

人体行为识别是机器视觉、模式识别、图像处理领域中一个非常重要的研究方向。在复杂场景下(背景扰动、光流变化、视角移动)的人体行为识别已逐渐成为研究热点。与其他图像识别方法相似,人体行为识别可以大致分为:图像显著区域检测、底层人体特征提取和人体运动表征、简单动作识别、高层复杂行为抽象和复杂场景理解等基本过程。一些经典的人体行为识别算法(如Rober等[1]提出的基于HMM的行为识别方法,HMM是一种常用于人体行为识别的建模方法),并涉及到行为理解。Vasu等[2]提出二维视角不变空间,以解决行为识别的视角问题。Li[3]提出使用光流方向直方图描述人体行为的方法,这些方法都已在简单场景下取得了理想的识别效果。复杂场景下目标检测和特征提取过程受到遮挡、背景、视角和光线变化等因素的影响,已成为一项具有挑战性的工作。
虽然复杂场景下不同的人体行为识别算法所采用的识别策略不同,但其关注点多集中在复杂场景下的目标检测和行为理解,以及基于视频序列的时空信息分析解算。例如,Laptev[4]将Harris角点扩展到三维空间,这些时空特征点邻域的像素值在时间和空间都有显著变化,并能够自适应时间维和空间维。Dollar等[5]则指出上述算法存在一种缺陷,即检测出来的稳定有效兴趣点数量太少,进而提出改进方法,先分别在时间维和空间维进行Gabor滤波, 使得被检测到的兴趣点数目会随着时间和空间局部尺度的改变而变化,并且满足对兴趣点的数量需求。Park等[6]提出了一种基于贝叶斯网络的个体姿态估计方法,对个体行为建模,最后模拟出一种交互行为决策树,进行行为分类。将兴趣点检测应用于复杂场景下,会产生大量的背景兴趣点。这些无用的兴趣点会增加系统计算成本和行为识别的错误率。针对这个问题,Bregonzio等[7]提出了将时空兴趣点作为人体行为识别的特征描述子。通过计算前后一帧的不同,来估计视觉注意的焦点,然后利用Gabor滤波在这些子区域来检测显著点。基于全局或局部特征的时空兴趣点检测方法,各有利弊,都在一定程度上取得了不错的实验效果,但依然不能很好解决复杂背景下的人体目标识别和行为理解问题。
针对上述方法中存在的问题和不足,本文在传统2D-Harris角点检测算法的基础上做出改进,将多尺度信息引入Harris检测中,通过冗余点剔除、空间尺度选择、时间尺度抑制方法,极大减少了背景兴趣点的产生,提高了图像处理速度,减轻了计算负担,对光线变化、物体遮挡、复杂背景具有良好的适应能力。图 1是传统兴趣点检测和本文算法处理过后的兴趣点分布对比图。场景选择在较为复杂的人体行为数据库Hollywood2中,经过冗余点剔除、时空抑制的兴趣点能够较为准确地定位运动人体附近的重要信息,并且将无关兴趣点剔除,可极大提高特征提取速度和目标检测精度。

|
| 图 1 复杂场景中人体目标兴趣点检测优化对比 |
本文采用基于码本的Bag-of-words模型和HOG算子,对处理过的时空兴趣点进行特征提取。这种方法最初被应用在图像检索算法中,后来逐渐形成“视觉词汇”的概念。本文使用HOG算子提取局部特征向量;然后使用AIB贪婪算法对特征向量进行合并,得到具有旋转不变性的“视觉词汇”。这些“视觉词汇”作为一个整体构成字典;最后使用SVM进行训练,得到Bag-of-words特征分类模型,对待测图像提取相应的特征进行行为类别预测。为了验证本文方法的有效性,我们选用目前一些较权威的人体行为识别数据库,如KTH人体行为数据库、罗切斯特大学的Activities of Daily Living数据库、UCF、Hollywood场景数据库,YouTube行为识别数据库等进行实验。
1 改进时空兴趣点检测算法 1.1 冗余点剔除基于局部特征的时空兴趣点检测方法在应对移动背景、光流场变化、视角变化等情况时,展现了其优越的性能。但是,由于传统Harris角点检测中不包含尺度信息,其检测结果中包涵大量无用的背景信息点。Yaron等[8]利用图像边缘滤波对图像序列进行检测。在一次目标检测实验中,有近82%的兴趣点属于背景兴趣点;只有约18%的兴趣点是不需要进行背景抑制处理的有效兴趣点。大量无用的干扰数据会增加计算量,影响目标识别精度。图 2a)~图 2d)分别是在罗切斯特大学的Activities of Daily Living数据库、UCF人体运动数据库、Hollywood2场景数据库、KTH基准数据库上进行传统兴趣点检测的结果,检测到大量无用的兴趣点。兴趣点检测与显著区域检测的目的相似,都希望获得更少的兴趣点以及更准确的区域划分,为后期特征提取和行为识别提供有效的数据支持。

|
| 图 2 不同数据库进行传统兴趣点检测,产生大量无用兴趣点 |
为了解决这一问题,本文提出了一种基于改进的Harris-Laplace算法进行时空兴趣点采集,对采集到的兴趣点进行冗余点剔除,以提高特征提取效率和准确度。Harris角点检测对光线和对比度的改变具有鲁棒性,但对尺度变化敏感。不同的尺度空间是通过输入视频序列与不同低通滤波器进行卷积得到的。在实际运算中,以变换高斯核函数尺度因子获得滤波器然后与视频序列卷积得到不同尺度空间的图像序列。
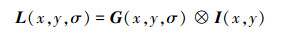
|
(1) |
式中,L(x, y, σ)表示尺度空间, I(x, y)表示输入图像, G(x, y, σ)为带有尺度因子σ的高斯核函数, 多尺度高斯核函数G(x, y, σ)为
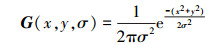
|
(2) |
式中,σ为尺度因子, Harris-Laplace多尺度检测自相关矩阵为M=μ(x, y, σI, σD)
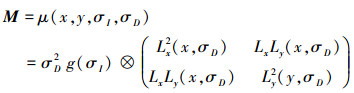
|
(3) |
式中,x, y代表图像的像素坐标, σI为积分尺度, σD为微分尺度。一般σI=sσD, 通常可设定经验值s=0.6。多尺度Harris检测每个尺度空间图像上点的响应值
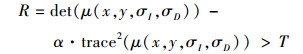
|
(4) |
式中,α=0.04-0.06, T为阈值用来控制提取角点的数目, R越大越有可能是角点。局部检测得到的特征点会随着尺度变化向着梯度方向发生位移, 这种改变是非常微小的, 且表达相似的局部特征结构。这样就产生了非常多表达相同结构、差异很小的冗余点, 这些冗余点增加了计算量。本文提出一种在各尺度候选点中选择最具代表性特征点的方法, 具体算法如下:

|
| 图 3 基于改进时空兴趣点检测的人体行为识别算法流程图 |
Step1 多尺度兴趣点检测。首先对输入视频帧按照公式(1)进行不同尺度上的高斯滤波生成尺度空间L(x, y, σ)。然后按照公式(4)多尺度响应值检测算法设定阈值, 将响应值大于设定阈值的兴趣点作为候选兴趣点。
Step2 构建选择矩阵。构建候选兴趣点响应矩阵M(m, n)和候选点尺度矩阵K(m, n), 初始化M(x, y)=0, K(x, y)=0。将检测到的兴趣点响应值和对应尺度赋给M(x, y)与K(x, y)。
Step3 兴趣点筛选。利用半径为3的像素统计滤波器, 对候选兴趣点矩阵进行滤波, 通过比较领域内候选点响应值, 得到半径阈值范围内响应最大值MaxValue1和次最大值MaxValue2的候选点。对Step1中的每一点(x, y)在不同尺度下得到的兴趣点进行判断。如果对应区域的响应值MaxValue2>T(阈值)且满足区域点属于M(m, n)则保留, 不满足对应位置清0。这样最终保留下来的兴趣点组成了候选兴趣点矩阵。
通过上述方法的改进, 在兴趣点检测阶段剔除了大量冗余点, 减少了后续特征提取计算量、降低了特征向量分类时的干扰, 提高了图像兴趣点采集精度。
1.2 背景兴趣点抑制本文首先在最终采集到的兴趣点上采用邻域抑制标记(neighborhood suppression label), 然后选出中心点并对周围的领域点进行角点强度响应值评估, 最后通过中心点附近的领域点评估结果来判断是否应该对这个中心点进行抑制。引入影响因子θσ(X, Xu, v)

|
(5) |
式中, θσ(X)和θσ(Xu, v)分别代表点X≡(x, y)和X≡(x-u, y-v)的梯度。u、v分别指代整个邻域的范围尺度。当θσ(X)和θσ(Xu, v)逐渐趋近时, 影响因子逐渐达到最大值, 相互正交时影响因子是最小的。对于每一个中心点Mσ(X), 我们定义权重参数tσ(X)作为梯度值的和
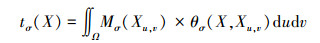
|
(6) |
式中,Ω代表坐标取值范围, 其中β为抑制强度因子, 对候选兴趣点进行邻域抑制
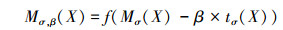
|
(7) |
式中,f为激活函数, 当z≥0, f(z)=z, z < 0时则忽略z值。β在这里用来控制邻域抑制强度, 根据实验得出β在[0.8-1.6]范围内取得最好的抑制效果。当β持续变大时, 抑制效果增强兴趣点数量减少, 最后将获得的兴趣点放入邻域抑制响Mσ, β中。
1.3 时间空间抑制为了进一步移除与运动目标不相关的兴趣点, 需要进行时空兴趣点抑制。本文采用T.Lindeberg的尺度选择算法[9], 其中尺度Sσ=N×σ, 这种方法能够进行多尺度兴趣点优化选择。在目标检测阶段, 为了去除图像中大量的冗余点, 抑制静态兴趣点的产生是一种行之有效的方法。在进行运动目标检测时, 静态兴趣点可以当成背景点进行抑制[10], 静态兴趣点抑制算法为
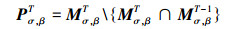
|
(8) |
式中,Mσ, βT是T时刻兴趣点集Pσ, βT为T时刻非静态兴趣点集, 在连续帧T和T-1间去除静态兴趣点。时间约束算法的描述如下:
通过对冗余点的剔除、背景点抑制, 再通过基于空间和时间约束的算法进一步剔除无用静态兴趣点, 最后得到带有尺度信息的运动目标显著区域兴趣点集合。
| 时间约束算法 |
| 输入:(H⊆W⊆N)图像堆栈:iS; |
| 空间角点: cp; |
| 输出:检测到的时空兴趣点 |
| 1. for i=1→H do |
| 2. for j=1→ W do |
| 3. Gabor尺度空间=Gabor滤波器(iS(i, j, :)); |
| 4. end for |
| 5. end for |
| 6. for i=N→2 do |
| 7. f1=iS(:, :, i); f2=iS(:, :, i-1); |
| 8. g1=Gabor(:, :, i); g2=Gabor(:, :, i-1); |
| 9. im1=iS(:, :, i); im2=iS(:, :, i-1); |
| 10. cpf1←cpf1\(cpf1, cpf2, g1, g2, im1, im2); |
| 11. end for |
| 12. return(cp) |
图 4~图 6分别是在不同数据库下使用未经算法优化的兴趣点提取方法与本文兴趣点提取方法的对比。可以看出, 改进后的兴趣点明显减少, 虽然兴趣点数量减少, 但都围绕或者包裹重要目标本身, 这样十分有利于直接进行特征提取。图 6还尝试了更为复杂的生活环境和运动观察视角, 实验结果可以为显著区域预测提供直接帮助, 缩小特征提取区域的搜索范围。

|
| 图 4 KTH数据库中多尺度兴趣点实验结果对比 |

|
| 图 5 YouTube数据库实验结果对比 |

|
| 图 6 移动视角下的人体行为识别实验结果对比 |
梯度直方图特征(HOG)是一种对图像局部重叠区域的密集型描述符, 它通过计算局部区域的梯度方向直方图来构成特征。HOG特征结合SVM分类器已广泛应用于图像识别中, 尤其在行人检测中获得了极大成功。由于在进行人体行为识别时, 单幅图像往往不能对行为进行完整表达, 很多行为动作都是跨越多个视频帧来完成。本文通过时空特征点来描述一个行为。所谓时空特征点, 就是一小段局部视频序列构成的立方体特征空间, 用来描述例如抬手、屈膝等。对一个行为对描述, 就是对一些时空特征点的类型和位置进行描述。本文首先通过背景兴趣点抑制、时空兴趣点约束等方法, 在不同尺度范围内, 筛选得到T时刻的候选兴趣点集Pσ, βT, 然后对每一个兴趣点进行扩展处理, 首先对视频帧按下列公式进行图像梯度计算:
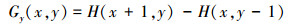
|
(9) |
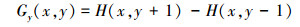
|
(10) |
式中, Gx(x, y)、Gy(x, y)、H(x, y)分别表示输入图像中像素点(x, y)处的水平方向梯度、垂直方向梯度和像素值。像素点在(x, y)处的梯度幅值G和梯度方向α分别为
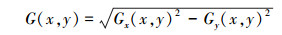
|
(11) |
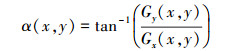
|
(12) |
根据像素点的幅值和方向, 计算梯度投影直方图, 将整个图像帧的梯度直方图保存下来。与传统HOG不同的是, 加入时间轴t作为纵深信息, 构成一个特征立方体。将特征立方体(x, y, t)按照(4:4:3)的比例划分, 分割成一系列小区域。目的在于提高目标识别鲁棒性的同时, 尽量提取更多有用的特征信息。
需要注意的是在这里并不直接使用特征立方体本身充当特征描述子, 不同的人进行相同动作行为时, 外观和运动多少都会有所不同, 特征立方体的数目也不尽相同, 但是特征立方体的类型相对不多。所以在这里将特征立方体映射到一个与它最接近的原型向量上来, 让原型特征立方体来代替与其相近的其他特征立方体。这样数目巨大的特征立方体就被缩减成类型特征立方体, 通过对类型特征立方体进行梯度直方图计算获得特征描述子。
3 建立视觉词汇表和行为分类本文使用BoV模型从局部运动特征中提取视觉词汇, 采用类似金字塔分级特征空间分割方法, 但在这里按时空兴趣点分布进行分层。这样做可以让局部特征分组问题变得简单且具有鲁棒性。最后在每一层中对视觉词汇进行压缩以减少特征空间的维度。
取T时刻视频图像IT, PT代表T时刻兴趣点集。我们将这些兴趣点按照水平或者垂直的方法进行区域划分, 水平方向划分可以帮助进行上肢和下肢的动作识别, 垂直方向划分可以帮助进行左右两侧肢体动作的识别。
这里采用AIB[11]视觉词汇压缩算法, 主要思想是图像分层处理, 对相同分层的视觉单词进行距离计算, 计算公式如下
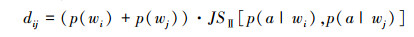
|
(13) |
式中,{wi}和{wj}分别代表相邻的视觉单词, 通过不断迭代方法计算相同分层中不同视觉单词之间的dij, 当dij为最小时,将相应的2个视觉单词进行合并。AIB本质是一种贪婪算法将局部相似词簇进行优化合并,在完成视觉单词的层级压缩之后,计算视觉单词直方图,最后将直方图信息输入SVM中进行学习、训练最后采用打分机制得到不同行为的分类。图 7显示了运用分层结构和词汇压缩对识别率的影响,图 7a)将不同算法组合实验,证明具有分层结构和进行词汇压缩处理的行为识别率更高。图 7b)显示算法在不同数据库上实验的识别率。

|
| 图 7 平均识别率与词汇尺度之间的影响关系 |
为了验证算法有效性,选取KTH人体行为数据库、罗切斯特大学的Activities of Daily Living数据库、UCF、Hollywood场景数据库,YouTube行为识别数据库等进行实验。KTH是行为识别基准数据库,由4种不同场景下25个人分别作出6种不相同的动作:行走、慢跑、快跑、拳击、挥手、拍手,视频总数超过了2 000个[12]。将其中7个人的视频作为训练集使用,再7个人作为验证集,11个人作为测试集,在KTH数据库上本文算法识别率达到了98.65%。
图 5选取更为复杂的YouTube数据库,目标运动速度更快,背景复杂,与真实的环境基本一致,通过对比看到经过算法处理的兴趣点数量大大减少,并且紧密附着在运动目标周围。这样既减轻了计算量,又不会丢失重要目标的信息。随着人体的快速运动,兴趣点坐标不会受到运动、光照、背景纹理的影响而发生漂移。
图 6选取了Hollywood2数据库中的视频片段,目标和镜头都处于运动状态下。时空兴趣点组成的显著区域大量附着在重要运动目标周围,在进行特征提取的时候,可以根据这些兴趣点密度分布利用聚类算法进行重要目标区域预测,建立特征提取区域。表 2展示了本文算法和其他不同算法在KTH、UCF和YouTube数据库上的识别率对比。
| Method | KTH | UCF | YouTube |
| Our approach | 95.58 | 88.48 | 81.90 |
| Kim et al. | 95.31 | - | - |
| Wu et al. | 95.10 | 88.76 | - |
| Gilbert et al. | 94.50 | - | - |
| Lin et al. | 93.43 | 89.38 | - |
| Jhuang et al. | 91.70 | 87.80 | - |
| Wong et al. | 86.62 | - | - |
| Willems et al. | 84.26 | - | - |
| Doll′ar et al. | 81.17 | - | - |
本文提出了一种基于改进时空兴趣点的复杂场景下,人体行为识别方法。在传统兴趣点检测算法的基础上,对采集到的兴趣点进行背景点抑制和时空域条件约束。目的在于尽量消除无用兴趣点对重要目标检测产生的干扰,以便能够准确、快速提取人体目标的特征信息。在去除无用兴趣点方面效果明显,通过对不同行为识别数据库的实验,证明本文算法能够较大幅度提高在复杂背景下的人体行为识别准确率,并且对移动视角下的运动目标检测也具有较好的检测效果。
| [1] | Robertson N, Reid I. Behaviour Understanding in Video:A Combined Method[C]//10th IEEE International Conference on computer Vision, 2005:808-815 |
| [2] | Parameswaran V, Chellappa R. View Invariance for Human Action Recognition[J]. International Journal of Computer Vision , 2006, 66 (1) : 83–101. DOI:10.1007/s11263-005-3671-4 |
| [3] | Li X. HMM Based Action Recognition Using Oriented Histograms of Optical Flow Field[J]. Electronics Letters , 2007, 43 (10) : 560–561. DOI:10.1049/el:20070027 |
| [4] | Laptev I. On Space-Time Interest Points[J]. International Journal of Computer Vision , 2005, 64 (2/3) : 432–439. |
| [5] | Dollar P, Rabaud V, Cottrell G, et al. Behavior Recognition via Sparse Spatio-Temporal Features[C]//2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, 2005:65-72 |
| [6] | Park S, Aggarwal J K. A Hierarchical Bayesian Network for Event Recognition of Human Actions and Interactions[J]. Multimedia Systems , 2004, 10 (2) : 164–179. DOI:10.1007/s00530-004-0148-1 |
| [7] | Bregonzio M, Gong S, Xiang T. Recognising Action as Clouds of Space-Time Interest Points[C]//IEEE Conference on Computer Vision & Pattern Recognition, 2009:1948-1955 |
| [8] | Yaron O, Sidi M. A Combined Corner and Edge Detector[C]//Proc of Fourth Alvey Vision Conference, 1988:147-151 |
| [9] | Lindeberg T. Feature Detection with Automatic Scale Selection[J]. International Journal of Computer Vision , 1998, 30 (2) : 77–116. |
| [10] | Chakraborty B, Holte M B, Moeslund T B, et al. A Selective Spatio-Temporal Interest Point Detector for Human Action Recognition in Complex Scenes[C]//2011 International Conference on Computer Vision, 2011:1776-1783 |
| [11] | Slonim N, Tishby N. Agglomerative Information Bottleneck[C]//Advances in Neural Information Processing Systems, 1999:617-623 |
| [12] | Schuldt C, Laptev I, Caputo B. Recognizing Human Actions:A Local SVM Approach[C]//17th International Conference on Pattern Recognition, 2004:32-36 |
