

射频识别(radio frequency identification,RFID)是一种利用无线射频来自动识别目标的物联网关键技术,在产品供应链、安全、交通、目标跟踪等众多领域都有广泛应用。RFID系统由阅读器和标签组成,阅读器负责读取标签信息;标签由于受到制作工艺和成本的限制,一般采用无源结构,由阅读器的能量激活,负责承载目标信息。随着应用场景所需标签数目的增多,出现了多个标签同时响应阅读器请求的情况,此时信息发生了冲突,阅读器将无法正常读取标签信息,这种情况被称为标签碰撞,该问题的产生将直接影响RFID系统的正常工作,从而降低系统识别效率,延长识别时间,是急需解决的关键问题。
目前标签防碰撞算法主要分为两类:确定性树型算法及概率性Aloha算法。树型算法复杂度较高,识别时间较长,本文将把低复杂度的Aloha型算法作为主要的研究方向。帧时隙Aloha算法[1]由基本帧时隙算法(basic framed slotted aloha,BFSA)和动态帧时隙算法(dynamic framed slotted aloha,DFSA)组成,整个识别过程分为多个帧,标签选择帧内时隙来响应阅读器请求,BFSA算法采用固定帧长,而DFSA算法的帧长可根据标签数目动态调整,因而识别效率较高,随着标签数目的增多,受限帧长使其性能迅速下降。文献[2]提出了一种增强型动态帧时隙算法(enhanced DFSA,EDFSA),通过标签分组来减少标签数目增多对算法性能的影响;文献[3]提出了一种基于组的DFSA算法,证明了当帧长与标签数目相比拟时,标签数目越少,系统效率越高的原则,以上2种算法均没有对如何分组做相应说明。文献[4]提出了一种基于帧内分组和精确标签估计的标签防碰撞算法(collision group algorithm,CGA),在受限帧长情况下,随着标签数目的增多,依然不能有效解决碰撞问题。文献[5]提出了一种基于距离分簇的防碰撞算法,并在文献[6]中给出了最优簇数目的计算方法,这2种算法采用固定的分簇步长,制约了分簇的合理性,文献[7, 8]通过合并或缩减多个簇的方法来改进以上算法,其步长调整具有一定局限性。
本文提出一种基于标签分布距离的碰撞避免算法(tag distribution distance based collision avoidance algorithm,DBCA),该算法适用于大规模RFID应用场景。根据标签分布距离,优化分组步长调整,建立新型的标签分组结构,保持组内待识别标签数目一致,并匹配初始帧长,确保识别时的最佳系统效率;为了提高单位时间内识别标签的数目,减少碰撞概率,采用不同属性的标签参与识别工作,将限定工作频率引入动态帧时隙算法,给出以不同频率在相应帧时隙通信的方法;利用基于距离的分组方法,设计阅读器与标签端详细的标签识别过程。仿真结果和性能分析表明,相比于已有算法,本算法在提高系统识别效率和缩减识别时间方面具有较优的性能。
1 分组结构及组内标签通信方法 1.1 基于标签分布距离的分组结构根据帧长与待识别标签数目相比拟时,标签数目越小,系统识别效率越高的原则[3],将阅读器读写范围内的标签进行分组,并依次识别,以保证较高的系统识别效率。通过改变阅读器发射功率的大小,来调整其可覆盖的识别区域,达到对标签进行分组识别的目的。在当前分组的确认过程中,标签不属于当前分组的情况可分为2种:1)标签与阅读器的距离超过了阅读器读写半径,不能激活标签;2)标签虽然可以接收阅读器读写命令,但由于信号强度过弱,导致标签反射信息不能成功到达阅读器。
假设已知组内最优标签数目ni,标签均匀分布在读写区域,已知其密度Di。阅读器调整发射功率改变读写半径,来划分标签在各组中的归属,并依次完成组内标签的识别,半径可由小到大逐步增加,直至最大读写范围,所有标签识别完毕。发射功率与读写半径的关系式由文献[9]获得。图 1为分组结构的示意图。

|
| 图 1 基于标签分布距离的分组结构示意图 |
由图可知,各分组所属区域除第0组为圆形外,均为以读写器为中心的圆环。假设一共有C个分组,则第i个分组的读写半径为ri,i∈{0,1,…,C-1},若先前组内标签均已被识别进入休眠状态,不再参与分组,则分组的读写范围Sir为:π(ri2-ri-12),此时读写半径增长的步长为:stepi=ri-ri-1。
标签均匀分布时,分组读写范围将保持一致,以确保组里初始标签数目一致,由公式(1)表示:
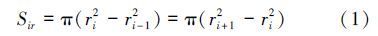
若读写范围Sir和前一组读写半径ri-1已知,由stepi=ri-ri-1带入(1)式,可得步长的表达(2)式:

步长stepi随着标签分布情况及分组所属读写范围的变化而动态改变,需保持组内标签数目与初始帧长相匹配,不会因读写半径的增大,组内标签数目的迅速增长,而导致碰撞的概率急剧增加。
1.2 基于属性的组内标签通信确定分组后,在组内可使用DFSA算法[1]来完成阅读器与标签的识别工作,在每帧的识别过程中,依然会出现多个标签在相同时隙响应阅读器请求而发生碰撞的情况,为了进一步减少这种情况,假设应用于不同场景的标签具有不同的属性,在响应阅读器请求的上行通路中使用不同的工作频率,即携带不同的副载波,对其信号进行调制。但不同属性标签的使用,受到阅读器成本的限制,需限定属性个数,并在特定频率上取值,因而此方法适用于组内标签的识别,因为分组后的组内待识别标签数目将显著减少,不适用于大规模标签的识别坏境。
由于无源标签受到其成本、尺寸、内存等方面的限制,本身无法识别阅读器识别请求的频率,因而阅读器与不同属性标签通信的下行通路可使用同一频率,而传输标签响应的上行通路中信号频率的识别由阅读器完成。当多个标签在同一时隙内响应,阅读器可识别属性不同的标签,对于同一属性的多个标签且在同一时隙内响应才会导致信息碰撞,因此利用基于属性的组内标签通信方法可大大提高识别效率和系统吞吐量。
2 DBCA算法识别过程DBCA算法识别过程的详细描述如下:
1) 阅读器根据已知的最佳分组读写范围Sir,及上一轮读写半径ri-1,根据(2)式,调整步长stepi,求得当前读写半径ri,并以对应发射功率向外发送识别请求信息(request)。
2) 当标签与阅读器的距离d满足ri-1<d<ri时,标签才具备发送应答信息(response)响应阅读器请求的能力。并在随后组内通信的每个帧内选择时隙通信,若在某时隙内被成功识别,则标签转为休眠状态,不再参与识别过程。
3) 阅读器在某时隙内收到标签响应信息后,进行识别工作,并判断时隙是否产生碰撞,根据判断的结果记录一帧内的成功时隙个数ssu、空闲时隙个数so、碰撞时隙个数sc,用于对下一帧的帧长进行动态调整。时隙内不产生碰撞的情况如下:
·一个时隙内只有一个标签响应阅读器请求;
·一个时隙内有多个标签响应阅读器请求,但其全部或部分的属性不同,不同属性的标签响应不产生碰撞。
4) 阅读器向已成功识别的标签发送确认信息(confirmation),对应标签收到该信息后,进入休眠状态。
5) 阅读器判断当前组内标签是否全部识别完毕,若没有则采用步骤3)中记录的结果动态调整帧长,进行下一帧的识别;否则进入步骤1)进行下一分组的识别工作。在下一分组标签识别之前的各组内标签均已进入休眠状态,不会参与下一组的识别工作。
6) 分组识别继续进行,直到阅读器读写半径达到最大值,即已包含可读写范围内的所有标签,则识别过程结束。
图 2为DBCA算法的流程图。

|
| 图 2 DBCA算法流程图 |
假设帧长为L,标签数目为n,则在第i组内给定时隙中只有一个标签响应的概率为:

当前帧内可被成功识别的时隙数目为:
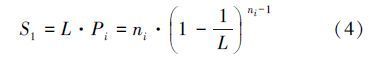
对S1以变量ni求导,并让其值等于零,dS1/dni=0,来求得达到最大标签可识别数目时,所对应的最佳ni值:
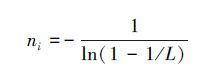
通过变形可得:
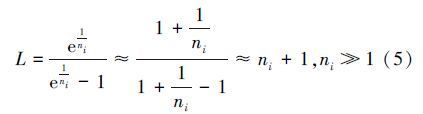
由上述分析可知,在组内只有当帧长与组内标签数目保持一致时,系统识别效率最高,此时在相同的帧长下,能使更多标签被识别。系统效率的定义为公式(6):
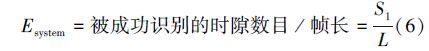
组内标签的数目将直接影响识别效率和系统吞吐量,若标签数目过大将会增大时隙内的碰撞概率;若标签数目过小又会增加空闲时隙数。因而需在给定条件下,寻找能够维持最大系统效率所对应的最佳组内标签数目。
假设帧长为L,标签数目为n,则在第i组内给定时隙中有α个标签同时响应的概率为:

在一个时隙中,如果存在多个不同属性的标签同时响应的情况,其中只要有标签能被识别,即将此时隙认作成功时隙,由此成功时隙Sse由(8)式表示:
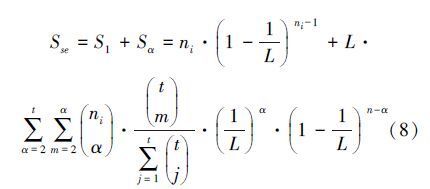

由于阅读器对不同属性标签的响应需采用不同频率的接收器,因此t值将受到阅读器成本的限制,不能过大。假设t=3,图 3将给出在不同帧长的条件下,系统识别效率随组内标签数目变化的关系图。从图中可知,对应最佳组内标签数目,本算法系统效率的最大值可达到51.5%,这将大大优于已有相关算法。

|
| 图 3 系统识别效率与标签数 目的关系图(随L变化) |
图 4为在不同t值的条件下,系统识别效率随组内标签数目变化的关系图。

|
| 图 4 系统识别效率与标签数 目的关系图(随t变化) |
从图中可以看出,在帧长L=128的情况下,t值越大,相同组内标签数目能达到的系统效率越高,但t值受到阅读器成本及读取复杂度的限制,不能过大。
图 5为在不同C值的条件下,系统识别效率随读写区域内全部标签数目变化的关系图,此时L=128,t=3。

|
| 图 5 系统识别效率与标签数 目的关系图(随C变化) |
从图中可以看出,随着分组数目的增加,可以达到系统最大效率的标签数目也在不断增加,这意味着在相同系统效率下,通过分组可以识别更多的标签。观察几条曲线的交点,利用公式(8)还可以得到,用于区分分组个数的临界标签数目。
从以上分析可知本算法的系统识别效率最高可达50%以上,远高于纯ALOHA算法(18.4%)、DFSA算法(36.8%)及EDFSA算法(34.6%~36.8%)的最高系统效率。
3.3 优化步长调整由以上分析可得,在给定条件下,能够达到最大系统效率时的最佳组内标签数目nopt,并根据标签分布密度Di来计算最优化组内读写范围Sir,已知前一组读写半径ri-1,则可利用公式(2)来计算最优步长stepopt ,从而达到合理划分分组的目的。
4 DBCA算法的性能分析在这一节中,我们将所提算法与其他已有算法DFSA[1]、EDFSA[2]及CGA[4]进行性能比较,并对仿真结果进行分析。以完成标签识别所需的总时隙数来衡量算法性能,若所需总时隙数较少则表明识别延时较小,系统吞吐量高,反之亦然。本文将采用Matlab进行仿真,为了得到更精确的仿真结果,将对1 000次的仿真结果取平均值作为最终的结果。假设:1)标签均匀分布在20 m×20 m的区域,阅读器位于整个读写区域的中心,其最大读写半径rmax=10 m。2)标签数目最大可达1 000,为了准确分析性能,将分为2种工作情景:小规模场景,标签数目0~200;大规模场景,标签数目0~1 000。3)DFSA算法的帧长可随标签数目的变化而动态改变,其初始帧长设为16,最大帧长可达256。4)EDFSA、CGA算法的初始帧长设为128,所有算法的最大帧长均设为256。5)DBCA算法可根据组内标签数目确定起始帧长,并随未识别标签数目的减少而递减帧长。
图 6为在小规模标签的工作场景下所需总时隙数目与标签数目的关系图。从图中可知,标签数目小于120时,EDFSA算法所需的时隙数目大于DFSA算法,这是因为DFSA算法在标签数目较少时,帧长也较小,初始值仅为16,帧长随标签数目的增加而成倍增加,因而存在较少的空闲时隙;而EDFSA算法初始帧长为128,在标签数目较少时,出现了较多的空闲时隙,性能较差,而当标签数目超过120时,帧长可以跟上标签数目的变化,此时其性能将优于DFSA算法。由于CGA算法具有帧内分组的功能,相对于前两种算法,所需时隙数目较少。本算法相比于其他3种算法所需时隙数目最少,这是因为其分组步长和帧长都可以根据最佳组内标签数目进行动态调整,使其系统效率达到最优,所以性能最好,由于标签总数过小,此处未使用多属性标签。

|
| 图 6 总时隙数与标签数目的关系图(小规模场景) |
图 7为在大规模标签的工作场景下所需总时隙数目与标签数目的关系图。从图中可知,DFSA算法所需的时隙数将随标签数目的增加成指数增长,这是因为帧长只能增长到其最大值256,而随着标签数目的持续增加,碰撞时隙将显著增多,所以系统性能将迅速下降。EDFSA算法性能将优于DFSA算法,所需的时隙数将随标签数目的增加而线性增长,这是因为该算法具有标签分组功能,通过分组来减少待识别的标签数目,并可以在组内调节帧长,可保持系统效率达到较高水平。CGA算法在标签数目小于700时,其所需总时隙数小于EDFSA算法,而大于700后,将超过EDFSA算法的增长量,这是因为该算法以帧内分组来提高标签识别效率,但在帧长最大值有限、标签数目迅速增加的情况下,将不能很好的处理碰撞问题,算法性能下降。本算法所需的总时隙数最少,这是因为其利用优化步长进行合理分组,帧长随组内标签数目动态调整,保证组内有较高的系统识别效率,同时采用多属性标签参与识别,可以在相同帧长下,识别更多的标签,减少了碰撞时隙,性能最优。

|
| 图 7 总时隙数与标签数目的关系图(大规模场景) |
解决大规模标签场景下的信息碰撞问题,提高系统的识别效率,是RFID技术发展所需关注的关键问题之一。本文提出了一种基于标签分布距离的碰撞避免算法(DBCA),适用于大规模RFID应用场景。利用动态步长调整,给出了一种对待识别标签的合理分组方法;根据标签的不同属性,建立了分组内的帧时隙通信方法,可在一个时隙内识别多属性标签,提高了标签的识别速度;设计了新的标签识别过程,并对算法进行了优化。仿真结果及性能分析表明,本算法在提高系统识别效率和减少标签识别时间方面,相比于已有算法,具有更优的性能。
| [1] | Klair D K, Chin K W, Raad R. A Survey and Tutorial of RFID Anti-Collision Protocols[J]. IEEE Commun Surv Tutor, 2010, 12(3):400-421 |
| Click to display the text | |
| [2] | Lee S R, Joo S D, Lee C W. An Enhanced Dynamic Framed Slotted ALOHA Algorithm for RFID Tag Identification[C]//Proceedings of the 2nd Annual International Conference on Mobile and Ubiquitous Systems:Networking and Services, 2005:166-174 |
| [3] | Wang C Y, Lee C C. A Grouping-Based Dynamic Framed Slotted ALOHA Anti-Collision Method with Fine Groups in RFID Systems[C]//5th International Conference on Future Information Technology, 2010:1-5 |
| [4] | Lin Chunfu, Frank Yeongsung Lin. Efficient Estimation and Collision-Group-Based Anticollision Algorithms for Dynamic Frame-Slotted ALOHA in RFID Networks[J]. IEEE Trans on Automation Science and Engineering, 2010, 7(4):840-848 |
| Click to display the text | |
| [5] | Ali K, Hassanein H, Taha A M. RFID Anti-Collision Protocol for Dense Passive Tag Environments[C]//The Proceedings of the 32nd IEEE Conference on Local Computer Networks, 2007:819-824 |
| [6] | Alsalih W, Ali K, Hassanein H. Optimal Distance-Based Clustering for Tag Anti-Collision in RFID[C]//The Proceedings of the 33rd IEEE Conference on Local Computer Networks, 2008, 266-273 |
| [7] | Waleed Alsalih, Discrete Power-Based Distance Clustering for Anti-Collision Schemes in RFID Systems[C]//13th Annual IEEE Workshop on Wireless Local Networks, 2013:868-873 |
| [8] | Alsalih W, Ali K, Hassanein H. A Power Control Technique for Anti-Collision Schemes in RFID Systems[J]. Journal of Computer Networks, 2013, 57:1991-2003 |
| Click to display the text | |
| [9] | Zhou F, Chen C, Jin D, et al. Evaluating and Optimizing Power Consumption of Anti-Collision Protocols for Applications in Rfid Systems[C]//ISLPED'04 NY, USA, 2004:357-362 |
