

2. 中国人民解放军 第五七一九工厂, 四川 彭州 611937
软件测试是在软件开发过程中,用以保证软件质量的重要手段。而测试用例大量冗余的压缩是软件测试面临的一个重要难题。测试用例集之所以会出现冗余,是因为覆盖某一测试目标的数据,往往可以也同时覆盖其他测试目标。在回归测试中,人们会根据新的测试需求,不断补充大量的测试用例,这也会造成测试用例冗余的产生。虽然现在有很多工具通过重用测试用例集来降低回归测试的成本,但回归测试依然可能是极其耗时的过程。现已发现,在某些情况下,回归测试花费的时间需要高达7周的时间[1]。另外,现在软件项目多以迭代开发的方式开发,回归测试是必不可少的环节。在这种情况下,回归测试所花费的代价可能是一个重要的指标。因此,如果能够根据既定的测试充分性规则对已有的测试用例集进行约简,将会大大减少测试用例集的冗余度,从而提高软件测试的效率。
一般而言,测试用例集缩减的基本原理是:按照给定测试准则,找到当前测试用例集的一个子集,使得其同样能够覆盖原来的测试目标,即该子集成为原有测试数据集的代表集。如果一个测试用例集的任何真子集都不能满足既定的测试准则,则称该测试用例集为最优集或者最小集。
近年来,已有很多关于压缩测试用例集的研究成果。Leung和White证明,寻找测试用例集的最小化子集是一个NP-Hard问题,因此,仅能找到该问题的近似最优解。Harrold等人提出了一种启发式算法HGS,该方法的核心思想是尽早选出更多的基本测试用例。Chen和Lau提出了另一种启发式算法GRE算法[2],该方法不断应用如下3种策略,直到满足所有的测试目标:① 选择所有的测试用例;② 移除所有的一对一的冗余测试用例;③ 选择更多覆盖测试目标的测试用例。其中应用策略③ 时,需要保证策略① 和② 均成功应用结束。Lin和Huang[3]对Harrold等提出的方法进行了改进,其思路是根据测试用例的优先级对测试用例集进行缩减。大量的实验表明,该方法能够有效地缩减测试用例集。
与测试用例缩减相关的工作是测试用例的选择和测试用例的优先排序。前者主要是面向回归测试,侧重点在于代表集能否覆盖程序中被修改的部分[4];而后者则在特定的排序规则下,寻找测试用例集执行的最佳顺序,实验结果表明,测试用例优先排序可以尽早发现程序中尽可能多的错误[5]。Walcott等[6]使用遗传算法同时解决测试用例集选择和优先级排序的问题。Li等[7]使用了贪心算法和一组启发式算法解决了优先级排序问题。
此外,还有许多学者使用多目标优化方法来解决测试用例集缩减问题。例如Yoo和Harman[8]提出了一种基于帕累托(Pareto)优化的多目标测试用例集缩减方法。优化的目标有语句覆盖率、测试用例的排错记录及执行该测试用例所花费的时间等。Hsu和Orso[9]采用整数线性规划方式进行测试用例集的缩减,在缩减时可以支持任意多个优化目标。
上述方法虽然在一定程度上减少了测试用例集的数量,但是并没有特别关注缩减后测试数据集的缺陷检测能力是否下降,而缺陷检测能力是衡量测试数据集质量的一个重要指标。如果测试数据集的缺陷检测能力降低,即使测试用例集的个数减少了,也会对测试工作造成负面影响。为此,本文引入了变异分析和业界标准的覆盖准则来建立测试用例缩减问题的数学问题,并采用进化优化方法求解上述优化模型,以期有效降低测试数据的冗余度,提高软件测试的效率。
1 测试用例集缩减为多目标优化问题1.1 问题描述测试用例集多目标优化,旨在根据在测试中的多重优化准则,在可行测试用例集合中选取一组帕累托有效子集。通过对帕累托最优理论的探讨,可将多目标测试用例集最优化的问题可以抽象为如下描述:
1) 给定:一组测试用例集合T及一组n个目标的函数y={f1(x), f2(x), …, fn(x)}。
2) 问题:寻求一组测试用例集合T的子集T′,使得该子集在目标函数的约束下取得帕累托最优。此问题中的多目标函数即为测试人员所关心的优化准则的数学描述。
在y={f1(x), f2(x), …, fn(x)}中。当T的子集t1优超时,即为决策向量t1优超决策向量t2。优化取得的最终结果,即T的帕累托最优子集T′,即可取得回归测试优化准则中所预期的目标,从而达到测试用例集缩减的目的。
1.2 使用的目标函数缩减测试用例集目的在于减少冗余,以提高测试效率。如果在对测试数据进行缩减时,测试用例集的缺陷检测能力下降,同样会给测试带来负面影响。因此,缩减后的测试用例集应能满足既定的测试充分性准则,以保证其缺陷检测能力不会大幅度降低。
变异测试是一种面向缺陷检测的软件测试技术,通过人工分析方法对程序注入缺陷,以模拟真实的缺陷[10]。研究结果表明,变异缺陷能够在很大程度上反映软件的真实缺陷。变异测试通过测试数据集发现这些变异缺陷的个数,对其完备性进行评价。与其他结构化测试准则相比,满足变异测试准则的测试数据集具有更高的缺陷检测能力。因此,把测试用例集所满足的变异测试充分性准则作为一个基本目标,以保证其缺陷检测能力。变异测试包括3个主要环节:① 对原程序进行合乎语法的微小变动,并生成若干个变异体,对应的语法变动规则称为变异算子;② 某测试用例集分别运行原程序和变异体,如果变异体运行结果不同于原程序的运行结果,则成为变异体被杀死;③ 通过变异评分对测试结果进行评价。如果测试用例集的缺陷检测能力不下降,则意味着缩减后的测试用例集和原测试用例集的变异评分相同。设程序P包含的变异体集合为M,如果测试用例集T′能够杀死M中K个变异体,则T′的的变异评分为:
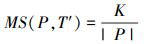
|
(1) |
因为测试用例集缩减的主要目的是降低回归测试的成本,所以对测试用例所花费的时间也将作为一个基本目标。对于成本,采用(Valgrind)来估计测试用例的执行时间,并使用这个时间作为执行测试用例的成本。
另外,附加的3个目标对应于基本的结构测试覆盖的度量。主要有语句覆盖:测试用例执行所覆盖程序语句的百分比;分支覆盖:测试用例执行所覆盖程序分支的百分比;MC/DC覆盖:在测试充分性上要强于判定或条件的覆盖准则。其在满足判定/条件覆盖准则基础上,还需额外证实判定语句中的每个条件可独立影响判定取值。
本文将选取几种目标的组合:三目标组合、四目标组合以及五目标组合。三目标组合选取语句覆盖率、执行花费的时间以及变异得分,四目标组合则是选取语句覆盖率,执行花费的时间、分支覆盖率以及变异得分。五目标组合则是在四目标的基础上新增MC/DC覆盖率。
设已给程序p和测试用例集T={t1, …, tn },变异体集合M={m1, …, mn },程序p对于每一个测试用例t1i(1≤i≤n),并假设:τ(ti)是ti测试用例执行程序p花费的时间,s(ti)是以测试用例ti执行程序p覆盖的语句集合,b(ti)是以测试用例ti执行程序p覆盖的分支集合,m(ti)是以测试用例ti执行程序p覆盖的MC/DC集合,ms(ti)是以测试用例ti杀死程序p的变异体集合。设已给定T′⊆T,则可将各个目标的分别描述如下:
1) 总执行时间花销:

|
(2) |
2) 总语句覆盖率
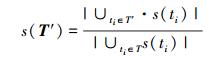
|
(3) |
3) 总分支覆盖率
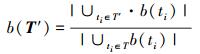
|
(4) |
4) 总MC/DC覆盖率
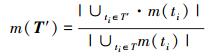
|
(5) |
5) 总变异评分比值

|
(6) |
显然,我们希望第一个目标值越小越好,而其余目标值越大越好。
2 核心算法下面采用遗传算法来求解测试用例集缩减问题。在算法实现上,首先将待缩减的测试用例集用一个01序列表示,若第i位的值为1,表示第i个测试用例被选中,当第i位的值为0,表示第i个测试用例未被选中。以下是算法实现的主要步骤:
Step1 设置进化优化遗传算法相关参数的值,包括种群规模、目标个数、交叉和变异的概率、评价和迭代的次数等。
Step2 初始化种群。
Step3 判断算法是否满足终止条件,若是,则跳转到Step6。
Step4 计算个体适应度函数值。
Step5 实施交叉和变异操作,生成下一代种群,并转到Step3。
Step6 终止进化,输出有效的测试用例集。
3 实验配置3.1 遗传算法本文将选用3种遗传算法来对本文所提出的方法予以验证:NSGA-Ⅱ(精英保留的非劣排序遗传算法)、IBEA(基于指标的遗传算法)、MOEA/D(基于分解的多目标进化算法)[11]。其中,NSGA-Ⅱ是NSGA(非劣排序遗传算法)的改进算法,有效地将NSGA的计算复杂度从0(mN3) 降至0(mN2),从而进一步提高算法的计算效率和鲁棒性。IBEA是一种通用多目标遗传算法,该算法首次将评价指标函数作为适应度评价方法嵌入到遗传算法中。MOEA/D同时优化多个子问题而不是直接将多目标优化问题作为一个整体来解决,那么对于传统的非分解式多目标优化算法来说,分配适应度和控制多样性的难度将在MOEA/D框架中得到降低。
3.2 实验数据集本文采用Siemens suit数据集中的4个程序进行实验。采用的实验程序来自于software artifact infrastructure repository(SIR), 分别是tcas(防止航空器相撞的系统)、schedule(一种优先调度器)、tot-info(针对指定的输入数据生成统计信息)以及space(数组定义语言的解释器)。这些程序被广泛应用于各种测试方法的有效性验证实验。被测程序的基本信息如表 1所示。
| 序号 | 程序 | 代码行数 | 测试用例个数 |
| 1 | tcas | 1 608 | 1 608 |
| 2 | schedule | 2 650 | 2 650 |
| 3 | tot-info | 1 052 | 1 052 |
| 4 | space | 6 199 | 13 585 |
考虑遗传算法本身具有的随机性,故文章采用的3种遗传算法对于每一个实验在相同的条件下重复执行20次。
文章采用的3种遗传算法中个体的均采用0-1编码。具体个体变色体表示为长度为m的二进制串(m的取值决定于被测程序测试用例的个数),取值为1表示选中该测试用例,反之取0。算法中使用常用的交叉和突变操作:平均交叉和比特翻转突变。其中交叉概率pc=0.1,突变概率pm=1/n(n是决策变量的个数)。
其中4个实验程序的初始种群均为100。每个程序产生的变异体个数和进化代数设置如表 2所示。
| 程序 | 缺陷个数 | 种群数 | 最大进化数 |
| tcas | 71 | 100 | 80 000 |
| schedule | 41 | 100 | 80 000 |
| tot-info | 53 | 100 | 80 000 |
| space | 98 | 100 | 80 000 |
HV指标[12]是一种解集综合质量评价指标,该指标可以对解集的收敛性、均匀性和广泛性同时进行评价,并能够给出解集的综合评价结果,该指标广泛运用在多目标优化评估方面。HV指标的数学描述为:设e为种群P中个体,仅被e支配的区域称为e的独立支配区域。令A为非支配解集,且A∈Ω,参考点记为Ref=(r1, r2, …, rk)∈Y,则A的HV指标可以由解集A中的所有点及其参考点在目标空间中所形成的超立方体的体积表示,该体积公式如(7) 式所示:
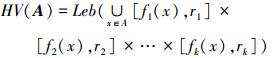
|
(7) |
式中,Leb(A)表示解集A的勒贝格测度,[f1(x), r1]×[f2(x), r2]×…×[fk(x), rk]表示被x支配而不被Ref支配的所有点围成的超立方体。由此可见,当集合的HV指标最大化时,该集合为帕累托最优解。
为了不同算法实验结果的比对,我们提供了标准的HV值,它是每一个算法HV值与最佳结果的HV值的比值。标准的HV值的取值范围在[0, 1]。其中1表示最佳值。由于不能通过计算获得问题的最佳HV值,我们将结果集混合后估计最优值。
4 实验结果与分析为了消除随机性的影响,HV评估指标对遗传算法20次执行结果进行评价,并统计其平均值进行分析比较。这里将会比较小型SIR程序和space的程序的实验结果。然后对3种算法的5个运算结果进行两两比较,并通过Bonferroni校正获取2个算法之间的p-value。
对于小型SIR程序,表 3表示在三目标的情况下不同算法的标准化HV的值。在表 3中我们可以看出NSGA-Ⅱ和MOEA/D明显比IBEA算法更加有效(p-value 0)。当然,NSGA-Ⅱ算法是最有效的。表 4表示在四目标的情况下不同算法的标准化HV的值。在表 4中可以看到,IBEA总是得到最低的标准化HV的值(对于所有的比较p-value 0)。与三目标的情况相似,NSGA-Ⅱ仍然是最有效的。但是MOEA/D-PBI和MOEA/D-WS在tot_info程序的结果并没有明显差异(p-value 0.401)。表 5表示在五目标的情况下不同算法的标准化HV的值。类似地,IBEA总是得到最低的标准化HV的值,NSGA-Ⅱ总是表现的最佳。综上所述,比较所有的实验结果可知,NSGA-Ⅱ的HV值普遍最优,而IBEA的HV值通常最低。对于MOEA/D算法,MOEA/D-PBI总是比MOEA/D-TCH和MOEA/D-WS表现地更加有效。
| 算法 | tcas | tot-info | schedule |
| IBEA | 0.180 198 | 0.201 014 | 0.320 396 |
| MOEA/D-PBI | 0.998 968 | 0.997 991 | 0.998 433 |
| MOEA/D-TCH | 0.963 383 | 0.973 234 | 0.832 326 |
| MOEA/D-WS | 0.973 733 | 0.981 369 | 0.886 112 |
| NSGA-Ⅱ | 1.000 000 | 0.999 984 | 0.999 412 |
| 算法 | tcas | tot-info | schedule |
| IBEA | 0.138 366 | 0.138 963 | 0.241 152 |
| MOEA/D-PBI | 0.999 032 | 0.998 415 | 0.998 620 |
| MOEA/D-TCH | 0.712 001 | 0.816 236 | 0.652 095 |
| MOEA/D-WS | 0.982 946 | 0.998 409 | 0.989 736 |
| NSGA-Ⅱ | 1.000 000 | 0.999 988 | 0.999 995 |
| 算法 | tcas | tot-info | schedule |
| IBEA | 0.120 208 | 0.171 396 | 0.110 158 |
| MOEA/D-PBI | 0.998 952 | 0.997 328 | 0.998 362 |
| MOEA/D-TCH | 0.935 984 | 0.996 585 | 0.893 080 |
| MOEA/D-WS | 0.962 149 | 0.997 245 | 0.970 386 |
| NSGA-Ⅱ | 0.999 965 | 0.999 927 | 0.999 948 |
对于space程序,表 6给出三目标组合下不同算法标准化HV的值。明显看出,MOEA/D-PBI比NSGA-Ⅱ略有效。
| 算法 | space |
| IBEA | 0.733 022 |
| MOEA/D-PBI | 0.999 295 |
| MOEA/D-TCH | 0.912 298 |
| MOEA/D-WS | 0.927 719 |
| NSGA-Ⅱ | 0.976 187 |
此外,为了研究在优化过程中遗传算法的性能如何变化,图 1绘制了NSGA-Ⅱ和MOEA/D-PBI对三目标tcas问题的运行的300 000个评价中的标准化HV值的轨迹。在不同目标的其他程序问题上也观察到类似的结果。如图 1所示,2种算法的标准化HV值轨迹在进化的初始阶段快速增加,并在大约80 000次评估时达到最佳值。这意味着进化算法能够在80 000评估值中良好收敛。

|
| 图 1 NSGA-Ⅱ和MOEA/D-PBI对三目标tcasHV值 |
测试用例集的冗余不仅会浪费大量的测试时间,并且还占用了软件测试资源,给软件测试所谓成本带来极大的挑战。本文给出了一种将变异分析和覆盖准则相结合的方式来解决测试用例集缩减方案,其中采用了多目标优化方法来进行求解,目标选取了时间开销、语句覆盖率、分支覆盖率、MC/DC覆盖率以及变异评分。变异评分用于检验测试用例集在被测程序故障能力的有效性。在实验中,应用了3种多目标进化算法进行实验验证,实验的评价指标采用HV值比较不同算法的结果集。实验结果表明,该方法在保证测试覆盖率和变异评分准确性的情况下,能有效地缩减测试用例集。对SIR小程序而言,NSGA-Ⅱ的HV值普遍最优,而IBEA的HV值通常最低。对于space程序,MOEA/D-PBI比NSGA-Ⅱ更有效,而IBEA的HV值仍然最低。
| [1] | Elbaum S, Malishevsky A G, Rothermel G. Test Case Prioritization:a Family of Empirical Studies[J]. IEEE Trans on Software Engineering, 2002, 28(2): 159-182. DOI:10.1109/32.988497 |
| [2] | Chen T Y, Lau M F. A New Heuristic for Test Suite Reduction[J]. Information & Software Technology, 1998, 40(5): 347-354. |
| [3] | Lin J W, Huang C Y. Analysis of Test Suite Reduction with Enhanced Tie-Breaking Techniques[J]. Information & Software Technology, 2009, 51(4): 679-690. |
| [4] | Orso A, Harrold M J, Rosenblum D, et al. Using Component Metacontent to Support the Regression Testing of Component-Based Software[J]. 2001:716-725 |
| [5] | Elbaum S G, Malishevsky A G, Rothermel G. Prioritizing Test Cases for Regression Testing[C]//Proceedings of the ACM/SIGSOFT International Symposium on Software Testing and Analysis, 2000:102-112 |
| [6] | Walcott K R, Soffa M L, Kapfhammer G M, et al. TimeAware Test Suite Prioritization[C]//ACM/SIGSOFT International Symposium on Software Testing and Analysis, 2010:849-853 |
| [7] | Li Z, Harman M, Hierons R M. Search Algorithms for Regression Test Case Prioritization[J]. IEEE Trans on Software Engineering, 2007, 33(4): 225-237. DOI:10.1109/TSE.2007.38 |
| [8] | Yoo S, Harman M. Using Hybrid Algorithm for Pareto Efficient Multi-Objective Test Suite Minimisation[J]. Journal of Systems & Software, 2010, 83(4): 689-701. |
| [9] | Hsu H Y, Orso A. MINTS; A Ueneral Framework and Tool for Supporting Test-Suite Minimization[C]//Proceedings of the International Conference on Software Engineering, 2009:419-429 |
| [10] |
陈锦富, 卢炎生, 谢晓东. 软件错误注入测试技术研究[J]. 软件学报, 2009, 20(6): 1425-1443.
Chen Jinfu, Lu Yansheng, Xie Xiaodong. Research on Software Fault Injection Testing[J]. Journal of Software, 2009, 20(6): 1425-1443. (in Chinese) |
| [11] | Hierons R M, Li M, Liu X, et al. SIP:Optimal Product Selection from Feature Models Using Many-Objective Evolutionary Optimization[J]. ACM Trans on Software Engineering & Methodology, 2016, 25(2): 17. |
| [12] | Brockhoff D, Friedrich T, Neumann F. Analyzing Hypervolume Indicator Based Algorithms[J]. Lecture Notes in Computer Science, 2008, 5199(2008): 651-660. |
2. The No. 5719 Factory of PLA, Pengzhou 611937, China
