

在现代战争中, 空空精确制导武器利用红外成像进行目标要害部位识别能够进一步提高制导精度、武器作战效能, 已经成为夺取制空权的一种极其重要的火力打击方式。
在当前的空战环境下, 目标的机动能力不断增强, 人工干扰也成为目标必备的一种反制空空导弹手段, 这对红外空空导弹的目标识别提出了更高的要求:①在末制导段, 红外导引头捕获的目标轮廓细节逐渐变大, 直至充满视场, 传统基于目标角点的识别跟踪方法极易造成跟踪点漂移, 无法保证跟踪的准确性; ②目标投放红外诱饵造成目标局部遮挡甚至是全遮挡, 破坏目标特征的整体性, 干扰的红外辐射特性改变目标的红外特征分布, 对导引头目标识别造成混淆; ③引战配合需要识别目标部位信息, 便于控制导弹姿态偏转和战斗部爆炸方向, 提高武器系统的杀伤概率。这些因素使得目前常用的整体目标识别算法近乎失效, 迫切需要红外成像制导空空导弹目标识别技术进一步发展, 将目标要害部位识别研究引入红外精确制导武器。
对于传统的基于局部区域提取、融合的方法, 末制导段的空中目标会经历剧烈的尺度变化, 无法实现目标要害部位的识别。传统的基于机器学习的要害部位识别仍然使用手工特征进行目标要害部位推理, 无法脱离进行目标整体识别的问题。对于目标被遮挡、发生形变、目标部位未完全暴露态势下的目标要害部位识别仍无法解决。
深度学习[1]作为机器学习中的热门研究领域, 通过建立类人脑的分层结构模型, 从数据中逐层提取有效、抽象的特征进行组合。特别地, 基于深度学习的图像语义分割网络可以实现图像中不同对象的像素级标注, 能够直接实现目标部位级别的识别。Long等[2]提出了完全卷积神经网络(full convolutional networks), 将端对端的卷积网络推广到了语义分割中, 使用反卷积层来进行上采样, 提出了跳跃连接来改善上采样的粗糙度。编码器-解码器(encoder-decoder)结构, 对应的典型结构为U-net[3]网络, 使用池化层缩减输入数据的空间维度, 解码器通过反卷积层等网络层逐步恢复目标细节和相应的空间维度。空洞卷积[4](dilated convolutions)结构去除池化层, 特点是在不增加参数数量的情况下增大了感受野, 改善网络性能。条件随机场[5](conditional random field, CRF)方法常可用来在后期处理中改进分割效果, 基于底层图像像素强度进行“平滑”分割, 可以提高语义分割的效果。
与传统的基于目标识别的目标要害部位识别方法[6-9]相比, 基于深度学习的目标要害部位识别算法能够充分利用目标特征, 自下而上地进行特征抽象提取, 避免了在目标图像表征不完整情况下推理要害部位产生的误差。
因此, 本文以红外成像空空导弹为研究对象, 研究了在弹道末端导引头对目标进行要害部位识别问题, 旨在缩短导弹攻击末端跟踪盲区的距离, 提高对目标的打击精度。本文主要的贡献在于:针对公开红外数据集缺少的问题, 本文对典型空中红外目标部位进行了分析, 并构建了对应的实测和仿真数据集; 针对传统识别算法对点选取的高要求、噪点适应性差、无法选取非特异点的缺点, 提出基于深度学习的要害部位识别方法; 分析红外空中目标要害部位的任务需求, 提出针对要害部位识别的网络优化方法, 包括改进损失函数以加速网络训练, 采用纹理增强的数据集加强模型鲁棒性。
1 基于关键点检测网络的要害部位识别传统目标识别方法是基于人的先验认知经验, 从数学角度抽象得到的, 本质上是对图像蕴含的信息进行降维处理, 只取出关注、侧重的特征信息部分。神经网络(neural network, NN)作为一种具备高维、非线性分类能力的分类器, 在图像分类、目标识别领域发挥出优异性能。本节将基于卷积神经网络分析目标要害部位识别任务, 提出目标多要害部位识别方法, 并针对该任务的隐含约束对网络训练提出带约束的损失函数和数据扩充方法。分析和实验验证了该方法能够加快识别网络的训练速度, 提高训练精度。
1.1 经典关键点检测任务方法分析实现目标关键点检测任务, 首先需要从图像中检测得到目标区域。通过构建anchor的方式产生候选区域, 在图像上滑动窗口对原图进行采样。通过设置不同大小、长宽比的滑动窗口: Dratios=[0.5, 1.2], Dscales=[8,16,32], 生成的anchors如图 1所示。蓝色矩形框即为不同尺度、长宽比的anchor, 定义基础anchor面积为s, 则各种框宽w, 高h的计算公式为

|
(1) |

|
| 图 1 Anchor生成示意图 |
可以看出, 图 1中生成的anchor尺寸小于目标真实尺寸。因此, 为了提高网络对不同尺度目标的检测结果, 减少需要计算的无关候选框, 同时引入区域提议网络(region proposal net)训练、提取更加“有效”的候选区域框。此时的训练任务只区分Anchor是否存在有意义的物体, 而不判断物体具体的类别。因此该训练任务总结为:
1) 判断Anchor是否为存在物体的区域;
2) 通过回归的方式迭代优化anchor的位置和大小, 更加贴近存在物体的边界。
这里提取的anchor虽然在通过scales扩大了感受域, 增大了能够探测到的目标尺度范围, 但从人眼视觉的角度——人眼去观察一幅图像时, 是一个由全局到局部的变化过程:一方面, 对于一副分辨率很高的图像, 人眼可以清晰区分图像中的物体; 当图像分辨率降低时, 人眼依旧可以在很大范围内识别出图像的内容。另一方面, 人类的日常生活过程中往往是在空间中做二维运动, 而人脑却可以通过在全局范围内运动下将各个局部范围内的认知组合起来, 构成全局的认知、感知, 即对地图形成一副鸟瞰图。
在传统的图像处理算法中, 图像金字塔的作用是可以对图像进行放大或缩小。而在卷积神经网络中, 金字塔输入量是经过卷积、归一化层等操作得到的特征图, 其中所包含的池化层输出的特征图尺寸按照1/2比例缩小, 构成了特征金字塔结构。对于每一层特征金字塔均可以进行RPN[10], 其输出存在比例关系, 输入存在潜在联系。因此将每个尺度下RPN的预测输出和周围的特征连接起来, 即由粗粒度(coarse)、分辨率低的特征输出逐级融合到精准(fine)、分辨率高的特征输出, 最终构成了金字塔网络[11](feature pyramid networks), 充分利用原图分辨率下的标注信息, 缓和在特征采样分辨率降低时取整导致的定位精度损失问题[12]。
Mask RCNN[13]主要针对图像语义分割构建网络模型, 因此网络架构中涉及的内容包括用于初步图像多尺度特征提取的backbone部分, 通过可插拔设计可以选用Resnet50、Resnet101[14]等网络结构作为backbone。在网络深层池化过程中形成多级的特征图, 在区分前景(foreground)与背景(background)的同时进行区域分割。将关键点视作单像素类别的分割方法在人体关键点部位检测任务中具有优秀的性能。
1.2 红外空中目标关键点检测方法分析本文以经典的Mask-RCNN网络架构为基础, 佐以提升网络性能、加快网络训练速度的网络层结构, 用回归的方式实现红外空中目标关键点的训练。
由于导弹在末端攻击时需要进行红外空中目标要害部位识别, 此时合理假设视场内仅存在一个目标, 设在机体坐标系下目标要害部位的集合为
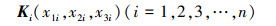
|
(2) |
式中,K1, …, Kn为惯性空间内的n个不重复点, 均可以在机体坐标系进行位置描述。设K1为“基准点”, 由K1经过转换矩阵Ti旋转、放缩得到Ki
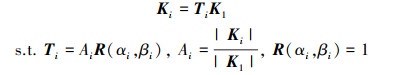
|
(3) |
式中, R(·)为旋转矩阵。因此K1, …, Kn间满足
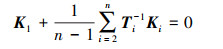
|
(4) |
式中, Ti-1为Ti的逆矩阵。由旋转矩阵R(·)可得R(αi, βi)-1=R(αi, βi)T, 由标量Ai可得Ti-1=R(αi, βi)T/Ai。存在φ(·)使得K1, …, Kn满足
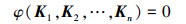
|
(5) |
对于刚体目标来说, 目标整体不会发生弹性形变与变结构, 每个Ki相对K1的Ai, αi, βi为定值, 不随目标状态、观察角度而变化, 即(3)式可简写为
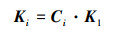
|
(6) |
式中, Ci即为由K1点到Ki点所经历旋转和平移变换矩阵的乘积, 为一常系数矩阵。所以K1, …, Kn在观察坐标系内的描述均可通过K1得到
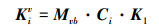
|
(7) |
式中: Mvb为由机体坐标系到观察视点坐标系的坐标转换矩阵; K1v, …, Knv间同样线性相关。
在原始的回归损失函数MSE(mean square error)、MAE(mean absolute error)中, 只单纯描述了各个回归点处的预测值与真值间的误差, 没有考虑回归点间的联系、约束。在图像语义分割像素级分类中, 通过在网络输出后端加入条件随机场, 学习相邻像素间潜在的分类类别约束信息, 如图 2所示。

|
| 图 2 相邻像素潜在类别相关性示意图 |
对于空中目标关键点, 由前文可知满足φ(K1v, K2v, …, Knv)=0。因此, 网络输出预测点间的潜在关系直接可由φ(·)描述。将其直接作为约束条件用于损失函数。则对于均方误差函数
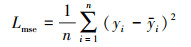
|
(8) |
变形为
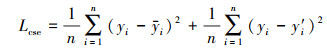
|
(9) |
式中: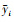
类似于滑模变结构控制的思想, 引入y′i能够使预测值yi尽快进入“滑模状态”, 并沿梯度方向收敛。如图 3所示。

|
| 图 3 训练数据收敛轨迹示意图 |
预测值与真值间的绝对误差P在常规损失函数Lmse作用下沿虚线方向向零点靠近。在自定义Lcse损失函数训练下则会先快速进入到φ(K1v, K2v, …, Knv)=0平面内, 再逐渐收敛。这样能够起到降维、加快训练速度的作用。
对于简单的二维平面内点的回归, 网络最后的预测输出层为全连接层, 不涉及到非线性变换。如图 4所示, 若初始预测各点位置误差为:x1=(2, 2), x2=(3, -4), 收敛到理想真值下时即到达零点

|
(10) |

|
| 图 4 二维平面多点回归轨迹 |
存在约束为
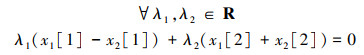
|
(11) |
即回归预测的P1, P2应关于Ox轴对称。
mse即采用常规均方差损失函数Lmse时的收敛轨迹, cse为采用Lcse时的收敛轨迹, 虚线连接部分为同批次迭代权值下的2个点的预测位置。可以看出, 在加入了约束条件的损失函数的训练下, 网络能够根据约束条件的先验知识进行预测值的调整。
1.3 空中红外目标要害部位识别网络对于红外图像来说, 相对于常见可见光数据集划分具有的3个颜色通道RGB描述, 可以认为只具有灰度值一个通道。这里针对飞机部位关键部位检测来说, 基础的网络框架类似于VGG架构, 通过采用多级小的卷积核串联进行特征提取, 同时采用具有加快网络训练速度、提高性能的LeakyReLU非线性函数, 再通过归一化层对同一批次的数据进行归一化处理, 加快学习速率。
网络结构如图 5所示, 具体的网络层定义如表 1所示。通过5个由池化层级联的卷积-归一化-卷积-归一化结构构成的特征提取单元分别从不同尺度对图像进行特征提取工作, 在最后对特征图进行拉伸得到特征向量, 通过全连接层进行权值调整, 同时在训练中利用dropout操作选择性激活节点, 再通过全连接进一步微调权值, 回归预测关键点位置。

|
| 图 5 构建网络结构图 |
| 网络层(类型) | 输出维度 |
| Block1_1(Conv2D+LeakyReLU+BN) | (None, 128, 160, 32) |
| Block1_2(Conv2D+LeakyReLU+BN) | (None, 128, 160, 32) |
| max_pooling2d_1(MaxPooling2D) | (None, 64, 80, 32) |
| Block2_1(Conv2D+LeakyReLU+BN) | (None, 64, 80, 64) |
| Block2_2(Conv2D+LeakyReLU+BN) | (None, 64, 80, 64) |
| max_pooling2d_2(MaxPooling2D) | (None, 32, 40, 64) |
| Block3_1(Conv2D+LeakyReLU+BN) | (None, 32, 40, 96) |
| Block3_2(Conv2D+LeakyReLU+BN) | (None, 32, 40, 96) |
| max_pooling2d_3(MaxPooling2D) | (None, 16, 20, 96) |
| Block4_1(Conv2D+LeakyReLU+BN) | (None, 16, 20, 128) |
| Block4_2(Conv2D+LeakyReLU+BN) | (None, 16, 20, 128) |
| max_pooling2d _4(MaxPooling2D) | (None, 8, 10, 128) |
| Block5_1(Conv2D+LeakyReLU+BN) | (None, 8, 10, 256) |
| Block5_2(Conv2D+LeakyReLU+BN) | (None, 8, 10, 256) |
| max_pooling2d_5(MaxPooling2D) | (None, 4, 5, 256) |
| Block6_1(Conv2D+LeakyReLU+BN) | (None, 4, 5, 512) |
| Block6_2(Conv2D+LeakyReLU+BN) | (None, 4, 5, 512) |
| Flatten_1(Flatten) | (None, 10240) |
| Dense_1(Dense) | (None, 512) |
| Dropout_1(Dropout) | (None, 512) |
| Dense_2(Dense) | (None, 8) |
针对红外空中目标图像要害部位识别任务的网络模型的训练和测试均运行于ThinkStation工作站, 显卡版本型号为NVIDIA GeForce GTX 1080Ti, 处理器为8核Intel Xeon E5-1630 v4, 主频为3.7 GHz。
软件方面操作系统为Ubuntu18.04 LTS采用CUDA9.0, Anaconda3构建的基于Python3.6.8的虚拟环境, 网络模型的构建与训练在keras2.0.8环境下完成。
2.1 实验数据集以空中目标为基础, 构建的要害部位数据集图像来源包括实测与仿真数据两部分。其中, 仿真数据从真实弹道条件与完备性2个角度出发, 基于数字弹道仿真产生目标尺度渐变的图像序列, 基于仿真模型全角度采样得到目标各个角度下的图像。
2.1.1 实测图像数据集实测图像数据来源于实验室在珠海航展期间用热像仪拍摄的上千幅真实飞机红外图像。但由于拍摄角度限制, 以及拍摄数据为连续图像序列, 数据间的唯一性、独立性并不高。主要观察方位处于飞机下半平面(如图 7所示)。

|
| 图 6 红外空中目标要害部位数据集构建 |

|
| 图 7 热像仪实测图像 |
由于实际采拍方法具有很大空间、时间上的局限性, 进行数字建模仿真更为高效。红外仿真弹道图像是基于战场态势对抗仿真实验平台生成, 该平台建立了一套基于新型红外热成像导引头的全链路仿真模型。其中, 图像分辨率大小为256×256, 红外波段为中波(3~5 μm), 输出帧率为100 Hz。该平台根据战机结构参数构建CATIA下的3D模型。同时在Fluent中进行飞机在不同速度下(0.8Ma和1.2Ma)的流场计算、热传递分析, 建立战机的红外仿真模型, 如图 8所示。

|
| 图 8 中波红外仿真模型 |
由上述的目标全方位图像, 以5°为间隔, 循环俯仰和偏航通道, 共计获得5 184幅图像作为总体数据集(0°~360°, 其中360°与0°完全一致, 因此不包含360°图像序列), 命名格式为θ_ϕ。其中, θ, ϕ分别为目标三维模型在空间惯性坐标系内的姿态角, 观察点和观察平面同时保持不变。
为保证测试数据和训练数据分布的一致性, 选取俯仰、偏航角为5°, 10°, 15°, 25°等图像数据作为训练集, 同时选取俯仰、偏航角为0°, 20°, 40°, 60°等图像数据作为测试集。因此, 原始训练集图像共计4 860张, 测试集图像共计324张。
对于训练图像进行数据补充时采用封装好的imgaug库, 该库是专门用于机器学习图像增强的python库, 支持多种多样的数据扩充方法, 并且不仅可以用于扩充图像, 还可以对关键点、边界框、热图(heatmap)、分割图进行扩充。对训练集原图图像进行数据补充效果如图 9所示。

|
| 图 9 原图数据补充效果图 |
针对红外目标在通常情况纹理信息缺失——飞机蒙皮灰度值一致, 近距时导引头灰度值饱和的情形,对数据集进行二值化处理扩充数据集至原数据集2倍大小。训练测试数据集分布以及简写如表 2所示。
对于一个算法的好坏, 评价指标通常从速度(speed)、精度(accuracy)、鲁棒性(robust)3个方面进行评估。
对于红外空中目标要害部位的精度评估, 采用
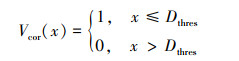
|
(12) |
式中, Dthres为精度误差阈值, 则算法在数据集中的精确度计算公式为
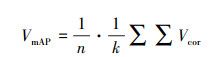
|
(13) |
训练过程如图 10所示, 在训练前期采用小批量数据输入方式, 加快网络训练速度。在训练中后期, 输入数据的批次大小(batch size)逐渐加大, 避免网络震荡。

|
| 图 10 网络模型训练过程 |
从训练过程中得到的loss损失曲线、平均绝对误差(mean absolute error, mae)变化曲线、训练和测试精度(accuracy, acc)变化曲线可以看出:由于训练集有data augmentation, 所以网络在训练集上的测试性能比测试集的性能指标差, 整体似乎展现欠拟合的状况。但实际上即便是有data augmentation, train mae依旧有2.5, 而原数据集mae低至1, 精度acc高至0.95。可见网络拟合效果良好, 没有欠拟合等其他负面问题。
2.3.2 模型测试评估对训练好的模型进行测试, 输出预测结果如图 11所示。由图可知, 对于不同姿态下的红外目标图像, 训练的网络模型均能够定位到左右机翼、机头、机体中心, 并且能够分辨出机体的“正面”, 即座舱所在的一面。

|
| 图 11 红外空中目标关键点识别结果 |
选择实测红外图像序列, 部分帧图像如图 12第1行所示, 用作模型输入以便于人眼观察。第2行为增强对比度后的图像。在进行模型要害部位识别输出时, 后文中将结果标注在增强对比度后的图像上, 这样更有助于结果分析。需要指出的是, 测试序列图像中可能包含不只一个目标, 但由于模型使用的回归预测的方式, 对于整幅图来说只会产生4个输出坐标, 因此仅对其中一架飞机进行目标要害部位识别。

|
| 图 12 实测序列展示(由左到右分别为第300, 500, 900帧) |
图 12第2行展示了对比度增强后的图像, 飞机整体灰度值一致性很高, 飞机纹理细节严重缺失, 很难分辨飞机的“上面”与“下面”。对比第300帧与第700帧的识别结果, 识别出的4个要害部位位置符合人的主观认识。但若要仔细区分左右机翼的话, 则2幅图内识别的位置恰好相反, 这也证明了飞机上表面与机腹纹理对区分左右机翼的影响。观察不同视角下的识别结果, 机头(座舱)、机身(中心)定位精度较高, 可以稳定反映目标要害部位真实位置。左右机翼位置在某些状况下会与人类认知相差较远, 这是因为训练集数据采样来源于俯仰和偏航通道, 对于图像平面内的旋转(即滚转通道)的训练样本是通过数据增强的方式产生的, 相关训练数据量不足, 导致模型识别对如图 12第500帧之类的飞机目标识别结果不好, 仍有待提高。
2.3.4 红外空中目标要害部位识别软件平台将网络封装整合形成GUI用户平台——红外空中目标要害部位识别软件提供了用于网络模型评估、用户图片测试的平台。如图 13所示, 主体界面模块单元包括:

|
| 图 13 基于卷积神经网络的红外空中目标要害部位识别软件平台 |
1)参数加载模块。具备加载显示路径下所有可用权重模型, 并对模型进行评估的功能; 还具有选择输入图片的功能, 进行预测结果可视化输出;
2) 原图及预测显示区。主要用于显示待识别图片与识别结果;
3) 耗时信息。输出进行单幅预测所耗费时间, 单位为s;
4) 状态信息显示。包括显示用户操作执行信息, 模型评估结果, 图像识别输出的定量数字结果信息。
对实验过程中获得的模型进行评估统计由表 3、图 14得到。其中, r为原始数据集, a为扩充数据集, r+a为综合数据集。
| 模型名称 | 训练数据集 | 测试数据集 | |||||
| 原始 | 扩充 | 综合 | 原始 | 扩充 | 综合 | ||
| weights_mse_8_1000 | 0.699 8 | 0.586 6 | 0.643 2 | 0.700 3 | 0.573 7 | 0.637 0 | |
| weights_bimse_8_1000 | 0.590 3 | 0.684 1 | 0.637 2 | 0.590 7 | 0.688 7 | 0.639 7 | |
| weights_bimse_8_2000 | 0.668 1 | 0.625 3 | 0.646 7 | 0.667 1 | 0.611 1 | 0.639 1 | |
| weights_cse_8_1000 | 0.784 2 | 0.748 6 | 0.766 4 | 0.771 1 | 0.726 5 | 0.748 8 | |
| weights_cse_16_1000 | 0.850 9 | 0.754 7 | 0.802 8 | 0.846 5 | 0.743 1 | 0.794 8 | |

|
| 图 14 空中要害部位识别概率统计 |
可以得到:各个模型在训练与测试集中的识别概率基本一致, 在每一类子集中的识别概率也无明显差异, 模型均没有表现出过拟合; 在采用带有约束损失函数训练网络时, 同样训练次数下的目标识别准确率提高约15%, 能够达到75%左右的识别率; 进一步训练1 000次, 网络识别率即达到80%。在以32批次训练后, 模型在原始数据集中的识别准确率下降约0.5%, 在二值化扩充数据集中的准确率上升约1%。可以说明:随着模型训练, 模型能够学习更加偏向形状的特征, 更有助于红外空中目标要害部位识别。
由图 14可以看出, 采用纹理数据扩充以及含约束条件的损失函数时, 网络性能会有提高。在用原始数据+扩充数据训练模型时, 加入约束条件使得网络训练更有目的性, 在综合测试集中的测试精度提高了10%。
3 结论本文针对红外成像空空导弹在攻击末端时刻下的目标要害部位识别进行研究。基于空中飞机目标结构、红外特性分析, 设计红外数据集的构建、生成方法。针对传统要害部位识别方法对遮挡问题的不适应性, 提出了空中目标要害部位识别的深度卷积网络模型, 定义新的带有约束条件的损失函数。提出并实现了广泛的红外空中目标关键点任务数据增强方法, 并应用到红外空中目标多要害部位识别回归任务。最后, 构建红外空中目标要害部位识别软件平台, 用于评估网络性能和输出预测值。实验结果表明, 采用本文所提出网络进行红外目标要害部位回归预测, 要害部位识别点平均误差小于5个像素。基于关键点检测网络的要害部位识别算法在抗噪性、鲁棒性上表现出优越的识别性能。
| [1] |
邱晓康. 深度学习的发展与应用[J]. 科技展望, 2016, 26(33): 93-95.
QIU Xiaokang. Development and Application of Deep Learning[J]. Science and Technology, 2016, 26(33): 93-95. (in Chinese) |
| [2] | LONG J, SHELHAMER E, DARRELL T. Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2014, 39(4): 640-651. |
| [3] | RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]//Medical Image Compating and Compater Assited Intervention, 2015 |
| [4] | YU F, KOLTUN V. Multi-Scale Context Aggregation by Dilated Convolutions[C]//International Conference on Learning Representations, 2016 |
| [5] | SUTTON C. An Introduction to Conditional Random Fields[J]. Foundations and Trends in Machine Learning, 2012, 4(4): 267-373. |
| [6] |
李萍, 方喜波, 黄志理. 基于红外成像制导的末端瞄准点选择技术[J]. 红外与激光工程, 2013, 42(5): 1131-1136.
LI Ping, FANG Xibo, HUANG Zhili. Aim Point Selecting Algorithm for Endgame Based on Infrared Imaging Guidance[J]. Infrared and Laser Engineering, 2013, 42(5): 1131-1136. (in Chinese) |
| [7] |
李成, 李建勋, 童中翔. 红外成像制导末端局部图像识别跟踪研究[J]. 兵工学报, 2015, 36(7): 1213-1221.
LI Cheng, LI Jianxun, TONG Zhongxiang. Research on Partial Image Recognition and Tracking in Infrared Imaging Terminal Guidance[J]. Acta Armamentarii, 2015, 36(7): 1213-1221. (in Chinese) |
| [8] |
胡磊力, 张君昌, 张亮中. 基于人类视觉系统的实时红外目标检测方法[J]. 西北工业大学学报, 2017, 35(5): 910-914.
HU Leili, ZHANG Junchang, ZHANG Liangzhong. Real-Time Infrared Target Detection Method Based on Human Vision System[J]. Journal of Northwestern Polytechnical University, 2017, 35(5): 910-914. (in Chinese) |
| [9] |
余瑞星, 吴虞霖, 曹萌, 等. 基于边缘与角点相结合的目标提取与匹配算法[J]. 西北工业大学学报, 2017, 35(4): 586-590.
YU Ruixing, WU Yulin, CAO Meng, et al. Target Extraction and Image Matching Algorithm Based on Combination of Edge and Corner[J]. Journal of Northwestern Polytechnical University, 2017, 35(4): 586-590. (in Chinese) |
| [10] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137-1149. |
| [11] | LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2117-2125 |
| [12] | LIN G, MILAN A, SHEN C. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017 |
| [13] | HE K, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]//Proceddings of the IEEE Internaltional Conference on Computer Vision, 2017: 2961-2969 |
| [14] | HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778 |
