

在如今的大数据时代中, 各行各业都在不断产生大量的图片、音频、文本等各类数据。随着数据类型和数量的不断增多, 相应的机器学习模型也应运而生。众所周知, 完善的数据标注是机器学习模型训练与更新的前提, 并且机器学习假设训练集和测试集满足独立同分布, 一旦数据分布发生变化, 大多数的模型就需要被重新训练[1]。但是在现实的应用中, 由于感受器不同、光照变化、视觉角度差异等一些不可避免的因素, 导致数据的分布出现差异, 并且人力标记和模型再训练会耗费大量时间, 而迁移学习却能够很好地解决此问题。
早在1995年时, 迁移学习的概念就已经被提出, 如终身学习、知识迁移、多任务学习、知识巩固等。目前, 迁移学习作为机器学习的一个大分支, 已经广泛应用于图像分类[2-3]、目标识别[4-6]、自然语言处理[7-8]、图像分割[9-10]等领域。迁移学习是利用数据、任务或模型之间的相似性, 将在源域学习或训练得到的模型应用于目标域中。当有海量的数据资源时, 机器学习很容易从大量数据中学习到一个鲁棒性较强的模型。但通常情况下, 研究领域中易获得的数据极为有限, 仅靠有限的数据进行学习, 所习得的模型鲁棒性差且容易造成过拟合。众所周知, 人类可以聪明地运用以前学到的知识, 更快或更好地解决新问题, 迁移学习的研究就是基于这一事实发展的。
领域自适应是迁移学习的研究内容之一, 旨在假设源域和目标域特征空间和类别空间相同而分布不同的条件下, 利用源域中丰富的标签数据学习一个分类器来预测目标域的标签, 主要问题是如何减小源域数据和目标域数据的分布差异。目前, 领域自适应的方法大致可以分为2种:基于样本的域自适应[11-17]和基于特征的域自适应[18-22]。基于样本的域自适应方法是通过对源域中的部分样本重加权来减少分布差异, 即与目标域相关的源域样本被赋予较大的权重, 与目标域无关的源域样本被赋予较小的权重; 基于特征的域自适应方法是寻找一个共享的特征表示空间来减少分布差异(边缘分布差异[17-18]、条件分布差异[23]), 同时保留输入数据的统计属性和几何结构。
在基于样本的领域自适应方面, Dai等[11]提出TrAdaboost方法, 将Adaboost的思想应用于迁移学习中来对样本加权, 但此方法在求解源域样本的权重时所涉及参数较多。Huang等[12]提出核均值匹配(KMM)方法, 通过对样本的概率分布进行估计, 把源域与目标域的分布比值作为样本的权重, 使得加权后的源域与目标域的概率分布尽可能接近, 而概率分布估计所产生的小误差往往会导致权重过大。除了直接增大样本的权重外, Long等[17]还提出迁移联合匹配(TJM)方法, 利用l2, 1范数稀疏化来重加权源域样本, 使得所提取的样本更具有判别性, 但此方法依赖于自适应矩阵, 需要通过不断迭代来选择有利于任务的源域样本。考虑到以往方法的局限性, 本文采用二次规划函数直接求得样本的权重, 避免了因估计概率分布及优化参数过程等造成的误差, 简单易实现, 并且不会受到高维密度估计所带来的维数困难。
在基于特征的领域自适应方面, Pan等[18]提出迁移成分分析(TCA)方法, 利用最大均值差异[24] (MMD)来减少领域间的边缘分布差异, 是一种全局方法, 所以忽视了样本空间内在的局部结构和信息。Long等[19]提出联合分布自适应(JDA)方法, 同时减少领域间的边缘分布差异和条件分布差异, 更能保留样本的原有属性。Wang等[20]考虑到边缘分布自适应与条件分布自适应并不是同等重要, 进而提出动态分布自适应(DDA), 采用一个平衡因子来动态调整2个分布的重要性。大量的研究工作表明, 同时考虑跨域集的边缘分布差异和条件分布差异更有利于实现任务的迁移。
本文提出基于判别性样本选择的无监督领域自适应(DSS)方法, 结合基于特征和样本的领域自适应方法, 通过学习一个由源域和目标域的公共迁移成分张成的子空间, 将不同领域的样本投影到这个子空间中, 可以显著地减少数据分布的差异, 并保留样本的统计属性。由于源域中的数据对于分类任务的重要性不同, 所以采用求解一个二次规划问题来得到样本权重, 进而实现对源域中有利于目标任务的样本重加权。最后采用最小化类内距离来实现同类聚集, 从而提高数据集的分类准确率。
1 DSS算法定义1 (迁移学习) 给定有标签的源域Ds={(x1, y1), …, (xns, yns)}和所要完成的学习任务Ts, 无标签的目标域Dt={x1, …, xnt}和所要完成的学习任务Tt, 其中Ds≠Dt或Ts≠Tt, 通过使用Ds和Ts的知识学习一个预测函数f(·)来完成目标域Dt的任务Tt。
定义2 (领域自适应) 给定有标签的源域Ds={(x1, y1), …, (xns, yns)}和所要完成的学习任务Ts, 无标签的目标域Dt={x1, …, xnt}和所要完成的学习任务Tt, 其中Ds≠Dt或Ts≠Tt, 假定源域和目标域的特征空间和类别空间相同, 但是数据分布不同, 通过使用Ds和Ts的知识学习一个预测函数f(·)来完成目标域Dt的任务Tt。
1.1 减少分布差异给定2个样本集Ds={xi, yi}i=1ns, Dt={xj}j=1nt, 较好地衡量这2个样本集之间的差异是迁移学习的核心内容。现有的度量准则包括欧氏距离、闵可夫斯基距离、马氏距离、KL散度等, 但这些方法的缺点是有参数或是需要密度估计, 所以Smola等[25]提出基于再生核希尔伯特空间(reproducing kernel hilbert spaces, RKHS)的一种距离度量方法——最大均值差异(maximum mean discrepancy, MMD), 则2个样本集的MMD距离定义为
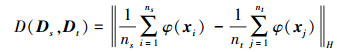
|
(1) |
式中:‖·‖H是RKHS范数;φ是基于核的特征映射。
目前基于特征的自适应方法大都考虑了自适应领域间的边缘分布和条件分布。由于假设源域与目标域的分布不同, 所以通过在RKHS空间中学习2个域的共同迁移成分, 将不同领域的样本投影到迁移成分所张成的空间中, 就能显著地减少数据分布的差异, 同时还能保留数据的原有属性。换句话说, 寻求一个映射φ, 使得P(φ(xs))≈P(φ(xt))且P(ys|φ(xs))≈P(yt|φ(xt))。本文采用MMD的无参数度量方法来计算RKHS空间中源域与目标域的分布距离, 如(2)式所示
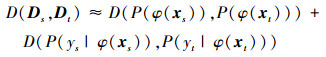
|
(2) |
令X={xs, xt}∈ Rd×(ns+nt), 考虑到实际的非线性问题, 采用一个非线性映射φ将源域和目标域映射到同一特征子空间Φ中。引入核函数κ(xi, xj)=<φ(xi), φ(xj)>=φ(xi)Tφ(xj), 对应的核矩阵为K且Kij=κ(xi, xj)∈ R(ns+nt)×(ns+nt)。
在空间Φ中, 其边缘分布差异为
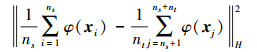
|
(3) |
由于目标域的标签未知, 所以条件概率分布中的P(yt|φ(xt))无法直接得到。一些研究者采用样本选择[26]、核密度估计[27]、协同训练[14]等方法, 但是这些方法需要目标域含有一些带标签的数据或是多个源域, 并不能解决本文的无监督领域自适应问题。根据贝叶斯公式, P(ys|φ(xs))和P(yt|φ(xt))可以用P(φ(xs)|ys=c)和P(φ(xt)|yt=c)来表示, 从而能够产生目标域的伪标签。由于一些伪标签可能是错误的, 故采用迭代的方法不断改善分类精度, 从而减少条件分布差异。
在空间Φ中, 其条件分布差异为
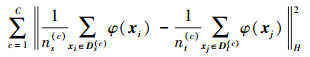
|
(4) |
式中:C是类别个数, Ds(c)={xi:xi∈Ds∧y(xi)=c}是源域中属于类c的样本;y(xi)是xi所属的标签;ns(c)是源域中属于类c的样本个数。对应的, 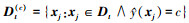
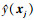
综合(2)~(4)式, 可得到源域与目标域的分布差异
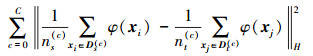
|
(5) |
式中, 当c=0表示边缘分布差异。
1.2 判别性样本选择为了使源域与目标域的样本更好地匹配, 本文在高维的再生核希尔伯特空间中通过样本重加权使得源域与目标域的分布更相近, 即对源域中与目标域相关的样本赋予较大的权重, 使得源域中的数据更具有判别性。在迁移学习中, 假设源域与目标域有不同的分布, 即P(xs)≠P(xt), 并且实际的数据集中包含大量的样本, 所以直接去估计P(xs)和P(xt)是不可行的。前人采用两邻域的分布比值
引理1[28] 设β(xi)∈[0, B](i=1, 2, …, ns)是关于变量xi∈S的函数, 假设集合S中的变量xi满足独立同分布, 则β(xi)的均值和方差存在且有界, β(xi)的平均值分布趋于正态分布, 即均值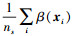
结合本文目的, 约束∫β(xi)dPs(xi)=1, 则有
|
令权重因子β(xi)∈[0, B](B≥1), 则在Φ空间中, 源域与目标域的分布差异为

|
(6) |
式中:
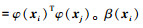
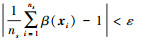
所以(6)式的二次规划函数可表示为
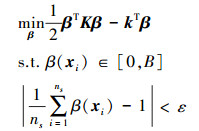
|
(7) |
通过求解此二次规划问题, 可以得到一个β的优化解。
除了最小化领域间的分布差异外, 还要尽可能地保留有利于目标域分类的数据属性。故在Φ空间中对样本实施PCA, 找到一个投影变换A, 把样本点投影到新的低维的空间Γ中, 则最大化投影后样本点的方差为
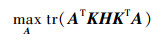
|
(8) |
式中: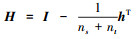
在空间Γ中, 加权后源域与目标域的分布差异为
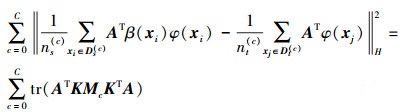
|
(9) |
式中
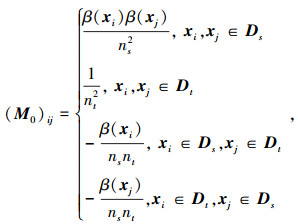
|
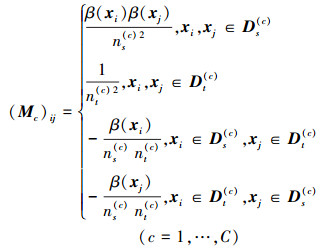
|
领域自适应问题的目的是最小化分布差异, 分类问题则需要最小化类内距离, 将两者统一结合起来, 可使源域中同类样本尽可能靠近, 异类样本尽可能远离, 从而有助于样本分类, 得到性能优良的学习算法[29]。
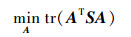
|
(10) |
式中: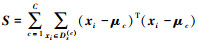
本文算法是通过最小化重加权源域与目标域间的分布差异(即公式(9))以及最小化类内间距(即公式(10))来得到具有判别性的样本, 并尽可能保留样本的数据属性(即公式(8)), 进而提高目标域的分类精度。综合(8)至(10)式, 有
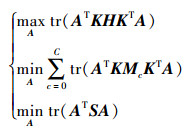
|
此外, 为了避免过拟合, 加入正则化项, 继而得到本算法的目标函数[17-20]

|
(11) |
式中,μ是正则化参数。注意到(11)
式中的分子和分母都是关于A的二次项, 因此(11)式的解与A的长度无关, 只与其方向有关。不失一般性, 令ATKHKTA=I, 即让数据变换前后的方差保持不变, 维持各自的数据特征[18]。所以, 最后的目标函数为
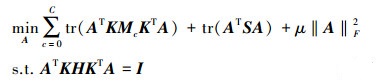
|
(12) |
根据约束优化理论, 定义Λ=diag(λ1, …, λd)为拉格朗日乘子, (12)式所对应的拉格朗日函数为
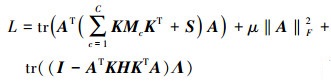
|
(13) |
通过令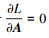
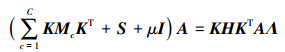
|
(14) |
求解等式(14)得到的d个最小的特征值对应的特征向量组成的矩阵即为自适应矩阵A, 且Z=ATK。
1.5 DSS算法输入 源域Ds={(xi, yi)}i=1ns, 目标域Dt={xj}j=1nt, 正则化参数μ, 子空间维度d
输出 分类准确率
开始
a) 计算核矩阵K和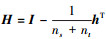
b) 求解(7)式的二次规划函数, 得到优化的权重β; 计算(9)式中Mc(c=0, 1, …, C)和(10)式中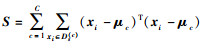
c) 求解(14)式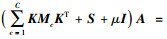
d) 根据{(ATki, yi)}i=1ns训练一个分类器f来更新目标域的伪标签, 矩阵S和Mc(c=0, 1, …, C);
e) 返回目标域的标签{yj}j=1nt;
f) 使用k近邻算法进行分类, 输出分类准确率。
结束
2 实验结果分析 2.1 数据集本文使用3个数据集:Office10数据集, Office+Caltech数据集, ImageCLEF数据集。表 1对这3个数据集进行了描述。Office+Caltech数据集的领域:a(Amazon, 从网上商户下载的图片), w(Webcam, 由网络相机拍摄低分辨率图像), d(DSLR, 数码单反相机拍摄高分辨率图像), c(Caltech-256);Office10数据集是Office+Caltech数据集的部分, 只包含a, w, d领域; ImageCLEF数据集源自ImageCLEF 2014领域适应挑战赛, 它的3个领域:i (ImageNet ILSVRC 2012), p (Pascal VOC 2012), c (Caltech-256)。图 1和图 2分别展示了3个数据集的部分图像。在实验中Office10数据集和ImageCLEF数据集采用图像的SURF特征(800维)。SURF特征被证明对噪声、位移、几何和光度变换具有很强的鲁棒性。Office+Caltech数据集采用图像的Decaf-6深度特征(在ImageNet上训练的卷积神经网络第6个全连接层提取的4 096维特征)。
| 数据集 | 样本 个数 |
特征 维度 |
类别 个数 |
域 |
| Office10 | 1 410 | 800(SURF) | 10 | a, w, d |
| Office+Caltech | 2 533 | 4 096(Decaf-6) | 10 | a, w, d, c |
| ImageCLEF | 1 800 | 2 048(SURF) | 12 | c, i, p |

|
| 图 1 Office+Caltech数据集 |

|
| 图 2 ImageCLEF数据集 |
本算法选用在目标域上的分类准确率作为算法的评价标准, 即准确率为
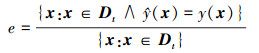
|
实验1 方法比较
将本文算法与6种领域自适应方法(TCA[18], JDA[19], TJM[17], BDA[20], DICD_S[30], DTJM[31])进行比较, 设置参数:子空间维度d=30,正则化系数μ=1,迭代次数T=10,权重上限B=10, 选用线性核函数和2-近邻分类器对3个数据集采用7种迁移方法进行比较, 比较结果如表 2至4所示。
| 源域-目标域 | TCA | JDA | TJM | BDA | DICD_S | DTJM | DSS |
| a-w | 42.03 | 41.02 | 43.73 | 40.68 | 48.14 | 43.05 | 46.10 |
| a-d | 37.58 | 40.76 | 42.68 | 39.49 | 40.13 | 41.40 | 47.13 |
| w-a | 35.18 | 40.50 | 36.43 | 40.29 | 38.94 | 34.76 | 41.65 |
| w-d | 83.44 | 83.44 | 87.26 | 84.71 | 88.54 | 84.08 | 88.54 |
| d-a | 33.40 | 35.91 | 34.13 | 35.80 | 36.95 | 33.19 | 37.89 |
| d-w | 83.05 | 83.73 | 80.34 | 84.07 | 86.44 | 81.69 | 86.10 |
| 平均值 | 52.45 | 54.23 | 54.09 | 54.17 | 56.52 | 53.05 | 57.90 |
| 源域-目标域 | TCA | JDA | TJM | BDA | DICD_S | DTJM | DSS |
| a-w | 74.58 | 77.29 | 75.59 | 76.95 | 72.88 | 75.25 | 77.63 |
| a-d | 80.89 | 85.99 | 82.80 | 85.99 | 84.08 | 83.44 | 87.26 |
| a-c | 79.34 | 81.92 | 82.37 | 81.66 | 82.90 | 82.64 | 83.35 |
| w-a | 82.78 | 89.87 | 85.49 | 89.98 | 75.26 | 86.33 | 91.34 |
| w-d | 100.00 | 99.36 | 100.00 | 99.36 | 99.36 | 99.36 | 99.36 |
| w-c | 76.05 | 82.28 | 77.20 | 82.01 | 82.37 | 78.01 | 82.81 |
| d-a | 88.20 | 92.48 | 87.89 | 92.59 | 85.80 | 87.79 | 92.07 |
| d-w | 98.31 | 98.64 | 98.31 | 98.64 | 98.64 | 98.31 | 98.64 |
| d-c | 80.85 | 84.42 | 80.05 | 84.42 | 83.08 | 80.05 | 84.51 |
| c-a | 90.81 | 89.04 | 90.81 | 89.87 | 91.86 | 90.71 | 90.50 |
| c-w | 79.66 | 82.37 | 82.71 | 82.91 | 77.29 | 81.69 | 81.36 |
| c-d | 78.98 | 80.25 | 86.62 | 80.25 | 86.62 | 86.62 | 82.17 |
| 平均值 | 84.20 | 86.99 | 85.82 | 87.04 | 85.00 | 85.85 | 87.58 |
| 源域-目标域 | TCA | JDA | TJM | BDA | DICD_S | DTJM | DSS |
| c-i | 84.33 | 90.33 | 83.67 | 89.50 | 85.00 | 87.67 | 90.33 |
| c-p | 71.67 | 74.00 | 71.83 | 73.83 | 72.17 | 74.17 | 74.50 |
| i-c | 91.33 | 92.17 | 90.50 | 92.17 | 91.83 | 92.33 | 92.50 |
| i-p | 74.33 | 75.83 | 73.83 | 75.67 | 76.17 | 75.33 | 76.17 |
| p-c | 82.50 | 80.50 | 82.67 | 80.50 | 84.17 | 83.83 | 83.33 |
| p-i | 79.67 | 78.17 | 78.83 | 78.83 | 80.50 | 79.33 | 78.61 |
| 平均值 | 80.64 | 81.83 | 80.22 | 81.75 | 81.64 | 82.11 | 82.61 |
TCA, JDA, BDA均属于基于特征的域适应方法, 并未对源域中的样本进行加权。从表中看出, TCA的分类效果不如JDA和BDA, 原因是TCA仅减少了源域与目标域间的边缘分布差异, 而JDA和BDA同时减少了边缘分布差异和条件分布差异, 能处理更多复杂的数据集。所以同时减少领域间的边缘分布差异和条件分布差异, 更有利于对齐源域与目标域, 保留数据的本质属性。
DICD_S和DSS均减少了域的分布差异, 并最小化类内距离, 但DSS算法对源域中的样本加权, 在样本选择上展现出更好的判别性, 能够有效地将固有的源域知识(特别是判别信息)迁移到目标域中, 进而提升分类性能。
表 3采用数据集的Decaf-6特征进行分类, 显然分类结果优于表 2所采用的SURF特征, 说明深度判别特征在某种程度上更能够保留样本的原有性质和有效信息, 减少领域分布差异, 提高分类的准确性。从表 2至4的实验结果看出, 使用DSS算法在3个数据集(共24个跨域集)上的平均分类准确率较其他6种算法均有所提升, 表明在跨域分类任务上DSS能较好地保留样本的统计属性, 进而自适应分类任务, 是一个相对有效且鲁棒的算法。
实验2 核函数比较
本实验讨论对不同跨域数据集选用不同核函数的分类精确度比较, 分别选用线性核函数、径向基核函数和多项式核函数在3个数据集上使用本文算法进行分析, 结果如表 5至7所示, 线性核函数对Office10数据集和ImageCLEF数据集的分类表现更好; 而径向基核函数对Office+Caltech数据集的分类表现更好。所以可针对不同的数据集选择较优的核函数。
| 源域-目标域 | 线性核函数 | 径向基核函数 | 多项式核函数 |
| a-w | 46.10 | 39.66 | 42.37 |
| a-d | 47.13 | 42.68 | 32.21 |
| w-a | 41.65 | 38.73 | 36.85 |
| w-d | 88.54 | 89.17 | 90.45 |
| d-a | 37.89 | 36.64 | 32.88 |
| d-w | 86.10 | 87.80 | 87.46 |
| 平均值 | 57.90 | 55.78 | 53.54 |
| 源域-目标域 | 线性核函数 | 径向基核函数 | 多项式核函数 |
| c-i | 90.33 | 90.00 | 83.17 |
| c-p | 74.50 | 75.50 | 71.83 |
| i-c | 92.50 | 92.33 | 91.00 |
| i-p | 76.17 | 76.33 | 75.00 |
| p-c | 83.33 | 85.00 | 83.17 |
| p-i | 78.61 | 80.00 | 80.17 |
| 平均值 | 82.61 | 83.19 | 80.72 |
| 源域-目标域 | 线性核函数 | 径向基核函数 | 多项式核函数 |
| a-w | 77.63 | 78.31 | 70.51 |
| a-d | 87.26 | 80.89 | 80.25 |
| a-c | 83.35 | 80.05 | 75.78 |
| w-a | 91.34 | 90.61 | 78.81 |
| w-d | 99.36 | 100.00 | 100.00 |
| w-c | 82.81 | 82.10 | 74.44 |
| d-a | 92.07 | 92.28 | 88.83 |
| d-w | 98.64 | 98.31 | 97.97 |
| d-c | 84.51 | 81.75 | 78.81 |
| c-a | 90.50 | 90.50 | 89.87 |
| c-w | 81.36 | 83.05 | 73.90 |
| c-d | 82.17 | 85.99 | 81.53 |
| 平均值 | 87.58 | 86.99 | 82.56 |
实验3 参数设置
本文在Office10数据集上讨论4个参数设置情况, 分别取k近邻分类器k∈{1, 2, 10, 20, 30, …, 150}, 正则化系数μ∈{0.001, 0.01, 0.1, 1, 10, 100}, 权重上限B∈{1, 2, …, 11}, 子空间维度d∈{20, 30, …, 100}。由于源域和目标域的样本有不同的分布并且目标域没有带标签的样本, 所以不能通过使用交叉验证法来自动调整目标分类器的最优参数, 因此本文采用控制变量法寻找出参数空间中的最优结果:当取值为μ=1, d=30, B=10, k=2时分类效果最好。图 3分别展示了给定3个参数值, 变换剩余一个参数值的平均准确率变化趋势。

|
| 图 3 参数设置 |
实验4 收敛性与有效性分析
图 4为使用7种算法在迭代次数取值为{1, 2, …, 20}的分类精度趋势。除TCA外, 其余6种算法通过迭代来改善分类准确率, 所以在迭代初期这6种算法的准确率都会有明显的梯度上升, 当迭代次数在8之后算法都趋于稳定, 从而验证了本文算法具有鲁棒性。

|
| 图 4 算法收敛性分析 |
跨域分类任务的一个评判准则为类间低相似度和类内高相似度, 所以为了更直观地说明本文算法的有效性, 本实验对Office10数据集源域a和目标域d进行相似度分析。构造原样本空间和TCA, DICD_S, DSS嵌入子空间中样本的相似矩阵, 为了更好地观察, 选择前3类样本, 包含源域a样本268个, 目标域d样本45个(如图 5所示, 黑色代表相似度低)。在相似矩阵中, 左上角子矩阵([0, 267]×[0, 267])和右下角子矩阵([268, 312]×[268, 312])分别表示源域和目标域的域内相似度, 其中对角块子矩阵([0, 91]×[0, 91], [92, 173]×[92, 173], [174, 267]×[174, 267], [268, 279]×[268, 279], [280, 300]×[280, 300], [301, 312]×[301, 312])表示源域或目标域中的类内相似度, 其余子矩阵为相同域的类间相似度; 而右上角([268, 312]×[0, 267])和左下角([0, 267]×[268, 312])表示域间相似度。

|
| 图 5 相似度分析 |
与TCA相比, DICD_S和DSS均减少了领域的条件分布差异, 所以表现出较好的类内相似性和类间可分性。为了更有利于目标域的分类, DSS对源域中的样本进行加权, 故从图 5d)中看出使用DSS算法得到的源域类内相似度更高, 样本更具有判别性, 从而说明本文算法的有效性。
除了分析跨域集的相似度外, 本文对Office10数据集中a-w与a-d 2个跨域集的MMD距离进行度量, 将DSS算法与BDA、DICD_S、DTJM比较, 结果如图 6所示。

|
| 图 6 跨域集的MMD距离 |
从图 6可看出, 随着迭代次数的增加, 本文算法的MMD距离小于其他3种方法, 即表明使用DSS算法更能减少领域间的分布差异, 从而验证了本文算法的有效性。
3 结论本文提出基于判别性样本选择的无监督领域自适应(DSS)方法, 旨在通过三方面来实现跨域自适应:(1)将源域与目标域映射到同一子空间, 减少两域的边缘分布差异和条件分布差异; (2)对源域中的某些样本重加权, 使得选择的样本更具有判别性; (3)减少源域的类内间距, 从而使同类样本更聚集, 异类样本更分散。最后通过对比实验可看出, DSS是一种有效且鲁棒的领域自适应方法。
本文算法虽然较前人结果上有了一定的改进, 但是仍有不足之处。如本文算法中分类器仅选用k近邻法, 后续将尝试采用不同的分类方法来提高分类精度。随着目前深度学习的发展, 各种深度学习模型不断被提出, 所以后续还会考虑扩展到深度迁移学习方面的研究。
| [1] | PAN S J, YANG Q. A Survey on Transfer Learning[J]. IEEE Trans on Knowledge and Data Engineering, 2010, 22(10): 1345-1359. DOI:10.1109/TKDE.2009.191 |
| [2] | SO Y J, NAMHYUN A, YUNSOO L, et al. Transfer Learning-Based Vehicle Classification[C]//2018 International SoC Design Conference, 2018 |
| [3] | SHI Q, ZHANG Y, LIU X, et al. Regularised Transfer Learning for Hyperspectral Image Classification[J]. IET Computer Vision, 2019, 13(2): 188-193. DOI:10.1049/iet-cvi.2018.5145 |
| [4] | HUANG Z, CAO Y, WANG T. Transfer Learning with Efficient Convolutional Neural Networks for Fruit Recognition[C]//IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference, 2019 |
| [5] | ZHENG W, ZONG Y, ZHOU X, et al. Cross-Domain Color Facial Expression Recognition Using Transductive Transfer Subspace Learning[J]. IEEE Trans on Affective Computing, 2016, 9(1): 21-37. |
| [6] | AMORNPAN P, PRAISAN P. Face Recognition Using Transferred Deep Learning for Feature Extraction[C]//2019 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering, 2019 |
| [7] | CHEN L. Assertion Detection in Clinical Natural Language Processing: a Knowledge-Poor Machine Learning Approach[C]//2019 IEEE 2nd International Conference on Information and Computer Technologies, 2019 |
| [8] | IOAN C S. Integrating Deep Learning for NLP in Romanian Psychology[C]//2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, 2018 |
| [9] | VAN O A, IKRAM M A, VERNOOIJ M W, et al. Transfer Learning Improves Supervised Image Segmentation Across Imaging Protocols[J]. IEEE Trans on Medical Imaging, 2015, 34(5): 1018-1030. DOI:10.1109/TMI.2014.2366792 |
| [10] | ANNEGREET V O, ACHTERBERG H C, VERNOOIJ M W, et al. Transfer Learning for Image Segmentation by Combining Image Weighting and Kernel Learning[J]. IEEE Trans on Medical Imaging, 2018, 38(1): 213-224. |
| [11] | DAI W, YANG Q, XUE G R, et al. Boosting for Transfer Learning[C]//International Conference on Machine Learning, 2007 |
| [12] | HUANG J, SMOLA A J, GRETTON A, et al. Correcting Sample Selection Bias by Unlabeled Data[C]//International Conference on Neural Information Processing Systems, 2006 |
| [13] | TAN B, SONG Y, ZHONG E, et al. Transitive Transfer Learning[C]//The 21th ACM SIGKDD International Conference, 2015 |
| [14] | CHEN M, WEINBERGER K Q, BLITZER J C. Co-Training for Domain Adaptation[J]. Advances in Data Analysis & Classification, 2011, 8(4): 1-23. |
| [15] | JIANG J, ZHAI C. Instance Weighting for Domain Adaptation in NLP[C]//The 45th Annual Meeting of the Association of Computational Linguistics, 2007 |
| [16] | JIANG J. A Literature Survey on Domain Adaptation of Statistical Classifiers[J]. British Journal of Psychiatry, 2008, 131(7): 83-89. |
| [17] | LONG M, WANG J, DING G, et al. Transfer Joint Matching for Unsupervised Domain Adaptation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014 |
| [18] | PAN S J, TSANG I W, KWOK J T, et al. Domain Adaptation via Transfer Component Analysis[J]. IEEE Trans on Neural Networks, 2011, 22(2): 199-210. DOI:10.1109/TNN.2010.2091281 |
| [19] | LONG M, WANG J, DING G, et al. Transfer Feature Learning with Joint Distribution Adaptation[C]//IEEE International Conference on Computer Vision, 2013 |
| [20] | WANG J, CHEN Y, FENG W, et al. Transfer Learning with Dynamic Distribution Adaptation[J]. ACM Trans on Intelligent Systems and Technology, 2019, 1(1): 1-25. |
| [21] | GRAUMAN K. Geodesic Flow Kernel for Unsupervised Domain Adaptation[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012 |
| [22] | JHUO I H, LIU D, LEE D T, et al. Robust Visual Domain Adaptation with Low-Rank Reconstruction[C]//Computer Vision and Pattern Recognition, 2013 |
| [23] | WANG J, CHEN Y, HU L, et al. Stratified Transfer Learning for Cross-Domain Activity Recognition[C]//IEEE International Conference on Pervasive Computing and Communications, 2018 |
| [24] | GRETTON A, BORGWARDT K M, RASCH M, et al. A Kernel Method for the Two Sample Problem[C]//Neural Information Processing Systems, 2008 |
| [25] | SMOLA A, GRETTON A, SONG L, et al. a Hilbert Space Embedding for Distributions[C]//International Conference on Algorithmic Learning Theory, 2007 |
| [26] | ZHONG E, ZHANG K, REN J, et al. Cross Domain Distribution Adaptation via Kernel Mapping[C]//ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2009 |
| [27] | QUANZ B, HUAN J, MISHRA M. Knowledge Transfer with Low-Quality Data:A Feature Extraction Issue[J]. IEEE Trans on Knowledge and Data Engineering, 2012, 24(10): 1789-1802. DOI:10.1109/TKDE.2012.75 |
| [28] | GEORGE C, ROGER L B. Statistical Inference[M]. 2nd edition. Beijing: China Machine Press, 2002. |
| [29] |
刘建伟, 孙正康, 罗雄麟. 域自适应学习研究进展[J]. 自动化学报, 2014, 40(8): 1576-1600.
LIU Jianwei, SUN Zhengkang, LUO Xionglin. Review and Research Development on Domain Adaptation Learning[J]. Acta Automatica Sinica, 2014, 40(8): 1576-1600. (in Chinese) |
| [30] | SHUANG L, SHIJI S, GAO H, et al. Domain Invariant and Class Discriminative Feature Learning for Visual Domain Adaptation[J]. IEEE Trans on Image Processing, 2018, 27(9): 4260-4273. DOI:10.1109/TIP.2018.2839528 |
| [31] | PENG J, SUN W, MA L, et al. Discriminative Transfer Joint Matching for Domain Adaptation in Hyperspectral Image Classification[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(6): 972-976. DOI:10.1109/LGRS.2018.2889789 |
