

2. 中国科学院计算技术研究所, 北京 100190
零样本学习[1]把语义属性、语义词向量和文本描述作为已知类别和未知类别间的迁移指示,以减少对类别标签的依赖,提高分类模型的泛化能力,已成为机器学习领域中研究热点之一。文献[2]利用属性建立直接属性预测模型(direct attribute prediction, DAP)和间接属性预测模型(indirect attribute prediction, IAP)。为解决DAP和IAP模型的领域偏移问题,文献[3]引入了属性稀疏表示方法(RKT)。但RKT需要假设属性数据库的标注信息完全正确。文献[4]利用属性低秩表示进行改进,使其更适用于实际应用。针对训练数据与测试数据间的差异性,文献[5]提出自适应样例属性算法,同时引入了区分性样例属性算法。文献[6]从属性和类别的关系、相对属性的关联性和多任务学习的策略等方面进行优化。针对具有类似属性的类别不容易被区分的问题,文献[7]把编码的底层特征作为辅助语义属性,从而识别相似属性的未知类别。属性具有良好的解释性,但大规模数据的标注具有困难。因此文献[8]提出把无监督学习的语义向量作为迁移知识。视觉空间到语义知识空间的映射容易出现领域漂移,因此文献[9]提出基于双视觉-语义映射路径的零样本分类方法,利用语义空间流形的内在联系对视觉-语义的映射路径进行优化。同时文献[10]提出基于语义自编码的零样本分类模型,解决了领域漂移问题。针对Hubness问题,文献[11]提出将图像特征空间作为公共的映射空间,同时结合卷积神经网络和循环神经网络,构建了端到端的深度零样本学习模型。
以上方法均针对属性学习和视觉到语义间映射函数方面进行优化,以提高属性分类器的精度。但很少考虑单一辅助知识对目标类别描述的局限性。本文利用粒子群优化算法学习用于零样本图像的融合特征权重,以提高语义空间的差异性,增强辅助知识的鲁棒性。
1 系统模型定义自适应加权融合特征的零样本图像分类的框架如图 1所示。首先随机初始化特征融合的权重w1和w2, 利用神经网络对类别标签的语义属性特征和语义文本特征进行融合; 然后, 经过一层全连接网络映射到图像的视觉空间; 最后, 利用粒子群算法初始的特征权重w1和w2进行优化。将测试样本的语义属性和语义词向量映射到图像视觉空间, 采用欧式距离度量图像的视觉特征和映射后的语义特征间的相似度。

|
| 图 1 自适应加权融合特征的零样本图像分类模型示意图 |
零样本图像分类模型可定义为:假设含N个训练样本的数据集Dtr(Ii, siu, tiu), 其中tiu ∈Ttr是第i个训练图片的第u个训练类标签, Ii是第i个训练图片, siu ∈RL×1表示对应图片的L维语义特征向量。零样本学习的目的是给定测试图片Ij, 能够估计其类别标签tjv ∈Tte, 其中tjv是第j个图片的第v个测试类标签, 需满足Ttr∩Tte=Ø, 即训练类(已知类)和测试类(未知类)无交集。作为语义类原型, 每个类标签tu和tv应与对应的语义空间表示su和sv保持一致。
2 自适应加权融合特征的零样本图像分类 2.1 语义融合特征的构建假设融合模型的输入是语义属性特征A=(a1, a2, …, ap), p表示属性向量的维数, W=(b1, b2, …, bq)表示输入的语义词向量特征。结合浅层神经网络可以分为输入层融合、全连接层融合和得分融合。
图 2给出了前特征融合方法, 即输入层的特征融合。首先分别对输入的语义属性特征A和语义词向量特征W进行归一化, 然后将2个特征按照维度的方向进行拼接, 可以表示为

|
(1) |

|
| 图 2 前特征融合模型 |
式中, F每行的特征维度是p+q, “+”表示特征串联。假设全连接层FC1和FC2的初始化权重分别为w1(1)和w1(2), 此时得到的模型输出为
|
(2) |
式中, f2(·)表示激活函数Relu。假设期望的输出是V, 那么融合模型的目标函数可以定义为

|
(3) |
与BP神经网络一样, 根据链式法则求解目标函数的偏导, 则有
|
(4) |
最后根据梯度下降算法更新权重值。
图 3给出了后特征融合方法, 即利用最后一个全连接层进行融合。与前特征融合不同, 利用神经网络进行后特征融合时, 不需要对A和W进行归一化。第一层的神经网络不共享, 经过共享的全连接层FC3得到输出, 此时的损失函数可以表示为

|
(5) |

|
| 图 3 后特征融合模型图 |
式中, W1(1), W2(1)和W3(2)分别表示全连接层FC1, FC2和FC3的初始化权重, “+”表示对应元素求和。模型参数的更新法则同前特征融合。
图 4给出了得分融合特征的方法。输入A和W分别经过2层非共享的全连接层, 得到了2个损失函数, 然后对其进行融合, 所以得分融合模型的损失函数表示为

|
(6) |

|
| 图 4 得分融合模型 |
式中, W1(1), W2(1), W1(2)和W2(2)分别表示全连接层FC1, FC3, FC2和FC4。在实际的融合模型训练时, 为了避免模型出现过拟合, 在损失函数中需要增添对每层权重参数的L2正则项。
2.2 PSO自适应权重学习改进的特征融合算法后特征融合的零样本图像分类模型的融合权重缺乏普适性, 因此引入粒子群优化算法确定分类模型的融合权重。首先随机初始化特征融合的权重w1和w2, 以后特征融合为例, 融合模型的输出为
|
(7) |
此时, 模型的目标函数可以定义为
|
(8) |
式中, ϕ(Ii)表示对图像Ii提取的图像特征, N表示样本数量。利用梯度下降法不断地更新权重参数, 当模型的损失函数收敛至稳定值, 停止融合模型的训练, 然后利用PSO算法学习特征融合权重。
假设群里由m个粒子组成, 每个粒子的位置对应问题的解。因为要对w1和w2的最优值进行学习, 那么每个粒子要在二维搜索空间中以特定的速度更新位置。每次更新时, 所有群体的最优位置gbest和个体的历史最优位置pbest也需要不断更新。pbest表示个体在所经历位置中适应度值最优的位置, gbest表示种群中全部粒子学习到的适应度值最优的位置。
考虑自己历史搜索的最好位置和群体内其他粒子的最优位置。对粒子群中的每个粒子分别使用xi(xi1, xi2), pi=(pi1, pi2)和vi=(vi1, vi2)表示第i个粒子的目前位置、历史最优位置以及更新速度, 其中i=1, 2, …, m, 令pi1=w1和pi2=w2。算法在每次迭代时, 当前位置xi作为新的特征权重, 设计适应函数对模型进行评估。在该模型中以分类的准确率作为PSO的适应度函数。假如当前位置的适应度值比历史最优位置pi=(pi1, pi2)的高, 就将第i个粒子的历史最优的位置替换成当前位置。最后可以得到整个粒子群适应度值的最优位置pg=(pg1, pg2), 即可得到优化后的权重(w′1, w′2)。设置最大迭代次数, 当算法迭代至最大值时, 停止位置更新。
针对第i个粒子的速度和位置, 第d维的更新规则如下所示
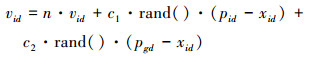
|
(9) |
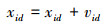
|
(10) |
式中, n是指惯性权重, 确定粒子之前速度对目前速度的影响程度, 以权衡算法的局部搜索和全局搜索能力。c1和c2表示学习因子, 使粒子具有向群体内最优个体学习和自我总结的能力。与惯性权重相似, 学习因子也可以起到全局搜索和局部搜索的平衡作用, 与惯性权重相反, 学习因子越大, 算法越容易收敛。通常c1和c2是2个非负值, 一般的, 取c1=c2=2。rand()是指在[0, 1]范围间取值的随机函数。因而PSO加权学习的特征融合算法流程如下:
1) 初始化
在二维权重的解空间中随机产生粒子的位置和速度, 且设置粒子当前最优位置为w1和w2。
2) 设计适应度函数
假设输入总样本个数N, 其中有n个样本被分类正确, 那么适应度函数定义为

|
(11) |
3) 更新最优位置
(1) 计算粒子的适用度函数值, 若高于当前个体的最优值pbest, 将当前的粒子位置作为该个体新的pbest位置。
(2) 比较粒子的适用度函数值和群体全体最优位置gbest, 假如当前粒子的位置优于gbest, 将当前粒子位置设置为gbest位置。
4) 更新粒子
利用(9)式和(10)式更新粒子的速度及位置。
5) 停止条件
如果不满足终止条件, 循环执行第2)至3)的步骤, 否则当循环至最大迭代次数时终止更新。
在零样本图像分类推断阶段的语义联合嵌入空间中, 利用欧式距离计算测试样本与所有语义特征的相似度, 再为测试样本分配与之距离最近的类别标签。结合学习的特征融合的权重w′1和w′2, 自适应加权融合特征的零样本学习可以表示为
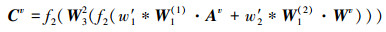
|
(12) |
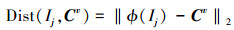
|
(13) |
式中, ϕ(Ij)表示在语义联合嵌入空间中第j个测试样本的图像视觉特征, Av和Wv分别表示第v个类别标签的语义属性向量和语义词向量特征, Cv表示融合后的特征。对测试样本的分类可以表示为

|
(14) |
当测试样本Ij和Cv取最小距离时的v即为测试样本Ij的类别标签。
3 实验结果及分析 3.1 实验数据集及设置为了验证基于自适应加权融合的零样本图像算法的有效性, 同时, 为了与基于融合特征的零样本图像分类算法进行对比, 本文的实验数据集选择动物属性数据集(animals with attributes, AWA)[11]。数据集AWA包括50个类别, 总计30 475张图像。对于每个类别, 数据集提供了85维的属性特征, 选择40个类别作为训练类别, 10个类别作为测试样本。采用Googlenet模型提取输入图像的特征。此外, 利用Word2vec在维基百科语料库中训练skip-gram模型, 提取对应每个类别标签1 000维的语义词向量。
在自适应加权融合的零样本图像分类算法中, PSO算法中初始化种群数量N和最大迭代次数分别设置为20, 同时PSO算法中惯性权重n、学习因子c1和c2通过交叉验证来确定, 最后设置n=0.5, c1=c2=11。
3.2 融合特征的零样本图像分类实验为了验证特征融合方法的有效性, 分别把前特征融合、后特征融合和得分融合的特征用于零样本图像分类。表 1给出了利用不同方法构建的融合特征在零样本图像分类中的识别准确率, 可以得出:利用后特征融合模型的准确率最高, 与前特征融合和得分融合相比, 分别提高了4%和13%。
图 5给出了得分融合和后特征融合的零样本图像分类的准确率与迭代次数变化的关系。在准确率上升的阶段, 当迭代次数相同时, 后特征融合模型的准确率高于得分特征融合。实验结果表明, 在得分阶段进行融合会降低模型的学习能力, 得分融合模型的损失函数不利于模型的收敛。

|
| 图 5 得分融合和后特征融合模型识别准确率的变化曲线 |
从图 6可以看出, 在5 000次迭代之前, 前特征融合模型收敛的更快, 但是在5 000次之后, 后特征融合模型的准确率高于前特征融合模型。同时, 前特征融合的准确率开始下降, 表明模型出现了过拟合。说明特征融合的数据预处理能够加快模型的收敛, 但是经过神经网络不断的学习, 容易出现过拟合。

|
| 图 6 前特征和后特征融合准确率变化曲线 |
在零样本图像分类中, 后特征融合模型取得了更显著的效果。这是由于在后特征融合中, 第一层的神经网络能够自动学习参数, 减少了特征归一化的干预, 利用第二层神经网络可以共享特征间的信息, 能有效减少多个损失函数的干扰。
由于后特征融合的有效性, 零样本图像分类算法使用了该方法融合语义属性特征和语义词向量特征。表 2给出了后特征融合的零样本图像分类算法(zero-shot learning based on the fusion feature, FF-ZSL)在数据集AWA的识别准确率, 并与传统算法进行对比, 主要包括DeVISE[12], Socher [8]和MTMDL[13]。从表中可以得出, 融合特征比语义属性特征的分类精度高出了约3%, 而比语义词向量特征方法提高了10%。
图 7分别给出了不同辅助知识的分类准确率与训练迭代次数之间的关系曲线。从图 7a)可以得出, 融合特征加快了零样本图像分类模型的收敛效率, 并且语义词向量的零样本图像分类模型的准确率趋于平稳时, 前者的精度仍有上升的趋势。因此, 通过特征的融合可以提高语义知识的区分性, 增强语义知识的丰富性。

|
| 图 7 分类准确率和迭代次数间的关系曲线 |
相较于图 7a)~7b)语义属性作为公共知识时, 准确率出现了波动, 收敛的速度也较慢。可见, 融合特征的方法结合了语义词向量的快速收敛和语义属性的精确描述等优势。
3.3 自适应加权特征融合的零样本图像分类实验后特征融合的零样本图像分类自适应加权融合特征的零样本图像分类算法(zero-shot learning based on adaptive weighted fusion feature, AWFF-ZSL)需要PSO算法自适应学习特征融合的权重。图 8给出了PSO在学习特征融合权重的过程中, 最优个体适应度值随迭代次数变化的曲线。

|
| 图 8 最优个体适应度值和迭代次数关系曲线 |
从图 8中可得出, 随着每代个体位置的更新, 最优个体的适应度值也不断的进化。当迭代至第7代左右, 可获取全局最优的位置。
表 3给出了自适应加权融合特征的零样本图像分类模型的准确率,并与DeVISE[12]、Socher[8]、MTMDL[13]、Jimmy Ba[14]和DEMZSL[11]进行了比较。可以得出,在融合特征的基础上,利用PSO学习的加权融合特征,使模型的准确率提高了1.2%。说明了加权融合的特征比融合特征的语义空间更具差别性。
为避免AWFF-ZSL的随机性,分别对AWFF-ZSL和FF-ZSL算法进行多次实验,最后取平均值作为最终的分类精度。图 9给出的10次随机实验分类准确率表明:自适应加权融合特征AWFF-ZSL算法的准确率要高于融合特征FF-ZSL算法。可见,引入PSO算法自适应优化特征融合权重的方法,有效提高了融合特征的鲁棒性。

|
| 图 9 AWFF-ZSL与FF-ZSL算法准确率稳定性对比 |
本文提出一种粒子群优化融合特征的零样本图像分类算法。该方法首先对语义属性和语义词向量特征进行融合,同时引入粒子群优化方法学习融合特征的权重,提高模型的稳定性。基于AWA数据集测试实验,本文所提AWFF-ZSL算法的分类准确率达到88.9%,相较于FF-ZSL算法提高了1.2%,从而验证了该方法的有效性。同时,多次实验结果对比表明该方法具有较强的鲁棒性。
| [1] | LAROCHELLE H, ERHAN D, BENGIO Y. Zero-Data Learning of New Tasks[C]//23rd AAAI Conference on Artificial Intelligence, 2008: 646-651 |
| [2] | LAMPERT C H, NICKISCH H, HARMELING S. Attribute-Based Classification for Zero-Shot Visual Object Categorization[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 36(3): 453-465. |
| [3] | WANG D, LI Y, LIN Y, et al. Relational Knowledge Transfer for Zero-Shot Learning[C]//Thirtieth AAAI Conference on Artificial Intelligence, 2016: 2145-2151 |
| [4] | YU J, WU S, WANG L, et al. Robust Zero-Shot Learning with Source Attributes Noise[C]//2016 International Conference on Progress in Informatics and Computing, 2016: 205-209 |
| [5] | WANG L, WU S, YU J, et al. Learning Discriminative Instance Attribute for Zero-Shot Classification[C]//2016 International Conference on Progress in Informatics and Computing, 2016: 210-213 |
| [6] | CHENG Y, QIAO X, WANG X, et al. Random Forest Classifier for Zero-Shot Learning Based on Relative Attribute[J]. IEEE Trans on Neural Networks, 2018, 29(5): 1662-1674. DOI:10.1109/TNNLS.2017.2677441 |
| [7] | WANG S, JIANG S, HUANG Q, et al. S3MKL: Scalable Semi-Supervised Multiple Kernel Learning for Image Data Mining[C]//Proceedings of the 18th ACM International Conference on Multimedia, 2010: 163-172 |
| [8] | SOCHER R, GANJOO M, MANNING C D, et al. Zero-Shot Learning Through Cross-Modal Transfer[C]//Advances in Neural Information Processing Systems, 2013: 935-943 |
| [9] | LI Y, WANG D, HU H, et al. Zero-Shot Recognition Using Dual Visual-Semantic Mapping Paths[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3279-3287 |
| [10] | KODIROV E, XIANG T, GONG S. Semantic Autoencoder for Zero-Shot Learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3174-3183 |
| [11] | ZHANG L, XIANG T, GONG S. Learning a Deep Embedding Model for Zero-Shot Learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2021-2030 |
| [12] | FROME A, CORRADO G S, SHLENS J, et al. Devise: a Deep Visual-Semantic Embedding Model[C]//Advances in Neural Information Processing Systems, 2013: 2121-2129 |
| [13] | YANG Y, HOSPEDALES T M. A Unified Perspective on Multi-Domain and Multi-Task Learning[J/OL](2015-03-26)[2019-09-17]. https://arxiv.org/bas/1412.7489,2014 |
| [14] | JIMMY BA Lei, SWERSKY K, FIDLER S. Predicting Deep Zero-Shot Convolutional Neural Networks Using Textual Descriptions[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 4247-4255 |
2. Institute of Computing Technology, Chinese Academy of Science, 100190 China
