

2. 西北工业大学 电子信息学院, 陕西 西安 710029
目标分类是计算机视觉领域中非常重要的研究方向之一,是目标分割,目标跟踪与行为分析等诸多复杂计算机视觉问题的基础,已广泛应用于交通、安防、医疗等领域。计算机自动目标分类技术在一定程度上可以减少人工分类的劳动强度,改变人类的生活方式,但目前计算机自动目标分类技术的应用还受其分类精度的限制。人类拥有强大的目标分类能力,当人在区分不同目标时,先通过视觉通路筛选出自己感兴趣的区域,然后由神经系统做出正确判断,得出分类结果。如果计算机能模拟人类的这种能力,计算机自动目标分类技术将会与人类分类行为更相近,分类结果更准确。
可计算视觉注意力模型,是利用计算机技术实现的视觉认知模型,即利用视觉搜索中的多种信息,由计算机实现人类视觉注意力显著对象预测的技术。近年来,该领域涌现出多种基于不同技术且效果优良的视觉注意力模型。例如,基于自底向上特征整合的Itti[1]模型,基于神经响应去相关的AWS[2]模型,基于概率公式的SUN[3]模型,基于贝叶斯网络结构的Torralba[4]模型,基于图论的GBVS[5]模型等。此外,机器学习的方法也已应用于构建视觉显著模型当中,Kchölkopf等人[6]及Judd等人[7]分别利用图像块和从每个像素点得到的特征向量来得到显著区域。但是,现有的大部分视觉注意力模型大多根据观察者的“自由观察”,并未涉及诸如目标分类之类的技术。
关于目标分类,传统的方法有基于外观的分类方法[8-9]、基于特征的分类方法[10-11],类似于CAD的物体模型[12]、遗传算法等[13]。这些传统的方法在一些领域表现优良,但并不适用于多类目标分类。20世纪60年代,Hubel等人[14]在研究猫脑皮层时发现,用于局部敏感和方向选择的神经元,可以有效降低反馈神经网络的复杂性,并受到这种独特网络结构的启发,提出了卷积神经网络(convolutional neural networks,CNN)。如今,CNN已成为众多科学领域的研究热点,特别是在模式分类领域,其分类能力已由Krizhevsky等人[15]在包含几百种类别共计百万张图片的数据库ImageNet上得已检验。虽然CNN的机理类似于人类神经网络,但是传统的CNN忽视了人类视觉系统在分类前对信息筛选的重要作用。因此,如果能将CNN与视觉注意力模型相结合,将会更接近人类行为,其分类能力也会有所提高。
人类的视觉分类行为是一个视觉通络与神经系统相结合的过程。本文试图通过对人类信息处理机制及人类神经网络的仿真,将视觉注意力模型与CNN相结合,提出一种具有生物学优势的目标分类新方法。其具体工作:①建立一个眼动数据库EDOC(eye-tracking database for objects classification),用于记录观察者在分类时的注视点数据,分析并学习人类分类时的视觉行为;②基于EDOC数据库,引入真实眼动数据作为监督值,建立基于有监督学习的视觉注意力模型,以实现人类视觉信息处理机制的仿真;③建立更适合目标分类任务的卷积神经网络,以实现人类神经网络处理过程的仿真。
通过对人类视觉目标分类过程的仿真,结果与传统分类方法相比,本文所提出的目标分类方法,在分类过程上与人类分类行为更相近。实验表明,本文提出的视觉注意力模型可以更准确地预测人在分类时感兴趣区域,并与本文建立的CNN网络相结合,可显著提高目标分类的准确度及收敛速度。
1 算法描述本文提出的目标分类方法,结合了对人类视觉信息处理机制的仿真与对人类神经网络的仿真,其算法流程如图 1所示。

|
| 图 1 算法流程图 |
在对人类视觉信息处理机制的仿真过程中,本文首先建立了一个眼动数据库EDOC,记录观察者在分类时的注视点数据。然后在EDOC数据库里,随机挑选训练图像集,对其进行显著视觉特征提取,经过支持向量机(SVM)训练,同时引入真实眼动数据作为基准图像,建立了基于有监督学习的视觉注意力模型,能预测出人在进行目标分类的视觉显著图。
在人类神经网络仿真过程中,本文首先将视觉注意力模型预测出的视觉显著图前60%的显著区域,作为人类分类的感兴趣区域;然后设计了适合目标分类任务的卷积神经网络,以随机挑选感兴趣区域图片得到训练集,利用卷积神经网络对其进行特征提取,经过SVM训练,得到最终目标分类结果。
2 建立EDOC数据库由于现有的大部分眼动数据库在建立时,观察者是“自由观察”的,并没有在目标分类任务下,因此,为研究一般人在做目标分类时的视觉行为,本文建立了数据库EDOC(如图 2所示)。该数据库包含6类目标的彩色图像以及受试者观察这些目标的眼动数据。6类目标分别是飞机、自行车、汽车、狗、人和白猫,每类目标各包含50张样本,共计300张且均带有类别标签。图像尺寸由600×700至800×500不等。

|
| 图 2 EDOC数据库的示例 |
本文使用Tobii TX300眼动仪记录眼动数据。眼动数据采集对象共10人,年龄12岁至40岁,男女各5人。实验中,每幅图展示5 s,让受试者观察的同时对他们发出区分这6类目标的指令。为保证实验记录数据的准确性,每隔10幅图后均会进行自动校准。根据实验记录的数据分析得出,受试者在最初观察图像的1 s里很可能只是在自由观察,并未执行分类任务,所以本文舍弃了受试者前1 s的眼动数据,记录下来的眼动数据(见图 3b))用来训练视觉显著模型。而热图(见图 3c))可以反映出受试者在分类时的感兴趣区域,分割出的感兴趣区域用来做目标分类。统计所有受试者的注视点数据并经过高斯滤波(参数标准差为2)得到基准图像(ground truth, GT)(见图 3d)),用作测试显著模型的性能。

|
| 图 3 眼动数据采集与处理 |
视觉注意力是帮助人类从无标注场景进行视觉感知的一个重要属性,人类可以迅速从外界输入的大量视觉信息中判断出感兴趣信息,使之优先得到大脑神经的处理。为模拟人类的视觉注意机制,可通过计算的方法建立模型,即建立视觉注意力模型。为获得图像特征与视觉注意力之间的变换关系,本文首先对EDOC数据库里的图像提取特征,并将得到的特征与注视点数据相映射,得到适用于分类任务的视觉显著模型,利用该模型预测人在分类时的显著图,进而得到与人类分类行为相近的感兴趣区域,以作下一步分类。
3.1 显著视觉特征提取为提高视觉注意力模型的性能,本文将低层特征与高层特征相结合,通过反复实验和结果比较,剔除了场景图像中与任务不相关的特征后,选取了特征集F={f1, f2, …, f35},其中包括31个低层特征及4个高级特征。
3.1.1 低层特征1) 用金字塔滤波器对三尺度的多分辨率亮度图像进行四方向滤波,得到13个亮度特征(如图 4前13幅图所示)。

|
| 图 4 特征图 |
2) 用ITTI[9]模型计算得到颜色、强度、方向3个特征(如图 4第14~16幅图所示)。
3) 利用加入了语境特征的Torralba[11]模型,基于图论的GBVS模型及采用了Lab色彩空间和去相关特征图的AWS模型计算显著图,得到3个模型特征(如图 4第17~19幅图所示)。
4) 计算红、绿、蓝三颜色通道值及概率值,分别得到3个色度特征及3个色度概率特征(如图 4第20~25幅图所示)。
5) 用中值滤波器对六尺度的彩色图像进行滤波,并计算三维色度直方图,得到5个色度直方图特征(如图 4第26~30幅图所示)。
6) 参照摄影师在构图和平衡画面时会用到水平线特征,故选取水平线作为最后一个低层特征(如图 4第31幅图所示)。
3.1.2 高层特征在实验中,我们发现因存在先验知识的原因,人类对人、人脸及车等各类体征会给予更多关注。因此,本文选取人脸检测器跟人,汽车检测器的检测结果作为高级特征(如图 4第32~35幅图所示)。
3.2 训练过程在统计学习理论中发展起来的支持向量机(support vector machines, SVM)方法是一种通用学习方法,其在非线性分类、函数逼近、模式识别等应用中有非常好的推广能力,可以有效地解决有限样本条件下的高维数据模型构建问题,并具有泛化能力强、收敛到全局最优、维数不敏感等优点。因此,本文利用SVM理论,得到图像特征与视觉注意力之间的变换关系,将提取的特征集F映射到视觉注意力空间,训练得到每个特征与视觉注意力之间的关系,并利用该映射关系生成视觉显著图,进而得出人类在分类时的感兴趣区域。
训练过程中,取样本集S⊂T, T为基准图像的训练集。样本s∈S。令
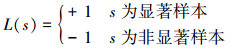
|
设P为基准图像的像素集,P={p1, p2, …, pN}, N为基准图像中像素的个数。O(pi)表示像素的显著度, i=1, 2, …, N。对像素集P进行排序得到有序集合Po={po1, po2, …, poN},其中O(po1)≥O(po2)≥…≥O(poN)。在利用SVM模型进行训练时,我们选择Sp⊂S作为正样本,Sn⊂S作为负样本,其中Sp={po1, po2, …, pom}, m=0.05N, Sn={pol, pol, …, poN}, N-l=0.3N,最终预测出显著图,训练过程的流程图如图 1上半部分(人类视觉信息处理机制的仿真过程)所示。
4 CNN网络设计人类的神经-中枢-大脑的工作过程,是一个不断迭代、不断抽象的过程。深度学习作为机器学习研究中的一个新领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来处理诸如图像之类的数据。CNN是一种深度学习下的多层次的机器学习模型,在CNN中,图像的一小部分(局部感受区域)作为多层结构的最低层的输入,将不同的信息传递到不同的层,每层均通过抽象去获得观测数据的最显著的特征并挖掘数据局部特征,经过不断的迭代提取全局特征,最终进行分类。
CNN的最大特点就是局部连接和权值共享。它的权值共享的网络结构使之更类似于生物神经网络,并且局部连接和权值共享可以减少所要训练的参数及计算复杂度。CNN网络结构包括:卷积层,池化层与全连接层,它们参数的设置正是整个CNN网络结构设计的重点。经过多次实验与调整,以及对目标特征的分析,本文设计了更适用于目标分类的CNN网络结构,包含4个卷积层,4个池化层,卷积层与池化层交替设置,如图 5所示。如此,多层的卷积层结构通过对输入的图像进行逐层抽象,从而获得更高层次的分布式特征表达,组合形成更抽象的特征,本文设计的CNN网络结构最后一层为全连接层,用于对图片对象的特征描述。

|
| 图 5 CNN网络结构 |
卷积可以提取出图像的局部特征,因此卷积层的设置是CNN网络结构设计的核心。通过对目标特征的分析,以及试验与调整,本文的CNN网络结构设计了4个卷积层(C1~C4)(如图 5所示)。特征的提取是通过以权值矩阵形式出现的卷积核(kernel)来完成的,本文建立的CNN网络各卷积层的卷积核大小分别为5, 5, 5, 4像素。针对各卷积层功能的不同,卷积核的大小也不同,如第一个卷积层的卷积核可以提取边缘、角等信息,通过实验与分析,5个像素的大小与目标边缘特征较符合,因此第一层卷积层的卷积核大小设为5。卷积核提取的二维特征集合为特征图。每层的特征图作为下一层的输入继续传播,本文CNN网络结构各卷积层输出的特征图数目分别为9, 18, 36, 72,卷积的步长均为1像素。此外,卷积核与输入之间的局部连接可以减少很多网络参数,降低计算负担。
4.2 池化层池化即为将尺寸比较大的图像的不同位置的特征进行聚合,计算图像一个区域上的某个特定特征的平均值(或最大值)来代表这个区域的特征。池化层的作用是使通过卷积层获得的特征具有空间不变性。因此为与卷积层层数一致,本文设计的CNN网络结构也包含4个池化层(S1~S4)(如图 5所示),分别连接在各层卷积层之后。为获取对平移、缩放和旋转不变的显著特征,各层池化大小均为2个像素,池化的步长均为1像素。本文采用常见的最大池化方式,其不仅可以降低特征的维数,还可以提高特征的鲁棒性。
4.3 全连接层本文CNN网络结构的最后一层为全连接层,输出一个兼顾了目标的局部特征与整体特征的648维的特征向量,由于本文CNN结构中的4个卷积层及4个池化层已先将特征的维数尽可能降低至可接受的大小,因此最后一层全连接层产生的计算负担在可接受范围内。最后利用liblinear SVM将得到的648维特征向量,进行训练,得出分类结果。
至此,本文建立的CNN网络结构,共计包含在4个卷积层、4个池化层、1个全连接层。在进行目标分类时,目标的一小部分作为本文CNN网络结构的最低层输入,经过个卷积层特征提取,并经过各池化层的最大池化,获得目标最显著的特征并挖掘出目标的局部特征,经过迭代,提取全局特征并结合局部特征进行分类,最终输出分类结果。
5 实验结果及分析为验证算法的正确性及有效性,本文设计了3组实验,第1组实验验证了本文的视觉显著模型(Ours)预测分类RoIs的能力,同时在相同条件下将Ours模型与其它视觉显著模型做了比较;第2组实验在数据库EDOC上评估了本文分类方法分类的错误率大小及错误率收敛速度,同时比较了本文分类方法与常规CNN的分类能力,本文分类方法是利用分类RoIs进行分类,而常规CNN是利用原图进行分类;为充分验证本文算法,第3组实验增加了实验数据量,建立了包含6 000张图的数据集,在该数据集上比较了本文分类方法与常规CNN分类时的错误率。实验环境是IBM x3650m5服务器,配置CPU E5-2603v2 (2.4 GHz), 32 GB RAM。
5.1 视觉显著模型预测分类感兴趣区域实验本实验利用EDOC数据库中的数据,对分类RoIs进行预测,实验采集的注视点数据作为基准。实验时,将所有彩色图像统一到200×200的大小,每类目标挑选30幅彩色图像作为训练,20幅作为测试。与Ours进行比较的8种模型分别是:AIM[16], AWS[2], Judd[7], ITTI[1], GBVS[5], SUN[3], STB[17], Torralba[4],这9种模型得到的典型视觉显著图对比如图 6所示。由于没有统一评价视觉注意力模型的标准,本文选取了常用的评价函数有:AUC、敏感度与特异度。AUC是一种用来度量视觉注意力模型与基准图像的差异的一个标准,通常,AUC的值介于0.5到1.0之间,AUC越大代表了模型的表现越好,与基准图像更相近。敏感度,又称为真阳性率,指将已知类别的目标准确分类的数目占总分类结果的比例,敏感度越高,模型越灵敏。特异度,又称为真阴性率,指将非该类的目标准确剔除的数目占总分类结果的比例,特异度越高,模型筛检目标非该类的能力越强。当3种评价函数数值越高,说明该模型性能越好。本实验在60%的显著区域计算敏感度与特异度。3种评价函数的实验结果如表 1所示。

|
| 图 6 9种模型得到的视觉显著图对比 |
| 参数 | Ours | AIM | AWS | GBVS | ITTI | STB | SUN | Torralba | Judd | 平均值 |
| AUC | 0.842 1 | 0.723 2 | 0.781 1 | 0.828 4 | 0.607 8 | 0.815 1 | 0.736 0 | 0.715 8 | 0.828 7 | 0.764 2 |
| 敏感度/% | 73.289 5 | 51.821 2 | 61.187 8 | 71.479 4 | 40.860 5 | 67.915 3 | 49.825 2 | 52.761 9 | 71.990 5 | 60.125 7 |
| 特异度/% | 82.235 4 | 77.417 4 | 79.148 0 | 77.858 8 | 77.821 7 | 78.867 4 | 76.031 4 | 76.540 2 | 77.674 5 | 78.177 2 |
图 6为EDOC数据库里的部分样例在9种模型下的视觉显著图对比,通过人的主观判断,可以看出相较于其他8种模型,Ours模型能更好的提取目标的特征,如车轮、眼睛等局部特征,人脸,汽车等整体特征。如此,特征的更好提取,更有利于分类准确度的提高。
从表 1中可以明显看出,在AUC指标下,Ours模型的结果为0.842 1,均高于其他8种模型,远高于ITTI模型,最接近基准图像(1.000 0)。Ours模型的敏感度为73.289 5,为9种模型的最大值,比平均值大约高13%,说明Ours模型较其他模型更灵敏。而实验中特异度的最大值也为Ours模型。结果表明,Ours模型在3种评价函数下,性能良好,与基准图像更一致。因此,Ours模型明显提高了利用视觉显著图预测人在分类时注视点的精度,更适用于提取分类RoIs。
5.2 在EDOC数据库上的分类实验本文从分类错误率的大小与收敛速度两方面,来评价本文分类方法性能。首先,将Ours模型预测的显著图前60%的区域,作为分类RoIs,实例如图 7所示。

|
| 图 7 分类RoIs获取 |
然后将分类RoIs作为如图 5所示CNN网络的输入进行分类。并与将原图作为输入的常规CNN分类分类方法结果作以比较。实验时,将所有图像均统一为100×100的大小,每类目标挑选30幅作为训练,20幅作为测试。2种分类方法各进行3次实验,CNN网络的练次数分别为500, 1 000, 1 500,以得到的错误率作为评判标准,结果如表 2所示。
| 训练次数 | 错误率/% | |
| 原始图像 | 分类Rols | |
| 500 | 73.3 | 63.3 |
| 1 000 | 50.0 | 36.7 |
| 1 500 | 36.5 | 18.2 |
从表 2中可以看出,在3种训练次数下,本文的方法分类错误率均低于常规CNN。虽然在训练次数为500的时候,由于训练次数较少,2种方法的错误率都高于50%,但是本文方法的错误率比常规方法的错误率小10%。随着训练次数的增加,本文方法的错误率从63.3%下降到36.7%,直到18.2%。而常规的CNN在训练次数为1 000时,错误率为50%,当训练次数增加到1 500时,其错误率仍高于30%。虽然随着训练次数的增加,2种方法的分类错误率均会下降,但是很明显本文的分类方法分类错误率的收敛速度快于常规CNN方法。在相同训练次数下,错误率更低。因此,本文的分类方法可以优化分类结果。
5.3 在6 000张图上的分类实验5.1及5.2节的实验,虽从两方面验证了本文分类方法的合理性,但是数据库EDOC包含的数据量较少,而目前又没有现成的包含6类目标的大数据库可以利用,所以,为充分验证本文分类方法,如图 8所示,本节建立了一个较大的包含了6 000张图的数据集以进行实验。该数据集中的图片均来自网络,每类各有1 000张。

|
| 图 8 6 000张图的示例 |
实验中,首先利用Ours模型预测这6 000张图的显著图,并将显著图的前60%显著的区域作为分类RoIs。然后利用CNN网络对分类RoIs进行分类,并与将原图作为输入的常规的CNN分类分类方法结果作以比较。同样地将所有图像均统一为100×100的大小,每类目标挑选600幅作为训练,400幅作为测试, 分类错误率对比结果如表 3所示。
| 训练次数 | 错误率/% | |
| 原始图像 | 分类Rols | |
| 500 | 63.2 | 44.6 |
| 1 000 | 56.7 | 33.8 |
| 1 500 | 46.9 | 29.1 |
从表 3中可看出,在包含了6 000张图的较大数据库上的实验中,随着训练次数增加,2种方法的错误率虽然均有下降,但是在相同训练次数下,本文方法分类错误率明显低于常规CNN。在训练次数为500的时,本文的方法的错误率(44.6%)比常规方。法的错误率(63.2%)低近20%,甚至低于常规方法在训练次数为1 000次的分类错误率(56.7%)随着训练次数次数的增加,本文分类方法的错误率从44.6%下降到29.1%,而常规方法的错误率从63.2%下降到46.9%,本文分类方法分类错误率的收敛速度很明显快于常规CNN方法。因此,本文的分类方法在较大数据集上也有优良的分类表现。
6 结论受人类对不同目标进行分类识别行为的完整过程的启发,本文提出了一种结合基于学习的视觉显著模型与CNN的目标分类新方法。通过建立EDOC数据库,研究并记录人们在进行目标分类时的视觉行为;然后,利用该数据库训练出针对分类任务的有监督视觉注意力模型,预测人在区分不同目标时的感兴趣区域;最后设计了适用于分类的CNN网络,利用视觉注意力模型得到的感兴趣区域进行目标分类。本文的方法与常规的CNN分类方法相比,分类准确度有明显提高,且收敛速度更快,其生物学优势也十分显著。由于人类的视觉行为很复杂,思考过程尤为如此。对于不同目标,人类的思考过程也有所不同,因此,我们暂时无法利用计算机完整地仿真其过程。在今后的工作中,我们可以针对不同目标,提取不同的特征,构造不同的CNN网络结构,进一步提高分类效率。
| [1] | Itti L, Koch C. A Saliency-Based Search Mechanism for Overt and Covert Shifts of Visual Attention[J]. Vision Research, 2000, 40(12): 1489-1506. |
| [2] | Garcia-Diaz A, Fdez-Vidal X R, Pardo X M, et al. Decorrelation and Distinctiveness Provide with Human-Like Saliency[C]//International Conference on Advanced Concepts for Intelligent Vision Systems Springer, Berlin, Heidelberg, 2009, 5807: 343-354 |
| [3] | Zhang L, Tong M H, Marks T K, et al. Sun:A Bayesian Framework for Saliency Using Natural Statistics[J]. Journal of Vision, 2008, 8(7): 1-20. DOI:10.1167/8.7.1 |
| [4] | Torralba A. Modeling Global Scene Factors in Attention[J]. Journal of The Optical Society of America A, 2003, 20(7): 1407-1418. DOI:10.1364/JOSAA.20.001407 |
| [5] | Schölkopf B, Platt J, Hofmann T. Graph-Based Visual Saliency[J]. Advances in Neural Information Processing Systems, 2007, 19: 545-552. |
| [6] | Schölkopf B, Platt J, Hofmann T. A Nonparametric Approach to Bottom-Up Visual Saliency[C]//International Conference on Neural Information Processing Systems, 2006: 689-696 |
| [7] | Judd T, Ehinger K, Durand F, et al. Learning to Predict Where Humans Look[C]//IEEE International Conference on Computer Vision, 2010: 2106-2113 |
| [8] | Swain M J, Ballard D H. Indexing via Color Histograms[C]//International Conference on Computer Vision, 1990: 390-393 |
| [9] | Schiele B, Crowley J L. Recognition Without Correspondence Using Multidimensional Receptive Field Histograms[J]. International Journal of Computer Vision, 2000, 36(1): 31-50. DOI:10.1023/A:1008120406972 |
| [10] | Lowe D G. Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. DOI:10.1023/B:VISI.0000029664.99615.94 |
| [11] | Lindeberg T. Scale Invariant Feature Transform[M]. Scholarpedia, 2012: 2012-2021 |
| [12] | Mohan R, Nevatia R. Perceptual Organization for Scene Segmentation and Description[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 1992, 14(6): 616-635. |
| [13] | Lillywhite K, Lee D J, Tippetts B, et al. A Feature Construction Method for General Object Recognition[J]. Pattern Recognition, 2013, 46(12): 3300-3314. DOI:10.1016/j.patcog.2013.06.002 |
| [14] | Hubel D H, Wiesel T N. Receptive Fields and Functional Architecture of Monkey Striate Cortex[J]. Journal of Physiology, 1968, 195(1): 215-243. DOI:10.1113/jphysiol.1968.sp008455 |
| [15] | Krizhevsky A, Sutskever I, Hinton G E. Imagenet Classification with Deep Convolutional Neural Networks[C]//International Conference on Neural Information Processing Systems, 2012: 1097-1105 |
| [16] | Bruce N D B, Tsotsos J K. Saliency Based on Information Maximization[C]//International Conference on Neural Information Processing Systems, 2005: 155-162 |
| [17] | Garcia-Diaz A, Fdez-Vidal X R, Pardo X M, et al. Decorrelation and Distinctiveness Provide with Human-Like Saliency[C]//International Conference on Advanced Concepts for Intelligent Vision Systems, 2009: 343-354 |
2. School of Electronics and Information, Northwestern Polytechnical University, Xi'an 710029, China
