

2. 甘肃省高原交通信息工程及控制重点实验室, 甘肃 兰州 730070
近年来,多种算法应用于对事物对象的分类识别研究,AdaBoost算法[1]在被提出后因其较高的检测速度广泛应用于人脸检测中,其技术已经甚为成熟。针对传统AdaBoost算法存在的问题,许多研究学者如钱志明、李文辉、刘王胜、付忠良等[2-5]提出了不同的改进方法,并取得了较好的改进效果。AdaBoost算法的思想是通过调整样本权重和弱分类器权值,从训练出的弱分类器中筛选出权值系数最小的弱分类器组合成一个最终强分类器[6]。在以往的改进算法中,对弱分类器加权系数未同时考虑到弱分类器的可靠性及对正样本的识别能力。本文在传统算法的基础上,利用改进的细菌觅食优化算法的思想全局优化提升弱分类器的权重系数,并提出新的权重系数求解方式,使得弱分类器在FRR一定的情况下得到更低的FAR,从而使目标检测算法的分类识别性能得以提高。
1 Adaboost算法AdaBoost算法是最著名的且被广泛使用的Boosting算法,在训练集上依次训练弱分类器,每次下一个弱分类器是在训练样本的不同权重集合上训练的。权重由每个样本分类的难度确定,而分类的难度是通过前面步骤中的分类器的输出估计得到[7]。AdaBoost算法在样本训练集使用过程中,对其中的关键分类特征集进行多次挑选,逐步训练分量弱分类器,用适当的阈值选择最佳弱分类器,最后将每轮训练确定的最佳弱分类器组合为强分类器。其中,级联分类器的设计模式为在尽可能保证感兴趣图像输出率的同时,减少非感兴趣图像的输出率,随着迭代次数不断增加,所有的非感兴趣图像样本都不能通过,而感兴趣样本始终保持尽可能通过为止。
1.1 AdaBoost算法训练过程算法训练过程[8]描述如下:
1) 输入样本集S={(x1, B1), (x2, B2), …, (xn, Bn)}, Bi=yi为样本类别, yi∈{1, -1}即分别表示正样本和负样本, n为总的训练样本数量。
2) 初始化样本权值, 令w1, i=1/n
3) 对于迭代次数t=1, 2, …, T
① 对于每个所选特征训练一个弱分类器ft(xi), 误差值根据样本权值计算, 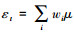
② 计算ft的缩放系数
③ 从生成的弱分类器中, 找出一个具有最小εt的弱分类器ft更新每个样本对应的权重, 使更新后的错误样本权重相对增加, 而正确分类的样本权重相应减小, wt+1, i=wt, iexp(-αtyift(xi))/zt, zt=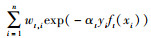
算法分类过程描述如下:
1) 弱分类器级联成强分类器F(x)=
2) 分类结果输出

|
由AdaBoost算法的描述过程可知, 该算法在实现过程中根据训练集的大小初始化样本权值, 使其满足均匀分布, 在后续操作中通过公式来改变和规范化算法迭代后样本的权值。样本被错误分类导致权值增大, 反之权值相应减小, 这表明被错误分类的训练集包含一个更高的权值。这就会使在下轮时训练样本集更注重于难以分类的样本, 针对这些关键样本的不断学习来构建下一个弱分类器, 直至样本被正确分类[9]。在达到规定的迭代次数或者预期的误差率时, 则强分类器构建完成。
2 快速的变概率细菌觅食算法细菌觅食算法(BFO)[10]是一种新兴的智能优化算法, 受到不同领域及专家学者的广泛关注。目前广泛应用于工程参数优化、神经网络、模式识别、图像处理问题等方面。
针对BFO存在的缺陷, 目前已有的改进算法大多针对问题的某个方面在一定程度上进行了改进。周佳薇等[11]提出的变概率的混合细菌觅食优化算法(VPBFO), 有效提高了求解精度及早熟收敛能力, 但选择合适的控制参数及其他方面还有待提高。本文提出了一种快速的变概率细菌觅食算法, 算法利用改进的随机化佳点集方法初始化种群, 这使得产生的菌群具有全局搜索空间、多样性和均匀性; 由于细菌觅食算法3个主要操作中最重要的是趋化操作, 其他2种操作主要是辅助优化, 故本文为提高算法的收敛速度, 在进行趋化性操作时将旋转和直向结合为一步完成, 利用PSO的快速搜索能力的思想[12], 直接以粒子移动方法替换趋化操作的方向和步长, 样本中的每个个体都进行一次趋化性操作后, 更新细菌个体最佳位置和菌群最佳位置; 采用变概率的迁徙-消亡策略, 利用菌群适应度方差的稳定性自适应改变迁徙概率, 由此避免菌群陷入局部极值。
设p(i, j, k, m)为细菌i在第j次趋向操作、第k次复制操作及第m次迁徙操作后的位置, 其中j, k, m的初始值均为0, 设第i个细菌的位置为Ni=[xi1, xi2, …xin], 基准概率值a=0.1, 上限控制变量b=0.3。
快速的变概率细菌觅食优化算法的过程描述如下:
1) 初始化参数。菌群大小S、搜索空间维度v、趋化次数Td、复制次数Tre、迁徙次数Ted。
2) 初始化菌群位置。利用随机化佳点集方法初始菌群, 并计算细菌个体的适应度值h。设置细菌个体最佳位置初始值和全局最佳位置初始值。
3) 设置变量。其中趋化次数j=1:Td, 复制次数k=1:Tre, 迁徙-消亡次数m=1:Ted。
4) 进行趋化操作。对细菌位置以粒子群算法的更新方式(1)、(2)式进行更新并计算新位置上的适应度函数值。
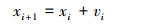
|
(1) |
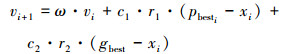
|
(2) |
5) 进行复制操作。趋化操作完成后, 累加每个细菌在周期内的适应度函数值得到健康值, 对健康值进行排序, 复制健康值优的细菌, 而对于健康值劣的细菌进行淘汰。
6) 进行迁徙操作。完成复制操作后, 对每个细菌个体产生一个随机概率, 将其与(3)式变化的Ped进行比较, 小于Ped的细菌执行消亡操作, 同时累加所有小于Ped的细菌总数r, 采用随机化佳点集方法生成S个新个体, 按照健康值的优劣排序, 选择较优的前r个细菌作为迁徙-消亡后的新个体, 在解空间按照式(4)初始化, [Xmin, Xmax]为优化区间, X为细菌的初始化位置。
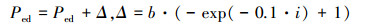
|
(3) |
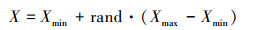
|
(4) |
7) 判断。若循环结束, 则输出结果, 否则跳转至步骤4), 继续执行直至符合终止条件。
3 基于快速的变概率细菌觅食的AdaBoost弱分类器优化权重在基于快速的变概率细菌觅食的AdaBoost算法中, 样本在样本搜索空间中找到最佳弱分类器, 通过优化弱分类器权重来提高训练速度与精度。弱分类器的加权系数优化不仅仅与误差率有关, 在利用AdaBoost算法时主要实现的是分类识别作用, 故组合成强分类器时也应考虑到弱分类器的可靠性及对正样本的识别能力。在本文中, 为了将识别率和可靠性同时考虑进去, 故设正样本的拒绝率为δ, 该拒绝率的取值是由被错误分类的正样本占总样本的百分比决定。
3.1 训练弱分类器流程算法流程如下:
1) 输入训练样本集S, 初始化样本权值w1, i。
2) Do for t=1, 2, …T
① 利用随机化佳点集方法初始化样本集个体的位置与速度, 并计算每个样本的初始化适应度值。
② 根据样本误差公式求得εt。
③ 对于每个样本将其适应函数值与其趋化过程中经过的个体最佳位置Pbest比较, 确定是否替换最佳位置值, 否则保持个体经历过的最佳位置值不变; 同时将适应值与全局历史最佳位置gbest比较, 较好则选取当前值为最佳位置值, 否则全局历史最佳位置值不变。
④ 进行个体的趋化、复制及迁徙-消亡操作。
⑤ 搜索出一个具有最小εt的弱分类器ft计算弱分类器的权值系数。
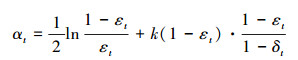
|
(5) |
k为一常数, 0<k<1, 其值满足在第t次循环中使最小误差率的上界下降。
⑥ 更新每个样本对应的权重wt+1, i, 归一化样本权值。
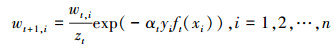
|
(6) |
⑦ 判断。若循环结束, 则输出结果, 否则跳转至②, 继续执行直到符合终止条件。
3) 分类结果输出

|
AD AdaBoost算法[13]考虑弱分类器的权重与错误率及对正样本的识别能力有关, 有效地降低了分类器在低FRR端的FAR。本文通过对传统算法和已改进算法的分析, 提出弱分类器的权值不仅与错误率及对正样本的识别能力有关, 还应与弱分类器的可靠性有关。通过对求解加权系数的方式作以改进, 经过理论分析和实验验证, 得出该算法的求解方式比传统AdaBoost算法的求解方式效率有了更大的提升。下面证明本文算法通过改善样本H(xi)值的分布来改进弱分类器的分类性能。已知可靠性=识别率/1-拒绝率,为同时考虑分类器对正样本的识别能力及可靠性, 在此用识别率乘以可靠性。
令

|
(7) |
该式右端第一项与AdaBoost算法的形式一致, 故只考虑后一项, 令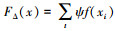
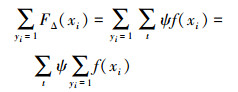
|
(8) |
对应的负样本

|
(9) |
np和nn分别表示样本集中正样本数和负样本数, 则在t次循环中, 识别错误的正样本数为(np+nn)δ, 识别正确的正样本数表示为np-(np+nn)δ, 故

|
(10) |
将(10)式代入(8)式得

|
(11) |
第t个弱分类器识别错误的样本总数(np+nn)ε, 则识别错误的负样本数表示为(np+nn)ε-(np+nn)δ, 识别正确的负样本数为nn-[(np+nn)ε-(np+nn)δ]。故
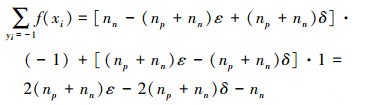
|
(12) |
在训练过程中, 要求εt<0.5, 故

|
(13) |
综合(9)式、(11)式及(13)式得到

|
(14) |
通过理论分析得到, 该求解方式能够满足检测条件, 并且能够保证正负样本具有更好的分布。图 1给出了传统AdaBoost算法以及本文算法在Heart数据集[14]中的F(xi)分布的对比。

|
| 图 1 正负样本权重对比图 |
由图 1可以看出本文算法下正负样本分布能更好的向外延伸, 且FAR值低于传统AdaBoost算法下的值, 说明本文算法的改进效果更胜一筹, 在符合FRR要求的阈值处具有更低的FAR。
4 实验与分析为了验证本文算法的改进效果, 在UCI数据集上选取4组实验数据集, 分别为Diabetis、Heart、Segment、Yeast。该4个数据集均选择200个训练样本和100个测试样本(实例数目范围是303~2 308, 属性范围是8~75)。在MATLAB上应用传统AdaBoost算法和本文改进算法进行实验, 选用SVM作为基分类器, 设置算法的迭代次数为65次, 趋化次数取10, 复制次数取4, 迁徙-消亡次数取4, 样本实验数据集如下表 1所示。
| Data Set | #Instances | #Attributes |
| Diabetis | 1 151 | 20 |
| Heart | 303 | 75 |
| Segment | 2 308 | 20 |
| Yeast | 1 484 | 8 |

|
| 图 2 Diabetes检测情况比较 |

|
| 图 3 Heart检测情况比较 |

|
| 图 4 Segment检测情况比较 |

|
| 图 5 Yeast检测情况比较 |
由以上实验结果分析得到, Diabetis、Yeast 2种数据集在初始训练时误检率相同, 随着迭代次数的增加, 误检率降低得更快, 在精度一定的情况下, 训练次数更少; Heart数据集的检测结果可以看出在初始时本文算法的误检率明显低于传统AdaBoost算法; 而Segment数据集上的检测结果显示在初始时误检率高于传统算法, 经过训练次数的不断增加, 误检率得到明显改善。通过分析得出, 针对不同数据集, 改进算法的误检率随着迭代次数增加而不断降低, 最终达到一个稳定值, 且收敛速度相比较传统AdaBoost算法降低的更快, 说明改进算法更具高效性。同时, 在误检率相同时, 改进算法训练出的弱分类器数目少于传统AdaBoost算法, 说明在相同精度下本文算法的强分类器级联数较少, 其运算速度更快, 从而泛化能力更强。本文对所选弱分类器的加权系数作以改进, 同时考虑错误率、对正样本的识别能力及弱分类器的可靠性, 使得每轮训练中在注重错分类样本的同时, 提高对正样本的正确分类能力, 结合实验结果得出算法的检测精度与速度得到明显提高。
5 结论本文结合细菌觅食优化算法及AdaBoost算法的优缺点, 将改进的细菌觅食算法结合AdaBoost算法来优化弱分类器权重, 对提出的算法进行了严密的理论分析和实验验证, 结果表明本文改进算法比传统AdaBoost算法具有较高的分类性能。现今各种改进的AdaBoost算法在人脸识别方面已取得了较大的成功, 此类问题涉及二分类问题, 在接下来的工作中, 将本文改进算法应用于人脸检测中验证该算法的高效性, 后续工作中将该算法推广至多分类问题中, 实现识别分类功能。
| [1] | Freund Y, Schapire RE. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting[C]//COLT'95 Proceedings of the Second European Conference on Computational Learning Theory, 1995:23-37 |
| [2] |
钱志明, 徐丹. 一种Adaboost快速训练算法[J]. 计算机工程, 2009(20): 187-188.
Qian Zhiming, Xu Dan. Fast Adaboost Training Algorithm[J]. Computer Engineering, 2009(20): 187-188. DOI:10.3969/j.issn.1000-3428.2009.20.066 (in Chinese) |
| [3] |
李文辉, 倪洪印. 一种改进的Adaboost训练算法[J]. 吉林大学学报, 2011(3): 498-504.
Li Wenhui, Ni Hongyin. An Improved Adaboost Training Algorithm[J]. Journal of Jilin University, 2011(3): 498-504. (in Chinese) |
| [4] |
刘王胜, 冯瑞. 一种基于AdaBoost的人脸检测算法[J]. 计算机工程与应用, 2016, 52(11): 209-214.
Liu Wangsheng, Feng Rui. Face Detection Method Based on AdaBoost Algorithm[J]. Computer Engineering and Applications, 2016, 52(11): 209-214. DOI:10.3778/j.issn.1002-8331.1511-0340 (in Chinese) |
| [5] |
付忠良, 张丹普, 王莉莉. 多标签AdaBoost算法的改进算法[J]. 四川大学学报, 2015(5): 103-109.
Fu Zhongliang, Zhang Danpu, Wang Lili. Improvement on AdaBoost for Multi-Label Classification[J]. Journal of Sichuan University, 2015(5): 103-109. (in Chinese) |
| [6] |
李睿, 张九蕊, 毛莉. 基于AdaBoost的弱分类器选择和整合算法[J]. 兰州理工大学学报, 2012(2): 87-90.
Li Rui, Zhang Jiurui, Mao Li. AdaBoost-Based Selection of Weak Classifier and Its Conformation Algorithm[J]. Journal of LanZhou University of Technology, 2012(2): 87-90. (in Chinese) |
| [7] |
Milan Sonka, Vaclav Hlavac, Roger Boyle. 图像处理、分析与机器视觉[M]. 兴军亮, 译. 4版. 北京: 清华大学出版社, 2016: 269-271 Milan Sonka, Vaclav Hlavac, Roger Boyle. Image Processing, Analysis, and Machine Vision[M]. Xing Junliang, Translator.4th Edition. Beijing, Tsinghua University Press, 2016:269-271(in Chibnese) |
| [8] |
翟中华. 基于肤色和Adaboost算法的人脸检测方法研究[D]. 广州: 华南理工大学, 2012 Qu Zhonghua. Research of Face Detection Based on Skin Color and Adaboost Algorithm[D]. Guangzhou, South China University of Technology, 2012(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10141-2009115873.htm |
| [9] |
郭乔进, 李立斌, 李宁. 一种用于不平衡数据分类的改进AdaBoost算法[J]. 计算机工程与应用, 2008, 44(21): 217-221.
Guo Qiaojin, Li Libin, Li Ning. Novel Modified ADA Boost Algorithm for Imbalanced Data Classification[J]. Computer Engineering and Applications, 2008, 44(21): 217-221. DOI:10.3778/j.issn.1002-8331.2008.21.059 (in Chinese) |
| [10] | Hanning Chen, Yunlong Zhu, Kunyuan Hu. Self-Adaptation in Bacterial Foraging Optimization Algorithm[C]//Proceedings of the 3rd International Conference on Intelligent System and Knowledge Engineering, 2008:1026-1031 |
| [11] |
周佳薇. 细菌觅食优化算法研究及其在图像增强中的应用[D]. 西安: 西安电子科技大学, 2014 Zhou Jiawei. Research on Bacterial Foraging Optimization Algorithm and its Application in Image Enhancement[D]. Xi'an, Xidian University, 2014(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10701-1015429286.htm |
| [12] |
张弛. 基于粒子群的AdaBoost算法及其在人脸检测中的应用研究[D]. 武汉: 华中师范大学, 2010 Zhang Chi. Study for AdaBoost Algorithm Based on PSO and its Application in Human Face Detection[D]. Wuhan, Huazhong Normal University, 2010(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10511-2010136516.htm |
| [13] |
李闯, 丁晓青, 吴佑寿. 一种改进的AdaBoost算法——AD AdaBoost[J]. 计算机学报, 2007(1): 103-109.
Li Chuang, Ding Xiaoqing, Wu Youshou. A Revised AdaBoost Algorithm——AD AdaBoost[J]. CHinese Journal of Computers, 2007(1): 103-109. (in Chinese) |
| [14] |
张亮, 李智星, 王进. 基于动态权重的AdaBoost算法研究[J]. 计算机应用研究, 2017(11): 1-6.
Zhang Liang, Li Zhixing, Wang Jin. Research on Dynamic Weights Based AdaBoost[J]. Application Research of Computers, 2017(11): 1-6. (in Chinese) |
2. Gansu Provincial Key Laboratory of Traffic Information Engineering and Control, Lanzhou 730070, China
