

2. 青岛海洋科学与技术试点国家实验室, 山东 青岛 266000;
3. 国防大学 联合作战学院, 河北 石家庄 050000
目标噪声信号作为当前水声目标识别的主要信号源之一, 所承载的目标特性信息有限, 难以像多传感器探测不同角度表征目标特性, 但经过对目标噪声信号进行分析处理, 可获取不同类别的数据信息, 通过综合利用这些数据信息进行融合判别, 能够有效提高识别分类的正确率, 并降低虚警。近年来, 水声目标噪声非线性特征提取研究工作发展迅速, 目前的研究主要采用希尔伯特-黄变换[1-3]、小波分析[4-5]、高阶谱分析[6-8]等现代信号处理方法提取特征, 并取得了一定的研究成果, 但相关算法过于复杂, 由于在实际工程应用中信号处理的实时性要求, 上述算法在短时间内难以得到实际应用。随着近几年深度学习相关理论的发展, 应用深度学习模型解决水声目标自主识别问题已逐渐成为研究重点。如卷积神经网络[9-13]、深度置信网络[14-15]、堆栈式自编码[16]等模型均被用来解决水声目标特征提取和识别问题, 但相关方面研究仍处于起步阶段。另外, 不少文献在进行识别分类研究时, 使用的样本数据比较单一, 研究对象多为某一特定类别的噪声信号, 训练和测试数据多来自于同一水声目标, 因此在对相关模型进行测试时均取得了相对较好的分类效果。但由于水声目标信号类型繁多且分布广泛, 加之数据来源困难, 导致类别分布不平衡。因此, 其实际应用效果仍有待进行进一步验证。
通常, 多信息源数据融合过程可概括为:利用计算机技术对按时序获得的若干传感器的观测信息在一定准则下加以自动分析、综合以完成所需的决策和估计任务而进行的信息处理过程[17]。因此通常而言, 信息融合多针对于多源或多传感器情况。而本文研究主要关注单传感器多类别目标噪声信息的融合情况, 虽然这与传统多信息源数据融合概念有本质区别, 但其相关方法理论仍有借鉴意义。参照信息融合相关定义, 本研究中多类别特征融合判别过程可概括为:利用计算机技术对按时序获取的目标噪声信号的若干类别数据特征在特征级层面和决策级层面加以融合, 以完成目标属性判别任务。
综上所述, 本文针对当前水声目标噪声识别分类正确率相对较低、虚警率高的问题, 采用长短时记忆网络, 自动学习提取目标噪声时域包络、DEMON谱、梅尔倒谱系数等信息的数据特征, 形成多类别特征子集, 建立了基于多类别特征子集的特征级融合识别分类模型和基于D-S证据理论的决策级融合识别分类模型, 并使用样本库数据和港池试验数据对上述模型进行了测试验证, 对比了多类别特征融合判别与单一类别特征识别分类的差异。
1 多类别特征融合识别分类模型 1.1 长短时记忆网络提取声学数据特征 1.1.1 长短时记忆网络结构单元本文主要基于长短时记忆网络(long short term memory, LSTM), 研究构建目标噪声识别分类模型, 并通过借助网络结构中的“参数共享”机制, 大幅降低模型参数量, 以达到实际应用的目的。长短时记忆网络是循环神经网络的变种模型, 对于处理时间序列数据问题有较好的表现效果, 其基本单元如图 1所示[18], 由1个中心节点和3个门控单元组成。中心节点通常被称为记忆细胞, 用以存储当前网络状态, 3个门控单元分别为输入门、输出门和遗忘门, 用以控制记忆块内信息流动。在前向传播过程中, 输入门用以控制输入到记忆细胞的信息流, 输出门用以控制记忆细胞到网络其他结构单元的信息流; 在反向传播过程中, 输入门用以控制迭代误差流出记忆细胞, 输出门用以控制迭代误差流入记忆细胞。而遗忘门则用以控制记忆细胞内部的循环状态, 决定信息的取舍或遗忘。通过这种门控机制, LSTM网络得以控制单元内信息流动, 使其具备了保存长时间信息的能力, 即“记忆”能力, 并使其在训练过程中能够防止内部梯度受外部干扰, 避免了梯度弥散和梯度爆炸问题。

|
| 图 1 LSTM基本结构单元 |
设单个LSTM记忆块的输入向量为xt, 输出向量为yt, 前向传播公式可表述为[19]:
① 长期记忆单元Ct更新过程
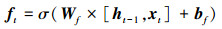
|
(1) |
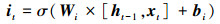
|
(2) |
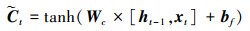
|
(3) |
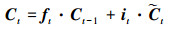
|
(4) |
式中:ft代表遗忘门, it代表输入门; 在每一个时刻, 遗忘门会控制上一时刻记忆的遗忘程度, 而输入门则控制新记忆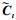
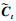
式中Wf, Wi, Wc分别为遗忘门、输入门及Ct更新过程权重参数, bf, bi, bc分别为这3个过程对应的偏置参数。
② 短期记忆单元ht更新过程

|
(5) |
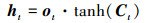
|
(6) |
式中:ot表示输出门, 控制着短期记忆如何受长期记忆影响;(5)
式中Wo, bo分别为输出门的权重和偏置参数。
1.1.2 多层LSTM提取声学数据特征模型主要通过多层LSTM网络自主学习声学数据特征, 图 2给出了多层LSTM网络结构图。

|
| 图 2 多层LSTM网络结构图 |
定义网络输入为X, 输出为Y, 网络层数为n, 每一层网络的时间步数为t。按时间步数对输入序列X进行数据分割, 得到X={x1, x2, …, xt}, 依次输入第一层隐层网络, 根据公式(1)~(6), 各层网络结构单元按时间步数t展开依次计算当前时刻单元短期记忆ht1及长期记忆Ct1(变量中上标表示当前层数, 下标表示当前时间步数), 作为下一时刻结构单元的输入, 最终获取第一层网络输出Y1={h11, h21, …, ht1}, 作为下一层LSTM隐层输入时间序列。设网络隐层数量为n, 由第一层至第n层网络逐层计算, 最终获取多层LSTM输出序列Y={y1, y2, …, yt}={h1n, h1n, …, htn}, 即为输入序列X的特征向量。
结合公式(1)~(6), 多层LSTM前向传播表达式为[20-21]
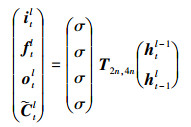
|
(7) |
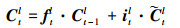
|
(8) |
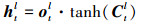
|
(9) |
式中:
将水声目标噪声信号经数据预处理过程, 分别获取时域包络、DEMON谱及MFCC数据集, 使用上述3类训练数据集分别有监督预训练时域包络-LSTM、DEMON-LSTM及MFCC-LSTM并保存模型参数, 使用保存的模型参数按照公式(7)~(9)计算多层LSTM输出, 形成多类别特征子集。其中, DEMON数据集由1 000 Hz以内归一化DEMON谱数据构成; 在获取MFCC数据集时, 首先需对噪声信号样本作分帧处理, 获取各帧36阶MFCC特征向量C, 包括MFCC参数、一阶差分梅尔频率倒谱系数、二阶差分梅尔频率倒谱系数, 按各帧时间先后顺序, 生成各样本MFCC特征数据M作为MFCC-LSTM网络输入向量, 即M={c1, c2, …, cn}, 式中n为单个样本帧数。
1.2 基于多类别特征融合的目标噪声识别分类模型按照融合过程中数据的抽象层次, 可将信息融合划分为数据级、特征级、决策级3个层级, 其中, 数据级融合为最低层级, 决策级为最高层级。理论上融合层级越低, 目标特性信息就越全面, 判别效果越好, 但同时数据量、模型规模等均相对较大, 模型对数据轻微变化也会相对比较敏感。本文主要从特征级融合判别和决策级融合判别2个方面分别构建识别分类模型, 进而对比2种判别模型的识别分类效果。
1.2.1 基于多类别特征子集特征级融合的识别分类模型多类别特征子集特征级融合以最大化分类效果为目的, 将反映噪声信号不同表征面的的多个特征子集进行数学关联、分析、整合, 以便形成统一的融合识别分类框架。图 3给出了基于多类别特征子集特征级融合的噪声信号识别分类框架。

|
| 图 3 多类别特征子集特征级融合识别分类框架 |
由图 3可知, 多类别特征子集特征级融合识别分类的具体内容为:采用特征级信息直接融合策略f(·)=ϕ{βa(·), βb(·), …, βn(·)}获取多类别融合特征。式中f(·)表示特征级融合框架, 是多类别子集特征融合的主要研究对象; ϕ表示融合运算子, 是特征融合框架的核心, 本文主要采用了基于“形式”组合的串联特征融合运算子, 将多种类别形式的特征子集通过串联形式进行直接融合; β表示子集预处理算子, 为特征融合前准备工作, 本文中β主要指通过数据预处理手段获取目标噪声归一化数据向量(如时域包络数据、DEMON谱数据、MFCC系数等)的过程。
本文基于多类别特征子集特征级融合对目标噪声进行识别分类的具体步骤为:①在模型训练阶段, 经数据预处理, 获取训练样本同源多类别数据向量, 如时域包络数据、DEMON谱数据、MFCC数据以及其他类别的数据向量; ②以上述同源多类别数据作为网络输入, 训练多层LSTM, 分别获取各类别数据条件下的特征子集; ③通过ϕ融合算子, 以串联形式直接融合多类别特征子集, 获取训练样本融合特征子集T; ④使用T训练分类器用以进行目标识别分类; ⑤在预测分类阶段, 重复上述过程, 获取测试样本融合特征子集Z, 使用训练好的分类器判别目标类别。
1.2.2 基于D-S证据理论决策级融合的识别分类模型设Θ={θ1, θ2, …, θn}为当前所研究问题的识别框架, 其中包含n个完备且互斥的独立命题θi, 根据D-S融合理论, 在当前识别框架下以M表示Θ内所有元素及元素间并集构成的集合, 其对应了所有目标类型的判别情况。在对水上、水下2类目标进行识别分类时, Θ={θ1, θ2}, 其中θ1表示“水上类别”, θ2表示“水下类别”。并且有M= ∅, θ1, θ2, θ1∪θ2, 其中, θ1∪θ2表示既可能为水下又可能为水上的情况。根据D-S理论, 当前识别框架下mass函数可表述为
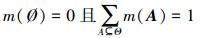
|
(10) |
对于∀A⊆Θ, 在水声噪声信号识别框架Θ上的Dempster合成规则可表述为[22]
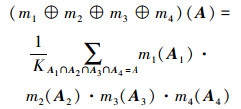
|
(11) |
式中
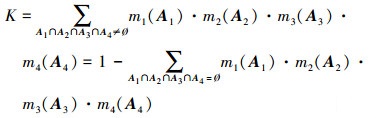
|
(12) |
式中,A1, A2, A3, A4分别表示当前识别柜架下4种判别情况。
如图 4所示, 本文基于D-S证据理论决策级融合对目标噪声进行识别分类的具体步骤为:①对目标噪声经数据预处理获取时域包络、DEMON谱、MFCC数据等多类别训练数据集; ②使用多类别数据训练集有监督预训练各类别数据输入情况下多层LSTM识别分类模型, 并保存网络模型参数; ③在预测分类阶段, 按照上述过程同样获取各类别测试数据, 使用训练好的多层LSTM识别分类模型分别预测目标噪声所属类别概率Pa,Pb等; ④基于D-S证据理论对各单一类别特征判别概率进行决策级融合判别目标类型。

|
| 图 4 基于D-S证据理论决策级融合识别分类框架 |
此外, 本文中仅以水声噪声信号的时域包络、DEMON谱、MFCC数据作为待融合数据信息, 但实际在进行多类别特征融合判别是不仅限于上述3类数据, 也可对其它类别数据进行联合判别。
1.3 模型度量方法本文主要关注水上、水下2类声学信号的分类问题。使用机器学习中准确率、真正率、假正率(虚警率)、假负率[23]及声呐信号检测中检测率、漏检率、虚警率等[24]相关概念, 分别定义本文使用的识别分类正确率Pacc, 以及真正率Pd、假负率Pm、假正率Pfa、真负率Pn等相关概念。其中正确率Pacc指“对水上、水下2类信号识别分类正确的比例”, 真正率Pd指“水下声学信号被正确识别分类的比例”, 假负率Pm指“水下声学信号被错误识别分类的比例”, 假正率Pfa指“水上声学信号被错误识别分类的比例”, 真负率Pn指“水上声学信号被正确识别分类的比例”。
表 1给出了本识别分类问题的分类混淆矩阵[22]。其中, NTP为“真正例”, 即判别为水下类别中正确的数目; NFP为“假正例”, 即判别为水下类别中错误的信号数目; NFN为“假反例”, 即判别为水上类别中错误的信号数目; NTN为“真反例”, 即判别为水上类别中正确的信号数目, 设分类目标总数为N, 则有
| 分类数目 | 预测为水下H1 | 预测为水上H0 | 实际总计 |
| 实际为水下H1 | NTP | NFN | NTP+NFN |
| 实际为水上H0 | NFP | NTN | NFP+NTN |
| 预测总计 | NTP+NFP | NFN+NTN | NTP+NFN+NFP+NTN |
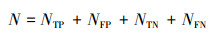
|
(13) |

|
(14) |
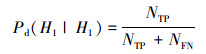
|
(15) |
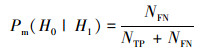
|
(16) |
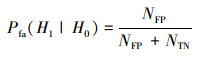
|
(17) |
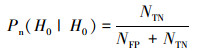
|
(18) |
另外, 使用“ROC曲线”(receiver operation characteristic)衡量识别分类模型性能[25], ROC曲线横坐标为假正率, 纵坐标为真正率。通常, 若一个模型的ROC曲线被另一个模型的曲线完全“包住”, 则后者性能优于前者, 另外也可使用ROC曲线下的面积, 即AUC(area under roc curve)评价模型优劣。
2 模型验证本文首先使用样本库数据对上述多类别特征融合判别方法进行了测试, 之后使用港池试验数据对上述方法进行了验证, 并对比研究了多类别特征融合判别与单一类别特征识别分类的效果差异。
2.1 样本库测试样本库包含65 000条噪声信号, 其中水上类别42 000条, 水下类别23 000条。随机选择2类目标各4/5的样本组成训练集。按照图 3所示过程, 本文使用了在水声信号处理中常用的时域包络、DEMON谱、MFCC系数作为待融合类别数据, 分别通过有监督预训练多层LSTM模型, 自主学习提取目标噪声特征子集, 之后, 采用串联特征融合运算子融合特征子集形成融合特征, 并训练后端识别分类模型, 相关参数设置见表 2。在前期研究中, 在上述3类输入数据条件下, 采用“9层网络-100个LSTM单元节点数”的组合均取得了相对较好的训练效果。同时, 为降低这3类特征子集特征点数、幅值大小等因素差异造成得影响, 设置特征子集点数均为390, 并在进行特征融合之前对各特征子集幅值作归一化处理。
| 输入 数据 |
LSTM 输入节点数 |
LSTM 层数 |
LSTM 单元节点数 |
特征子集 维数 |
| 时域数据 | 30 000 | 9 | 100 | 390 |
| MFCC | 3 861 | 9 | 100 | 390 |
| DEMON | 3 276 | 9 | 100 | 390 |
选取样本库中466条信号进行测试, 根据样本时长进行多次判别, 基于判别统计情况给出最终识别分类结果。
图 5给出了基于统计值的各样本的分类正确概率, 其中, 横坐标为各测试样本编号, 纵坐标为分类正确概率, 另外, 蓝色点表示分类正确, 红色点表示分类错误。从图中可以看出, ①单一类别特征判决情况下, 采用MFCC作输入数据, 样本总体分类正确概率优于其他两类; ②多类别特征融合判别的样本总体分类正确概率优于单一类别特征判别情况。

|
| 图 5 各样本识别分类正确概率 |
同时, 使用“样本均方误差(MSE)”作为衡量样本总体分类效果的标准, 其计算公式可表述为
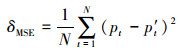
|
(19) |
其含义为样本测试正确概率与期望概率(100%)的偏差, 同样, 也可使用“均方根误差(RMSE)”作为衡量标准, 其计算公式可表述为
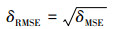
|
(20) |
表 3给出了使用样本库数据测试时, 单一类别数据判别及多类别特征融合判别的δRMSE及δMSE对比情况, 表中结果同样表明多类别特征融合判别的样本总体分类正确概率优于单一类别特征判别情况。
| 判别 效果 |
单一类别数据判别 | 特征级融合判别 | 决策级融合判别 | ||||||||||
| 时域 包络 |
DEMON | MFCC | 时域- DEMON |
时域- MFCC |
DEMON- MFCC |
时域- DEMON- MFCC |
时域- DEMON |
时域- MFCC |
DEMON- MFCC |
时域- DEMON- MFCC |
|||
| δRMSE | 10.14 | 8.05 | 4.81 | 8.22 | 4.64 | 4.23 | 4.59 | 8.29 | 4.91 | 4.19 | 4.31 | ||
| δMSE | 102.93 | 64.82 | 23.20 | 67.63 | 21.53 | 17.93 | 21.23 | 68.8 | 24.16 | 17.6 | 18.59 | ||
图 6样本库测试ROC曲线给出了与图 5相对应的样本库数据测试的ROC曲线, 从图中AUC面积可看出多类别特征融合判别模型较单一类别特征判别模型判别效果更好。

|
| 图 6 样本库测试ROC曲线 |
表 4给出了使用样本库数据测试的分类混淆矩阵, 表中依次分别为使用单一类别特征判别与多类别特征融合判别情况下的测试结果, 根据公式(13)~(18), 计算各度量指标, 详情见表 5, 其结果表明:①当采用多类别特征融合方法进行判别时, 模型判别的正确率、真正率和假正率(虚警率)等指标均优于单一类别特征判别方法; ②在对特征进行两两融合判别时, 识别分类结果易受单一特征判别影响, 如表中时域-DEMON特征级融合及决策级融合判别结果相对较差, 但对上述3类数据同时进行融合判别时, 结果较为稳定, 受单一特征判别影响较小。
| 判别结果 | 判别方式 | 预测为水下 | 预测为水上 | 实际总计 | |
| 实际为水下 | 单一特征 | 时域包络 | 61 | 24 | 85 |
| DEMON | 66 | 19 | |||
| MFCC | 80 | 5 | |||
| 特征级融合 | 时域-DEMON | 69 | 16 | ||
| 时域-MFCC | 79 | 6 | |||
| DEMON-MFCC | 79 | 6 | |||
| 时域-DEMON-MFCC | 79 | 6 | |||
| 决策级融合 | 时域-DEMON | 67 | 18 | ||
| 时域-MFCC | 80 | 5 | |||
| DEMON-MFCC | 79 | 6 | |||
| 时域-DEMON-MFCC | 80 | 5 | |||
| 实际为水上 | 单一特征 | 时域包络 | 103 | 278 | 381 |
| DEMON | 91 | 290 | |||
| MFCC | 26 | 355 | |||
| 特征级融合 | 时域-DEMON | 99 | 282 | ||
| 时域-MFCC | 22 | 359 | |||
| DEMON-MFCC | 17 | 364 | |||
| 时域-DEMON-MFCC | 24 | 357 | |||
| 决策级融合 | 时域-DEMON | 82 | 299 | ||
| 时域-MFCC | 26 | 355 | |||
| DEMON-MFCC | 17 | 364 | |||
| 时域-DEMON-MFCC | 17 | 364 | |||
| 判别方式 | 度量指标 | Pacc | Pd | Pm | Pfa | Pn |
| 单一特征 | 时域包络 | 72.7 | 71.8 | 28.2 | 27.0 | 73.0 |
| DEMON | 76.4 | 77.6 | 22.4 | 23.9 | 76.1 | |
| MFCC | 93.3 | 94.1 | 5.9 | 6.8 | 93.2 | |
| 特征级融合 | 时域-DEMON | 75.3 | 81.2 | 18.8 | 26.0 | 74.0 |
| 时域-MFCC | 94.0 | 92.9 | 7.1 | 5.8 | 94.2 | |
| DEMON-MFCC | 95.1 | 92.9 | 7.1 | 4.5 | 95.5 | |
| 时域-DEMON-MFCC | 93.6 | 92.9 | 7.1 | 6.3 | 93.7 | |
| 决策级融合 | 时域-DEMON | 78.5 | 78.8 | 21.2 | 21.5 | 78.5 |
| 时域-MFCC | 93.3 | 94.1 | 5.9 | 6.8 | 93.2 | |
| DEMON-MFCC | 95.1 | 92.9 | 7.1 | 4.5 | 95.5 | |
| 时域-DEMON-MFCC | 95.3 | 94.1 | 5.9 | 4.5 | 95.5 |
使用港池试验数据对本文模型进行验证, 港池试验示意图如图 7所示。试验过程中, 使用试验船吊放宽带声源播放水声信号, 声源深度约7 m, 声学传感器与声源位同一深度, 距声源直线距离约为100 m。采集播放信号的1/3倍频程谱级约为80~85 dB@1 000 Hz。试验期间, 实际探测水上类别的信号39批次, 水下类别的信号32批次。表 6给出了使用港池试验数据测试的分类混淆矩阵, 其中, 采用单一DEMON特征进行判别为现场试验结果。

|
| 图 7 港池试验示意图 |
| 判别结果 | 判别方式 | 预测为水下 | 预测为水上 | 实际总计 | |
| 实际为水下 | 单一特征 | 时域包络 | 21 | 11 | 32 |
| DEMON(现场试验结果) | 23 | 9 | |||
| MFCC | 26 | 6 | |||
| 特征级融合 | 时域-DEMON | 22 | 10 | ||
| 时域-MFCC | 26 | 6 | |||
| DEMON-MFCC | 26 | 6 | |||
| 时域-DEMON-MFCC | 26 | 6 | |||
| 决策级融合 | 时域-DEMON | 22 | 10 | ||
| 时域-MFCC | 25 | 7 | |||
| DEMON-MFCC | 27 | 5 | |||
| 时域-DEMON-MFCC | 27 | 5 | |||
| 实际为水上 | 单一特征 | 时域包络 | 9 | 30 | 39 |
| DEMON(试验结果) | 9 | 31 | |||
| MFCC | 7 | 32 | |||
| 特征级融合 | 时域-DEMON | 9 | 30 | ||
| 时域-MFCC | 7 | 32 | |||
| DEMON-MFCC | 5 | 34 | |||
| 时域-DEMON-MFCC | 6 | 33 | |||
| 决策级融合 | 时域-DEMON | 9 | 30 | ||
| 时域-MFCC | 8 | 31 | |||
| DEMON-MFCC | 6 | 33 | |||
| 时域-DEMON-MFCC | 7 | 32 | |||
表 7给出了不同判别方式对应的分类指标, 其结果同样表明, 在港池试验数据条件下, 采用多类别特征融合判别效果优于单一类别特征判别效果, 且对上述3类数据同时进行融合判别时, 结果较为稳定。
| 判别方式 | 度量指标 | Pacc | Pd | Pm | Pfa | Pn |
| 单一特征 | 时域包络 | 71.8 | 65.6 | 34.4 | 23.1 | 76.9 |
| DEMON(现场试验结果) | 76.1 | 71.9 | 28.1 | 23.1 | 79.5 | |
| MFCC | 81.7 | 81.3 | 18.8 | 17.9 | 82.1 | |
| 特征级融合 | 时域-DEMON | 73.2 | 68.8 | 31.3 | 23.1 | 76.9 |
| 时域-MFCC | 81.7 | 81.3 | 18.8 | 17.9 | 82.1 | |
| DEMON-MFCC | 84.5 | 81.3 | 18.8 | 12.8 | 87.2 | |
| 时域-DEMON-MFCC | 83.1 | 81.3 | 18.8 | 15.4 | 84.6 | |
| 决策级融合 | 时域-DEMON | 73.2 | 68.8 | 31.3 | 23.1 | 76.9 |
| 时域-MFCC | 78.9 | 78.1 | 21.9 | 20.5 | 79.5 | |
| DEMON-MFCC | 84.5 | 84.4 | 15.6 | 15.4 | 84.6 | |
| 时域-DEMON-MFCC | 83.1 | 84.4 | 15.6 | 17.9 | 82.1 |
为解决水声目标噪声识别过程中识别分类正确率相对较低、虚警高等问题, 本文采用长短时记忆网络, 建立了多层LSTM水声信号特征提取模型, 自动学习提取声学信号时域包络、DEMON线谱、梅尔倒谱系数等信息的数据特征, 构建多类别特征子集。在此基础上, 建立了基于多类别特征子集的特征级融合识别分类模型和基于D-S证据理论的决策级融合识别分类模型, 利用样本库数据和港池试验数据对上述融合识别分类模型进行了测试, 对比多类别特征融合判别与单一类别特征识别分类效果的差异, 得到如下结论:
1) 多类别特征融合判别模型的识别分类效果总体优于单一类别特征判别模型。在对特征进行两两融合判别时, 识别分类结果易受单一特征判别影响, 但对文中时域包络、DEMON谱、MFCC 3类数据同时进行融合判别时, 结果较为稳定, 受单一特征判别影响较小, 因此, 增加融合数据类型, 有助于提高判别稳定性, 降低错误判别结果的影响。
2) 较单一类别特征判别方法, 多类别特征融合判别可有效提高识别分类的正确率, 降低虚警率, 但特征级和决策级2种融合方法优劣程度及融合判别实时性问题仍需作进一步研究。
3) 当融合的局部单一类别数据判别模型相同时, 决策级融合判别更能有效利用单一类别数据判别模型的优化结果, 对各输入数据条件下局部判别模型的限制较小, 模型优化更为简便。相比之下, 特征级融合判别模型受各类别特征子集维数、数量等参数影响较大, 具体而言, 可分性强的特征子集, 对融合判别结果会产生良性影响, 而可分性差的特征子集, 对融合判别结果会产生不良影响。本文仅针对这两种融合判别模型进行了研究介绍, 但由于未开展优化选择相关研究, 因此二者优化后判别效果对比情况需进一步研究探讨。
| [1] |
王逸林.希尔伯特黄变换在矢量信号处理中的应用研究[D].哈尔滨: 哈尔滨工程大学, 2006 WANG Yinlin. Research on the Application of Hilbert-Huang Transformation to Vector Signal Processing[D]. Harbin: Harbin Engineering University, 2006(in Chinese) |
| [2] |
李秀坤, 谢磊, 秦宇. 应用希尔伯特黄变换的水下目标特征提取[J]. 哈尔滨工程大学学报, 2009, 30(5): 542-546.
LI Xiukun, XIE Lei, QIN Yu. Underwater Target Feature Extraction Using Hibert-Huang Transform[J]. Journal of Harbin Engineering University, 2009, 30(5): 542-546. (in Chinese) DOI:10.3969/j.issn.1006-7043.2009.05.014 |
| [3] |
李新欣.船舶及鲸类声信号特征提取和分类识别研究[D].哈尔滨: 哈尔滨工程大学, 2012 LI Xinxin. Research on Feature Extraction and Classification of Ship Noise and Whale Sound[D]. Harbin: Harbin Engineering University, 2012(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10217-1012518423.htm |
| [4] |
韩雪.基于听觉特征的水中目标辐射噪声特征提取[D].哈尔滨: 哈尔滨工程大学, 2013 HAN Xue. Feature Extraction of Underwater Target Based on Auditory Features[D]. Harbin: Harbin Engineering University, 2013(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10217-1014132315.htm |
| [5] |
石超雄, 李钢虎, 何会会, 等. 基于提升小波变换的MFCC在目标识别中的应用[J]. 声学技术, 2014, 33(4): 372-375.
SHI Chaoxiong, LI Ganghu, HE Huihui, et al. Application of the Lifting Wavelet Transform Based MFCC in Target Identification[J]. Technical Acoustics, 2014, 33(4): 372-375. (in Chinese) |
| [6] |
程玉胜, 王易川, 史广智, 等. 基于现代信号处理技术的舰船噪声信号DEMON分析[J]. 声学技术, 2006, 25(1): 276-281.
CHENG Yusheng, WANG Yichuan, SHI Guangzhi, et al. DEMON Analysis of Underwater Target Radiation Noise Based on Modern Signal Processing[J]. Technical Acoustics, 2006, 25(1): 276-281. (in Chinese) |
| [7] |
葛青.水下目标识别中的数据融合技术[D].哈尔滨: 哈尔滨工程大学, 2008 GE Qing. The Information Fusion in Underwater Target Recognition[D]. Harbin: Harbin Engineering University, 2008(in Chinese) |
| [8] |
王杨.水下目标辐射噪声多维特征分析技术[D].哈尔滨: 哈尔滨工程大学, 2012 WANG Yang. Underwater Target Multidimensional Radiation Analysis of Characteristics of the Technology[D]. Harbin: Harbin Engineering University, 2012(in Chinese) |
| [9] |
张大伟, 章新华, 付留芳, 等. 基于听觉感知与卷积神经网络识别舰船目标[J]. 声学技术, 2015, 34(6): 181-184.
ZHANG Dawei, ZHANG Xinhua, Fu Liufang, et al. Recognitiuon of Ships Based on Auditory Sense and Convolutional Neutral Methorks[J]. Technical Acoustics, 2015, 34(6): 181-184. (in Chinese) |
| [10] |
卢安安.基于深度学习方法的水下声音目标识别研究[D].哈尔滨: 哈尔滨工程大学, 2017 LU Anan. Underwater Acoustic Classification Based on Deep Learning[D]. Harbin: Harbin Engineering University, 2017(in Chinese) |
| [11] | VALDENEGRO-TORO M. Improving Sonar Image Patch Matching via Deep Learning[C]//2017 European Conference on Mobile Robots, Paris, 2017 |
| [12] | WILLIAMS D P. Underwater Target Classification in Synthetic Aperture Sonar Imagery Using Deep Convolutional Neural Networks[C]//International Conference on Pattern Recognition 2016, Mexico, 2016: 2497-2502 |
| [13] |
王强, 曾向阳. 深度学习方法及其在水下目标识别中的应用[J]. 声学技术, 2015, 34(2): 138-140.
WANG Qiang, ZENG Xiangyang. Deep Learning Methods and Their Applications in Underwater Targets in Recognization[J]. Technical Acoustics, 2015, 34(2): 138-140. (in Chinese) |
| [14] | KAMAL S, MOHAMMED S K, PILLAI P R S, et al. Deep learning Architectures for Underwater Target Recognition[C]//Ocean Electronics, 2013: 48-54 |
| [15] |
杨宏晖, 申昇, 姚晓辉, 等. 用于水声目标特征学习与识别的混合正则化深度置信网络[J]. 西北工业大学学报, 2017, 35(2): 220-225.
YANG Honghui, SHEN Sheng, YAO Xiaohui, et al. Underwater Acoustic Target Feature Learning and Recognition Using Hybrid Regularization Deep Belief Network[J]. Journal of Northwestern Polytechnical University, 2017, 35(2): 220-225. (in Chinese) DOI:10.3969/j.issn.1000-2758.2017.02.008 |
| [16] |
陈越超, 徐晓男, 姚晓辉, 等. 基于降噪自编码的水中目标识别方法[J]. 声学与电子工程, 2018, 1: 30-33.
CHEN Yuechao, XU Xiaonan, YAO Xiaohui, et al. Underwater Target Recognition method based on Denoising Auto-Encoder[J]. Acoustics and Electronics Engineering, 2018, 1: 30-33. (in Chinese) |
| [17] |
刘同明, 夏祖勋, 谢洪成. 数据融合技术及其应用[M]. 北京: 国防工业出版社, 1998.
LIU Tongming, XIA Zuxun, XIE Hongcheng. Technology and Application of Data Fusion Technicies[M]. Beijing: National Defense Industry Press, 1998. (in Chinese) |
| [18] | KLAUS Greff, RUPESH K, SRIVASTAVA, et al. LSTM:a Search Space Odyssey[J]. IEEE Trans on Neural Networks and Learning Systems, 2017, 28(10): 2222-2232. DOI:10.1109/TNNLS.2016.2582924 |
| [19] | ALEX Graves. Learning Precise Timing with LSTM Recurrent Networks[J]. Journal of Machine Learning Research, 2002(3): 115-143. |
| [20] | WOJCIECH Zaremba. Recurrent Neural Network Regularization[J/OL]. (2015-12-19)[2019-03-01]. https: //arxir.org.pdf/1409.2329v5.pdf |
| [21] | NITISH Srivastava, GEOFFREY Hinton, ALEX Krizhevsky, et al. Dropout:a Simple Way to Prevent Neural Networks from Overfitting[J]. Journal of Machine Learning Research, 2014(15): 1929-1958. |
| [22] |
夏佩伦. 目标跟踪与信息融合[M]. 北京: 国防工业出版社, 2010.
XIA Peilun. Target Tracking and Information Fusion[M]. Beijing: National Defense Industry Press, 2010. (in Chinese) |
| [23] |
PETERFlach. 机器学习[M]. 北京: 人民邮电出版社, 2016.
PETER Flach. Machine Learning[M]. Beijing: Posts & Telecom Press, 2016. (in Chinese) |
| [24] |
田坦, 刘国枝, 孙大军.声纳技术[M].哈尔滨: 哈尔滨工程大学出版社, 1999 TIAN Tan, LIU Guozhi, SUN Dajun. Sonar Technology[M]. Harbin, Harbin Engineering University Press, 1999(in Chinese) |
| [25] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
ZHOU Zhihua. Machine Learning[M]. Beijing: Tsinghua University Press, 2016. (in Chinese) |
2. National Laboratory for Marine Science and Technology, Qingdao 266000, China;
3. Joint Operations College, National Defense University, Shijiazhuang 050000, China
