

2. 中国航空无线电电子研究所, 上海 200241;
3. 西北工业大学 电子信息学院, 陕西 西安 710129
在现代空战战场中,无论是近距离空战还是远距离空战,机动决策在空战中的重要性都是毋庸置疑的。尤其是在近距离空战中,无人机的机动动作非常剧烈和频繁,正确的机动动作可以有效地规避敌方的攻击,同时快速地占领优势位置,对于战场中取得先机有着巨大的影响。空战机动决策可以展现无人机战斗性能和战术运用,而一对一的空战机动决策则是机动决策研究的基础。
在空战机动决策研究中,基于人工智能算法研究成为当前研究的主要方向。目前在空战机动决策领域使用的人工智能算法[1]主要有神经网络、人工免疫系统、强化学习和遗传算法4种。
文献[2]使用了基于深度神经网络的机动决策算法,但是基于神经网络的空战机动决策需要较多的空战典型例子来训练,并且无法解释机动决策结果,不便于空战结果分析。文献[3]通过免疫网络建立机动决策模型,从而模仿了生物免疫系统的记忆能力,这种算法具备自学习能力[4-5]。文献[6]基于强化学习设计了空战机动决策算法,决策的实时性较强[7-9],但是强化学习算法探索未知空间的能力有待提高。
与其他的智能优化算法相比,遗传算法占用资源相对较少,适应度好,可以通过对算法的改进收敛到最优,适用于优化问题[10]。空战机动决策的目的就是通过分析环境信息寻找无人机的最优动作,因此有很多学者将遗传算法应用在空战机动决策领域中。文献[11]提出一种矩阵对策法与遗传算法相结合的空战决策算法,逐步产生最优解来控制无人机的行为。文献[12]设计了一种基于遗传算法的分类器系统,增加了遗传算法产生决策的准确性。
传统的遗传算法[13-14]具有鲁棒性强、搜索范围广的特点[15],适用于大规模优化问题求解,与搜索最优机动策略,建立空战机动决策库的研究目的相契合。针对传统遗传算法无法解决没有显式目标函数的问题,本文提出了一种基于强化遗传算法的无人机空战机动决策建模方法,可以通过遗传搜索产生合理的机动决策序列,完成无人机的自主机动决策过程。
1 算法模型与流程基于强化遗传算法的无人机空战机动决策方法主要包括机动动作库的建立、空战态势评估模型的设计、强化遗传算法的设计和空战决策模型的建立。
1.1 机动动作库的建立空战战术机动动作库的建立是无人战机空战决策的基础和关键,为空战机动决策的选取提供依据,所以建立一个灵活并且贴近战场的机动动作库是至关重要的一部分。将机动动作库的建立分为建立无人机运动模型和建立机动动作库两部分。
1.1.1 建立无人机运动模型对建立无人机运动模型做出以下合理假设:
1) 假设飞机为一个刚体;
2) 假设地球为惯性坐标系(将地面坐标系看作惯性坐标,忽略地球自转及公转影响);
3) 忽略地球曲率;
在考虑飞机机动决策问题时,将无人机看作质点,建立三自由度模型,模型参数定义如图 1所示。

|
| 图 1 三自由度模型 |
在惯性坐标系下,无人机的质点运动方程为[16]:
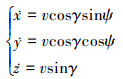
|
(1) |
式中:v表示速度; ẋ, ẏ, ż表示v在3个坐标轴方向的分量; 航迹倾角γ表示速度与水平面的夹角; 航向角ψ表示速度在水平面的投影与y轴方向的夹角。
相同惯性坐标系下, 无人机的质点动力学方程为

|
(2) |
式中:g表示重力加速度; nx为沿着速度方向的过载, 代表飞机的推力作用; nz为沿着俯仰方向的过载, 即法向过载; μ为绕速度矢量的滚转角。
1.1.2 建立机动动作库假设速度矢量与机体轴向保持一致, 使用[nx, nz, μ]为控制量来控制飞机进行机动, 一组控制量作为一个机动决策值。NASA设计提出了7种基本的机动动作[17], 实现了飞机最大过载下的机动控制, 本文在此基础上增加了各个方向的增减速控制, 将基本操纵动作扩展为15种, 各动作及参数设置如表 1所示。
| 机动方式 | nx | nz | μ/(°) |
| 匀速前飞 | 0 | 1 | 0 |
| 加速前飞 | 1 | 1 | 0 |
| 减速前飞 | -1 | 1 | 0 |
| 匀速左转 | 0 | 8 | -82.8 |
| 加速左转 | 2 | 8 | -82.8 |
| 减速左转 | -2 | 8 | -82.8 |
| 匀速右转 | 0 | 8 | 82.8 |
| 加速右转 | 2 | 8 | 82.8 |
| 减速右转 | -2 | 8 | 82.8 |
| 匀速下降 | 0 | 8 | 180 |
| 加速下降 | 2 | 8 | 180 |
| 减速下降 | -1 | 8 | 180 |
| 匀速爬升 | 0 | 8 | 0 |
| 加速爬升 | 2 | 8 | 0 |
| 减速爬升 | -1 | 8 | 0 |
如果目标处于我机导弹的攻击区ωU内, 且目标进入角小于90°时(考虑到近距空空导弹多是红外制导的导引头, 虽然红外空空导弹具有全向攻击的能力, 但是尾焰的红外特性最为明显, 因此尾后攻击的成功率依然远大于迎头攻击的效果), 认为能够截获目标获得发射机会, 定义我机对敌机的优势函数为

|
(3) |
即我方获得一次开火机会, 就会得到5回报值, 同理可以得到敌机的优势函数kT, 即基于攻击区的综合优势函数为

|
(4) |
除了考虑导弹攻击区之外, 针对空战态势的整体优势函数S, 结合基于攻击区的优势函数和建立的整体优势函数可以得到某一刻的空战态势k
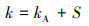
|
(5) |
在仿真过程中对于超出飞行范围的行动进行惩罚, 飞行范围的限制包括飞行高度限制[1 12]km和两机间的最小距离200 m。定义惩罚函数为
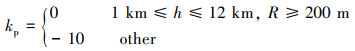
|
(6) |
综合态势函数和优势函数, 可以得到强化信号函数
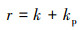
|
(7) |
传统的遗传算法主要解决性能指标明确定义的显式优化问题, 即有明确适应度函数[19-20]。每一个个体编码作为一个解, 都可以代入适应度函数直接计算得到其适应度值。但是空战机动决策是一个动态连续的序贯决策问题, 环境状态不确定性强, 难以用一个静态的优化模型进行数学描述, 从而得出明确的优化目标函数。对于这类性能指标不能明确定义的隐式优化问题, 传统的遗传算法难以直接应用。强化学习的试错学习机制适应于不确定环境下没有明确学习目标的策略探索, 借鉴强化学习中的探索机制进行规则采样, 进而将探索获得的大量样本进行遗传进化迭代, 可以解决遗传算法中的目标优化问题[21]。
本文对遗传算法的改进即是将强化学习的探索思想与遗传算法相结合, 以强化遗传算法为基础, 形成基于强化学习的分类器系统。由以下两部分组成强化遗传算法系统:
1) 分类器子系统, 表示此刻的分类器种群, 与环境交互获得分类器的回报值, 为分类器分配奖励;
2) 规则发现子系统, 通过传统遗传算法的步骤生成新的分类器种群。目的是生成更好的规则。
1.3.1 分类器子系统基于强化遗传算法的学习分类器系统即是在规则和消息系统中采用强化学习的探索方式与环境进行交互, 同时采用遗传算法作为规则发现组件用以对现有的分类器集合进行优化更新。系统的主要设计思想如下, 每一个分类器作为一条规则, 规则包括条件和动作2个部分。从遗传算法的角度, 一个分类器可以被编码为一个染色体[22]。在进行决策任务中, 激活条件与当前环境消息匹配的分类器, 同时向环境发送其对应的动作。当环境与多个分类器匹配时, 计算适应度值, 适应度高的动作消息被执行, 动作执行后从环境得到的奖励, 根据探索得到的奖励值计算分配各个分类器的适应度。在奖励分配后分类器种群将会更新, 适应度相对较低的分类器将会被淘汰, 提高了分类器种群的质量。
分类器以IF/THEN的形式存储规则[23]。规则中的IF部分表示条件, THEN部分表示行动, 按照常用的染色体编码形式, 条件和行动都被设计成一个二进制编码, 二进制编码代表态势状态的各个特征。分类器的具体执行步骤如表 2所示。
| 步骤 | 执行过程 |
| 1 | 通过传感器获得环境状态信息, 将状态信息编码后作为系统的输入; |
| 2 | 将环境状态信息与规则集中的条件部分进行匹配, 激活对应的分类器; |
| 3 | 激活的分类器产生新的状态并送入当前的消息统; |
| 4 | 分类器进行适应度分配; |
| 5 | 通过效应器处理新消息集, 输出新的分类器; |
| 6 | 返回步骤1 |
规则发现系统的目的是产生出新规则, 并改良现有的规则。规则发现系统是在分类器执行一定次数, 并获得一定数量的激活分类器样本后才开始执行的, 可以认为之前的通过强化学习的探索获得的“规则-奖励值”配对为遗传算法提供了进化学习的个体样本, 遗传算法从这些样本中提取高适应度的个体作为初始种群[24], 然后在此基础上开展后续的遗传算法操作。根据轮盘赌方法选择分类器进入交配池, 经过交叉和变异产生的新的种群, 开始下一轮的仿真计算, 直到种群适应度值或者遗传迭代次数达到要求, 结束计算, 输出种群。规则发现子系统的具体执行步骤如表 3所示。
| 步骤 | 执行过程 |
| 1 | 提取高适应度的分类器组建初始种群 |
| 2 | 运用选择, 交叉, 变异算子构造新的规则 |
| 3 | 运行分类器系统, 计算新种群适应度 |
| 4 | 判断适应度值是否符合要求, 达到要求后输出种群, 否则返回步骤1 |
综上, 将本文设计的基于强化遗传算法的学习分类器系统的执行步骤总结为如下:
step1 确定种群规模, 随机编码, 产生第一代群体;
step2 确定初始条件, 将环境状态信息与分类器的条件部分进行匹配, 激活匹配成功的分类器;
step3 按照强化学习探索策略选择适应度高的个体执行, 环境给激活执行的分类器返回奖励值;
step4 若探索决策结束, 执行下一步骤, 未结束则返回step2;
step5 基于激活的分类器个体集合计算整个分类器集合中各分类器的适应度;
step6 分类器种群在适应度分配结束后执行遗传算法;
step7 根据锦标赛方法选择个体进入交配池, 开始进行交叉、变异等遗传操作, 产生新的种群;
step8 判断产生的新的种群适应度值, 达到要求后输出种群, 否则进行step2。
1.4 空战决策模型 1.4.1 分类器个体设计空战中的每个个体都可以在算法中由分类器来表示。强化遗传算法中的分类器由环境状态和对应动作构成, 所以采用IF/THEN的形式描述一条空战机动规则, IF用来表示一种空战状态, THEN表示这条规则在这种状态下所采取的行动值, 每一条规则就是一个分类器。
表述空战状态的影响因素包括:我方速度矢量与瞄准线的夹角αU、目标速度矢量与瞄准线的夹角αT、我方速度矢量与目标速度矢量的夹角αUT, 距离R、我机高度ZU、高度差ZU-ZT、我机速度vU、速度差vU-vT, 以这8个因素作为空战无人机机动规则的状态描述。状态编码分为3位编码和2位编码, 3位编码如表 4所示, 2位编码如表 5所示。采取切向过载nx、法向过载nz, 滚转角μ控制量来控制无人机进行机动。行动编码也同样分为了3位编码和2位编码, 3位编码如表 6所示, 2位编码如表 7所示。
| 编码 | aU/(°) | aT/(°) | αUT/(°) |
| 000 | 0~22.5 | 0~22.5 | 0~22.5 |
| 001 | 22.5~45 | 22.5~45 | 22.5~45 |
| 010 | 45~67.5 | 45~67.5 | 45~67.5 |
| 011 | 67.5~90 | 67.5~90 | 67.5~90 |
| 100 | 90~112.5 | 90~112.5 | 90~112.5 |
| 101 | 112.5~135 | 112.5~135 | 112.5~135 |
| 110 | 135~157.5 | 135~157.5 | 135~157.5 |
| 111 | 157.5~180 | 157.5~180 | 157.5~180 |
| 编码 | R/km | vU/ (m·s-1) |
vU-vT/ (m·s-1) |
zU/km | zU-zT/km |
| 00 | < 1 | < 200 | < -50 | < -2 | -3 |
| 01 | 1~4.5 | 200~350 | -50~50 | -2~2 | 3~0 |
| 10 | 4.5~7.5 | 350~480 | 50~100 | 2~4 | 0~3 |
| 11 | >7.5 | >480 | >100 | >4 | >3 |
在一轮空战中, 总共进行n次决策, 每次决策都会激活一个个体, 就是从所有分类器群体中选择与当前状态匹配且适应度最大的个体, 解码其行动编码作为决策执行, 执行一次机动动作后, 根据新的态势关系进行态势评估将会获得一个奖励值r。待该轮空战的n次决策结束后, 将会得到n个回报值r1, r2, …, rn, 对于激活的n个个体, 设定其适应度为

|
(8) |
对于能够匹配但是未激活的个体(状态与该轮空战中出现的任意一个态势可以匹配, 但是适应度较低所以未选中), 设其适应度为
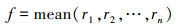
|
(9) |
对于未能匹配的个体, 适应度维持原数值不变。综上,遗传算法适应度函数的效能度量指标根据以下4步完成。
step1 为激活的分类器分派得分, 这个值根据上次完成的交战计算。信用分配保证每一个激活的分类器都能均等根据最后的作战得分获得奖励;
step2 为没有被激活的分类器则分配一个他们父母个体的平均适应度值。这种继承过程确保那些表现好的分类器会在遗传过程中被保留下来, 哪怕他们不总是被激活;
step3 为没有触发的分类器增加一个阻碍, 在遗传选择操作时逐步降低其适应度值, 从而降低那些拥有表现好的元素但是触发条件又不足的分类器的扩散和传播;
step4 为所有没有触发的分类器分配一个触发分类器的适应度值。这个步骤降低了分类器适应度值的噪声水平。这个信用分配过程完成了2个目标:强化激活的分类器, 在遗传过程中保持之前有效分类器的元素。
1.4.3 遗传算法运行逻辑遗传算法的主要操作包括选择、交叉、变异操作。
1) 选择操作
在机动决策建模过程中, 遗传算法的选择操作使用锦标赛方法, 锦标赛大小为n, 锦标赛选拔流程分为3步。
① 从种群中随机选择n条规则;
② 在n条规则中, 选择适应度最高的放入交配池;
③ 这一过程重复, 直到交配池内的数量大小得到满足, 来产生期望数目的新个体。
种群数量是重叠的, 代沟为0.5, 也就是说, 交配池的大小是规则种群的一半。
2) 交叉操作
配对组合从交配池中随机选择, 每一对都经过单点交叉, 交叉概率为0.9, 产生2个子规则。
3) 变异操作
突变以0.02/位的概率被应用于这些新的规则。当一个条件位被选择进行突变, 则以均等概率将该位变为0或1。
2 仿真实验在实际空战中, 飞行员会根据敌我信息作出判断, 改变机动决策。想要实现自主空战, 无人机也需要具备根据态势信息以及目标信息作出智能化机动决策的能力。空战战场瞬息万变, 目标基本不会只采取一个机动动作, 在仿真过程中, 采用基于统计学原理的机动决策算法作为目标的机动策略[25], 使一对一空战仿真实验更加贴合对抗过程。
仿真实验首先以目标策略机动的场景展开, 在目标策略机动的设定下, 分别以无人机均势、劣势、优势的初始态势开展3组仿真实验。
仿真参数设置空战决策周期为1 s、空战最大决策步数为30、种群规模为10 000、选择概率0.85、交叉概率0.9、变异概率0.02。
1) 初始均势
空战的初始态势设定如表 8所示, 在初始时刻, 无人机与目标处于迎头飞行的态势, 双方的飞行速度相同, 目标沿着初始航向按照选择策略飞行。按照遗传算法参数设定和空战环境模拟设定, 强化遗传算法进化2 500 000代, 进化过程中的适应度变化曲线(均匀选取100个点绘制), 如图 2所示。从图中可以看出, 由于个体编码生成的随机性, 难免产生一些执行效果较差的个体编码, 让无人机在仿真对战中处于劣势, 使得适应度函数震荡至负值, 经过后续迭代, 适应度在震荡中逐步增加, 适应度曲线在迭代至160 000次附近时趋于平稳, 因为目标机动的复杂度, 迭代次数有着明显的增加。算法执行结束时的适应度增加至3.14。由于适应度的取值方式为在迭代过程中均匀选取100个点, 图中的适应度曲线并非由所有产生的适应度值绘制, 只代表适应度的变化趋势, 曲线最后的值与最终输出适应度数值可能略有差异。
| 对象 | x/m | y/m | z/m | v/ (m·s-1) |
γ/(°) | ψ/(°) |
| UAV | 100 | 100 | 3 000 | 180 | 0 | 45 |
| 目标 | 3 000 | 3 000 | 3 000 | 180 | 0 | -35 |

|
| 图 2 初始均势适应度变化 |
按照最终输出的激活分类器个体中的机动规则执行对战仿真, 生成的轨迹如图 3所示, 轨迹细节放大如图 4所示, 速度变化如图 5所示。无人机和目标从初始时刻开始迎头飞行, 无人机执行加速动作, 目标执行减速动作, 在较短时间内接近目标, 在双方距离接近后, 无人机改变航向减速向右前方平飞, 摆脱目标的武器攻击角, 目标减速向左前方转弯。无人机减速右转成功进入目标后方, 让目标处于自身攻击区内, 达到武器发射条件并通过平稳速度来保持。说明强化遗传算法能够学习得出机动策略让无人机在目标策略机动的情况下从初始均势到最终优势。

|
| 图 3 初始均势的双方飞行轨迹 |

|
| 图 4 初始均势的轨迹细节放大 |

|
| 图 5 初始均势的速度变化曲线 |
2) 初始劣势
空战的初始态势设定如表 9所示。在初始时刻, 无人机处于被目标尾追飞行态势, 目标沿初始航向按照选择策略飞行。按照遗传算法参数设定和空战环境模拟设定, 强化遗传算法进化2 800 000代, 进化过程中的适应度变化曲线(均匀选取100个点绘制)如图 6所示。算法执行结束时的适应度增加至2.09。
| 对象 | x/m | y/m | z/m | v/ (m·s-1) |
γ/(°) | ψ/(°) |
| UAV | 100 | 100 | 3 000 | 180 | 0 | -45 |
| 目标 | 3 000 | 3 000 | 3 000 | 180 | 0 | -35 |

|
| 图 6 初始劣势的适应度变化 |
按照最终输出的激活分类器个体中的机动规则执行对战仿真, 生成的轨迹如图 7所示, 速度变化如图 8所示。无人机从初始时刻开始改变航向执行加速左转动作, 摆脱目标武器攻击角度, 目标同时执行加速右转动作。在双方距离接近后, 无人机改变航向向右前方转弯, 成功进入目标后方, 让目标处于自身攻击区内, 达到武器发射条件并通过匀速保持。说明强化遗传算法能够学习得出机动策略让无人机在目标策略机动情况下从初始劣势到最终优势。

|
| 图 7 初始劣势的飞行轨迹 |

|
| 图 8 初始劣势的速度变化曲线 |
3) 初始优势
空战的初始态势设定如表 10所示。在初始时刻, 无人机处于尾追目标飞行的优势态势, 我方飞行速度和目标相等, 目标沿着初始航向按照选择策略飞行。按照遗传算法参数设定和空战环境模拟设定, 强化遗传算法进化2 800 000代, 进化过程中适应度变化曲线(均匀选取100个点绘制)如图 9所示, 从图中可以看出, 算法执行结束时的适应度增加至4.35。
| 对象 | x/m | y/m | z/m | v/ (m·s-1) |
γ/(°) | ψ/(°) |
| UAV | 100 | 100 | 3 000 | 180 | 0 | 0 |
| 目标 | 3 000 | 3 000 | 3 000 | 180 | 0 | 45 |

|
| 图 9 初始优势的适应度变化 |
按照最终输出的激活分类器个体中的机动规则执行对战仿真, 生成的轨迹如图 10所示, 速度变化如图 11所示。初始时刻开始, 双方的初始速度相等, 无人机改变航向执行加速右转动作追击目标, 目标同时执行加速右转动作。在较短时间内无人机接近目标, 在双方距离接近后, 无人机改变航向右前方转弯, 目标向左前方转弯。无人机通过调整角度成功让目标处于自身攻击区内, 达到武器发射条件并通过调整速度来保持。说明强化遗传算法能够学习得出机动策略让无人机在目标策略机动的情况下从初始优势持续保持到最终优势。

|
| 图 10 初始优势的飞行轨迹 |

|
| 图 11 初始优势的速度曲线 |
伴随着现代战争的信息化和智能化, 在空战战场上使用无人机的趋势日益明显。为了实现空战战场中无人机自主机动决策, 本文建立了无人机的机动动作库和空战态势模型, 采用强化遗传算法建立空战决策模型, 建立了一对一空战对抗仿真测试场景, 结果表明本文基于强化遗传算法建立的空战机动决策模型, 通过自主学习能够获得正确的机动决策序列, 在作战中获得位置优势。
| [1] |
丁达理, 魏政磊, 唐上钦, 等. 自适应预测权重的空战鲁棒机动决策方法[J]. 系统工程与电子技术, 2020, 42(10): 2275-2284.
DING Dali, WEI Zhenglei, TANG Shangqin, et al. Robust Maneuvering Decision-Making Method for Air Combat Using Adaptive Prediction Weight[J]. Systems Engineering and Electronics, 2020, 42(10): 2275-2284. (in Chinese) |
| [2] |
张宏鹏, 黄长强, 轩永波, 等. 基于深度神经网络的自主空战机动决策[J]. 兵工学报, 2020, 41(8): 1613-1622.
ZHANG Hongpeng, HUANG Changqiang, XUAN Yongbo, et al. Maneuver Decision of Autonomous Air Combat Based on Deep Neural Network[J]. Acta Armamentari, 2020, 41(8): 1613-1622. (in Chinese) |
| [3] | JI H, YU M, HAN Q, et al. Research on the Air Combat Countermeasure Generation Based on Improved TIMS Model[J]. Journal of Physics:Conference Series, 2018, 1069(1): 012039. |
| [4] | JOHN K, KALMANJE K. Artificial Immune System Approach for Air Combat Maneuvering[C]//Proceedings of SPIE-the International Society for Optical Engineering, 2010: 656009 |
| [5] |
嵇慧明, 余敏建, 乔新航, 等. 改进BAS-TIMS算法在空战机动决策中的应用[J]. 国防科技大学学报, 2020, 42(4): 123-133.
JI Huiming, YU Minjian, QIAO Xinhang, et al. Application of the Improved BAS-TIMS Algorithm in Air Combat Maneuver Decision[J]. Journal of National University of Defense Technology, 2020, 42(4): 123-133. (in Chinese) |
| [6] |
左家亮, 杨任农, 张滢, 等. 基于启发式强化学习的空战机动智能决策[J]. 航空学报, 2017, 38(10): 217-230.
ZUO Jialiang, YANG Rennong, ZHANG Ying, et al. Intelligent Decision-Making in Air Combat Maneuvering Based on Heuristic Reinforcement Learning[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38(10): 217-230. (in Chinese) |
| [7] |
孙楚, 赵辉, 王渊, 等. 基于强化学习的无人机自主机动决策方法[J]. 火力与指挥控制, 2019, 44(4): 142-149.
SUN Chu, ZHAO Hui, WANG Yuan, et al. UCAV Autonomic Maneuver Decision-Making Method Based on Reinforcement Learning[J]. Fire Control & Command Control, 2019, 44(4): 142-149. (in Chinese) |
| [8] |
杜海文, 崔明朗, 韩统, 等. 基于多目标优化与强化学习的空战机动决策[J]. 北京航空航天大学学报, 2018, 44(11): 2247-2256.
DU Haiwen, CUI Minglang, HAN Tong, et al. Maneuvering Decision in Air Combat Based on Multi-Objective Optimization and Reinforcement Learning[J]. Journal of Beijing University of Aeronautics and Astronautics, 2018, 44(11): 2247-2256. (in Chinese) |
| [9] | ZHANG X, LIU G, YANG C, et al. Research on Air Combat Maneuver Decision-Making Method Based on Reinforcement Learning[J]. Electronics, 2018, 7(11): 279. |
| [10] | IMMANUEL S D, CHAKRABORTY U K. Genetic Algorithm: an Approach on Optimization[C]//2019 International Conference on Communication and Electronics Systems, 2020 |
| [11] |
邓可, 彭宣淇, 周德云. 基于矩阵对策与遗传算法的无人机空战决策[J]. 火力与指挥控制, 2019, 44(12): 61-66.
DENG Ke, PENG Xuanqi, ZHOU Deyun. Study on Air Combat Decision Method of UAV Based on Matrix Game and Genetic Algorithm[J]. Fire Control & Command Control, 2019, 44(12): 61-66. (in Chinese) |
| [12] | SMITH R E, DIKE B A, MEHRA R K, et al. Classifier Systems in Combat:Two-Sided Learning of Maneuvers for Advanced Fighter Aircraft[J]. Computer Methods in Applied Mechanics and Engineering, 2000, 186(2/3/4): 421-437. |
| [13] | SONG J, HOU C, XUE G, et al. Study of Constellation Design of Pseudolites Based on Improved Adaptive Genetic Algorithm[J]. Journal of Communications, 2016, 11(9): 879-885. |
| [14] | CHEN J, ZHANG D, LIU D, et al. A Network Selection Algorithm Based on Improved Genetic Algorithm[C]//2018 IEEE 18th International Conference on Communication Technology, 2018 |
| [15] |
宋遐淦.不确定环境下智能空战优化决策算法研究[D].南京: 南京航空航天大学, 2017 SONG Xiagan. Research on Intelligent Air Combat Decision under Uncertain Environment[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2017(in Chinese) |
| [16] |
曾宇航.小型尾座式无人机垂直起降及悬停控制研究[D].长沙: 国防科技大学, 2017 ZENG Yuhang. Research on Vertical Take-Off and Landing and Hovering Control of Small Tailsitter Unmanned Aerial Vehicle[D]. Changsha: National University of Defense Technology, 2017(in Chinese) |
| [17] | FRED A, GIRO C, MICHAEL F, et al. Automated Maneuvering Decisions for Air-to-Air Combat[C]//Proc AIAA Guidance Navigation and Control Conference, Monterey, 1987 |
| [18] | YANG Q, ZHANG J, SHI G, et al. Maneuver Decision of UAV in Short-Range Air Combat Based on Deep Reinforcement Learning[J]. IEEE Access, 2020, 8: 363-378. |
| [19] |
张维, 杨康宁, 张民. 一种求解不等圆Packing问题的改进遗传模拟退火算法[J]. 西北工业大学学报, 2017, 35(6): 1033-1039.
ZHANG Wei, YANG Kangning, ZHANG Min. An Improved Genetic Simulated Annealing Algorithm to Solve the Unequal Circle Packing Problem[J]. Journal of Northwestern Polytechnical University, 2017, 35(6): 1033-1039. (in Chinese) |
| [20] | SHARMA J, SINGHAL R S. Comparative Research on Genetic Algorithm, Particle Swarm Optimization and Hybrid GA-PSO[C]//2015 2nd International Conference on Computing for Sustainable Global Development, 2015 |
| [21] | MATSUMOTO K, TAJIMA Y, SAITO R, et al. Learning Classifier System with Deep Autoencoder[C]//2016 IEEE Congress on Evolutionary Computation, 2016: 4739-4746 |
| [22] | PEDROZO W G, NIEVOLA J C, RIBEIRO D C. An Adaptive Approach for Index Tuning with Learning Classifier Systems on Hybrid Storage Environments[C]//International Conference on Hybrid Artificial Intelligence Systems Springer, Cham, 2018: 716-729 |
| [23] | SU C, GAO Y, CAO C. Learning Classifier System Using Both Labeled and Unlabeled Data[C]//Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation ACM, 2010: 1065-1066 |
| [24] | O'HARA T, BULL L. A Memetic Accuracy-Based Neural Learning Classifier System[C]//IEEE Congress on Evolutionary Computation, Edinburgh, 2005: 2040-2045 |
| [25] |
国海峰, 侯满义, 张庆杰. 基于统计学原理的无人作战飞机鲁棒机动决策[J]. 兵工学报, 2017(1): 163-167.
GUO Haifeng, HOU Manyi, ZHANG Qingjie. UCAV Robust Maneuver Decision Based on Statistics Principle[J]. Acta Armamentarii, 2017(1): 163-167. (in Chinese) |
2. China Aeronautical Radio Electronics Research Institute, Shanghai 200241, China;
3. School of Electronics and Information, Northwestern Polytechnical University, Xi'an 710129, China
