

2. 西北工业大学 自动化学院, 陕西 西安 710072;
3. 西北工业大学 无人机特种技术国防科技重点实验室, 陕西 西安 710072
近年来,由于无人机具有成本低、可操作性好、可垂直起降、可携带其他载物等优点,其在军事及民用领域应用较多[1-2]。特别是配备了视觉系统后,更能加强其自主化、智能化,使其应用领域更为广泛。其中基于视觉的无人机定点着陆是一个热门的研究主题。通过对视觉传感器采集到的图像进行处理,并识别、跟踪着陆地标图像,以辅助无人机进行自主着陆[3]。但在着陆过程中,目标尺度、光照、拍摄角度以及局部区域环境会发生变化,再加上复杂的背景环境等干扰,使得目标的跟踪难度加大,甚至会丢失目标。因此,无人机定点着陆过程中的视觉跟踪问题是一个非常具备挑战性的研究课题。
近年来,人们针对视觉跟踪问题提出很多算法,但现有的算法在解决无人机定点着陆过程中的长时间实时视觉跟踪问题上仍存在不足。早期的基于模板匹配的跟踪是通过选择性地更新模板来描述相似性,从而找到最优的跟踪结果[4]。此类方法虽然对于目标的外观变化有一定的鲁棒性,但没有充分利用目标的特征信息,且模板更新存在误差,故无法长时间稳定准确地跟踪目标。基于稀疏表示(sparse representation)的方法是另一种常用的跟踪方法[5-6],但此类方法计算密集,没有充分利用上下文信息,无法保证长时间目标跟踪的稳定性与准确性。tracking-by-detection是通过在线学习模式(如SVM[7],boosting[8]),在序列图像中进行目标与背景的分类检测,从而达到目标跟踪的目的。但此类方法耗费时间较长,无法满足实时性的要求。Kalal等人对光流法进行改进,设计出一种中值流跟踪器[9]。该跟踪器跟踪性能较好,提高了目标跟踪的可靠性与实时性;但没有充分利用上下文信息,且无法在目标消失后重新找回目标。对此,Kalal等人在中值流跟踪器的基础上,提出了tracking-learning-detection(TLD)跟踪算法[10],此算法鲁棒性较高,通过在线训练多个专家模型(multiple experts),综合判断并纠正当前跟踪结果,保证目标跟踪的准确性。但此算法由于需在线训练多个专家模型,故实时性较为一般,不满足无人机基于视觉进行顶点着陆对于视觉跟踪算法实时性的要求。
本文基于上述背景分析,利用以SURF-BoW特征进行线下训练的SVM分类器进行跟踪器初始化,之后利用改进后的基于上下文信息相关性的中值流跟踪算法进行目标跟踪,保证目标跟踪的可靠性、完整性,并设计目标再搜索方法,保证在上述跟踪失败的情况下仍能找回目标并进行跟踪,提升整套算法的鲁棒性。
1 基于前后跟踪误差的中值流跟踪算法 1.1 前后跟踪误差对于计算机视觉中特征点的跟踪,是通过t时刻的某特征点的位置,估算出t+1时刻该点位置。但点的跟踪通常面临被跟踪点改变或者从图像中消失的情况,此时则认为该特征点跟踪失败。为了能够使得跟踪器自我评价特征点跟踪的可靠性,Kalal等人提出了一种基于向前向后一致性假设的中值流跟踪算法,假设如下[9]:①跟踪器由t时刻前向跟踪特征点到t+1时刻会生成1条轨迹;②跟踪器由t+1时刻后向跟踪特征点到t时刻,生成1条验证轨迹;③2条轨迹相比较,若明显不同,则认为该特征点跟踪错误。如图 1所示, a)中点A的前后跟踪轨迹一致,故跟踪正确;相反,b)中的点B前后跟踪轨迹不一致,则认为跟踪失败。

|
| 图 1 前后双向跟踪示意图 |
前后跟踪误差可用来判断双向跟踪轨迹是否相同。如图 2所示,It是t时刻图像, It+1是t+1时刻图像。使用跟踪器, 对It中的特征点xt向前跟踪到It+1中的点xt+1。之后, 向后跟踪, 即从It+1中的特征点xt+1向后跟踪到It中的xt。前后误差被定义为这2条轨迹的相似性。前后误差EFB=‖xt-t‖, 即点xt与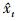

|
| 图 2 前后双向跟踪误差 |
中值流跟踪算法采用L-K光流法[11-12]为核心跟踪算法, 通过前后向跟踪误差及跟踪特征点相邻2帧周边区域相似性进行跟踪性能判断, 从而准确跟踪到目标。如图 3所示。

|
| 图 3 中值流跟踪算法 |
黄色矩形框区域Bt为t时刻跟踪到的目标, 即着陆地标。在Bt内均匀划分网格, 并以网格中心为跟踪特征点进行初始化, 得到t时刻的跟踪特征点集为xit (1≤i≤n), 其中n为t时刻初始化的跟踪特征点数目。之后采用L-K光流法对这些特征点进行双向跟踪, 继而可以计算出跟踪特征点的前后误差EFBi; 同时, 也可计算每个跟踪特征点的相似性Ni。其中Ni是指It图像中分别以特征点
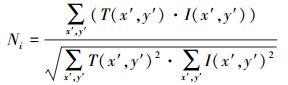
|
(1) |
式中,Ni的值域为[0, 1], 0表示完全不相似, 1表示完全相似。T(x, y)为图像T在(x, y)处的灰度值, I(x, y)为图像I在(x, y)处的灰度值。
2 基于上下文信息相关性的改进中值流跟踪器中值流跟踪器以L-K光流法为核心, 通过前后双向跟踪误差及跟踪特征点局部相似性检验, 筛除50%跟踪效果较差的特征点, 用剩下的特征点来估计整个边界框的位移。该算法虽提高了目标跟踪的可靠性与实时性, 却无法自己初始化目标, 不能保证长时间跟踪后目标的完整性, 并且无法在跟踪失败后再次检索目标, 使得整个跟踪算法不具备鲁棒性。为了解决上述问题, 本文基于改进的中值流跟踪算法, 设计了一套专门用于视觉导航的无人机定点自主着陆的目标实时跟踪算法, 该算法流程如图 4所示。

|
| 图 4 基于上下文相关信息的中值流跟踪算法流程 |
为实现基于视觉导航的无人机自主着陆, 本文设计了易检测识别并能够提取特征进行相对位姿解算的合作目标, 如图 5所示。

|
| 图 5 合作目标 |
如图 5a)所示, 该合作目标由同心的圆和菱形组成。圆为黑色, 菱形为白色, 颜色相对明显, 易于分割与识别。最外围的圆的作用是用来通过轮廓特征确定感兴趣区域, 即目标所在区域; 内部的菱形则用来提取特征点, 用于相对位姿信息的计算。提取的特征点为图 1b)中红色点, 而圆与菱形的中心点与特征点的连线可作为参考航向线使用。
实际的无人机飞行避免不了合作目标被遮挡的情况。本文设计的合作目标在面对图 2中的遮挡情况仍能继续使用。图 6a)外围圆部分被遮挡, 但仍能通过部分圆确定目标区域, 从而识别目标; 而内部菱形区域完整, 可提取完整的特征点进行现对位姿等导引信息的解算。图 6b)内部的菱形也被遮挡一部分, 通过部分圆能确定目标区域, 从而识别目标; 但内部的菱形特征点缺少一个, 无法计算相对位姿等导引信息。此时可对目标进行直线检测, 通过检测到的菱形边所在直线, 确定交点所在。检测到的交点即为所需特征点。

|
| 图 6 合作目标部分被遮挡 |
着陆地标检测的目的是为了提取感兴趣区域图像, 为下一步地标识别打下基础。首先, 需对采集到的视频帧图像进行预处理。如图 7所示, 预处理包括:图像灰度化、滤波去噪、图像分割、边缘检测和轮廓提取。在图像预处理后, 可以得到包含目标轮廓的可疑目标的轮廓集。然后利用最小矩形框包围这些轮廓, 得到包含地标图像的矩形图像集。

|
| 图 7 图像预处理 |
着陆地标识别的目的是在目标检测之后, 准确地识别出地标图像, 完成跟踪器目标初始化。本文基于SURF-BoW特征进行离线SVM分类器训练, 用于着陆地标识别。SURF(speeded up robust features)是一种尺度不变、旋转不变的特征点检测子与描述子, 具备速度快、鲁棒性好等优点[13]。而词袋(bag of words, 简称BoW)模型原是自然语言处理领域用于文本信息检索和文本分类的技术[14], 用于图像领域时, 需要将二维图像信息映射成视觉关键词集合, 这样即保存了图像的局部特征又有效压缩了图像的描述[15]。本文结合SURF与BoW的优势, 提取SURF-BoW特征来描述样本图像, 利用SVM算法对这些特征进行训练, 从而得到用于目标识别的SVM分类器。其中分类器构建步骤如下:
Step1 获取样本图像, 并将尺寸统一调整为256*256像素;
Step2 将每个样本图像分割为大小为32*32像素的单元格。每个单元格都提取SURF特征, 整幅样本图像所有的单元格提取到的SURF特征形成一个SURF特征集合;
Step3 使用K-means均值聚类算法对所有样本图像提取的SURF特征进行聚类, 得到K个类, 每个类的聚类中心对应一个视觉单词, 即每个类用一个视觉单词表示, 从而生成一个由K个视觉单词构成的视觉单词表, 即为视觉词典;
Step4 每个样本图像都要统计提取到的每个SURF特征点的所属类别, 确定每一类别中包含该样本图像SURF特征的个数; 统计结束后每一幅样本图像可生成一个K维的特征向量, 即为该样本图像的视觉词汇特征向量;
Step5 设正样本图像的类别标签为1, 负样本的类别标签为0, 每一个样本图像的K维视觉词汇特征向量和相应的类别标签可作为训练数据, 基于SVM训练算法, 训练得到着陆地标图像分类器。
目标的识别过程如下:
Step1 输入待分类图像, 并将其尺寸调整为256*256像素;
Step2 将待分类图像分割为大小为32*32像素的单元格。每个单元格都提取SURF特征, 所有的单元格提取到的SURF特征形成一个SURF特征集合;
Step3 统计提取到的每个SURF特征点的所属类别, 确定每一类别中包含该图像SURF特征的个数; 统计结束后可生成一个K维的特征向量, 即为待分类图像的视觉词汇特征向量;
Step4 将待分类图像的视觉词汇特征输入到着陆地标图像分类器内进行分类识别。

|
| 图 8 目标识别算法工作流程 |
中值流跟踪算法是以跟踪特征点来表征目标图像, 经双向L-K光流跟踪后, 以所有跟踪点的EFB与N的中值为阈值, 来去除50%跟踪效果较差的跟踪点, 以剩下的50%的跟踪点来估计目标边界框的位移。但该方法去除的50%的跟踪点不一定都是跟踪效果较差的点, 且跟踪到的目标无法保证其完整性。而且该方法还需要每一帧初始化跟踪点, 这样会浪费一定的时间。
故本文对中直流跟踪算法做出改进, 采用固定值ET, NT作为阈值, 来滤除跟踪效果较差的点。如式(2)所示, 当跟踪点满足式(2)中的条件, 即认为该点跟踪效果较好, 反之, 则较差。
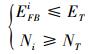
|
(2) |
式中,i指的是第i个跟踪点。经多次实验, 当ET=5, NT=0.7, 算法性能最好。如果剩下的跟踪点的数目不及初始化的一半, 则需重新初始化跟踪点。如此避免多次初始化, 减小了算法的时间复杂度。之后, 为了保证跟踪目标的完整性与准确性, 基于帧间目标相似性的特点, 以上一帧跟踪到的目标图像为模板, 与本帧跟踪到的目标图像进行归一化相关性匹配。具体过程是将2帧跟踪到的目标图像调整到相同尺寸, 然乎利用(1)式计算归一化相关系数NL。若NL满足(3)式, 则认为该时刻目标跟踪成功, 否则, 跟踪失败。
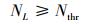
|
(3) |
式中,Nthr为设定的阈值。经多次试验Nthr=0.7时, 算法性能最好。
2.5 跟踪失败后的目标再搜索跟踪失败后, 可采用SVM分类器来准确地识别目标。但用分类起识别目标耗费时间较长, 会增加整套算法的时间复杂度, 降低算法的实时性, 故本文设计了跟踪失败后目标再搜索方法。该方法基于上下文信息来确定再搜索区域, 减小目标搜索范围; 之后利用时间复杂度较小的归一化模板匹配算法来进行目标识别。其中模板匹配所用模板是上一帧跟踪到的着陆地标图像, 通过实时更新模板图像, 可提高算法的鲁棒性, 并且能够准确识别到目标。该算法如下:
算法输入:t-3时刻到t-2时刻跟踪点的速度集V1={v1, v2, …, vn}, t-2时刻到t-1时刻跟踪点的速度集V2={v′ 1, v′ 2, …, v′m}, t-1时刻包围目标的最小矩形框中心坐标(xb, yb)、宽W、高H。
算法输出:t时刻跟踪到的目标图像。
1) 确定速度集V1的最大速度为v1max=max{v1, v2, …, vn}, 速度集V2的最大速度为v2max=max{v′ 1, v′ 2, …, v′ m};
2) 通过(4)式计算出短时间速度变化最大尺度λ;
3) 通过(5)式来估算出t-1时刻到t时刻的速度vem;
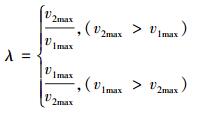
|
(4) |
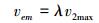
|
(5) |
4) 确定在t时刻目标的再搜索区域在整幅图中的位置如图 9所示, 其中Δt2为t-1时刻到t时刻的时间间隔;

|
| 图 9 再搜索区域划分示意图 |
5) 再搜素区域划分后, 在该区域里重新进行图像预处理、边缘提取、轮廓检测和目标检测, 得到“疑似目标”图像集;
6) 将上一帧目标图像与该“疑似目标”集里的目标一一进行归一化相关系数计算;
7) 取其中相关系数大于0.7且最大的“疑似目标”图像为本帧最终再搜索到目标, 若所有“疑似目标”图像的归一化相关系数均小于0.7, 则采用分类器去精确识别目标。
3 实验结果与分析 3.1 实验结果实验在Inter(R)Core(TM) i5-6200 CPU with HD Graphics 2.40GHz处理器、4.00GB内存的PC机上运行, 操作系统为Windows 10, 软件开发工具为VS2013+OpenCV2.4.9。实验采用3组视频A, B, C, 其中A, C视频帧图像尺寸大小为1 280×720, B视频帧图像尺寸大小为800×448;实验视频A中目标在191帧后完全消失, 于198帧后重新出现, 实验视频B, C中目标一直存在。
此次实验分别采用中值流跟踪算法、基于中值流跟踪器的TLD实时跟踪算法以及本文设计的算法进行着陆地标跟踪。对应每一个实验视频, 每种算法要运行10次并将结果取均值, 作为最后的结果。本文采用2种度量手段来评估算法。第一种为目标跟踪成功率及每帧图像算法运行时间, 其中目标跟踪成功率指的是目标跟踪成功的帧数与实验视频总帧数的比值。跟踪结果满足下式则认为跟踪成功:
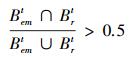
|
(6) |
式中,Bemt为算法跟踪到的目标所在矩形框, Brt为真实目标所在矩形框。第二种为跟踪误差Terr:
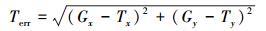
|
(7) |
式中,(Gx, Gy)为算法跟踪成功的目标所在矩形中心像素点的坐标, (Tx, Ty)为真实的目标所在矩形中心像素点的坐标。
经过实验后, 目标跟踪成功率及每帧图像算法运行时间如表 1与表 2所示。各算法对应的跟踪误差如图 10所示。图 11为各个实验视频在运行算法后跟踪到的目标截图。

|
| 图 10 跟踪误差 |

|
| 图 11 算法结果截图 |
由表 1可知,在跟踪地面静止的着陆地标时,本文所设计的目标跟踪算法相对于中值流跟踪算法,目标跟踪成功率较高,与TLD算法相近。由表 2可知,本文所设计的目标跟踪算法相对于TLD算法来说实时性较强,满足无人机自主着陆对于图像处理的时间要求。由图 10的目标跟踪误差曲线图可知,本文所设计的算法的目标跟踪误差不超过5个像素,相对于中值流跟踪算法与TLD算法,目标跟踪准确性较好。而由图 11中列出的各算法跟踪到的目标结果截图可以明显看出,本文所设计的算法跟踪到的目标相对于TLD与中值流跟踪算法来说,较为完整,表明本文所设计的算法在跟踪地面静止的着陆地标时,稳定性较好,能够跟踪到完整的地标图像,有利于下一步能够提取到足够的特征进行位姿导航信息的解算。
综上所述,在无人机定点着陆中利用视觉传感器进行地面着陆地标跟踪方面,本文所设计的算法相对于中值流跟踪算法与TLD算法,跟踪性能较好,实时性较强,能够准确、稳定的跟踪地标图像。
4 结论本文基于中值流跟踪算法的基础进行改进,设计了一套适用于无人机顶点着陆过程中对着陆地标进行跟踪的目标跟踪算法。实验结果表明,该算法不仅能够自动识别着陆地标,完成跟踪目标初始化,还能够实时、准确的跟踪目标,并且在跟踪失败后能够快速地重新搜索到目标,是一套鲁棒性较强的适用于无人机定点自主着陆的目标跟踪算法。该算法实时跟踪到的完整目标还可用于下一步提取足够的特征进行位姿导航信息的解算,为无人机在视觉着陆导航领域中的应用打下基础。
| [1] |
董国忠, 王省书, 胡春生. 无人机的应用及发展趋势[J]. 国防科技, 2006, 29(10): 34-38.
Dong Guozhong, Wang Shengshu, Hu Chunsheng. Application and Development Trend of Unmanned Aerial Vehicle[J]. National Defense Science and Technology, 2006, 29(10): 34-38. DOI:10.3969/j.issn.1671-4547.2006.10.008 (in Chinese) |
| [2] |
吴显亮, 石宗英, 钟宜生. 无人机视觉导航研究综述[J]. 系统仿真学报, 2010, 22(suppl 1): 62-65.
Wu Xianliang, Shi Zongying, Zhong Yisheng. An Overview of Vision-Based UAV Navigation[J]. Journal of System Simulation, 2010, 22(suppl 1): 62-65. (in Chinese) |
| [3] | Zheng Z, Wei H, Tang B, et al. A Fast Visual Tracking Method via Spatio-Temporal Context Learning for Unmanned Rotorcrafts Fixed-Pointed Landing[C]//Guidance, Navigation and Control Conference, 2017 http://ieeexplore.ieee.org/document/7829098/ |
| [4] | Matthews I, Ishikawa T, Baker S. The Template Update Problem[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2004, 26(6): 810-815. |
| [5] | Kulikowsk C. Robust Tracking Using Local Sparse Appearance Model and K-Selection[C]//Computer Vision and Pattern Recognition, 2011: 1313-1320 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5995730 |
| [6] | Zhong W, Lu H, Yang M H. Robust Object Tracking via Sparse Collaborative Appearance Model[J]. IEEE Trans on Image Processing, 2014, 23(5): 2356-2368. DOI:10.1109/TIP.2014.2313227 |
| [7] | Bai Y, Tang M. Robust Tracking via Weakly Supervised Ranking SVM[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2012: 1854-1861 http://dl.acm.org/citation.cfm?id=2354888 |
| [8] | Grabner H, Grabner M, Bischof H. Real-Time Tracking via On-Line Boosting[C]//British Machine Vision Conference 2006, Edinburgh, Uk, 2013: 47-56 http://ci.nii.ac.jp/naid/10027937146 |
| [9] | Kalal Z, Mikolajczyk K, Matas J. Forward-Backward Error: Automatic Detection of Tracking Failures[C]//International Conference on Pattern Recognition, 2010: 2756-2759 http://doi.ieeecomputersociety.org/10.1109/ICPR.2010.675 |
| [10] | Kalal Z, Mikolajczyk K, Matas J. Tracking-Learning-Detection[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2012, 34(7): 1409. |
| [11] | Lucas B D, Kanade T. An Iterative Image Registration Technique with an Application to Stereo Vision[C]//International Joint Conference on Artificial Intelligence, 1981: 674-679 http://dl.acm.org/citation.cfm?id=1623280 |
| [12] | Shi J, Tomasi. Good Features to Track[C]//1994 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2002: 593-600 |
| [13] | Bay H, Tuytelaars T, Gool L V. Surf:Speeded up Robust Features[J]. Computer Vision & Image Understanding, 2006, 110(3): 404-417. |
| [14] | Lewis D D. Naive(Bayes) at Forty: The Independence Assumption in Information Retrieval[C]//Europen Conference on Machine Learning Springer, Berlin, Heidelberg, 1998: 4-15 http://nar.oxfordjournals.org/external-ref?access_num=10.1007/BFb0026666&link_type=DOI |
| [15] |
李远宁, 刘汀, 蒋树强, 等. 基于"Bag of Words"的视频匹配方法[J]. 通信学报, 2007, 28(12): 147-151.
Li Yuanning, Liu Ting, Jiang Shuqiang, et al. Video Matching Method Based on "Bag of Words"[J]. Journal on Communications, 2007, 28(12): 147-151. DOI:10.3321/j.issn:1000-436x.2007.12.025 (in Chinese) |
2. School of Automation, Northwestern Polytechnical University, Xi'an 710072, China;
3. National Key Laboratory of Special Technology on UAV, Northwestern Polytechnical University, Xi'an 710072, China
