

2. 西安轻工业钟表研究所有限公司, 陕西 西安 710061;
3. 中国科学院 声学研究所, 北京 100190;
4. 中国科学院先进水下信息技术重点实验室, 北京 100190
水下目标识别对于海洋资源开发、海洋环境监测、海洋军事应用等具有重大意义[1]。在实际应用中, 由于水下环境的复杂性, 增加了水下目标的检测难度。
目前典型的水下目标检测算法有Fabic等[2]提出的基于形状分类的算法, 该算法利用斑点计数法和形状分析法对水下视频序列中的鱼类进行分类, 但其针对性强, 缺乏通用性, 难以应用于其他目标。Olivern等[3]利用哈里斯和黑森检测器, 对物体进行区域检测与匹配来检测水下目标, 但当水体存在非均匀光照时, 该算法性能衰减很快。
图像的检测、识别主要涉及行人检测[4]、面部识别[5]、图像分割[6]等。在众多图像的检测、识别算法中, 卷积神经网络(convolutional neural network, CNN)表现尤为突出。卷积神经网络[7]是通过端到端的方法进行训练的机器学习模型, 该模型采用梯度下降法来对参数进行调节。模型首先需要在特定数据集上进行训练, 在训练过程中, 模型可以逐渐学习提取图像目标特征, 最后利用提取的特征完成图像分类、目标检测或语义分割等任务。Wang等[8]提出基于尺度空间法的卷积神经网络目标识别算法, 该算法在目标检测准确率方面优于传统算法, 但其检测实时性较差, 并且对复杂环境下水下目标的检测准确率有待进一步提高。
针对文献[8]存在的水下复杂环境中目标检测准确率低、实时性差的问题, 本文在可变形卷积(deformable convolutional)[9]的基础上融合深度可分离卷积(depthwise separable convolution)[10]思想, 首先提出一种称为深度分离可变形卷积的新型卷积结构, 然后对SSD目标检测模型进行优化改进并提出一种基于改进SSD的水下目标快速检测算法(DD-SSD)。该算法首先利用残差卷积神经网络(ResNet)代替原始SSD目标检测模型的基础网络VGG-16, 然后在网络后端用深度分离可变形卷积适当替换标准卷积层, 在提高网络模型检测精度的同时保证了检测速度。该算法模型为真正端到端的检测模型, 可以直接将水下目标图像或者视频输入训练好的网络模型进行目标对象的检测。实验结果证明, 本文所提算法对复杂环境下的水下目标检测准确率有较大提高, 而且检测速度也明显提高。
1 深度分离可变形卷积可变形卷积网络是卷积神经网络的一种变体, 他对于解决复杂的视觉任务, 学习密集空间变化非常有效。深度可分离卷积主要通过对空间信息和深度信息进行去耦合来达到模型加速的目的, 在实际应用中可以进一步减少模型的检测时间。本文主要在可变形卷积过程中融合深度可分离卷积, 提出了深度分离可变形卷积模块, 它可以使网络模型的特征提取能力进一步增强, 同时减少网络模型的参数量, 降低模型的大小, 提高网络模型的运行速度。
1.1 可变形卷积传统卷积神经网络的卷积核的几何结构是固定的, 例如使用等宽等高的正方形卷积核, 这种卷积方式限制了网络模型几何变换建模的能力。如图 1a)所示, 3*3的卷积核大小、形状固定, 卷积过程中几何变换建模的能力不足。可变形卷积网络模型[9]主要针对卷积神经网络普遍对几何变换建模能力的不足, 提出一种新思路, 即在标准卷积核上加入一个可以学习的偏移量使采样网络可以自由变形。如图 1b)~1d)所示, 可变形卷积核的每个元素都按一定规则偏移, 采样位置也就随之变化, 从而提升卷积神经网络的几何变换建模能力, 提高对不规则物体、非刚性目标及复杂环境目标的识别、检测能力。

|
| 图 1 3*3卷积核采样点的位置图 |
Howard等于2017年提出MobileNet[11]移动端、轻量化的模型, 该网络模型由13个卷积层、平均池化层、全连接层以及输入输出层组成, 其核心是深度可分离卷积。深度可分离卷积主要将传统卷积分解为一个深度卷积和一个1*1的传统卷积, 这样处理有助于减少模型参数、降低计算量。深度可分离卷积如图 2所示。

|
| 图 2 标准卷积与深度可分离卷积说明 |
图 2a)表示传统的标准卷积, 图 2b)、2c)表示深度可分离卷积。如果卷积模块的输入为DF·DF·M, 输出为DF·DF·N, 卷积核为DK·DK, 那么标准卷积的计算量为
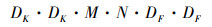
|
(1) |
而深度可分离卷积的计算量为
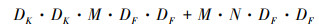
|
(2) |
从(1)至(2)式可以明显看出深度可分离卷积通过解耦空间信息和深度信息, 使模型参数量大大减少, 提升了模型运算效率。
1.3 深度分离可变形卷积针对可变形卷积会增加卷积网络的运行时间, 以及对复杂场景特征提取能力不足的问题, 本文提出深度分离可变形卷积。可变形卷积通过加入偏移卷积实现标准卷积核变形学习的能力。但在偏移卷积的过程中, 可变形卷积使用的是一般的标准卷积, 本文所提的深度分离可变形卷积, 是在可变形卷积学习偏移量的过程中将卷积的空间和通道进行分离, 一方面深度可分离卷积适当减少模型参数, 使模型具有更强的鲁棒性, 提高了卷积网络模型的特征提取能力; 另一方面通过减少模块参数量可以加快模块运行速率, 从而提升整个卷积网络模型的运行速度。
深度分离可变形卷积整个过程可分为3步:首先在输入特征图x上用深度可分离卷积进行采样, 获得x上每个像素点的偏移量; 然后利用双线性插值算法得到每个像素点偏移的像素量, 相当于在卷积核上产生形变达到不固定形状采样的目的; 最后在输入特征图x上用带有偏移量的卷积核进行可变形卷积操作, 即将带有权重的采样值进行加和计算。
假设输入特征图尺寸为DF·DF, 数量为M, 深度卷积核大小为DK·DK, 数量为N, 经过深度可分离卷积后的特征图yoffset大小不变,为DF·DF, 数量为2N, 输出yoffset是指输入特征图x中每个像素点的偏移量。这里得到的偏移量不是整数, 需要利用双线性插值算法进一步得到偏移量在输入特征图上对应的偏移像素量。采用双线性插值算法既可以得到尽可能精确的像素偏移量, 又可以使网络进行反向传播。最后在带有偏移像素量的输入特征图xoffset上进行卷积操作, 相当于在原始特征图x上利用可变形的卷积核进行卷积操作。整个深度分离可变形卷积过程可用(3)式表示
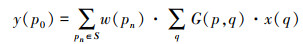
|
(3) |
式中:p0表示输出特征图y中的每个像素点位置;S表示卷积核权重矩阵;pn代表矩阵中的每个权重值;G代表二维双线性插值核;p=p0+pn+Δp代表通过深度卷积学习到的随机偏移量;q为映射到输入特征图x的整体空间位置。
图 3为深度分离可变形卷积的卷积过程示意图, 在输入层的特征映射基础上利用深度可分离卷积获得偏移采样特征提取, 然后通过双线性插值的算法将带有偏移量的采样点集中, 由于变形后的卷积核与原卷积核具有相同的空间分辨率及扩张维度, 所以输出偏移域和输入映射具有相同的空间分辨率, 即N个二维通道分别对应N个二维偏移量, 在网络模型的训练过程中, 梯度通过双线性运算进行反向传播, 原卷积核和偏移卷积核共同学习用于生成输出特征的权值参数量。

|
| 图 3 深度分离可变形卷积 |
深度分离可变形卷积参数量相比可变形卷积有所减少, 网络运行速度加快, 同时由于参数量的减少使网络稀疏化, 网络的特征提取能力进一步加强。
本文在ResNet-50网络模型的基础上进行改进, 主要在网络后端利用改进的可变性卷积替换标准卷积, 目的是进一步提高特征提取能力, 同时减少模型参数, 最终使网络模型在保证检测精度的情况下达到实时性检测的要求。
2 基于改进SSD的水下目标检测算法 2.1 SSD目标检测模型与基于候选区域(region proposal)的目标检测模型(如RCNN、Fast-RCNN、Faster-RCNN)不同, SSD(single shot multiBox detector)[12]是基于多边框(bounding boxes)回归的目标检测模型, 它是在YOLO[13]的基础上发展而来的。Faster RCNN[14]需要2步完成检测, 首先通过CNN得到候选框, 然后再进行分类与回归; 而YOLO与SSD只需要一步就可以完成检测。另外, YOLO需要在全连接层后检测, 而SSD直接采用卷积层进行检测。
SSD以VGG-16为基础模型, 在其基础上新增加了4个卷积层来获取不同尺度的特征图, 其结构示意图如图 4所示。

|
| 图 4 SSD网络结构图 |
SSD模型的输入图像尺寸主要为300×300, 图像经过输入层进入VGG-16卷积网络进行特征提取, 最后通过输出层计算损失量, 其损失函数包含两部分, 分别是定位损失和回归损失, 这两部分共同对网络结构进行评估, 总体损失还是如公式(4)所示
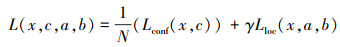
|
(4) |
(4) 式的第一部分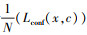
通过增加卷积神经网络的深度可以提升网络的特征提取能力, 而随着网络的加深会出现梯度消失致使网络很难训练。针对这个问题, He等[11]提出了残差网络ResNet, 它在网络不断加深的同时使网络训练变得容易, 提高了卷积神经网络的特征提取能力。
由于水下环境的复杂性及目标对象的特征多变性, 本文首先利用ResNet-50替换SSD的特征提取基础网络VGG-16用以提升一般对象的特征提取能力, 然后将ResNet-50网络的最后3个卷积层(Conv5)换成可变形卷积模块, 进一步提升水下复杂环境下柔性目标的特征提取能力, 最后在可变形卷积的offset过程中融合深度可分离卷积的思想, 达到降低网络运行时间的目的; 同时利用深度可分离卷积的稀疏表示增加网络的鲁棒性进一步提升网络特征提取能力。表 1为改进SSD基础网络模型的结构, 其中conv 5采用本文提出的深度分离可变形卷积模块。
| 层数 | 输出尺寸 | 结构/类型 |
| conv 1 | 114*114 | 7*7, 64, stride 2 |
| pool 1 | 57*57 | 3*3, max, stride 2 |
| conv 2 | 57*57 | 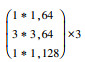
|
| conv 3 | 29*29 | 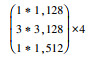
|
| conv 4 | 15*15 | 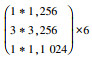
|
| conv 5 | 8*8 | 
|
| pool 5 | 2*2 | 7*7, 平均池化,步长1 |
| fc1000 | / | InnerProduct |
将深度可分离卷积思想融入可变形卷积中的offset过程中, 可以提升可变形卷积模块对非刚性目标复杂特征的提取能力, 同时可以进一步减少模型参数, 保证整体模型的鲁棒性的同时提高模型运行速度。
2.3 基于改进SSD的目标检测模型(DD-SSD)针对复杂环境下的水下目标检测任务, 本文提出一种优化的基于改进SSD的目标检测模型DD-SSD。该网络模型结构首先用2.2节改进的特征提取网络替换原SSD的特征提取网络, 在减少模型参数、提高模型检测速度的同时, 通过自学习产生形变的不规则卷积核对复杂环境下的水下目标进行更好的特征提取, 增加模型在复杂环境下的水下目标检测精度; 然后在特征提取网络后端增加4个卷积层, 充分利用不同尺度下的特征图进行检测。改进后的网络结构如图 5所示。

|
| 图 5 DD-SSD网络结构 |
在基于改进SSD的目标检测网络模型DD-SSD中, 图像首先输入到改进的特征提取网络, 利用深度可分离可变形卷积提升网络对复杂特征的提取能力, 然后在网络后端增加4个卷积层, 并抽取ResNet-50后端的2个卷积层(res4f、res5c)与模型最后的4个卷积共同组成6个卷积层作为检测目标使用。6个卷积层对应特征图的尺度依次减小, 并使用不同的预测锚框。其中在第一个卷积层(res4f)对应特征图的每个像素点设置4个锚框; 第二个卷积层(res4f)对应特征图的每个像素点设置6个锚框。依次, 第三、第四个卷积层对应特征图的每个像素点设置6个锚框, 最后2个卷积层设置4个锚框。锚框大小的生成规则与原始SSD一样。深度分离可变形卷积在保证目标特征信息完整的前提下, 一方面增加了模型的多样性、压缩了模型计算量, 同时减少了模型结构, 使模型检测实时性更好; 另一方面增加了模型几何变换的建模能力, 对复杂场景下的图像目标特征提取能力更强, 可以进一步提升复杂环境下的水下目标检测精度。
3 实验及结果分析为了验证所提算法的优越性, 本文设计了以下实验。首先采集水下柔性目标图像进行标注, 制作实验数据集。本文选取了6种水下生物模型作为检测的目标, 然后通过对比在不同网络模型下的训练、测试结果验证DD-SSD模型对水下目标检测的准确性和实时性。实验采用GPU训练方式, 并利用CUDNN进行加速处理。实验计算机所采用CPU为core i3处理器, GPU为GTX1070。
实验中, 首先利用公开数据集ImageNet对改进的特征提取网络模型预训练, 然后用自制水下目标数据集对基于改进SSD的水下目标检测模型进行训练, 并测试模型检测速度及检测精度。最后, 在公开数据集VOC上对用于检测的单层和多层附加卷积层进行实验, 进一步验证本文所提算法的有效性。
3.1 实验数据集实验采集了6种水下柔性目标共1 133张图片进行了标注工作, 然后按比例进行划分, 其中测试数据227个, 训练数据906个。表 2为详细实验采集数据。
实验中, 首先对各目标检测的基础网络进行图像分类的模型预训练。训练、测试数据集选用Imagenet数据集, 学习率设置为0.05, 训练方式选择multistep, 训练批次batch_size为14, 最大训练次数max_iter为600 000, 每训练10 000次进行一次测试, 最终各目标检测的基础网络对Imagenet图像数据集分类的测试结果如表 3所示。
| 分类准确度 | ResNet | ResNet-Deform | ResNet-DD |
| TOP1 | 57.04 | 58.30 | 59.84 |
| TOP5 | 80.75 | 81.63 | 82.79 |
实验结果表明加入可变形卷积对图像分类精度有一定提升, 但是在融入深度可分离卷积思想后的改进网络结构的图像分类精度最高, 比原始ResNet-50提升超过2个百分点, 比加入可变形卷积的ResNet-Deform网络结构提升超过1个百分点, 说明改进的基础网络特征提取能力更强。
3.3 改进前后模型检测精度及检测速度的实验对比实验模型的训练及测试采用自建的水下目标数据集, 在相同的训练环境及训练方式下, 对各实验模型各训练10 000次, 同时, 实验对各模型均进行100次的运行时间测试, 最后取平均值作为最终模型单次运行时间, 表 4为实验的最终结果。
| 模型结构 | 检测精度/% | 检测时间/ms | 模型参数/MB |
| ResNet-SSD | 83.55 | 48.94 | 127 |
| ResNet-Deform-SSD | 90.65 | 49.42 | 131 |
| DD-SSD | 95.06 | 45.91 | 107.2 |
通过表 4可以发现,加入可变形卷积后的网络模型(ResNet-Deform-SSD)对复杂水下的柔性目标检测精度比基础网络为ResNet的SSD网络模型(ResNet-SSD)提高了7个百分点, 而最终优化后的网络模型(DD-SSD)检测精度最高, 达到95.06%;同时, 可以发现加入可变形卷积之后网络模型(ResNet-Deform-SSD)的运行时间比基础网络为ResNet的SSD网络模型(ResNet-SSD)增加了0.5 ms, 模型参数量增加了4 MB, 而经过加入深度可分离卷积最终优化后的网络模型(DD-SSD)运行时间减少了3.5 ms, 参数量减少23.8 MB, 检测帧率约为22 frame/s, 基本满足实时目标检测要求, 实验总体结果符合预期目标。
图 6为水下目标检测测试数据的检测效果图, 其中图 6a)为原图, 图 6b)为优化后网络模型(DD-SSD)的检测结果图。从图中可以看到, 图 6a)中的水下目标被图 6b)中的矩形框准确框出来, 同时在目标框的左上角显示目标种类及可信度。说明本文提出的基于改进SSD的水下目标检测模型对水下目标检测的有效性和准确性, 可以实现对特定水下环境目标的检测。

|
| 图 6 实验检测结果图 |
为了进一步说明改进可变形模块对网络特征提取有提升能力, 实验选取不同层对比VOC数据集的目标检测结果, 表 5为实验结果对比。
表 5中, 1层(res5c)是指仅用res5残差卷积层进行检测, 6层是指用res4f、res5c以及后加的4个卷积层共6层进行检测, 改进前是指原始网络模型(ResNet-SSD), 改进后是指最终优化后的网络模型(DD-SSD)。实验结果表明在基础网络模型中添加深度分离可变形卷积模块可以提升对一般目标检测的准确率, 其中仅用1层(res5c)作为检测时, 改进后算法相比改进前准确率提高了7.4个百分点; 而用6层作为检测用时, 改进后算法相比改进前算法准确率提高约4.5个百分点。说明本文提出的深度分离可变形卷积确实可以提升网络模型对图像特征的提取能力。
4 结论本文针对复杂环境下的水下目标检测, 提出一种基于改进SSD的水下目标检测模型DD-SSD。实验结果显示, 利用本文算法对复杂环境下的水下目标检测效果明显优于以ResNet为基础网络的SSD目标检测算法, 检测精度(mAP)达到95.06%, 检测速度达到22 frame/s, 满足实际应用的检测速度及检测精度的基本要求。证明了本文所提算法对复杂水下环境目标检测的有效性和实用性。
| [1] | CHANG R, WANG Y, HOU J, et al. Underwater Object Detection with Efficient Shadow-Removal for Side Scan Sonar Images[C]//Oceans, 2016: 1-5 |
| [2] | FABIC J N, TURLA I E, CAPACILLO J A, et al. Fish Population Estimation and Species Classification from Underwater Video Sequences Using Blob Counting and Shape Analysis[C]//Underwater Technology Symposium, 2013: 1-6 |
| [3] | OLIVER K, HOU W. Image Feature Detection and Matching in Underwater Conditions[C]//Proceeding of Society of Photo-Optical Instrumentation Engineers, 2010 |
| [4] | LI J, LIANG X, SHEN S M, et al. Scale-Aware Fast R-CNN for Pedestrian Detection[J]. IEEE Trans on Multimedia, 2018, 20(4): 985-996. |
| [5] | PARKHI O M, VEDALDI A, ZISSERMAN A. Deep Face Recognition[C]//British Machine Vision Conference, 2015: 1-12 |
| [6] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs[J]. Computer Science, 2014(4): 357-361. |
| [7] | WEIDEMANN A D, GRAY D J, ARNONE R A, et al. Comparison and Validation of Point Spread Models for Imaging in Natural Waters[J]. Optics Express, 2008, 16(13): 9958-9965. DOI:10.1364/OE.16.009958 |
| [8] | WANG S H, ZHAO J W, CHEN Y Q. Robust Tracking of Fish Schools Using CNN for Head Identification[J]. Multimedia Tools and Applications, 2017, 76(22): 23679-23697. DOI:10.1007/s11042-016-4045-3 |
| [9] | DAI J, QI H, XIONG Y, et al. Deformable Convolutional Networks[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 764-773 |
| [10] | CHOLLET F. Xception: Deep Learning with Depthwise Separable Convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1251-1258 |
| [11] | HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J/OL](2017-04-06)[2019-05-15]. http://arxiv.org/pdf/1704.04861.pdf |
| [12] | LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot Multibox Detector[C]//European Conference on Computer Vision, 2016: 21-37 |
| [13] | REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788 |
| [14] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. |
| [15] | HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//Conference on Computer Vision and Pattern Recognition, 2016: 770-778 |
2. Xi'an Horological Research Institute or Light Industry Corporation Ltd., Xi'an 710061, China;
3. Institute of Acoustic, Chinese Academic of Sciences, Beijing 100190, China;
4. Key Laboratory of Science and Technology on Advanced Underwater Acoustic Signal Processing, Beijing 100190, China
