

2. 西北工业大学 计算机学院, 陕西 西安 710072
软件产品线是一组具有共同体系构架和可复用组件的软件系统,它们共同构建支持特定领域内产品开发的软件平台。软件产品线集中体现一种大规模、大粒度软件复用实践,是软件工程领域中软件体系结构和软件重用技术发展的结果[1]。软件产品线特征建模是呈现组件模块之间依赖、互斥等关系的重要手段,自Kang等[2]在1990年介绍面向特征域的分析方法提出后,特征建模就被广泛运用于软件产品线中。合理的配置特征模型直接影响和决定了整个产品线的质量和成败,然而产品线配置解决方案域并不唯一,因此如何获取最优配置方案解变得尤为重要。
遗传算法是一种求解问题的高度并行性全局搜索算法,它能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最优解,因此它在多目标优化问题的优化求解中有很大的作用和优势[3]。现阶段研究表明,将软件产品线特征模型映射编码后,通过遗传算法可以有效得到最优配置方案解[4]。本文将对现有的编码方式予以改进,通过合并相互依赖性高的模块,进一步合理缩小软件产品线特征模型,从而提高获取最优方案解的效率与个数。经过大量实验证明,这种编码方式是有效的。
1 软件产品线介绍 1.1 特征模型软件产品线工程是一个系统的发展软件系列产品的方法[5],其中软件产品被定义为一个特征集合,一个特征就代表着产品的一项功能。特征模型通常被用来表示一个软件产品线中的全部产品[2],特征模型可以表示为可见的树状结构,树的节点表示特征,树状结构将特征节点相关联。只要遵循特征模型的依赖、互斥等关系进行配置,就可以得到一个有效的软件产品配置。例如,图 1为GPS(全球定位系统)的特征模型,其根节点特征为GPS产品线本身。根据父节点与子节点之间的关系,其他节点可分为以下几种类型:

|
| 图 1GPS特征模型 |
1)强制型 定义该节点为其父节点必要节点,标示为●。如图 1中,寻路系统及人机交互是GPS产品线必须实现的功能,屏幕是人机交互必须具备的配置。
2)可选型 定义该节点为其父节点的可选节点,标示为○。如图 1中,提供路况信息是GPS产品线的可选功能。
3)组间或类型 定义为其父节点有且仅有一个子节点,标示为g[1, 1]。如图 1中,屏幕必须在触摸屏与液晶显示器中二选一。
4)组间异或类型 定义为其父节点至少有一个子节点,标示为g[1,*]。如图 1中,寻路系统在3D地图与自动寻路中至少实现一个功能。
此外,特征之间还存在2种约束关系:
1)等价关系 选择特征A则并需选择特征B,表示为单箭头虚线。如图 1中,路况信息与自动寻路为等价关系。
2)互斥关系 特征A与特征B不能同时存在,表示为双箭头虚线。如图 1中,键盘与触摸屏为互斥关系。
与此同时,特征模型通过特征属性来扩展特征的额外信息。特征属性的组成通常为:属性名称、阈值与数值。如图 1中人机交互的一个属性,可知其开销为8。特征属性不仅用来统计整个产品的细节信息,更是合理配置产品功能的重要依据。
1.2 多目标优化软件产品线最优化问题主要包含2类目标函数:①尽可能少的成本开销;②尽完备的实现功能。此问题也被称为多目标优化问题,多目标优化旨在找出一组同时满足所有优化目标的解集,再由相关决策做出最终选择。传统的多目标优化问题解决方案主要有2个:①将多目标转换为单目标,即把各目标加权,然后选择权值最高的解作为最优解;②仅针对多目标中的某一目标求解,其他目标只需达到一定范围即可。
然而,传统的多目标优化具有很大的主观性、不一致性,并不能有效的得到最优方案解。通过遗传算法可以很好解决这些问题,遗传算法可以并行的处理一组可行的解集,能在一次运算过程中找到满足多个目标的Pareto最优解集。
2 新型的编码方式软件产品线编码方式是将其特征模型依照特征进行编码,使它的排列形式符合遗传算法的基因序列,随后根据特征属性进行选择运算,最终获得软件产品配置最优方案解集。优秀的编码策略能极大的提高获取最优方案解集的效率和个数,文章将介绍三种编码方式:直接编码方式,强制编码,以及一种新型的编码方式——MPC编码。
2.1 直接编码直接编码即为直接按照层次遍历顺序对特征树进行编码。令特征集为S,编码特征集为S′,则S′=S。例如,图 2为任意特征模型树,此特征模型的直接编码如图 3所示。

|
| 图 2特征模型树 |

|
| 图 3 直接编码 |
强制编码是将强制型节点和其父节点结合为1个特征节点的编码方式。令特征集为S,编码特征集为S′,强制型节点集为M,则S′=S-M。例如,在图 2中,f1存在时f2必定存在,f2存在时f5必定存在,因此f1、f2与f5是共存的,于是可将3个特征结合为1个特征再依照层次遍历进行编码,如图 4所示,从而达到减小模型编码序列的目的,提高求解配置最优解的效率。

|
| 图 4 强制编码 |
MPC编码又称强制子父节点编码,是基于强制编码改进的编码方式,通过隐藏子父关系节点达到进一步缩小编码范围的目的。令特征集为S,编码特征集为S′,强制型节点集为M,根节点为r,组间型节点g的父节点为gf,该父节点gf的非组间型节点为fc,则:
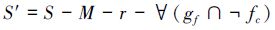

|
| 图 5 MPC编码 |
文章将采用遗传算法来求解软件产品线最优配置问题,在算法实现上,首先将特征按照顺序排列为一个0、1序列,其中序列第n位对应特征编码号n-1,当序列第n位值为1时,表示第n-1个特征被选中,当序列第n位值为0时,表示第n-1个特征未被选中。其次,若要得到一个合理、可行的产品配置,需要满足以下5个规则:
1)根节点是必要的,即产品线本身必定存在;
2)任意子节点存在时,其父节点必定存在;
3)若某节点存在强制型子节点,则当该节点存在时,其强制型子节点必定存在;
4)若某节点存在组间子节点时,则必须符合组间节点定义;
5)必须符合等价关系与互斥关系。
因此,我们可根据以上5个规则生成1个规则函数,通过算法1来检验特征序列是否满足配置要求。
算法1 规则函数
输入:特征序列
算法步骤:
Step1 若根节点为0,违反规则数+1;
Step2 若子节点为0,父节点为1,违反规则数+1;
Step3 若父节点为1,其强制子节点为0,违反规则数+1;
Step4 若父节点为1,其组间异或子节点都为0,违反规则数+1;
Step5 若父节点为1,其组间或子节点全部为0或有2个以上为1,违反规则数+1;
Step6 若某节点为1,其等价节点为0,违反规则数+1;
Step7 若某节点为1,其互斥节点为1,违反规则数+1。
输出:违反规则数。
最终,当得到的违反规则数等于0时,表示当前特征序列满足要求,是一个有效的配置方案解。
4 实验配置 4.1 遗传算法文章将选用2种遗传算法来对特征编码方式予以验证:NSGA-II[6](精英保留的非劣排序遗传算法)和IBEA[7](基于指标的遗传算法)。其中,NSGA-II是NSGA[8](非劣排序遗传算法)的改进算法,有效地将NSGA的计算复杂度从O(mN3)降至O(mN2),从而进一步提高算法的计算效率和鲁棒性。IBEA是一种通用多目标遗传算法,该算法首次将评价指标函数作为适应度评价方法嵌入到遗传算法中,使其可以与任意服从Pareto优胜规则的指标相结合,常用的指标有二元additive epsilon指标和二元hypervolume指标。
4.2 SPL特征模型文章选用2个传统模型E-Shopping[9]和WebPortal[10],以及2个大数据随机模型来验证3种编码方式,并使用Hypervolume指标(简称HV)来评估运算结果。E-Shopping是一个商务网站模型,WebPortal是一个门户网站模型,2个大数据随机模型分别采用5 000特征节点和10 000特征节点。其中,每个特征模型的基本数据如表 1所示。
| 软件产品线 | E-Shopping | Web-Portal | Large Data 5 000 | Large Data 10 000 |
| 特征个数 | 290 | 43 | 5 000 | 10 000 |
| 强制型节点个数 | 66 | 8 | 1 655 | 3 209 |
| 可选型节点个数 | 74 | 17 | 1 685 | 3 343 |
| 组节点个数 | 149 | 17 | 1 659 | 1 087 |
在实验中,模拟了5个目标来定义特征模型,并赋予初值:
1)违反规则数:通过特征模型树所生成的符合5个规则的规则函数,计算遗传算法个体解违反规则的数量,取最小值;
2)特征个数:个体解中包含特征的个数,取最大值;
3)特征被用性:个体解中的特征是否曾经被使用过,未曾使用过的特征存在未知缺陷,因此取最大值;
4)已知缺陷个数:曾经被使用过的特征都存在已知的缺陷个数,其值取最小值;
5)开销:每个特征都存在开销,其值取最小值。
5 实验结果及结论分析在实验中,首先对4个特征模型进行编码,编码后的节点个数如表 2所示。其中,EN表示编码节点个数,OP表示优化概率。优化概率的公式为:令特征个数为f,编码个数为e,则OP=(f-e)/f×100%。通过编码结果不难看出,MPC编码进一步缩小了模型大小,在10 000节点随机模型中可优化比高达40%,使得求解效率得到进一步提高。
| 软件产品线 | E-Shopping | Web-Portal | Large Data 5 000 | Large Data 10 000 | ||||
| EN | OP/% | EN | OP/% | EN | OP/% | EN | OP/% | |
| 直接编码 | 290 | 0 | 43 | 0 | 5 000 | 0 | 10 000 | 0 |
| 强制编码 | 215 | 25.86 | 35 | 18.60 | 3 345 | 33.1 | 6 791 | 32.09 |
| MPC编码 | 202 | 30.34 | 28 | 34.88 | 3 106 | 37.88 | 5 922 | 40.78 |
在求解最优方案解中,2个遗传算法分别执行2遍,1遍为5个等价目标的执行,1遍为限定违反规定数为0的执行。每次执行评估50 000次并循环30次,即得到30组解集。表 3~表 6为4个特征模型的测评结果,其中,VN表示30组解集中含有违反规则数为0解的解集个数,VR表示30组解集中所有违反规则数为0解所占全部解百分比。
| 编码方式 | 算法 | 5个等价目标的运算结果 | 限定违反规则数的运算结果 | ||||
| HV | VN(/30) | VR/% | HV | VN(/30) | VR/% | ||
| 直接编码 | NSGA-II | 0.000 000 | 0 | 0.00 | 0.136 545 | 13 | 100 |
| IBEA | 0.000 000 | 0 | 0.00 | 0.169 191 | 16 | 100 | |
| 强制编码 | NSGA-II | 0.003 343 | 28 | 2.07 | 0.149 158 | 30 | 100 100 |
| IBEA | 0.267 410 | 30 | 33.91 | 0.175 422 | 30 | 100 100 | |
| MPC编码 | NSGA-II | 0.003 751 | 30 | 4.97 | 0.162 943 | 30 | 100 |
| IBEA | 0.256 768 | 30 | 84.26 | 0.190 496 | 30 | 100 | |
| 编码方式 | 算法 | 5个等价目标的运算结果 | 限定违反规则数的运算结果 | ||||
| HV | VN(/30) | VR/% | HV | VN(/30) | VR/% | ||
| 直接编码 | NSGA-II | 0.012 498 | 22 | 1.52 | 0.222 625 | 30 | 100 |
| IBEA | 0.300289 | 30 | 61.64 | 0.260523 | 30 | 100 | |
| 强制编码 | NSGA-II | 0.059 950 | 30 | 1.70 | 0.275 413 | 30 | 100 |
| IBEA | 0.308381 | 30 | 78.99 | 0.307052 | 30 | 100 | |
| MPC编码 | NSGA-II | 0.168 637 | 30 | 6.02 | 0.284 126 | 30 | 100 |
| IBEA | 0.318109 | 30 | 97.04 | 0.318734 | 30 | 100 | |
| 编码方式 | 算法 | 5个等价目标的运算结果 | 限定违反规则数的运算结果 | ||||
| HV | VN(/30) | VR/% | HV | VN(/30) | VR/% | ||
| 直接编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 |
| IBEA | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 | |
| 强制编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 |
| IBEA | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 | |
| MPC编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 652 | 30 | 100 |
| IBEA | 0.000 000 | 0 | 0 | 0.000 651 | 30 | 100 | |
| 编码方式 | 算法 | 5个等价目标的运算结果 | 限定违反规则数的运算结果 | ||||
| HV | VN(/30) | VR/% | HV | VN(/30) | VR/% | ||
| 直接编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 |
| IBEA | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 | |
| 强制编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 |
| IBEAO | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 | |
| MPC编码 | NSGA-II | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 |
| IBEA | 0.000 000 | 0 | 0 | 0.000 000 | 0 | 0 | |
比较实验结果可知,在3个编码方式中,MPC编码的HV评估值普遍最优,直接编码的HV评估值通常最低,并且,MPC编码的含有违反规则数为0解的解集个数以及违反规则数为0解所占比也大部分高于其他2个算法。同样地,直接编码普遍偏低。尤其在大型随机模型LargeData实验中,直接编码和强制编码并不能得到有效解,然而MPC编码却得到了有效的结果。由此可证实,MPC编码的确在求解软件配置最优解中更加有效率。
6 结 论通过大量实验数据结果可验证MPC编码方式较优于其他编码方式,然而此方法还有很多不足之处。众所周知,软件产品线特征模型是各式各样的,本方法不一定能囊括所有特征模型,在某些特定模型下并不能绝对提高获取最优方案解的效率。如何使MPC编码可以优化更多特征模型是我们进一步研究的问题。
| [1] | 李兰涛, 王忠民. 基于UML的软件产品线建模方法研究[J]. 微计算机信息, 2006, 22(30): 204-206 Li Lantao, Wang Zhongmin. Software Product Lines Modeling Approach with UML[J]. Control & Automation, 2006, 22(30): 204-206 (in Chinese) |
| Cited By in Cnki (12) | |
| [2] | Kang K, Cohen S, Hess J, et al. Feature-Oriented Domain Analysis (FODA) Feasibility Study[R]. Technical Report CMU/SEI-90-TR-21, SEI, 1990 |
| [3] | Goldberg D E. Genetic Algorithms in Search, Optimization and Machine Learning[M]. Boston, Addison-Wesley Professional, 1989 |
| [4] | Abdel Salam Sayyad, Tim Menzies, Hany Ammar. On the Value of User Preferences in Search-Based Software Engineering: A Case Study in Software Product Lines[C]//35th International Conference on Software Engineering, 2013: 492-501 |
| [5] | Clements P, Northrop L. Software Product Lines: Practices and Patterns[M]. Boston, Addison-Wesley Professional, 2001 |
| [6] | Kalyanmoy Deb, AmritPratap, Sameer Agarwal, et al. A Fast and Elitist Multi-Objective Genetic Algorithm: NSGA-II[J]. IEEE Trans on Evolutionary Computation, 2002, 6(2): 182-197 |
| Click to display the text | |
| [7] | Zitzler E, Künzli S. Indicator-Based Selection in Multi-Objective Search[C]//Proc of the 8th hat'1 Conf Oil Parallel Problem Solving from Nature, 2004 |
| [8] | Srinivas N, Kalyanmoy Deb. Multi-Objective Optimization Using Ondominated Sorting in Genetic Algorithms[J]. Evolutionary Computation, 1994, 2(3): 221-248 |
| Click to display the text | |
| [9] | Sean Quan Lau. Domain Analysis of E-Commerce Systems Using Feature-Based Model Templates[D]. University of Waterloo, 2006 |
| Click to display the text | |
| [10] | Marcilio Mendonca, Thiago Tonelli Bartolomei, Donald Cowan. Decision-Making Coordination in Collaborative Product Configuration[C]//Proceedings of the 23rd Annual ACM Symposium on Applied Computing, 2008: 108-113 |
2. Department of Computer Science and Engineering, Northwestern Polytechnical University, Xi'an 710072, China
