内容控制其他参数不变, 改变单一项参数, 此外将本文方法与不带有去噪模块的深度自动编码器模型进行了比较, 观察实验结果, 如表 3所示。
| 方法 | 精确率/% | 召回率/% | F1值 |
| 学习率为0.001 | 93.55 | 90.72 | 0.92 |
| 学习率为0.02 | 87.75 | 83.39 | 0.85 |
| 重构误差为1.6 | 89.81 | 85.10 | 0.87 |
| 重构误差为3.2 | 86.54 | 81.53 | 0.84 |
| 深度自动编码器 | 91.93 | 84.37 | 0.88 |
由表 3可知,当调整学习率过大时,模型的精确率,召回率和F1值会有所下降,当调整学习率较小时候,可以有限地提高模型性能,但会使得模型收敛速度太慢,降低效率。综合以上原因,本文方法采用的学习率值为0.002。当增加重构误差值时,会使检测精度下降,本文所用方法性能指标高于深度自动编码器模型,说明通过去除噪声干扰可以有效提高目标检测能力,增加了模型鲁棒性。
图 3和图 4为本文方法分别在UAV123数据集和DLR慕尼黑航空影像数据集上运行效果,红色框为准确的识别结果,蓝色框为模型未识别出的目标,黄色框为将其他地面物体错误识别为待检测目标。在图 4中,地面目标具有多个方向,本文方法能够有效检测不同旋转角度的目标,其中主要原因在于,该方法提取到了目标的旋转不变特征,能够较好地处理带有多旋转角度待检测目标。

|
| 图 3 UAV123数据集目标检测效果 |

|
| 图 4 慕尼黑无人机影像数据集上目标检测效果 |
本文提出一种深度去噪自动编码器,用于带有多旋转角度和噪声的无人机航空影像目标检测任务。该方法通过提取感兴趣区域的径向梯度特征,得到目标检测旋转不变特征向量,在训练过程中使用深度去噪自动编码器主动添加高斯噪声,使模型能够对带有噪声的数据进行识别检测,在UAV123和慕尼黑无人机影像数据集上进行了实验,对比了多种常用的目标检测算法,本文方法取得最好的效果,具有良好的旋转不变性和鲁棒性,能够有效应用在无人机影像目标检测任务中。本文方法亦存在一定局限性,比如没有考虑如雨雾天气、夜晚等低光照条件下的目标检测应用,在后续工作中将对该类问题展开研究。
| [1] | REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016: 779-788 https://ieeexplore.ieee.org/document/7780460 |
| [2] | REN S, HE K, GIRSHICK R, et al. Faster RCNN:Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. |
| [3] | ZHOU Z, FENG J. Deep Forest: Towards an Alternative to Deep Neural Networks[C]//Proc 26th Int Joint Conf Artif Intell, Melbourne, Australia, 2017: 3553-3559 https://www.researchgate.net/publication/333052935_Deep_Forest-Based_Monocular_Visual_Sign_Language_Recognition |
| [4] | UIJLINGS J R R, VANDESANDE K E A, GEVERS T, et al. Selective Search for Object Recognition[J]. Int J Comput Vis, 2013, 104(2): 154-171. |
| [5] | MUELLER M, SMITH N, GHANEM B. A Benchmark and Simulator for UAV Tracking[C]//European Conference on Computer Vision, 2016 https://link.springer.com/chapter/10.1007/978-3-319-46448-0_27 |
| [6] | LIU K, MATTYUS G. DLR 3K Munich Vehicle Aerial Image Dataset[EB/OL]. (2015-12-31)[2020-01-05]. http://pbafreesoftware.eoc.dlr.de/3K_VehicleDetection_dataset.zip |
| [7] | LIU K, MATTYUS G. Fast Multiclass Vehicle Detection on Aerial Images[J]. IEEE Geosci Remote Sens Lett, 2015, 12(9): 1938-1942. |
| [8] | DENG Z, HAO S, ZHOU S, et al. Toward Fast and Accurate Vehicle Detection in Aerial Images Using Coupled Region-Based Convolutional Neural Networks[J]. IEEE J Sel Topics Appl Earth Observ Remote Sens, 2017, 10(8): 3652-3664. |
| [9] | LOGOGLU K B, et al. Feature-Based Efficient Moving Object Detection for Low-Altitude Aerial Platforms[C]//IEEE International Conference on Computer Vision Workshops, 2017: 2119-2128 |
| [10] | TANG T, ZHOU S, DENG Z, et al. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining[J]. Sensors, 2017, 17(2): 336-352. |
2. School of Civil Aviation, Northwestern Polytechnical University, Xi'an 710072, China;
3. China National Aviation Fuel Pengzhou Pipeline Transportation Company Limited, Chengdu 610202, China
