

2. 西北工业大学 航天学院, 陕西 西安 710072;
3. Signals, Images, and Intelligent Systems Laboratory(LISSI/EA 3956), University Paris-Est Creteil, Senart-FB Institute of Technology, 36-37 rue Charpak, 77127 Lieusaint, France
听觉感知是人类感知系统的一个重要组成部分,帮助我们察觉视觉盲区的重要信息,精确感知周围环境。现有的基于特征提取的环境声音信号处理技术已经被广泛应用于机器人导航、音频检索等领域。目前绝大多数先进的环境声音分类识别(environment sound classification and recognition, ESCR)系统采用基于梅尔滤波器提取的声音特征进行训练来对声音样本进行分类,其中最常见的是梅尔频率倒谱系数(MFCC)特征以及对数梅尔频谱图(Log-mel spectrum)特征。但是环境声音具有非线性和非结构化的特点,且普遍具有复杂的强背景噪声,所以上述2种常用特征是否适合环境声音的分类还需要进一步的研究。此外,一些研究结果表明,GFCC特征对噪声具有较高鲁棒性,使用该特征能够提高语音信号在噪声中的分类精度。因此,本文选取Log-mel特征,MFCC特征与Gammatone频率倒谱系数(GFCC)特征来分析不同特征对ESCR系统的影响。再次基础上,提出一种MFCC和GFCC的融合特征来提升ESCR系统的性能。
ESCR系统面临的最大挑战之一是如何在真实声学环境中具有良好的性能。因此,噪声灵敏度被看作是是良好特征提取技术的一个重要参数。尽管MFCC在多种声音识别任务中表现出极佳的分类识别性能,但是它的一个主要缺点,即它对噪声很敏感,使其在处理具有复杂背景噪声的环境声音时很难达到期望值。所以应当考虑选取一种对噪声具有较好鲁棒性的听觉特征来分析环境声音信号,即GFCC特征[1]。GFCC是基于等效矩形带宽(ERB)尺度和一组Gammatone滤波器组的更全面模型,旨在模拟人类听觉系统对声音信号的处理过程。MFCC和GFCC之间的主要区别在于其滤波器组。MFCC使用的是线性的梅尔尺度滤波器组,GFCC使用的是非线性的Gammatone滤波器组。该滤波器组的特点是具有类似于人类听觉滤波器幅度特性的高脉冲响应。这2种特征均可用于表示短期声音的频谱,并作为模仿人耳听觉特征的声音特征,被广泛应用于处理与人类语音相关的音频信号[2]。然而,在这些研究工作中,所分析的音频信号是语音信号或人类咳嗽的声音,不仅声音事件是线性的信号,而且背景噪声通常较弱。而在处理环境声音时,目标声音事件是非线性的信号,并且与其他被视为背景噪声的非线性环境声音一起出现,这增加了对目标环境声音事件进行分类的难度。因此需要进一步研究这2种特征在分析环境声音信号时的能力。
随着声音信号处理领域中,以深度神经网络为代表的智能算法的不断发展,其对声音信号分类的精度已被证明优于使用GMM、HMM以及SVM等传统方法的系统[3]。因此,近几年所提出的绝大多数声音分析系统都采用深度神经网络来实现目标。目前,绝大多数深度神经网络分析声音信号的第一步是选择适当的音频特征,进而使用这些特征来训练神经网络。只有少量的研究工作直接使用音频信号来训练模型,其结果表明,直接使用音频信号并没有提高分类识别精度。所以,使用听觉特征,并确定哪种特征更适合用于分析环境声音信号是十分重要的一项工作。文献[4]分析并比较了MFCC、GFCC和基于主成分分析(PCA)的MFCC-GFCC融合特征在嘈杂条件下识别说话人的性能。实验结果表明,GFCC在大多数信噪比下的识别精度优于MFCC,而采用两者的融合特征获得的识别精度最高。文献[3]分析了MFCC特征、MFCC的融合特征、频谱图特征以及其他特征在基于DNN、RNN、RDNN、CNN和RCNN的听觉场景识别中的性能。通过对比分析发现,前2个特征比频谱图特征更适合于基于CNN的环境声音识别任务。文献[5]分析对比了双通道MFCC,MFCC与其他特征的融合特征以及对数梅尔特征(Log-Mel),在基于DNN、RNN、CNN和组合神经网络(结合DNN、RNN和CNN的深度神经网络)的ESCR系统中对环境声音的分类能力。实验结果表明,采用MFCC特征与CNN组合的ESCR系统对环境声音的分类准确性最高。
然而,上述研究工作主要着眼与分析以梅尔滤波器为基础的不同特征和不同神经网络的组合对ESCR系统性能的影响,以及MFCC、GFCC 2种特征在分析语音信号时的性能对比,而没有考虑对比基于深度学习的环境声音识别性能,如GFCC对ESCR系统的性能有何影响。此外,文献[4]将MFCC与GFCC特征进行了融合,然而该方法采用PCA对融合后的特征进行了降维,这必然会导致信息丢失。因此,本文提出一种MFCC与GFCC的融合来解决这一问题。与此同时,由于采用深度学习方法进行目标分类时,训练数据的质量对提高分类精度来说较为关键,为此本文选择Urbansound 8K[6]数据库对环境声音分类模型进行训练。Urbansound 8K数据库被广泛应用于基于神经网络的环境声音分类系统,它包含10种共8 732个时长小于等于4 s的真实环境声音文件,总时长约为9.7 h。此外,建立了由多个隐含层组成的深度卷积神经网络(DCNN)模型,通过对输入的音频特征进行卷积、池化等操作处理,分析特征与音频信号间的映射关系,从而实现对环境声音进行分类。最后,分别提取UrbanSound8K数据库中每一个声音片段的Log-Mel特征、MFCC特征、GFCC特征以及MFCC与GFCC的融合特征MGCC,并用建立的DCNN对其分别进行训练。结果表明,4种特征中,采用MFCC特征得到的分类精度最高。在与同类方法的对比中,本文提出的基于MGCC和CNN的ESCR系统在Urbansound 8K数据集上的分类精度最好。
1 方法 1.1 特征提取本文选取的3种听觉特征可以被分为2类:①包含MFCC和GFCC的信号处理类特征;②频谱图类特征,即Log-Mel特征。
MFCC特征:MFCC的生成过程包括:①数据预处理;②对信号进行快速傅里叶变换得到频谱图;③通过中心频率分布在梅尔尺度上的重叠的三角形窗口将频谱图映射到梅尔频谱图;④对得到的梅尔频谱图进行对数运算以获得梅尔对数功率频谱图;⑤随后对该对数功率频谱图进行离散余弦变换后就可得到MFCC特征:
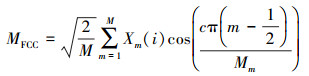
|
(1) |
式中:M是三角滤波器的个数;Xm是第m个对数梅尔频谱图的对数能量;c是倒谱系数的索引。
Log-Mel(LM)特征:我们使用提取MFCC特征相同的参数来提取LM特征。LM特征就是在提取MFCC过程中, 第四个步骤完成后获得的梅尔对数功率频谱图。
GFCC特征:GFCC与MFCC的不同之处主要体现在MFCC基于梅尔尺度而GFCC基于ERB尺度。GFCC的过程细节如下所示:①数据预处理;②对信号进行快速傅里叶变换;③声音信号输入n通道的Gammatone滤波器组, 其定义如下所示
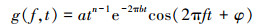
|
(2) |
式中:f是频率;a是常数;φ是相位;n是滤波器的阶数。公式(1)中的因子b是滤波器带宽, 其计算方法如下
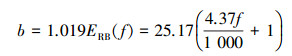
|
(3) |
式中
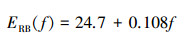
|
(4) |
ERB为等效矩形带宽;④根据公式(2)校正每个通道的滤波器响应并取绝对值以得到声音的时频图;⑤取该时频图进行离散余弦变换即可得到GFCC
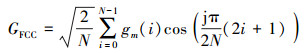
|
(5) |
式中:N是Gammatone滤波器的个数;gm为第m个耳蜗谱图(cochleagram);c是倒谱系数的索引。
1.2 MGCC特征文献[7]对大量听觉特征和声音分类系统进行分析对比后认为, 融合特征比单一特征更适合于环境声音分类系统。这是因为环境声音不同于语音信号或音乐信号, 它具有非线性以及声源众多等特点, 使得单一特征无法完全表征环境声音信号。因此, 本文提出一种基于归一化的MFCC和GFCC的融合特征。
数据归一化(normalization), 也称为标准化, 是数据挖掘的一项基础工作。考虑到MFCC与GFCC表征的声音特征有所不同, 若将二者结合, 可以综合2种特征包含的不同听觉信息, 以提高分类精度。由于MFCC和GFCC是基于不同尺度的滤波器提取而来的特征, 具有不同的量纲。如果单纯对2种特征进行线性叠加或组合反而会导致分类精度降低[8]。为了消除尺度不同而产生的量纲影响, 采用(6)式对MFCC和GFCC进行归一化处理
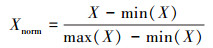
|
(6) |
将得到的2种归一化特征进行线性叠加即可得到本文提出的MGCC特征

|
(7) |
经过线性叠加的MGCC特征可以看做对单一特征的增强。叠加厚的特征既包含了经由梅尔滤波器提取的声音信息, 又包含了Gammatone滤波器提取的声音信息。通过增加特征包含的信息量, 可以有效提高声音事件分类结果(详细说明见第3节)。
1.3 数据库训练基于深度学习的ESCR系统以实现分类环境声音任务的主要障碍是计算资源的巨大需求和样本足够丰富的数据库。第一个问题可以通过升级计算机硬件得到解决, 尤其是升级GPU并将多个GPU并联使用可以基本满足计算要求。但是第二个问题无法在短时间内得到解决。与大量成熟的图像数据库相比, 环境声音的可用数据集的数量和大小仍然有限, 目前较为常用的2个环境声音数据库是UrbanSound 8K数据集以及ESC-50数据集。这2个数据库的建立已经在相当程度上解决了ESCR所面临的第二个问题。ESC-50数据集包含2 000个短时环境声音片段, 主要由50种声音构成并分为5组(动物、自然声音和水声, 人类非语音声音, 内部/家庭声音和外部/城市噪声)。Urbansound 8K数据库包含8 732个在城市中收集的短时(4 s)环境声音, 共分为10个类别, 包括:空调、汽车喇叭、儿童游戏、狗叫声、钻孔、发动机空转、枪击、手提钻、警报器和街头音乐。这些声音被打乱分配进10个文件夹中, 总计时长9.7 h。考虑到本文的目的主要是为了验证3种特征中哪种特征更适合用于环境声音的分类识别, 而不是对比哪种神经网络结构更适合于ESCR系统。因此, 本文只选择Urbansound 8K来训练用以对比特征性能的ESCR系统。
1.4 卷积神经网络本质上, 卷积神经网络(CNN)是研究人员受到生物学启发后改良多层感知器模型得到的一种神经网络架构。与其他深度学习结构相比, 卷积神经网络所需的参数要少, 但是却可以在图像和语音识别任务中获得更好的结果。标准的CNN由一系列不同的层组成深层架构, 其中主要包括:输入层、一系列卷积层、池化层和全连接层。
为了使得输入数据中的局部结构也能够得到利用, CNN中的卷积层使用一种特别的方法组织隐藏单元:这些隐藏单元不需要连接到前一层的整个输出, 仅需要连接到被称为接受域的每个小区域。同时, 使用这些隐藏单元的权重创建卷积内核, 将其应用于整个输入空间以生成特征映射。卷积操作的目的是提取输入的不同特征, 第一卷积层可以仅提取一些低级特征, 并且网络的卷积层越多, 越能够通过从低级特征中提取出更复杂的特征。这样的操作使得神经网络可以看到局部信息而不是一个像素点, 同时加深了神经网络对输入的理解。
在深度神经网络的训练过程中, 随着网络的加深, 非线性变换函数的输入值的整体分布会逐渐靠近非线性函数取值区间上下限, 从而导致梯度消失。所以在将卷积层的输出做非线性变换之前, 我们使用batch normalization(BN)避免梯度消失问题的产生。其作用是将非线性变换函数的输入值(卷积层的输出值)的分布引入均值为0方差为1的标准正态分布区间内, 使梯度变大, 以此来避免梯度消失的问题。
在卷积层后需要激励层对卷积层的输出做非线性映射。近几年的研究工作中, 常选用修正线性单元[9](rectified linear units, ReLUs)函数作为CNN的非线性激活函数, 函数描述如下所示
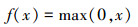
|
(8) |
相比于以往常用的激活函数(logistic sigmoid函数以及双曲正切函数)来说, ReLUs具有以下几个优点:①更快的计算速度; ②更有效的梯度传播; ③ReLUs实现稀疏后的模型能够更好地挖掘相关特征, 拟合训练数据; ④ReLUs不存在梯度消失问题, 使得模型的收敛速度维持在一个稳定状态等几个优点。
池化[10]是卷积神经网络中的另一个重要概念, 它的作用类似于滤波器, 能够过滤出池化层中的有用信息同时分析下一层的信息。池化层的使用还有效减少了神经网络的计算需求。
为了解决可能发生过拟合, 本文在每一次池化层后使用dropout来阻止该问题的出现。dropout使得一个神经元与随机挑选的其他神经元共同工作, 以减弱神经元节点间的联合适应性, 同时增强其泛化能力。具体来说, 就是在训练的迭代过程中, 每个神经元以预设的概率(一般为50%)随机移除, 学习过程照常进行。这样可以有效地防止深度神经网络学习虚假特征并能增加神经元的利用率, 同时确保了每个神经元学习到的特征更有利于深度模型得到正确的分类结果。
最后一层卷积层的输出经过池化后得到的输出将输入给作为分类器的全连接层, 用于对数据进行分类。
本文提出了一个6层CNN模型,将参数控制在较小的范围, 网络结构如图 1所示。该网络共19层, 其中17层是隐含层, 其中包括6个卷积层、6个ReLUs层、3个最大池化层和2个作为分类器的全连接层。6个卷积层可以分为3组, 每组均使用3×3的接受域以及步长为1×1的卷积操作。所有的卷积层都应用了BN以及ReLUs激活函数。第一组由第一和第二卷积层组成, 每层使用32个内核, 在第二卷积层后应用步长为2×2的最大池化层, 并应用dropout来减少过拟合。其他2组基本上与第一组相同, 不同之处在于第二组和第三组提高了卷积核的数量来提取更高级的信息, 2组卷积层的内核数分别为64和128。最后一个卷积层输出的数据通过最大池化和dropout操作后, 输入到2个全连接层构成的分类器中。这2个全连接层均由1 024个神经元组成。输出层为10个神经元组成, 分别代表UrbanSound8K数据库中的10个类别。

|
| 图 1 深度卷积神经网络结构 |
对于UrbanSound8K数据集中的每一个声音样本, 我们使用文献[11]中的方法对其进行如下处理:
1) 首先将声音样本降频到22 050 Hz并归一化;
2) 用帧长为512(约23 ms), 帧移为256的窗口将声音样本分成多个片段;
3) 对每一个声音片段分别提取3种(见1.1节)听觉特征。为了保持维度一致, 我们采用120通道的梅尔频率来产生LM特征。对于MFCC和GFCC, 我们选取其前40维, 加上其一阶差分和二阶差分, 最终得到120维的MFCC和GFCC特征。根据公式(7), 使用得到的120维MFCC和GFCC来产生维度同样为120的MGCC特征;
4) 删除空白片段并打乱数据集。根据文献[11]中的实验结论, 对处理后的数据集不使用数据增强。
当训练完成, 用测试集对模型进行测试时, 一个声音样本的分类结果就是该样本每个片段的似然性总和。
我们首先对选取不同通道数的GFCC特征进行10-fold交叉验证, 来分析选取多少通道的GFCC特征适合用于分析环境声音, 对比结果如表 1所示。
| 序号 | 类 | GFCC20 | GFCC30 | GFCC40 |
| 1 | 空调 | 90.3 | 93.9 | 92.7 |
| 2 | 汽车鸣笛 | 62.1 | 72.7 | 82.1 |
| 3 | 儿童玩乐 | 51.1 | 67.1 | 73.0 |
| 4 | 狗叫声 | 63.1 | 73.2 | 68.6 |
| 5 | 钻孔 | 72.8 | 74.7 | 83.2 |
| 6 | 发动机空转 | 78.7 | 91.5 | 93.7 |
| 7 | 枪击 | 24.6 | 48.9 | 52.1 |
| 8 | 手持式凿岩机 | 84.2 | 93.2 | 91.0 |
| 9 | 警笛 | 80.3 | 86.4 | 83.9 |
| 10 | 街头音乐 | 58.2 | 72.5 | 68.7 |
| 平均分类精度 | 65.6 | 77.4 | 78.9 | |
从中可以看出, 儿童玩乐、狗叫、枪击和街头音乐是对使用GFCC特征的CNN来说, 分类难度较高的环境声音。3类GFCC特征对这4类声音的分类精度均未达到80%。总的来看, GFCC30比GFCC20的分类精度高出11.8%, GFCC40的分类效果最好, 比GFCC30的分类精度高出1.5%, 达到了78.9%。此外, 虽然GFCC30在某些声音的分类上取得了高于GFCC40的表现, 但是GFCC40的总体表现优于GFCC30。因此, 我们选取40通道的GFCC与MFCC融合来获取MGCC特征, 并将其与其他3种特征进行对比。
我们用10-fold交叉验证基于CNN的ESCR系统。其中, 训练100个循环, 每个循环被定义为训练集中的所有数据被模型学习1次。当训练完成后, 计算测试集总的分类精度以及文件夹中每一类的分类精度。模型的学习率(learning rate)设定为0.001, dropout为0.5。深度模型在Tensorflow上建立, 在配备有Xeon-5处理器和2个GTX 1080 GPU的工作站上运行。对比结果如表 2所示。
| 序号 | 类 | LM | MFCC | GFCC | MGCC |
| 1 | 空调 | 87.4 | 91.7 | 92.7 | 96.7 |
| 2 | 汽车鸣笛 | 75.0 | 62.7 | 82.1 | 86.5 |
| 3 | 儿童玩乐 | 81.5 | 80.8 | 73.0 | 89.9 |
| 4 | 狗叫声 | 60.5 | 78.2 | 68.6 | 80.2 |
| 5 | 钻孔 | 70.8 | 87.7 | 83.2 | 93.0 |
| 6 | 发动机空转 | 91.8 | 93.6 | 93.7 | 94.6 |
| 7 | 枪击 | 28.6 | 72.4 | 52.1 | 57.1 |
| 8 | 凿岩机 | 73.1 | 87.0 | 91.0 | 98.1 |
| 9 | 警笛 | 93.2 | 84.8 | 83.9 | 93.1 |
| 10 | 街头音乐 | 72.5 | 89.9 | 68.7 | 87.4 |
| 平均分类精度 | 73.4 | 82.9 | 78.9 | 87.7 | |
表 2展示了3种特征与本文提出的深度卷积神经网络在Urbansound 8K数据集上得到的分类结果。其中, LM-CNN、MFCC-CNN、GFCC-CNN和MGCC-CNN分别表示采用Log-Mel特征、MFCC特征、GFCC40特征以及MGCC特征的基于CNN的ESCR系统。
2.2 实验结果从表 2中可以看出, 前4种特征都分别有比其他特征分类精度高的声音种类。基于深度卷积神经网络的ESCR系统采用MGCC来表征声音信号进行训练得到了最高的分类精度, 达到了87.7%, 分别比Log-Mel、MFCC和GFCC高了14.3%、4.8%以及8.8%。MGCC特征只有枪击声的分类精度低于MFCC特征, 其余9类的分类精度都高于另外3种听觉特征。采用Log-Mel特征的ESCR系统分类精度最低, 只有73.4%。尽管在儿童玩乐和警笛这2类声音的分类上, Log-Mel特征的分类精度要高于MFCC和GFCC, 但是其余8类声音的分类精度都低于其他2种特征。MFCC仅在汽车鸣笛声的分类精度上低于其余2种特征, 仅为62.7%, 对剩余9种声音的分类均优于其他2种特征。此外, MFCC在对GFCC比较有挑战性的4种声音的分类上均取得了较好的结果。其中, MFCC对枪击声的分类精度达到了72.4%, 而Log-Mel和GFCC对枪击声的分类精度表明, 这2种特征基本无法识别该类声音。
图 2展示了在Urbansound 8K数据集上评估4种特征的混淆矩阵。

|
| 图 2 ESCR系统在Urbansound 8K数据集上评估4种特征的混淆矩阵 |
从中可以看出, GFCC和MFCC特征的分类能力优于Log-Mel特征。进一步展示了相较于频谱图特征(Log-Mel), 信号处理特征(MFCC和GFCC)更适合基于深度神经网络的ESCR系统。而融合2种信号处理特征的MGCC特征在环境声音分类任务中的性能最佳。
图 3展示了10-fold交叉验证后得到的Log-Mel、MFCC、GFCC和本文提出的MGCC特征在ESCR系统中的分类精度。

|
| 图 3 3种特征与基于CNN的ESCR系统中的分类精度对比 |
最后, 我们用本文提出的MGCC-CNN环境声音与现有环境声音分类模型进行了对比。结果如表 3所示。需要指出的是, 由于本文并未对数据集做任何处理, 因此第二个模型的分类精度是在未经过数据增强和数据混合的Urbansound 8K数据集上得到的分类精度。可以看出, 在这几种模型中, 本文提出的MGCC-CNN环境声音分类识别系统的分类精度为87.7%, 比文献[11-12]的精度分别高了15%、12%及5.8%。这些结果表明, 在环境声音分类任务中, 相较于使用传统特征的模型来说, 本文提出的MGCC特征和6层CNN组成的ESCR系统具有更好的鲁棒性并在分类精度上取得了显著提升。
本文的主要目的是研究基于深度神经网络的环境声音分类系统。为此,我们设计了一个深度卷积神经网络,并选取了Log Mel、MFCC和GFCC 3种听觉特征,在UrbanSound8K数据集上进行了对比验证。由于使用GFCC特征的环境声音分类的研究工作并不多见,因此,本文首先分析了选取多少通道数的GFCC特征更适合于环境声音的分类。在确定40通道GFCC特征效果更好后,我们通过10-fold交叉验证分析对比了Log-Mel特征、MFCC特征、GFCC特征以及本文提出的MGCC特征在本文设计的ESCR系统中的平均分类精度。实验结果表明,在这3种特征中,基于MFCC和GFCC融合的MGCC特征更适合基于深度卷积神经网络的ESCR系统。最后,在Urbansound 8K数据集上对比了本文提出的基于MGCC-CNN的环境声音分类识别系统和现有的环境声音分类识别系统的分类精度。结果表明,本文提出的基于融合特征和CNN的ESCR系统分类精度最高。
| [1] | ADIGA A, MAGIMAI M, SEELAMANTULA C S. Gammatone wavelet Cepstral Coefficients for Robust Speech Recognition[C]//2013 IEEE International Conference of IEEE Region 10, 2013: 1-4 |
| [2] | ALI H, TRAN S N, BENETOS E, et al. Speaker Recognition with Hybrid Features from a Deep Belief Network[J]. Neural Computing and Applications, 2018, 29(6): 13-19. DOI:10.1007/s00521-016-2501-7 |
| [3] | DAI W. Acoustic Scene Recognition with Deep Learning[M]. Pittsburg: Carnegie Mellon, 2016. |
| [4] | BURGOS W. Gammatone and MFCC Features in Speaker Recognition[D]. Melbourne, Florida: Florida Institute of Technology, 2014 |
| [5] | LI J, DAI W, METZE F, et al. A Comparison of Deep Learning Methods for Environmental Sound Detection[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing, 2017: 126-130 |
| [6] | SALAMON J, JACOBY C, BELLO J P. A Dataset and Taxonomy for Urban Sound Research[C]//ACM Press, 2014: 1041-1044 |
| [7] | CHACHADA S, KUO C-C J. Environmental Sound Recognition:a Survey[J]. APSIPA Transactions on Signal and Information Processing, 2014(3): e14. |
| [8] | AGRAWAL D M, SAILOR H B, SONI M H, et al. Novel TEO-Based Gammatone Features for Environmental Sound Classification[C]//2017 25th European Signal Processing Conference, Kos, Greece, 2017: 1809-1813 |
| [9] | NAIR V, HINTON G E. Rectified Linear Units Improve Restricted Boltzmann Machines[C]//Proceedings of the 27th International Conference on Machine Learning, 2010: 807-814 |
| [10] | BOUREAU Y L, PONCE J, LECUN Y. A Theoretical Analysis of Feature Pooling in Visual Recognition[C]//Proceedings of the 27th International Conference on Machine Learning, 2010: 111-118 |
| [11] | PICZAK K J. Environmental Sound Classification with Convolutional Neural Networks[C]//2015 IEEE 25th International Workshop on Machine Learning for Signal Processing, 2015: 1-6 |
| [12] | ZHANG X, ZOU Y, SHI W. Dilated Convolution Neural Network with Leaky ReLU for Environmental Sound Classification[C]//22nd International Conference on Digital Signal Processing, 2017: 1-5 |
2. School of Astronautics, Northwestern Polytecnical University, Xi'an 710072, China;
3. Signals, Images, and Intelligent Systems Laboratory(LISSI/EA 3956), University Paris-Est Creteil, Senart-FB Institute of Technology, 36-37 rue Charpak, 77127 Lieusaint, France
