

2. 陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021
近年来,研究人员提出了多种声学特征提取技术,以提高由目标辐射噪声特性识别舰船的能力。然而,不同应用场景下这些特征具有不同的有效性,甚至存在无效和冗余的特征[1]。直接使用所有特征进行识别分类,不仅会消耗额外的存储空间,增加模型训练成本[2],还会因模型复杂度过高而降低识别正确率。因此,特征降维是识别分类系统中的重要环节。
特征降维可分为特征变换与特征选择2类[4]。特征变换的目的是去除特征间的冗余,如采用主成分分析(principal components analysis,PCA)等[5]。基于相关分析, 特征变换能够在保留原特征主要信息的前提下得到其低维表示形式。然而,特征降维方法仅考虑了特征之间的冗余,忽略了特征与类别间的关联,因此无法量化各个特征的有效性。此外,变换后的低维特征丢失了原始特征的物理含义,不利于研究人员的理解和分析[4]。
特征选择的关键是构建有效的特征子集评价指标,包括基于分类性能的评价指标以及基于数据本身统计特性的评价指标等。据此,特征选择可以分为封装模型、嵌入模型和过滤模型3类[6]。封装模型基于特征子集的分类性能进行特征选择。例如,文献[7]利用支持向量分类器的结果,得到了具有较高分类正确率的特征子集。但受限于分类器的训练过程,封装模型存在运算量大,计算时间长的问题。为了兼顾分类性能和特征选择效率,嵌入模型在构建分类器的过程中进行特征选择。文献[8]提出了最小绝对值收敛和选择算子法(least absolute shrinkage and selection operator, LASSO),通过在线性分类器中引入范数正则化项对特征权重进行稀疏化,然后选择权重系数大于0的特征。在此基础上,研究人员提出了多种基于LASSO的特征选择方法[9-10],能够同时进行分类器构建和特征选择,具有良好的稳定性。但是,LASSO方法在处理高维数据时计算量较大,容易产生过拟合[11]。此外,由于LASSO方法所选特征子集依赖于分类器,泛化能力较差[4]。为了得到通用性更强的特征子集,过滤模型采用独立于分类器的方法,仅依据数据本身特性评估特征或特征子集。典型过滤模型包括Fisher得分法[12-13]、拉普拉斯分数法[14-15](Laplacian score, LS)以及相关特征选择法[16-17](correlation-based feature selection, CFS)。Fisher得分法对每个特征打分,使得在高分特征构建的空间里,同类别样本点间距尽可能小,而异类样本点间距尽可能大。LS能够依据样本空间的局部几何结构对特征子集进行评估。然而,上述2种方法均无法去除特征集合中的冗余特征[18],即与类别无关的特征或与已选特征提供相似信息的特征[19]。基于特征与类别高度相关且特征间低冗余的原则,Hall提出了基于相关度量的CFS。该方法利用Pearson系数,从特征与类别以及特征相互之间的相关性对特征进行综合评价。但由于使用线性相关度量准则,此方法不适用于分析特征间的非线性关系。
在对水下目标辐射噪声进行特征选择时,由于目标的多样性和水声信道的复杂性,其声学特征之间可能存在多种线性相关之外的复杂关系。针对此问题,本文提出一种基于归一化最大信息系数的特征选择方法(normalized maximal information coefficient feature selection, NMIC-FS)。通过最大信息系数度量特征间的线性及非线性关系,该方法能够全面评估特征子集的相关度、冗余度;同时,结合前向序列特征搜寻策略,该方法能够快速搜寻特征子集空间,具有较高的计算效率。本文将所提方法应用于实测ShipsEar[20]舰船辐射噪声数据集。实验结果表明所提方法可在保持较高分类性能的前提下去除无关、冗余的特征;同时,与其他特征选择方法的比较结果表明,该方法能够以较小规模的特征子集得到更高的分类正确率。
1 最大信息系数理论最大信息系数[21-22](maximal information coefficient, MIC)以2个随机变量间的联合概率密度度量其相关程度。MIC不仅可以度量随机变量之间的线性关系,还可以度量随机变量之间的非线性关系以及广义的非函数关系,从而可以挖掘出随机变量之间的深层联系。
由于实际应用中通常无法直接获得随机变量的联合密度函数, 需要由样本估计其经验联合概率密度函数。对于二维联合随机变量(X, Y), 其样本集合记为D={(xi, yi)|i=1, 2…N}。其中, N为样本容量。通过分别将X和Y的值域划分为m和n个不同的区间, 可将样本空间离散化为m×n的网格G。在指定的网格G下, 经验联合概率密度和经验边缘概率密度可分别由各格子中的样本数目和区间内的样本数目在样本容量中的占比估计, 并可进一步估计出互信息I(D|G)
|
(1) |
式中:D|G表示使用网格G划分样本集合D时引入的概率分布;p(x)和p(y)分别是X和Y的经验边缘概率密度;p(x, y)是X和Y的经验联合概率密度。
在离散化样本集合D时, 同样的网络规模m×n下可能存在多种不同的值域划分方式。所有可能的网格G上的最大互信息记为
|
(2) |
为了比较不同规模网格G上的最大互信息, 将I*(D, m, n)进一步标准化如下
|
(3) |
基于最大互信息, 随机变量X和Y之间的MIC定义为
|
(4) |
式中, B(N)为样本个数的函数, 通常设置B(N)=N0.6[21]。MIC(X, Y)的取值范围在[0, 1]。
2 归一化最大信息系数特征选择方法归一化最大信息系数特征选择方法(NMIC-FS)主要由特征子集评价指标与特征子集搜索策略两部分构成。本节分别介绍该方法中基于归一化MIC的特征子集评价指标以及启发式的前向序列特征子集搜索策略。
2.1 基于归一化MIC的特征子集评价特征选择的目的是寻找一个最优特征子集, 使该集合中的特征与类别高度相关, 同时特征间互不相关。记{xi, ci|i=1, 2…N}是样本容量为N, 特征全集为F={f1, f2…fM}的数据集, 其中xi为具有M维特征的样本, ci为对应的类别, 将N个样本的类别记作类别变量c。本文分别使用MIC(fi, c)和MIC(fi, fj)估计特征fi与类别c的相关度以及特征fi和fj之间的冗余度。MIC(fi, c)的取值越接近于1表明该特征与类别的关联度越高, 反之两者相关程度越弱。同样, MIC(fi, fj)取值越高说明fi和fj之间的冗余度越高, 相互可替代性越强。
为了提高特征选择性能, 本文依据相关度以及冗余度这2个指标优化特征子集, 使得该子集中的特征与类别高度相关, 同时各个特征之间互不相关。然而, 对于不同的数据集, MIC(fi, c)和MIC(fi, fj)的取值区间不同。若直接使用MIC(fi, c)和MIC(fi, fj)估计相关度和冗余度, 则取值较小者会被淹没, 从而使特征子集的评价指标出现较大的估计偏差。为了消除这一影响, 本文定义归一化缩放的度量特征fi与类别c相关度
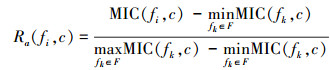
|
(5) |
和度量特征fi与fj之间冗余度
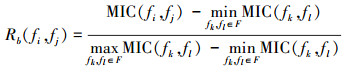
|
(6) |
式中, k≠l。
采用归一化MIC对特征子集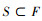
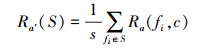
|
(7) |

|
(8) |
式中, s=|S|, fi, fj∈S且i≠j。
为了使所选特征子集中特征与类别高度相关, 而各特征之间互不相关, 需要综合考虑相关度和冗余度这2个指标。据此, 综合(7)式和(8)式, 可得特征子集S的整体评价指标
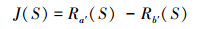
|
(9) |
该指标对特征与类别间的相关程度和备选特征子集冗余度进行整体评估。所选特征子集保留了与类别相关度高的特征, 降低了特征间的冗余度, 能够在提高分类正确率的同时降低计算复杂度。
2.2 NMIC-FS特征选择策略特征选择策略是特征选择的另一个重要构成, 即如何从特征全集中找出可使性能评价指标最大化的特征子集。特征选择策略可采用遍历搜索、随机搜索和启发式搜索等。为了能够以较低的运算成本获得较高的性能评价指标, 本文采用启发式的前向序列搜索策略。
该策略的基本思想是从剩余特征集中逐个选取特征并与已选特征组合成备选特征子集, 然后选择可使备选特征子集性能指标最大化的特征。记S为已选特征子集, R=F\S为剩余特征集。算法开始时S为空集, 无需考虑特征间的冗余度。此时可选择与类别相关度最高的特征, 并将其加入, 即
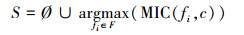
|
(10) |
之后, 逐个从R中选出使(9)式最大的特征, 并将其加入S, 即
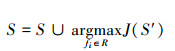
|
(11) |
式中, 备选特征子集S′=S∪fi。
NMIC-FS整体流程如下:
输入:特征全集F={f1, f2…fM}, 设已选特征子集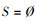
输出:优化特征子集S={f′1, f′2 …f′k}
1) 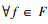
2) 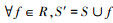
重复步骤2直到|S|=M或J(S)达到最大值。
3 实验数据分析 3.1 数据及其分析流程1) 目标辐射噪声数据
本节将所提NMIC-FS应用于ShipsEar数据集[20]。该数据集采集于西班牙大西洋沿岸的Vigo港口附近区域。水听器的采样频率为52 734 Hz, 并前置了一个截止频率为100 Hz的高通滤波器, 以降低浅水环境噪声的影响。录音中包括了11种不同的船舶类型和背景噪声。船只类型有渔船、远洋班轮、渡轮、拖船、摩托艇、游艇、小帆船等。
由于舰船辐射噪声的多样性以及水声环境的复杂性, 该数据集有效的声学特征难以直接确定。因此, 本实验提取尽可能多的声学构成原始特征集合, 然后使用NMIC-FS进行特征选择。舰船辐射噪声的主要特征集中在3 kHz以下的低频部分。因此, 特征提取前需要将原信号降采样至6 kHz, 以使提取的特征更有代表性。将每段信号提取的声学特征以向量形式构成样本, 则从该数据集中可得样本数2 785。每个样本中各个特征的物理含义如表 1所示。
| 特征名称 | 特征编号 |
| 过零率 | 1 |
| 能量 | 2 |
| 能量熵 | 3 |
| 谱质心 | 4 |
| 谱延展 | 5 |
| 谱熵 | 6 |
| 谱通量 | 7 |
| 谱滚降 | 8 |
| Mel频率倒谱系数 | 9~21 |
| 谐波比 | 22 |
| 基频 | 23 |
| 音色向量 | 24~35 |
| 一阶差分Mel频率倒谱系数 | 36~48 |
| 二阶差分Mel频率倒谱系数 | 49~61 |
2) 数据分析流程
为了验证NMIC-FS在水下目标识别中的有效性和优越性, 本文分别用LS、CFS、LASSO以及NMIC-FS对提取的特征集合进行选择, 并分别将支持向量机(support vector machine, SVM)和随机森林(random forest, RF)作为分类模型, 以评估各方法所得特征子集的分类能力。
实验包括两部分:①NMIC-FS选择前后SVM和RF 2种分类模型所得分类性能的对比, 目的是验证NMIC-FS所得的特征子集是否能够提升实测水下目标辐射噪声的分类性能。②LS、CFS、LASSO和NMIC-FS 4种特征选择方法的比较, 目的是验证NMIC-FS是否能更有效地进行特征选择, 即更快获得具有更高分类正确率、更小规模的特征子集。
3.2 NMIC-FS特征选择前后分类效果比较表 2和表 3分别展示了以SVM和RF作为分类模型时特征选择前后的分类正确率和分类时间。其中, 为了准确评估各特征子集的分类能力, 本文采用10次十折交叉验证估计平均分类正确率, 以降低因训练/测试样本划分不同而引入偏差。具体步骤是:在1次十折交叉验证中, 首先将所有样本随机划分为10等份, 然后分别将其中1份作为测试集, 剩余9份作为训练集, 可得10个不同的测试分类正确率。重复10次上述过程, 将所有测试分类正确率的均值作为分类正确率的最终估计值。
依据NMIC-FS的特征选择结果, 当特征子集规模为26维时, 以SVM为分类模型的分类正确率达到最大值81.2%, 相应的分类时间为3.13 s。与选择前61维特征集合相比, NMIC-FS得到的特征子集分类时间更短, 且能够达到更高的分类正确率, 在保持较高分类性能的前提下去除无关、冗余的特征, 如表 2所示。
当特征子集规模为30维时, 以RF为分类模型的分类正确率达到最大值82.4%, 相应的分类时间为6.61 s。与特征选择前61维特征集合相比, NMIC-FS同样显著缩短了分类时间、提高了分类正确率, 如表 3所示。
使用NMIC-FS对上述舰船辐射噪声的61维声学特征进行选择,并从样本空间分布和特征选择过程2个方面与LS、CFS和LASSO进行对比。
3.3.1 最佳二维特征的样本空间分布为了比较LS、CFS、LASSO和NMIC-FS的特征选择效果,由各方法得到的最佳二维特征构成样本空间,并以可视化方式观察样本的空间分布,如图 1所示。图中特征1和特征2分别表示各方法所得的第1最佳特征和第2最佳特征,2类样本分别来自于滚装船和摩托艇。由2类样本的空间分布可看到,NMIC-FS获得的最佳二维特征可使2类样本间的重叠面积最小,具有更强的可分性,如图 1d)所示。

|
| 图 1 4种方法最佳特征滚装船和摩托艇样本空间分布图 |
为了比较LS、CFS、LASSO和NMIC-FS搜寻优化特征子集的能力,本文基于各特征选择方法估计的特征重要性,按由高至低的次序将特征逐个加入特征子集,然后使用分类正确率评估特征子集的分类性能。依据分类正确率随特征子集规模增加的变化趋势,对各特征选择方法进行分析比较。以分类正确率作为特征子集性能指标时,不同的训练/测试样本划分方式以及分类模型的选择均会影响分类正确率的估计。在本实验中,同样以10次十折交叉验证的方式估计特征子集的平均分类正确率。同时,实验中分别采用SVM和RF作为分类模型评估特征子集的分类能力。
图 2展示了以SVM为分类模型时4种方法的特征选择过程。由分类正确率的变化趋势可以看到,当特征子集规模逐渐增加时,NMIC-FS能够以最快的速度提升分类正确率。当特征子集规模为19时,其平均分类正确率为78.0%,与使用全部特征能够获得的分类正确率相当。当特征子集规模达到26时,平均分类正确率达到81.2%并趋于稳定,高于使用全部特征时的分类正确率。此时,所选特征子集中已包含可用于舰船辐射噪声分类的所有相关信息。当特征子集规模继续增大时,平均分类正确率有所下降,这是因为分类模型的复杂度随特征维数增加,但并没有引入新的有效信息。总体来讲,同CFS、LASSO以及LS相比,NMIC-FS能够以更快的速度提升特征子集的分类正确率,表明其能够从原有特征集合中快速搜寻到更优的特征子集。同时,NMIC-FS能够以更少的特征获得等于甚至优于使用全部特征时的分类性能。

|
| 图 2 基于SVM分类性能的特征选择过程 |
图 3中展示了以RF为分类模型时4种方法的特征选择过程。NMIC-FS可在特征子集规模为11时达到与使用全部特征时相当的分类正确率79%。此外,在特征子集规模为30时达到最高分类正确率82.4%。同CFS、LASSO、LS相比,在特征子集规模相同的情况下,NMIC-FS的特征子集可得到更高的分类正确率;在分类性能相同的情况下,NMIC-FS所需特征子集规模更小。

|
| 图 3 基于RF分类性能的特征选择过程 |
比较图 2和图 3,可以看到4种方法在SVM模型和RF模型下的特征选择过程具有明显差异。不同分类模型下特征子集的分类性能随子集规模增加时的变化趋势不同,且RF模型获得的分类正确率高于SVM模型获得的分类正确率。这种差异表明特征子集的分类性能与分类模型有关。此外,在SVM模型和RF模型下,NMIC-FS均能找到优于其他3种方法的特征子集,对这2种分类模型具有良好的适应性。
4 结论在基于辐射噪声进行目标识别时,声学特征中的无关、冗余数据不仅会降低系统的分类性能,还会增加系统的运算负担和存储成本。基于归一化的最大信息系数,本文提出的NMIC-FS能够综合度量特征与类别的相关性和特征间的冗余性,并结合前向顺序搜索策略实现了快速特征选择。NMIC-FS在ShipsEar实测数据集上的应用结果表明,该方法能在保持较高分类正确率的前提下大幅减少分类所需的特征数目,提高识别系统的效率。与CFS、LASSO和LS的比较表明,NMIC-FS在SVM、RF两种不同的分类模型下的均能够以更少的特征表征原有特征集,且特征子集的分类正确率随着子集规模上升最快,证实了方法的有效性和实用性。
| [1] |
杨宏晖, 戴健, 孙进才, 等. 用于水声目标识别的自适应免疫特征选择算法[J]. 西安交通大学学报, 2011, 45(12): 28-33.
YANG Honghui, DAI Jian, SUN Jincai, et al. A New Adaptive Immune Feature Selection Algorithm for Underwater Acoustic Target Classification[J]. Journal of Xi'an Jiaotong University, 2011, 45(12): 28-33. (in Chinese) |
| [2] | ALELYANI S, TANG J, LIU H. Feature Selection for Clustering:a Review[M]. New York: CRC Press, 2014. |
| [3] | YU L, LIU H. Efficient Feature Selection via Analysis of Relevance and Redundancy[J]. Journal of Machine Learning Research, 2004, 5: 1205-1224. |
| [4] | TANG J, ALELYANI S, LIU H. Feature Selection for Classification:a Review[M]. New York: CRC Press, 2014. |
| [5] | ABDI H, WILLIAMS L J. Principal Component Analysis[J]. WIREs Computational Statistics, 2010, 2(4): 433-459. |
| [6] | GUYON I, ELISSEEFF A. An Introduction to Variable and Feature Selection[J]. Journal of Machine Learning Research, 2003, 3: 1157-1182. |
| [7] |
杨宏晖, 孙进才, 袁骏. 基于支持向量机和遗传算法的水下目标特征选择算法[J]. 西北工业大学学报, 2005, 23(4): 512-515.
YANG Honghui, SUN Jincai, YUAN Hong. A New Method for Feature Selection for Underwater Acoustic Targets[J]. Journal of Northwestern Polytechnical University, 2005, 23(4): 512-515. (in Chinese) DOI:10.3969/j.issn.1000-2758.2005.04.023 |
| [8] | TIBSHIRANI R. Regression Shrinkage and Selection via the Lasso:a Retrospective[J]. Journal of the Royal Statistical Society:Series B(Statistical Methodology), 2011, 73(3): 273-282. DOI:10.1111/j.1467-9868.2011.00771.x |
| [9] | ZOU H. The Adaptive Lasso and Its Oracle Properties[J]. Journal of the American Statistical Association, 2006, 101(476): 1418-1429. DOI:10.1198/016214506000000735 |
| [10] | ZOU H, HASTIE T. Regularization and Variable Selection via the Elastic Net[J]. Journal of the Royal Statistical Society:Series B(Statistical Methodology), 2005, 67(2): 301-320. DOI:10.1111/j.1467-9868.2005.00503.x |
| [11] | CAI J, LUO J, WANG S, et al. Feature Selection in Machine Learning:a New Perspective[J]. Neurocomputing, 2018, 300: 70-79. DOI:10.1016/j.neucom.2017.11.077 |
| [12] | GU Q, LI Z, HAN J. Generalized Fisher Score for Feature Selection[C]//Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Arlington, Virginia, 2011: 266-273 |
| [13] | ZHOU M. A Hybrid Feature Selection Method Based on Fisher Score and Genetic Algorithm[J]. Journal of Mathematical Sciences:Advances and Applications, 2016, 37(1): 51-78. |
| [14] | HE X, CAI D, NIYOGI P. Laplacian Score for Feature Selection[C]//Proceedings of the 18th International Conference on Neural Information Processing Systems, Cambridge, MA, 2005: 507-514 |
| [15] | HUANG R, JIANG W, SUN G. Manifold-Based Constraint Laplacian Score for Multi-Label Feature Selection[J]. Pattern Recognition Letters, 2018, 112: 346-352. DOI:10.1016/j.patrec.2018.08.021 |
| [16] | HALL M A. Correlation-Based Feature Selection for Discrete and Numeric Class Machine Learning[C]//Proceedings of the Seventeenth International Conference on Machine Learning, San Francisco, CA, 2000: 359-366 |
| [17] | MURSALIN M, ZHANG Y, CHEN Y, et al. Automated Epileptic Seizure Detection Using Improved Correlation-Based Feature Selection with Random Forest Classifier[J]. Neurocomputing, 2017, 241: 204-214. DOI:10.1016/j.neucom.2017.02.053 |
| [18] | ZHAO Z, WANG L, LIU H, et al. On Similarity Preserving Feature Selection[J]. IEEE Trans on Knowledge and Data Engineering, 2013, 25(3): 619-632. DOI:10.1109/TKDE.2011.222 |
| [19] | HU L, GAO W, ZHAO K, et al. Feature Selection Considering Two Types of Feature Relevancy and Feature Interdependency[J]. Expert Systems with Applications, 2018, 93: 423-434. DOI:10.1016/j.eswa.2017.10.016 |
| [20] | SANTOS-DOMíNGUEZ D, TORRES-GUIJARRO S, CARDENAL-LóPEZ A, et al. ShipsEar:an Underwater Vessel Noise Database[J]. Applied Acoustics, 2016, 113: 64-69. DOI:10.1016/j.apacoust.2016.06.008 |
| [21] | RESHEF D N, RESHEF Y A, FINUCANE H K, et al. Detecting Novel Associations in Large Data Sets[J]. Science, 2011, 334(6062): 1518-1524. DOI:10.1126/science.1205438 |
| [22] | RESHEF Y A, RESHEF D N, FINUCANE H K. Measuring Dependence Powerfully and Equitably[J]. Journal of Machine Learning Research, 2016, 17(211): 1-63. |
2. School of Electronic Information and Artificial Intelligence, Shaanxi University of Science and Technology, Xi'an 710021, China
