

多智能体协同及其目标围捕是当前控制领域的研究热点之一, 并广泛应用于多种无人系统的团队协作任务中, 如多无人机协同侦查[1-2]、多导弹协同制导[3]、多无人船协同搜索[4]、多移动传感网络区域覆盖[5]等。在多对一的追逃任务中, 自主移动多智能体从多个方向实现对目标的协同合围, 可以有效提高成功围捕的概率[4, 6], 因此研究多智能体的协同合围具有重要的理论意义和广阔的应用前景。
目前, 已有不少学者对协同合围控制进行了一定程度的研究。文献[3]以多反舰导弹为研究对象, 设计了可任意指定攻击角度的协同打击导引律, 通过设定一组均匀分散的攻击角度实现对目标的合围打击。文献[7]针对分数阶多智能体系统, 采用领导-跟随一致性, 实现了多智能体按照期望的相对角度和相对距离对目标的合围跟踪控制。文献[8]针对带有非线性拉格朗日动力学的多智能体系统, 设计了带有避碰功能的协同合围算法, 使得多智能体能以给定的相对位置实现对目标的合围。文献[9]针对多水下潜航器对目标的围捕任务, 采用时间竞争机制进行任务分配, 并设计相应的航路规划算法, 实现了复杂环境下的目标合围。总的来说, 多智能体协同合围控制问题可以划分为2个独立的子问题:一个是合围点的协同自部署; 另一个是给定合围点以后如何将多智能体导引到对应的合围点上[10]。从现有的研究成果可以看出, 目前关于协同合围控制问题的研究大多是集中在后一个子问题上, 本文将专门针对合围点的协同自部署问题开展研究。
本文首先将合围点的部署问题建模为单位圆上的覆盖控制问题, 然后基于多智能体一致性理论设计了面向合围点部署的分布式控制协议, 实现了合围点在围捕圈上的均匀自部署。考虑到现实中的一些多智能体系统运行时间短(如多导弹系统)、或者具有重复运动特性(如协作搬运多机器人系统), 一般都要求在有限时间内快速实现合围点部署; 与常见的采用终端滑模控制实现有限时间收敛的方法不同, 本文受文献[11]中方法的启发, 提出了一种针对离散时间系统的时变可调增益策略, 将闭环系统的收敛特性由渐进收敛调整为给定有限时间收敛, 从而大大提高了合围点部署的效率。
1 合围点部署问题 1.1 问题描述考虑在一个足够大的无障碍二维空间中随机地分布着n个自主移动智能体Qi, i∈In={1, 2, …, n}和一个目标点O, 如图 1所示,图中的虚线圆代表以目标为圆心的围捕圈。分布式协同合围任务的目标就是在某种待设计的分布式控制协议作用下, 使多智能体对目标的理想合围点能自发地均匀分散在围捕圈上, 然后通过进一步导引实现多智能体对目标的合围。

|
| 图 1 多智能体协同围捕单个目标 |
假设对于任意的智能体Qi, 都能通过自身携带的传感器测得其相对于目标点的方位角qi, 并能通过多智能体系统的通信网络G实现与邻近的智能体(如Qi-1和Qi+1)实时交换方位角信息。本文的目标就是基于这种局部信息交换, 设计分布式控制协议, 以实现合围点在围捕圈上的均匀自部署。
1.2 问题建模合围点均匀分散在围捕圈上, 也就是使合围点实现对围捕圈的均匀覆盖, 故可将合围点部署问题, 建模为以目标为中心的圆(即围捕圈)上的均匀覆盖控制问题, 如图 2所示。不失一般性地, 考虑该圆为单位圆。由多智能体的初始方位角, 可以确定出合围点在圆上的初始位置, 当合围点均匀分散到该圆上时, 就完成了多智能体的合围点部署。

|
| 图 2 多智能体合围点在以目标为中心的圆上的部署 |
给出合围点部署问题的离散形式的演化方程如下

|
(1) |
式中:qi(k)代表第k步时智能体Qi的合围点方位角;(xi, yi)是合围点的位置坐标;τ为仿真步长;ui为待设计的分布式控制协议。
为了后文中分析与证明的方便, 按照合围点初始方位角的大小对其进行编号如下

|
(2) |
根据公式(2),称qi的左邻居为qi-1, qi的右邻居为qi+1(特别的, q1的左邻居为qn, qn的右邻居为q1)。再结合图 2, 定义邻接角距di为从智能体Qi的左邻居Qi-1沿逆时针方向到智能体Qi之间的圆弧的长度, 则邻接角距di的计算公式为
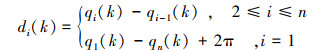
|
(3) |
当所有的邻接角距di(i=1, 2, …, n)都相等时, 就实现了合围点在圆上的均匀部署。实际上, 以上建模过程也就实现了将合围点部署问题转变为了邻接角距di(i=1, 2, …, n)的一致性问题。
结合图 2可知, |di+1-di|反应了智能体Qi对其所在的左右邻居之间的这一段圆弧均匀覆盖程度的优劣, 其值越小, 代表对该段圆弧的覆盖越均匀。故定义整个多智能体系统的覆盖代价函数为
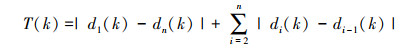
|
(4) |
显然, T(k)≥0;覆盖代价函数T(k)越小, 表示多智能体在圆上的分布越均匀; 当T(k)=0时, 所有智能体将完全均匀地分布在该圆上。故接下来任务就是设计分布式控制协议ui(k)(i=1, 2, …, n), 使覆盖代价函数T(k)在有限时间内趋近于零。
2 分布式控制协议设计直接给出本文设计的分布式控制协议如下

|
(5) |
式中,K为可调增益。
本节先给出结论, 其证明将在下一节中给出, 即:当固定的可调增益K和仿真步长τ的乘积满足0 < τK < 1时, 在分布式控制协议(5)的作用下, 覆盖代价函数T(k)将渐进收敛到零。
为了实现在任意给定的有限时间T*内收敛, 进一步引入时变可调增益策略, 通过动态地改变分布式控制协议(5)中增益K的大小实现有限时间收敛。时变的可调增益K(k)随时间t(k)的变化如下
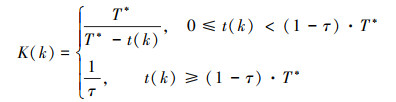
|
(6) |
为保证(6)式在数学上有意义, 规定T*>0, 0 < τ < 1。
将(5)式中固定的可调增益K换成(6)式中时变的可调增益K(k), 即可实现覆盖代价函数T(k)在指定的有限时间T*内收敛到零。
需要说明的是, 在实际应用中, 智能体Qi可根据自身初始方位角、接收到的邻居智能体的初始方位角, 以及其与±π的关系, 依据公式(2)判断出自身的编号i是属于{1}, {n}, {2, 3, …, n-1}中的哪一种, 然后即可应用公式(3)和(5)计算控制量ui(k)的大小。因此, 在实际应用时, 不需要人为地为智能体分配编号, 也就是说, 所提出的控制协议是一种完全分布式的控制协议。
3 收敛性分析本节给出所提出的分布式控制协议的收敛性证明。首先证明在控制协议(5)以及固定可调增益K的作用下, 闭环系统具有渐进收敛特性; 然后分析引入时变可调增益K(k)后, 闭环系统将在给定有限时间内收敛。
3.1 渐进收敛性分析在开始证明之前, 先给出一个待使用的引理。
引理1 对于一个矩阵P∈Rn×n, 如果该矩阵的每一个元素都是非负的且行和为1, 则称该矩阵为一个随机矩阵, 存在P1n=1n, 且Pk仍是一个随机矩阵。若随机矩阵P的对角元素非零且其对应的通信拓扑是连通的, 则称该随机矩阵是非周期和不可分解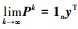
下面开始收敛性证明。
1) 当2≤i≤n-1时, 由公式(1)、(3)、(5)可得

|
(7) |
2) 当i=1时, 有

|
(8) |
3) 同理, 当i=n时, 有

|
(9) |
可将公式(7)~(9)统一写成如下的矩阵形式

|
(10) |
式中, D(k)=[d1(k), d2(k), …, dn(k)]T, 矩阵C为

|
(11) |
由公式(10)可得
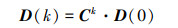
|
(12) |
当0 < τK < 1时, 根据引理1可知, 随机矩阵C是SIA的, 故有
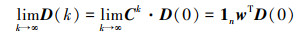
|
(13) |
式中, w∈Rn×1, 且其中的每一个元素都是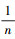

|
(14) |
由di(k), i=1, 2, …, n渐进一致可知, 覆盖代价函数T(k)将渐进收敛到零。
另外, 由上述证明过程可知, 在分布式控制协议(5)的作用下, 系统收敛的条件是:多智能体系统的通信拓扑是连通的, 且每个智能体需要至少能收到左右邻居的合围点方位角信息; 可调增益K和仿真步长τ的乘积需满足0 < τK < 1。
3.2 有限时间收敛性分析引理2 对于如下的Toeplitz矩阵T∈Rn×n[13]

|
(15) |
其特征值的解析表达式为
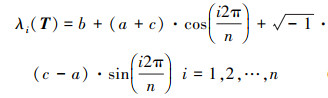
|
(16) |
下面分析在时变可调增益K(k)的作用下, 闭环系统的有限时间收敛特性。
在时变可调增益K(k)的作用下, 公式(10)中的随机矩阵也是时变的, 记作C(k)。根据已有的研究成果[14], 公式(10)的收敛速度是由矩阵C(k)的本质谱半径res(C(k)), 也即矩阵C(k)的第二大特征值决定的; res(C(k))越小, 系统的耦合强度越小, 收敛速度越快。根据引理2, 随机矩阵C(k)的本质谱半径为
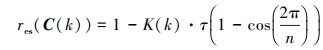
|
(17) |
显然, 在某一既定的多智能体合围点部署场景下, 控制协议中的可调增益K(k)越大, C(k)的本质谱半径越小, 系统的收敛速度也就会越快。
分析公式(6)可知, 本文设计的时变可调增益K(k)随时间t(k)单调递增, 也就是说, 系统的收敛速度是单调递增的。考虑到系统收敛的条件为0 < τK(k) < 1, 当t(k)→(1-τ)T*时, τK(k)→1, 系统的收敛速度将达到保证系统收敛情形下的极大值, 故对于一个有界的初始覆盖代价函数T(0)来说, 在到达给定的有限收敛时间T*之前, 覆盖代价函数T(k)将收敛到零, 即有

|
(18) |
当t(k)≥(1-τ)T*后, τK(k)=1, 由于在此之前邻接角距di(i=1, 2, …, n)已实现精确一致, 故系统将临界稳定于平衡状态。
4 仿真验证为了验证本文所提出的控制协议的有效性, 在MATLAB环境下进行了3组具有对比性的数值仿真实验。仿真步长τ对应物理世界中离散控制系统的采样周期, 设置为τ=0.01 s; 假设有6个自主移动智能体, 随机地指定一组初始方位角(如-170°, -155°, -140°, -115°, -70°, -50°), 由公式(1)计算出初始合围点位置如图 3所示。3组对比性仿真实验的具体设置如下:

|
| 图 3 多智能体合围点的初始位置分布 |
实验1 取固定的可调增益K=1, 以验证所提出的分布式控制协议(5)能实现合围点围绕目标点的均匀部署以及系统的渐进收敛特性。
实验2 在验证分布式控制协议(5)的基础上进一步验证提出的时变可调增益策略(6), 并指定有限收敛时间为T*=4 s。
实验3 进一步地验证分布式控制协议(5)和时变可调增益策略(6), 并与实验2形成对比, 指定有限收敛时间T*=2 s。
在相同的初始合围点位置下, 经过以上3组仿真实验, 合围点最终都收敛到相同的位置, 如图 4所示。可见在保证收敛的前提下改变可调增益的大小只是影响系统收敛速度的快慢, 并不会影响闭环系统最终的平衡状态。同时, 由图 4可以看出, 对于随机给定的初始位置, 在本文提出的分布式控制协议(5)的作用下, 合围点最终实现了围绕目标点的均匀自部署, 能够为多智能体进行目标合围提供理想的合围点信息, 这也就实现了本文最初的设计目标。另外, 对比图 3和图 4可以看出, 多智能体在单位圆上的空间顺序没有被改变, 这有利于实现多智能体在进行目标合围时避免相互碰撞。

|
| 图 4 多智能体合围点的最终位置分布 |
图 5是3组实验的覆盖代价函数T(k)随时间变化的对比图。从图中可以看出, 3组实验中的T(k)最终都收敛到了零, 结合公式(4)可知最终都实现了各邻接角距的精确一致, 也即都实现了合围点的精确均匀部署。另外, 从图 5中可以看出, 当采用固定可调增益, 且令K=1时, T(k)收敛较慢, 大约在10 s时收敛到零; 当采用时变可调增益, 且令T*=4 s时, T(k)收敛较快, 并实现了按指定的有限时间收敛到零; 当采用时变可调增益, 且令T*=2 s时, T(k)收敛速度更快, 并实现了按指定的有限时间收敛到零。上述仿真结果验证了本文提出的时变可调增益策略的有效性。

|
| 图 5 3组实验的覆盖代价函数收敛过程对比 |
图 6至图 8分别给出了3组实验的具体仿真结果, 包括合围点方位角qi(k)、邻接角距di(k)以及控制量ui(k)随时间的变化曲线。从图 6a)、图 7a)、图 8a)中可以看出, 合围点方位角qi(k)最终随时间保持恒定不变, 也就是说合围点最终在单位圆上是静止的, 不是在实现均匀分散的情况下沿着单位圆同步旋转的。从图 6b)、图 7b)、图 8b)中可以看出, 邻接角距di(k)最终实现了精确一致, 且稳态值为60°, 这也印证了公式(14)的正确性, 即在智能体个数n=6时, 邻接角距的稳态值是360°/n=60°。从图 6c)、图 7c)、图 8c)中可以看出, 控制量ui(k)最终取值为零, 这是由于当邻接角距di(k)实现一致时, 结合控制协议(5)可知, 此时控制量ui(k)取值为零; 结合公式(1)可知, 当控制量ui(k)为零时, 合围点方位角qi(k)也将不再改变, 也就是说合围点最终是静止的; 另外, 需要说明的是, 若指定的有限收敛时间T*较小, 在时间到达T*时控制量ui(k)将会变得较大, 其变化率也有可能较大, 但该控制量是用于计算理想合围点位置的, 无需具体的执行机构去实现控制量ui(k), 故不必考虑控制受限等问题。

|
| 图 6 实验1仿真结果 |

|
| 图 7 实验2仿真结果 |

|
| 图 8 实验3仿真结果 |
多智能体从多个方向实现对目标的合围, 可有效提高成功围捕的概率。本文针对多智能体合围点部署问题开展研究, 提出了一种完全分布式的控制协议, 在实现合围点围绕目标均匀部署的基础上, 又引入了时变可调增益策略, 能在给定有限时间内实现快速收敛, 大大提高了合围点部署的效率。本文的结果除了应用于多智能体合围点部署外, 在边界环境监测、协同搬运、搜索救援、协同打击等方面也有潜在的应用价值。
| [1] | WANG Zhu, LIU Li, LONG Teng, et al. Multi-UAV Reconnaissance Task Allocation for Heterogeneous Targets Using an Opposition-Based Genetic Algorithm with Double-Chromosome Encoding[J]. Chinese Journal of Aeronautics, 2018, 31(2): 339-350. |
| [2] |
屈耀红, 张峰, 谷任能, 等. 基于距离测量的多无人机协同目标定位方法[J]. 西北工业大学学报, 2019, 37(2): 266-272.
QU Yaohong, ZHANG Feng, GU Renneng, et al. Target Cooperative Location Method of Multi-UAV Based on Pseudo Range Measurement[J]. Journal of Northwestern Polytechnical University, 2019, 37(2): 266-272. (in Chinese) |
| [3] | WANG Xingliang, ZHANG Youan, WU Huali. Distributed Cooperative Guidance of Multiple Anti-Ship Missiles with Arbitrary Impact Angle Constraint[J]. Aerospace Science and Technology, 2015, 46: 299-311. |
| [4] |
刘琨.多无人艇协同搜索与围捕方法研究[D].哈尔滨: 哈尔滨工程大学, 2019 LIU Kun. Research on Cooperative Searching and Hunting Method for Multiple Unmanned Surface Vehicles[D]. Harbin: Harbin Engineering University, 2019(in Chinese) |
| [5] | SONG Cheng, FAN Yuan. Coverage Control for Mobile Sensor Networks with Limited Communication Ranges on a Circle[J]. Automatica, 2018, 92: 155-161. |
| [6] |
李瑞珍, 杨惠珍, 萧丛杉. 基于动态围捕点的多机器人协同策略[J]. 控制工程, 2019, 26(3): 510-514.
LI Ruizhen, YANG Huizhen, XIAO Congshan. Cooperative Hunting Strategy for Multi-Mobile Robot Systems Based on Dynamic Hunting Points[J]. Control Engineering of China, 2019, 26(3): 510-514. (in Chinese) |
| [7] | MO Lipo, YUAN Xiaolin, YU Yongguang. Target-Encirclement Control of Fractional-Order Multi-Agent Systems with a Leader[J]. Physica A:Statistical Mechanics and Its Applications, 2018, 509: 479-491. |
| [8] | LI Chuanjiang, CHEN Liangming, GUO Yanning, et al. Cooperative Surrounding Control with Collision Avoidance for Networked Lagrangian Systems[J]. Journal of the Franklin Institute, 2018, 355(12): 5182-5202. |
| [9] | CHEN Mingzhi, ZHU Daqi. A Novel Cooperative Hunting Algorithm for Inhomogeneous Multiple Autonomous Underwater Vehicles[J]. IEEE Access, 2018, 6: 7818-7828. |
| [10] | WANG Chen, XIE Guangming, Cao Ming. Forming Circle Formations of Anonymous Mobile Agents with Order Preservation[J]. IEEE Trans on Automatic Control, 2013, 58(12): 3248-3254. |
| [11] | SONG Yongduan, WANG Yujuan, JOHN Holloway, et al. Time-Varying Feedback for Regulation of Normal-Form Nonlinear Systems in Prescribed Finite Time[J]. Automatica, 2017, 83: 243-251. |
| [12] | REN Wei, BEARD R W. Consensus Seeking in Multiagent Systems under Dynamically Changing Interaction Topologies[J]. IEEE Trans on Automatic Control, 2005, 50(5): 655-661. |
| [13] | SONIA Martinez, FRANCESCO Bullo, JORGE Cortes, et al. On Synchronous Robotic Networks——Part I:Models, Tasks and Complexity[J]. IEEE Trans on Automatic Control, 2007, 52(12): 2199-2213. |
| [14] | HUANG Chao, YU Changbin. Uniform Upper Bound of the Second Largest Eigenvalue of Stochastic Matrices with Equal-Neighbor Rule[J]. Journal of the Franklin Institute, 2017, 354(14): 6033-6043. |
