

2. 中国科学院大学, 北京 100049;
3. 成都崇信大数据服务有限公司, 四川 成都 611230
随着信息技术的发展, 人们正在以前所未有的速度生产和消费各种各样的数据, 面对海量数据的不断增长, 传统的数据存储和计算模型无法满足需求, 分布式系统得到了长足发展, 其中Apache开源的Hadoop[1]以其高可靠和低成本优势, 迅速成为业内广泛采用的分布式解决方案。
MapReduce模型[2]是Hadoop的核心计算框架, 分为Map和Reduce 2个阶段:Map阶段完成原始数据的并行计算, 产生中间数据; Reduce阶段读取中间数据并计算得到最终结果。其性能取决于数据分布状态[3], 数据分布比较均衡, 性能就比较高, 一旦出现数据倾斜, 性能就会降低, 因此研究MapReduce模型中数据分布状态, 对提升整个分布式计算的性能有很重要的意义。
本文通过构建数据块直方图、存储节点直方图和文件直方图的方式来描述MapReduce模型中的数据分布状态, 判断是否存在数据倾斜, 并利用贪心策略, 通过数据块交换的方法, 在不改变每个存储节点存储量的条件下, 使数据的分布趋于均衡。
1 相关研究 1.1 直方图在统计学领域, 直方图常用于描述数据的分布状态, 一般用横轴表示数据类型或数据范围, 纵轴用一系列高度不等的纵向条纹或线段表示数据的分布情况。直方图描述的数据分布状态可以为分布式并行计算的效率优化奠定基础[4-5], 文献[6]中利用元组抽样方法提出基于MapReduce的小波直方图构建算法, 文献[7]中提出了基于MapReduce的maxdiff直方图的构建方法, 文献[8]中对MapReduce框架进行扩展, 在map( )函数之前和reduce( )函数之后分别增加了数据的采样和统计, 对基于MapReduce的等宽和等深直方图构建算法进行了改进。
上述基于MapReduce的直方图构建算法的核心思想是将文件中的原始数据在Map阶段计算并转换成<key, value>对的形式, 然后通过Hash分区将<key, value>对传输到相应的Reduce节点, 最后在Reduce节点上进行直方图的构建, 这必然会出现Map节点与Reduce节点间数据传输量大的问题。尽管很多改进算法能够降低Map节点与Reduce节点间的数据传输量, 但仍然无法从根本上解决该问题。
1.2 数据均衡MapReduce的计算过程中可能出现2个方面的性能瓶颈:Map阶段并行计算时间受到负载重的Map任务制约; Reduce阶段计算时间受到负载重的Reduce任务制约。文献[9]中分析了原因:Map阶段是由于原始数据分布不均衡, 导致某一个(或某一些)Map任务处理的数据量远多于其他Map任务; Reduce阶段是由于数据内容本身的倾斜和Hadoop默认Hash分区方法不合理, 导致某一个(或某一些)Reduce任务的数据处理量远多于其他Reduce任务。
Map阶段的数据倾斜与数据内容息息相关, 而数据内容是数据自身的属性, 是无法改变的, 因此目前大量的研究集中在Reduce阶段对中间数据的分区方法改进上。例如:文献[10-11]中提出基于元组的采样策略, 文献[12-13]中提出基于数据块的采用策略, 其思路都是先采样后调整分区; 文献[14]中提出了一种增量式分区策略, 通过多轮递增机制实现Reduce端数据平衡。
基于以上研究现状, 本文尝试通过改进的基于MapReduce模型的数据直方图并行构造算法完成对Map阶段的数据倾斜进行度量和判定的工作, 并在此基础上通过数据均衡算法对其存在的数据倾斜问题进行改进和优化。
2 直方图构造算法针对MapReduce模型中直方图数据传输量大的问题, 本文通过计算分组、计算频率和、传输直方图信息等过程实现基于MapReduce的数据直方图的并行构建, 从根本上解决了Map节点与Reduce节点间的数据传输量大的问题。
2.1 相关定义横看成岭侧成峰, 远近高低各不同。我们在看待事物的时候, 如果角度不同, 往往会得到不同的结果。对于数据来说, 具有同样的道理。数据本身是有具有维度的, 同样的数据从不同的维度进行观察往往也会得到不同的结果。在具体的数据应用场景中, 通常是针对某一个(或某几个)具体的数据维度进行数据分析, 不失一般性, 本文假设一个数据文件datafile中含有mass条记录, 存储于分布式系统中, 并据此进行数学定义:
定义1 数据文件datafile中的若干条记录中均包含某一方面的信息, 提取该信息片段, 并将其定义为数据维度D, 设其对应的值域为R, 且其取值可通过计算转化为数值域R*。
例如 在分析Log4j产生的海量日志文件时, 其日志级别主要是FATAL、ERROR、WARN、INFO和DEBUG, 我们可以将该日志文件作为datafile, 在其数据维度D(级别Level)上, 值域R为{FATAL, ERROR, WARN, INFO, DEBUG}, 并可以进一步将其转换成数值域R*为{1, 2, 3, 4, 5}。
定义2 数据文件datafile中的每条记录在值域R(或数值域R*)上都对应着一个值, 设为x, 用f(x)表示datafile中所有记录取值为x的频率值; 另设Gi为该文件的第i个分组, 则可以进一步定义当x∈Gi时, datafile中所有记录在该分组范围内的频率和。

|
(1) |
定义3 以Gi为横坐标轴, 处于该范围内的频率和f(x)为纵坐标轴, 建立数据文件datafile在数据维度D上对应的直方图H, 其数学表达式为:

|
(2) |
式中, N为分组数。
2.2 算法描述Step1 计算分组
直方图横坐标轴的核心是计算文件在数据维度D的对应值域R(或数值域R*)的范围或类型, 并据此进行分组, 所有并行构造直方图的Map节点必须有统一的分组。根据应用条件的不同, 本文提出3种确定直方图横坐标范围或类型的方法:
1) 如果文件在数据维度D的对应值域R(或数值域R*)的范围已知, 可以根据经验快速分组。比如:在分析某文件的时间维度上, 可以得到每天、每周、每月或每年的统计分析结果, 那么其数值域可以相应的设置为1~24, 1~7, 1~31或1~12等。
2) 如果文件在数据维度D的对应值域R(或数值域R*)的范围未知, 且相关数据维度的类型不明确, 可以先在Map节点上采用相同的标准对数据块进行并行聚类, 再根据分类情况在Reduce节点上统计所有的分类。比如:对微博数据中用户关注的领域进行分析时, 可以先在Map节点并行执行领域聚类计算, 再通过Reduce节点合并统计出整个文件所有用户关注的全部领域。
3) 如果文件在数据维度D的对应值域R(或数值域R*)的范围未知, 且数据分布不清楚, 可以在各Map节点通过各自的map task计算每个数据块的最大值和最小值, 然后将所有数据块对应的最大值和最小值传输到一个Reduce节点, 计算出全局最大值和全局最小值, 再据此进行分组。比如:在分析高中在校学生身高数据时, 就可以使用该方法来确定直方图的横坐标轴。
Step2 计算频率和
直方图纵坐标轴的核心是计算每个分组对应的频率和。由于数据文件被划分成若干个数据块分布式存储, 因此在计算频率和的过程中, 本文以数据块为单位进行计算, 可以获得每个数据块在每个横坐标分组范围内的频率和。
Step3 构造数据块直方图
根据直方图横坐标轴的分组信息和纵坐标轴的频率和信息, 可以在Map节点上并行的构造出所有的数据块直方图。
Step4 传输数据块直方图信息
Map节点并行构造出的数据块直方图无法直接传输到Reduce节点上, 须将其转化成<key, value>对的形式, 本文采用 < Gi, f(x) > 的形式传输一个数据块的数据直方图信息。
Step5 构造文件直方图
当所有数据块的直方图信息都传输到一个Reduce节点上, 该Reduce节点将所有数据块对应的<key, value>对中key值相同的进行分组, 并依次将对应的value值进行累加操作, 得到新<key, value>对, 进而构造出整个数据文件的数据直方图。
基于MapReduce的直方图并行构造过程如图 1所示:

|
| 图 1 直方图并行构造过程 |
数据直方图可以描述出在某一数据维度D上, 文件在分布式系统中各个存储节点上的分布情况, 根据该分布情况, 我们可以提取出相关的数学模型。
3.1 相关定义定义4 设数据文件datafile被划分成n个block, 每个block在建立数据直方图时划分成m个组, 则该文件中所有block的数据直方图信息可以使用以下矩阵A来表达:
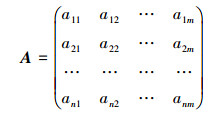
|
(3) |
式中, 该矩阵的第i行表示第i个block对应的数据直方图的信息, 第j列表示数据直方图的第j个分组, 数值aij表示第i个block在其第j个分组组距值范围内的频率和信息。
由于数据文件在划分成block时是采用固定大小划分的, 忽略末尾block差异性, 可以得到以下约束条件:
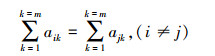
|
(4) |
上述矩阵A及其约束条件可以看作是基于数据块的文件直方图的一种数学表达。
如果将这n个block分布存储于N个存储节点上(n≫N), 在不改变每个存储节点存储容量的条件下, 要想每个分组的频率和都尽量达到均衡分布, 问题就转变成在含有约束条件的矩阵A中将n个行向量, 分成N份, 使得每一份中m个分量上的值(或累加值)趋近于相等, 问题的本质是在不改变数据块内容以及每个节点数据块数量的前提下, 寻找一个数据块均衡分布的全局最优解。
定义5 节点均衡向量Aavg
将n个block均衡的分配到N个节点上, 则每个节点上的节点均衡值可以定义成一个节点均衡向量:
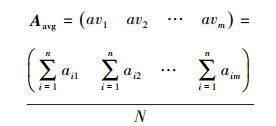
|
(5) |
定义6 组合矩阵Ak
将矩阵A中的任意k个行向量累加组合成一个新的行向量, 构成的新矩阵定义为Ak, 则矩阵Ak中必然有Cnk个行向量。
矩阵Ak中的行向量与均衡向量之间的相似性的度量标准很多, 比如:欧氏距离、曼哈顿距离、马氏距离、夹角余弦等, 考虑到本文提出的数据均衡算法关注的重点在于每个存储节点上相关分量的频率和是否相等, 偏重于数值大小的比较, 因此本文选用欧式距离作为向量间相似度的衡量标准。
设有行向量p=(ai1 ai2 … aim), 则向量p与均衡向量之间的欧式距离:
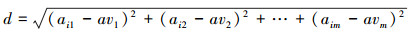
|
(6) |
定义7 文件均衡偏差值df。将所有存储节点中的block所构成的行向量与均衡向量之间的距离累加值定义为文件均衡偏差值。
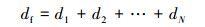
|
(7) |
本文提出的数据均衡算法是在不改变所有节点已经分配block数量的情况下, 通过各个节点间block的调整和交换, 实现数据内容方面的均衡。因此, 确定每个节点存储了多少个block是本算法的前提条件。
例如 表 1是一个被划分成14个block的文件, 该文件被分布到5个节点上, 其每个节点block分布数量信息如表 1所示。
根据block直方图信息和block分布数量信息, 本文提出基于数据直方图的数据均衡算法, 具体过程如下:
Step1 计算节点均衡向量Aavg;
Step2 构造组合矩阵Ak;
设block分布信息表中block数最大值为k, 则需要构造组合矩阵Ak。例如:上表所示的block分布信息中, block数最大值是3, 则需要构造组合矩阵A3, 且A3有C143=364个行向量。
Step3 计算向量距离;
计算矩阵Ak中所有行向量与节点均衡向量之间的距离;
Step4 根据距离大小分配block。
从组合矩阵Ak中选择d值最小的N个互不相关的行向量, 并将组成该行向量的若干个block分配到同一个存储节点上。
算法:
Input: matrix A and block distribution quantity
Output: block distribution information
1.Aavg[group]←A[n][group];
2.while A is not null and n > k
//Take any k rows data from matrix A
//and accumulate into one row into matrix Ak
3.Ak[i][group]←A[n][group];
//Mark the k rows subscript composed of
//Ak[i][group] from matrix A
4.Index[i][k]←1…k;
5.di←|Ak[i][group]-Aavg[group]|;
6.min ←di; //Search minimum value in di
//Find k rows data from matrix A
7.A[Index[i][0]][group]…A[Index[i][k]][group];
//Delete the k rows data from matrix A
8.A[n-k][group]←A[n][group];
9.n=n-k;
10.end while
4 实验验证 4.1 实验设计为了验证算法的正确性和优越性, 利用虚拟机搭建一个由7个节点构成的Hadoop集群进行测试。整个Hadoop集群由2个NameNode节点和5个DataNode节点组成, 其中每个节点均为内存512MB, 硬盘8GB, 操作系统为CentOS 6.5, Hadoop版本为2.6.0, 修改并设置block大小为256 kB, 副本数为1。
Step1 采用构造数据直方图的算法构造整个数据文件的数据直方图。将包含1 223 348个随机数的大小为3.5 MB的数据文件datafile.txt存储到实验中搭建的Hadoop集群中, 设置分组数为5, 构建数据块数据直方图和整个文件数据直方图, 分析数据倾斜状态, 并对比直方图构造算法的数据传输量。
Step2 根据整个文件的数据直方图和每个数据块(block)的数据直方图的相关信息, 采用随机分配和基于数据直方图的数据均衡算法进行分配2种方案, 对比其文件均衡偏差值, 并根据节点数据直方图分析其数据倾斜状态。
4.2 实验结果及分析 4.2.1 直方图分析由于实验集群中block大小被设置为256 kB, 因此实验中的数据文件被划分成14个block, 每个block对应的分组和每组频率和的统计信息如表 2所示:
| block序号 | 0~20 | 21~40 | 41~60 | 61~80 | 81~100 |
| 1 | 17 618 | 17 495 | 17 363 | 17 404 | 17 502 |
| 2 | 8 662 | 17 453 | 26 488 | 21 986 | 12 793 |
| 3 | 2 647 | 26 301 | 38 354 | 9 512 | 10 568 |
| 4 | 13 110 | 21 893 | 26 485 | 21 551 | 4 343 |
| 5 | 4 378 | 12 943 | 8 982 | 17 396 | 43 683 |
| 6 | 14 010 | 13 909 | 24 430 | 24 489 | 10 544 |
| 7 | 10 433 | 13 915 | 24 504 | 31 597 | 6 933 |
| 8 | 10 513 | 26 103 | 21 041 | 27 954 | 1 771 |
| 9 | 7 089 | 17 320 | 33 126 | 19 285 | 10 562 |
| 10 | 13 242 | 21 782 | 17 532 | 24 355 | 10 471 |
| 11 | 11 303 | 23 628 | 13 155 | 20 049 | 19 247 |
| 12 | 13 993 | 14 081 | 29 469 | 19 259 | 10 580 |
| 13 | 24 460 | 19 253 | 15 812 | 26 983 | 874 |
| 14 | 26 117 | 8 524 | 26 319 | 8 789 | 17 633 |
通过表 2可以直接构建出每个block的数据直方图, 如图 2所示:

|
| 图 2 block数据直方图 |
所有block数据直方图的信息在Reduce节点合并统计后, 得到整个文件的数据直方图, 如图 3所示:

|
| 图 3 file数据直方图 |
通过block的数据直方图(见图 2)可以看出:多个block之间的数据分布差异明显; 通过整个文件的数据直方图(见图 3)可以看出:整个文件的数据内容本身分布不均衡, 第3个分组的数据量明显偏多, 第1个分组和第5个分组的数据量明显偏少。
算法数据传输量分析:如果采用传统的直方图构建算法, 需要将3.5 MB的数据在Map端处理成120多万个<key, value>对, 然后传输到Reduce端, 通过<key, value>对合并来完成文件直方图的构建; 而采用本文提出的改进算法只需要传输14个数据块共70个<key, value>对的统计信息, 就可以在Reduce端快速建立整个文件的直方图, 而且还可以同时完成数据块直方图的构建和该文件在某一存储节点上数据直方图的构建。
4.2.2 数据均衡分析将14个block分布到5个存储节点上, 假设block分布情况为:4个三block节点, 1个双block节点, 对比2种block分布算法。
| block | 0~20 | 21~40 | 41~60 | 61~80 | 81~100 |
| number | 3 | 3 | 3 | 3 | 2 |
| distribution | block1 block2 block3 |
block4 block5 block6 |
block7 block8 block9 |
block10 block11 block12 |
block13 block14 |
方案1 随机分布算法
文件均衡偏差:df=137 467.08
方案2 数据均衡算法
| block | 0~20 | 21~40 | 41~60 | 61~80 | 81~100 |
| number | 3 | 3 | 3 | 3 | 2 |
| distribution | block1 block9 block10 |
block6 block11 block12 |
block2 block8 block14 |
block3 block5 block13 |
block4 block7 |
文件均衡偏差:df=81 290.32
图 4和图 5中的nodeEV表示节点期望值, 通过nodeEV与node1~node5的对比可以看出:采用随机block分布算法, node1~node5节点之间以及节点与nodeEV之间直方图差异比较明显; 而采用数据均衡算法, node1~node5节点之间直方图差异比较小, 而且基本上与nodeEV的直方图分布很接近, 因此采用数据均衡算法比采用随机block分布算法具有更好的数据均衡效果。

|
| 图 4 随机算法节点直方图 |

|
| 图 5 均衡算法节点直方图 |
经过不同数据多次实验验证, 采用数据均衡算法比采用随机block分布算法在文件均衡偏差值上可以有较大幅度的提高(本文实验结果提高了40.87%)。
5 结论本文针对MapReduce并行计算框架中出现的中间数据的数据倾斜问题, 提出了一种基于直方图的数据均衡算法, 该算法通过构建数据块直方图的形式来分析数据倾斜问题, 并定义文件均衡偏差值对数据倾斜程度进行度量, 进而通过交换节点中存储的数据块的方式, 在保证所有节点存储容量不变的条件下, 降低文件均衡偏差值。经过不同数据多次实验验证, 该算法比随机block分布算法具有更好的均衡效果。
同时也要指出, 本文提出基于直方图的数据均衡算法在计算过程中采用了贪心策略, 该策略并不保证能够找到数据均衡分布的全局最优解, 但是可以找到一个全局最优解的很好的近似解, 因此在工程上具有极大的应用价值。
| [1] |
陈吉荣, 乐嘉锦. 基于Hadoop生态系统的大数据解决方案综述[J]. 计算机工程与科学, 2013, 35(10): 25-35.
Chen Jirong, Le Jiajin. Reviewing the Big Data Solution Based on Hadoop Ecosystem[J]. Computer Engineering and Science, 2013, 35(10): 25-35. DOI:10.3969/j.issn.1007-130X.2013.10.003 (in Chinese) |
| [2] |
李建江, 崔健, 王聃, 等. MapReduce并行编程模型研究综述[J]. 电子学报, 2011, 39(11): 2635-2642.
Li Jianjiang, Cui Jian, Wang Dan, et al. Survey of MapReduce Parallel Programming Model[J]. Acta Electronica Sinica, 2011, 39(11): 2635-2642. (in Chinese) |
| [3] |
王刚, 李盛恩. MapReduce中数据倾斜解决方法的研究[J]. 计算机技术与发展, 2016, 26(9): 201-204.
Wang Gang, Li Sheng'en. Research on Handling Data Skew in MapReduce[J]. Computer Technology and Development, 2016, 26(9): 201-204. (in Chinese) |
| [4] | Blanas S, Patel J M, Ercegovac V, et al. A Comparison of Join Algorithms for Log Processing in MapReduce[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, New York, 2010: 975-986 |
| [5] | Zhang Chi, Li Feifei, Jestes J. Efficient Parallel KNN Joins for Large Data in MapReduce[C]//Proceedings of the 15th International Conference on Extending Database Technology, New York, 2012: 38-49 |
| [6] | Jestes J, Yi Ke, Li Feifei. Building Wavelet Histograms on Large Data in MapReduce[C]//Proceedings of the Vldb Endowment, 2011: 109-120 |
| [7] | Shi Yingjie, Meng Xiaofeng, Wang Fusheng, et al. HEDC++:an Extended Histogram Estimator for Data in the Cloud[J]. Journal of Computer Science and Technology, 2013, 28(6): 973-988. DOI:10.1007/s11390-013-1392-7 |
| [8] | Tang Mingwang. Efficient and Scalable Monitoring and Summarization of Large Probabilistic Data[C]//Proceedings of the 2013 SIGMOD/PODS Ph D Symposium, New York, 2013: 61-66 |
| [9] | Kwon Y, Balazinska M, Howe B, et al. A Study of Skew in MapReduce Applications[C]//Open Cirrus Summit, Moscow, Russia, 2011 |
| [10] | Gufler B, Augsten N, Reiser A, et al. Load Balancing in MapReduce Based on Scalable Cardinality Estimates[C]//Proceedings of the 2012 IEEE 28th International Conference on Data Engineering(ICDE), Washington, USA, 2012: 522-533 |
| [11] | Gufler B, Augsten N, Reiser A, et al. Handing Data Skew in MapReduce[C]//Proceedings of the 1st International Conference on Cloud Computing and Services Science, Noordwijkerhout, Netherlands, 2011, 146: 574-583 |
| [12] | Kolb L, Thor A, Tahm E. Block-Based Load Balancing for Entity Resolution with MapReduce[C]//Proceeding of the 20th ACM International Conference on Information and Knowledge Management Glasgow, UK, 2011: 2397-2400 |
| [13] | Kolb L, Thor A, Tahm E. Load Balancing for MapReduce-Based Entity Resolution[C]//Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Washington, USA, 2012: 618-629 |
| [14] |
王卓, 陈群, 李战怀, 等. 基于增量式分区策略的MapReduce数据均衡方法[J]. 计算机学报, 2016(1): 19-35.
Wang Zhuo, Chen Qun, Li Zhanhuai, et al. An Incremental Partitioning Strategy for Data Balance on MapReduce[J]. Chinese Journal of Computers, 2016(1): 19-35. DOI:10.11897/SP.J.1016.2016.00019 (in Chinese) |
2. University of Chinese Academy of Sciences, Beijing 100049, China;
3. Chengdu ChongXin Big Data Services Co., Ltd. Chengdu 611230, China
