

由于从本地读取数据能够得到更大的性能提升,所以任务往数据存储节点迁移是大数据计算的一种趋势。然而,传统集群计算中资源分配采用静态方式,导致大量的数据需要远程访问,因而被越来越多的计算框架放弃。随着以HDFS为架构的数据存储中心的出现,各种各样的大数据计算框架不断涌现,如MapReduce[1]、Dryad[2]、Spark[3]、Flink[4]等。但是,从现有的趋势看,由于无法使用一个通用的计算框架来满足所有的用户需求,这就造成了同一个企业或者组织内,存在同时运行多个计算框架的局面。为了减少基础设施的投入,一些企业或者组织开始使用资源管理系统,如YARN[5]、Mesos[6]、Borg[7]、Omega[8]、Mercury[9]、Kubernetes[10]等,实现在各个计算框架之间共享集群计算资源。
另外,随着分布式环境下计算密集型计算任务以及视频数据处理需求的增加,如分布式机器学习领域等,这些新型计算框架通常采用CPU加速(GPU)的方式来提高性能。新型计算框架则需要一种包含GPU和CPU的集群计算资源,即异构集群资源。而现有的Mesos、YARN等集群资源管理主要考虑CPU、内存和网络带宽资源的管理,对于GPU,采用粗粒度资源分配方式,一次将整个GPU全部分配给任务。这种资源管理的缺点是,当任务只使用少量GPU资源(如,显存)时,由于任务对GPU的独占,其他任务就无法实现GPU资源的共享,浪费了部分GPU计算资源。因此,迫切需要设计和实现一种任务之间共享GPU的细粒度资源管理系统,提高GPU资源的使用效率。这种新的异构集群资源分配方法,它既能保证各种不同的计算框架在共享异构集群计算资源时,避免CPU任务分配过多而GPU资源“饥饿”,或者GPU任务过多而CPU资源“饥饿”,也能保证GPU计算资源在任务之间实现细粒度的共享,提高GPU计算资源的使用率。
论文的主要工作是提出了一种集中式异构集群细粒度资源分配方法,提高了集群计算资源的整体利用率。第一,设计了一种异构集群资源管理框架,满足不同计算框架对异构资源的共享;第二,提出了一种混合主资源公平(hybrid domain resource fairness, HDRF)分配模型,实现了CPU资源与GPU资源之间的合理分配;第三,通过GPU显存的分割,实现了GPU资源的细粒度分配,满足了GPU资源在不同任务之间的共享。
1 研究现状现有的集群计算资源管理系统,主要针对CPU和内存,使用集中或者分布式资源管理模型。YARN采用集中式管理,提供FIFO、容量以及公平分配3种资源调度方式。其资源仅包含CPU核以及内存,无法管理GPU资源。文献[11]扩展了YARN的GPU资源管理方式,采用任务独占GPU资源,其缺点是缺乏CPU、GPU资源的混合共享。Mesos使用DRF[6]实现资源在不同计算框架的公平分配。针对不同的计算框架,设置CPU核或内存作为主资源,在调度过程中,选择主资源使用量最小的计算框架,向该计算框架提供资源,以期实现集群资源的公平分配。算法的缺点是只考虑CPU以及内存资源,GPU资源采用粗粒度分配方式,不利于GPU资源的共享。另外,算法采用串行方式分配资源,存在延迟情况。Omega解决了Mesos的串行分配的缺点,但是需要处理分配冲突,而且尚未发现有GPU资源的管理。分布式资源管理框架Mercury很好地解决了实时任务的延迟分配问题,但是,不支持GPU资源的管理。Kubernetes虽然实现了GPU资源的管理,但是GPU资源亦采用独占方式。Borg使用集中模型,尚未发现对GPU资源的管理。文献[11]、Mesos以及Kubernetes等资源管理系统,由于只是按照GPU卡的个数来管理GPU资源,因此很难实现GPU资源的共享,即实现细粒度的GPU资源管理。本文中,通过将GPU显存引入集群资源管理范围,通过GPU可用显存的大小来调度任务,从而实现了GPU细粒度的资源分配。
针对单纯的GPU集群[12-13],现有资源管理系统主要研究如何构建GPU集群并管理GPU资源,这些系统按照日历或者静态方式分配GPU资源,无法满足不同计算框架之间的动态资源分配。而本文提出的异构集群资源管理策略,既可以管理CPU资源,又可以管理GPU资源,并且实现了不同计算框架之间的动态资源分配。
2 异构集群资源管理模型本文主要针对CPU-GPU的异构集群,不涉及性能配置等异构的情况。首先给出异构数据中心上资源管理系统的整体结构。然后,介绍计算框架请求资源并提交任务的运行过程。最后给出了细粒度任务的共享资源分配算法。
2.1 系统结构异构数据中心资源管理系统由计算节点和资源管理中心组成,如图 1所示。

|
| 图 1 异构集群资源管理模型 |
计算节点由节点资源管理、任务管理器以及运行队列组成。它是任务执行的主体,负责进行节点的资源管理、任务执行调度和任务运行状态的控制,另外,计算节点向资源管理中心汇报任务的状态和节点资源信息。对于每个GPU,按照GPU显存的大小对GPU进行细粒度分割。计算节点向资源管理器汇报可用显存的大小,资源管理中心可以将剩余的GPU显存分配给其他任务,实现任务对GPU的细粒度共享。
资源管理中心由计算框架管理、任务队列、任务日志、资源分配以及资源监控组成。计算框架管理会管理计算框架生命周期内的注册、日志登记、运行过程控制和退出的整个过程;任务日志完成计算框架对应的状态信息的记录,包括创建框架日志文件、所有任务的DAG图、任务的预想开始时间、预想结束时间、资源需求信息以及数据要求信息;任务队列中包含所有的排队状态的可执行任务,将任务提交到对应的计算节点运行队列;并从资源监控获得集群节点资源信息,然后将资源公平地分配给任务队列中的任务;资源监控收集并记录各个集群节点可使用的计算资源,主要包括CPU核数、节点可用内存、GPU卡的编号以及对应的GPU显存大小、磁盘空间和网络带宽等信息。
2.2 资源管理运行过程整个资源管理的运行过程按照以下步骤完成(以下的步骤序号与图 1中序号对应)。
1) 计算框架注册:
步骤1 计算框架运行后,其调度器向资源管理中心的计算框架管理器发送注册信息;
步骤2 计算框架管理器将注册信息写入到日志记录中。
2) 任务的资源分配:
步骤1 计算框架接收到注册回复消息后,向任务队列中提交自己的任务;
步骤2 资源分配从日志记录中获得各个计算框架中已经结束的任务和正在执行的任务,计算出各个计算框架正在使用的资源信息;
步骤3 从资源监控中获得可用资源信息;
步骤4 将资源提供给任务队列中的任务;
步骤5 任务队列根据资源分配结果,将任务转送到资源所对应的计算节点运行队列中。
3) 任务的执行:
步骤1 运行队列负责将任务启动并执行;
步骤2 任务的排队、开始、结束信息提供给计算节点的任务管理器。
4) 资源状态的更新:
步骤1 节点资源管理启动任务管理器;
步骤2 一旦任务的状态发生变化,任务管理器将信息汇报给节点资源管理器;
步骤3 节点资源管理器将任务状态信息以及可用资源信息发送给资源监控;
步骤4 资源监控更新日志记录中对应的任务的状态信息。
2.3 混合DRF资源分配算法对于异构集群资源,本文提出混合DRF资源分配算法,该算法能够保证CPU计算框架和GPU计算框架共享计算资源。对于每个计算框架,除了计算其占用的CPU核以及内存的份额外,还需要单独计算其GPU资源使用。对于单纯的CPU计算任务,采用CPU的逻辑核作为分配单元;对于GPU计算,只需要较少的CPU资源完成初始化和启动,主要考虑GPU资源,为实现细粒度共享,任务需要的GPU显存大小需要确定,根据显存大小,就可以确定共享的任务的数量。综合考虑GPU资源显存份额,再考虑CPU以及内存的份额,实现这些资源份额在不同框架上的公平共享,即混合DRF算法。
集群中的资源包括CPU核数VC, 内存大小VM,GPU显存大小VG,集群全部资源表示为A(VC, VM, VG), 已经使用的资源表示为R(VC, VM, VG), 可用资源表示为A-R。
计算框架表示为f, 计算框架中的任务表示为t, 每个任务使用的资源表示为r。假如集群中有n个计算框架, 可表示为F={f1, f2, …, fn}, 其中fi代表第i个计算框架。如果fi中有k个任务, 表示为Ti={t1i, t2i, …, tki}, 其中tji表示计算框架fi的第j个任务。任务tji需要的计算资源表示为rji= < VC, VM, VG>。
如果计算框架fi中, 有p个任务正在运行, 那么其使用的资源总和表示为Ri(VC, VM, VG), 其中CPU核数为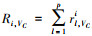
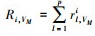
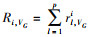
正在运行的任务使用的资源量与系统总的资源量的比值称为资源比, 用s表示。计算框架fi的CPU、内存和显存的资源比分别为sci=Ri, VC/AVC, smi=Ri, VM/AVM和sgi=RiVG/AVG。资源比中最大的记为主资源si, 即si=max{sci, smi, sgi}。
当系统的可用资源为A-R时, 资源分配器首先计算各个计算框架的主资源, 选择主资源最小的框架作为优先分配可用资源的计算框架, 然后再根据计算框架中未执行的任务的资源需求与可用资源的大小决定哪个任务获得计算资源。假如计算框架fi的主资源si最小, 计算框架fi获得资源分配权力, 从自己未执行的任务中选择一个可以符合以下要求的任务tji执行。对于CPU任务, 即, ①任务tji的CPU核数需求小于A-R中的CPU核数, tij, VC≤(A-R)VC; ②任务tji的内存需求小于A-R的内存大小, tij, VM≤(A-R)VM; 对于GPU任务, 即, ③任务tji的GPU显存需求小于A-R的显存大小, tij, VG≤(A-R)VG; 当前计算框架没有任务满足要求时, 可根据主资源选择下一个计算框架。
为了避免某些资源要求高的任务的“饥饿”问题, 使用资源预约机制。在资源分配器中提前设置了一个超时时间OT, 而对于每个任务都有一个等待资源的时间, 记作WT, 这个时间从任务提交到任务队列上开始计时, 当任务等待资源的时间达到了超时时间, 就为这个任务进行资源预留。一旦集群的可用资源满足该任务的预留资源要求, 就分配资源。在资源分配时, 资源分配器检查是否存在延迟超过的任务, 如果有, 该资源保留, 直到为任务tji预留到需求的资源为止。
算法1:HDRF
输入:计算框架集合F, 可用资源容量R, 超时时间OT
输出:计算框架的任务分配的资源容量
过程:
S1 A= < VC, VM, VG>//全部资源容量
S2 R= < VC, VM, VG>//已经使用的资源容量
S3 F={f1, f2, …, fn}//n个计算框架
S4 R1, R2, …, Rn//n个计算框架使用的资源
S5 s1, s2, …, sn//n个计算框架的主资源
S6 while(F≠null){
S6.1 computing sci//计算CPU比值
S6.2 computing smi//计算内存比值
S6.3 computing sgi//计算显存比值
S6.4 computing si//计算主资源
S6.5}
S7 if(
S7.1 reserve tji;
S7.2 return;
S7.3}
S8 fl=min{s1, s2, …, sn}//选择主资源最小的计算框架
S9 if(
S9.1 update R, Rl
S9.2}
算法的S1到S5为设置初始值。S6计算各个计算框架正在使用的资源比值。S7检查延迟超时任务, S8根据各个计算框架的主资源值, 选择主资源最小的计算框架。S9选择最等待资源时间最长以及资源需求小于可用资源的任务, 并更新系统的使用资源量以及当前计算框架的资源使用量。
3 系统评价系统在一个集群上进行试验, 集群中包含8台NF5468M5服务器, 每台服务器2颗Xeon2.1处理器, 每个处理器包含8个核, 32 GB DDR4内存, 2块RTX2080TI GPU卡, 10 GB显存, 总的资源容量为:128核, 256 GB内存, 160 GB显存。1台AS2150G2磁盘阵列, 用于存储数据。
3.1 资源使用率的评价测试时, 使用了2个计算框架JOB1和JOB2, JOB1是字符串统计程序, 其每个任务使用 < 2 core, 2 GB内存>, 其主资源为CPU; JOB2是完全GPU实现的矩阵乘法, 其每个任务使用 < 1 core, 4 GB内存, 4 GB显存>, 其主资源为GPU。
图 2a)是JOB1中的任务随着时间变化而分配得到的CPU和内存资源曲线, 图 2b)是JOB2中的任务随着时间变化而分配得到的CPU、内存和GPU显存资源曲线, 图 2c)是JOB1和JOB2随着时间变化而分配得到的主资源曲线。在前1 min, JOB1的主资源是CPU, JOB2的主资源为GPU内存, 在后续的时间里面, 每个作业都能够使用60%左右自己的主资源, 高于平均分配资源给不同的作业的方式。所以, 从测试的数据看, 使用混合主资源分配方法, 可以很好地利用CPU资源和GPU资源。

|
| 图 2 资源共享使用比率 |
接下来, 本文评价了使用混合DRF资源分配方法与其他资源分配方法的比较, 一个是先来先服务, 另外一个是只使用CPU和内存的DRF方法。
实验中采用大小2种规模任务, 小任务包含的计算资源:CPU任务 < 1 core, 0.5 GB>, GPU任务 < 2 core, 2 GB内存, 2 GB显存>; 大任务包含的计算资源:CPU任务 < 2 cores, 2 GB>, GPU任务 < 1 core, 4 GB内存, 4 GB显存>。同时运行2个计算框架, 每个计算框架中包含任务数量为80, 一半是GPU任务, 一半CPU任务。实验中1个计算框架完成后, 继续提交相同类型任务, 实验持续时间10 min。实验结束后计算完成的任务数量, 结果如表 1所示。
| 任务数 | 大任务 | 小任务 | |||||
| FIFO | DRF | HDRF | FIFO | DRF | HDRF | ||
| CPU | 2 700 | 2 140 | 2 749 | 5 401 | 5 013 | 5 421 | |
| GPU | 2 683 | 2 858 | 2 753 | 5 212 | 5 109 | 5 463 | |
| 总数 | 5 383 | 4 998 | 5 502 | 10 613 | 10 122 | 10 884 | |
从表 1的数据看,不管是大任务还是小任务,FIFO调度方式中,CPU任务完成的数量与GPU完成的大致相同,这是由于FIFO调度时不考虑任务对主资源的要求,2种不同类型的任务数同样对待的结果。对于DRF来说,完成的CPU任务数明显比完成的GPU任务数少,这说明把GPU任务按照CPU或者内存来计算主资源时,它获得的计算机会较多,所以其完成的任务数较多。对于混合DRF,完成的GPU任务数量与完成的CPU任务数大致相同,原因在于各自按照CPU和GPU作为自己的主资源,每种主资源占比相同,所以其完成的任务数大致相当。从总任务来看,虽然FIFO以及混合DRF中完成的CPU与GPU任务数大致相同,但是由于混合DRF考虑各自的主资源,使得每种主资源都得到最大的分配,故混合DRF中,总的完成任务数明显比FIFO中总任务数多出许多。这说明混合DRF,使得不同类型的任务最大化自己的主资源,因而系统的总体资源得到更高效的利用。
3.3 粗细粒度GPU资源使用率的比较针对实验中的任务,计算框架分别按照粗粒度和细粒度方式分配GPU计算资源,实验中1个计算框架完成后,继续提交相同类型的任务,实验持续时间75 min。实验中的计算框架与任务与3.2中的相同,实验结束后,图 3给出了粗细粒度资源调度下GPU资源使用率曲线。

|
| 图 3 粗细粒度GPU使用率比较 |
从图 3可以看出,当任务独占GPU时,GPU利用率大约只有30%左右;当根据GPU显存大小来进行细粒度GPU分配时,由于同一个GPU上存在多个任务对GPU的共享,数据从主机内存拷贝到显存以及从显存拷贝到主机内存是并行运行,间接提高了GPU中kernel函数的执行效率,GPU使用率平均达到45%左右。因此,使用GPU资源的细粒度共享,可以提高GPU资源利用率。
4 结论在异构集群的细粒度资源分配算法中,计算资源的合理分配非常重要,对于CPU和GPU混合的计算框架,采用混合DRF是一种简单有效的资源分配方式。另外,GPU与CPU之间的解耦至关重要,可保证异构集群的整体资源使用效率。
| [1] | DEAN J, GHEMAWAT S. MapReduce:Simplified Data Processing on Large Clusters[J]. Communication of the ACM, 2008, 51(1): 107-113. |
| [2] | ISARD M, BUDIU M, YU Y, et al. Dryad: Distributed Data-Parallel Programs Form Sequential Building[C]//Proceedings of the 2nd ACM SIGOPS/Euro Sys European Conference on Computer Systenm, 2007: 59-72 |
| [3] | ZAHARIA M, N. CHOWDHURY N M M, FRANKLIN M, et al. Spark: Cluster Computing with Working Sets[R]. Technical Report UCB/EECS-2010-53, 2010 |
| [4] | PARIS Carbone, ASTERIOS Katsifodimos, STEPHAN Ewen, et al. Apache Flink:Stream and Batch Processing in a Single Engine[J]. IEEE Data Engineering Bulletin, 2015, 38(4): 28-38. |
| [5] | HADOOP Project. Hadoop Capacity Scheduler[EB/OL].(2019-08-23)[2019-08-25]. http://hadoop.apache.org/common/docs/r1.2.9/capacity_scheduler.html |
| [6] | HINDMAN B, KONWINSKI A, ZAHARIA M, et al. Mesos: a Platform for Fine-Grained Resource Sharing in the Data Center[C]//Implementation Berkety, CA: USENIX Association, 2011: 22-35 |
| [7] | VERMA A, PEDROSA L, KORUPOLU M, et al. Large-Scale Cluster Management at Google with Borg[C]//Tenth European Conference on Computer Systems, New York, 2015: 18-34 |
| [8] | SCHWARZKOPF M, KONWINSKI A, ABD-EL-MALEK M, et al. Omega: Flexible, Scalable Schedulers for Large Compute Clusters[C]//Proc of 8th ACM European Conference on Computer Systems, New York, 2013: 351-364 |
| [9] | KARANASOS K, RAO S, CURINO C, et al. Mercury: Hybrid Centralized and Distributed Scheduling in Large Shared Clusters[C]//2015 USENIX Annual Technical Conference, Berkeley, 2015: 485-497 |
| [10] | ACURA P. Deploying Rails with Docker, Kubernetes and ECS[M]. Berkeley, Apress, 2016 |
| [11] | FUKUTOMI D, IIDA Y, AZUMI T, et al. GPUhd: Augmenting YARN with GPU Resource Management[C]//International Conference on High Performance Computing in Asia-Pacific Region, 2018 |
| [12] | MYEONGJAE J, SHIVARAM V, AMAR P, et al. Multi-Tenant GPU Clusters for Deep Learning Workloads: Analysis and Implications[EB/OL].(2018-05-13)[2019-08-10]. http://www.microsoft.com/en-us/research/publication/multi-tenant-gpu-clusters-deep-learning-workloads-analysis-implications/ |
| [13] | VOLODYMYR V, KINDRATENK O, JEREMY J, et al. GPU Clusters for High-Performance Computing[C]//2009 IEEE International Conference on Cluster Computing and Workshops, New Orleans, USA, 2009: 1-8 |
