

在金属铣削过程中,刀具的磨损与产品的加工质量具有密切的联系。刀具的磨损量可以通过铣削过程中的动态信号表现出来,通过对铣削过程中的动态信号进行采集、处理与识别能够监测刀具的磨损状态,从而避免刀具磨损所造成的损失。识别刀具磨损状态一直是国内外学者研究的热点问题之一,他们提出了众多利用振动信号、力信号以及声发射信号识别刀具磨损状态的研究成果[1, 2, 3, 4, 5, 6, 7]。目前的研究成果主要是基于支持向量机、模糊系统、神经网络等人工智能算法建立信号特征与刀具磨损状态的数学模型,通过多个训练样本的学习确定模型的参数[8, 9]。这些方法的可行性与有效性主要依赖于信号特征与判决阈值的选择。小波变换[10]、希尔伯特-黄变换(HHT)[11]、混沌时序分析[12]等信号特征提取方法被不断地应用在刀具磨损的信号特征提取方面,但是由于刀具磨损信号特征常常被淹没在强大的噪声背景中,很多信号特征提取方法所提取的特征中含有冗余信息。在这种情况下,刀具磨损的信号特征的敏感度与关联度被大大地降低了,最终影响了刀具磨损状态的识别效果。所以,如何简化包含冗余信息的多维信号特征,得到能够反映刀具磨损状态的低维特征具有非常重要的价值。
流形学习能够通过非线性降维的方式提取不同类型高维数据的内在特征,与传统的线性降维方法相比,流形学习在处理高维、复杂非线性的刀具磨损信号时能够更加有效地发现非线性数据的本质结构。本文通过流形学习中的局部切空间排列(LTSA)方法对刀具磨损信号的时域特征与频域特征构成的原始高维特征空间进行维数约简,消除原来信号特征中的冗余信息。然后使用隐马尔可夫模型作为分类器[13],建立降维之后的特征矢量与故障类别之间的映射关系,最终实现刀具磨损状态的识别。
1 局部切空间排列算法(LTSA)的维数约简方法局部切空间排列(local tangent space alignment,LTSA)方法是一种有效的流形学习算法,被广泛地应用在信号数据集维数约简方面[14]。本文使用LTSA方法用来约简铣削过程中的刀具切削力信号的原始特征维数。其主要思想是:将刀具磨损相关的力信号进行特征提取,将每一次不同刀具磨损量的实验信号转化为一个特征点,该特征点的维数就是刀具磨损特征提取后的维数,而所有特征点的存在形成了刀具磨损特征空间;利用刀具磨损特征点所在局部空间的切空间来表示点的邻域,并对每一个刀具磨损特征点都建立邻域切空间;最后利用刀具磨损特征点局部切空间排列来求出整体低维嵌入坐标,从而实现约简刀具磨损特征。使用LTSA方法将刀具磨损数据集X=[x1,x2,…,xN],xi∈Rm,化简为d(m>d)维的数据集的步骤总结如下:
1) 构造特征点的局部邻域。对于刀具磨损数据集X中的任意特征点xi,i=1,2,…,N,使用欧氏距离确定其ki个邻近特征点组成的邻域Xi=[xi1,xi2,…,xiki]。
2) 特征点的局部邻域中线性拟合。在刀具磨损特征点xi的邻域内选择一组正交基Oi构成xi的d维切空间;计算邻域中每一个点xij(j=1,2,…ki)到切空间上的正交投影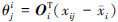 。其中xi=
。其中xi=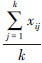 为矩阵
为矩阵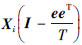 的前d个最大的左奇异矢量。特征点xi的在其邻域中的局部坐标为Θi=
的前d个最大的左奇异矢量。特征点xi的在其邻域中的局部坐标为Θi=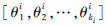 。
。
3) 获取特征的全局坐标Ti。将每一个特征点的局部坐标转化为刀具磨损特征空间的全局坐标需要满足2个条件:(1)全局坐标应该尽量保留每个特征点邻域的几何结构信息;(2)全局重构误差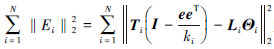 为最小值。其中,特征点xi的局部坐标Θi经过转化后得到全局坐标Ti=[ti1,ti2,…,tiki],其中Li为转化矩阵,将全局重构误差最小化得到全局坐标Ti。
为最小值。其中,特征点xi的局部坐标Θi经过转化后得到全局坐标Ti=[ti1,ti2,…,tiki],其中Li为转化矩阵,将全局重构误差最小化得到全局坐标Ti。
隐马尔可夫模型(HMM)是一种概率论模型,具有学习能力与自适应能力,拥有严谨的数据结构和完善的数学理论基础,能够通过训练获取知识,从而有效地对待识别目标进行分类。近年来,HMM在切削过程监测中得到了广泛应用[15, 16, 17]。考虑使用测力传感器记录刀具磨损过程中的工件受力情况,其力信号的变化与刀具磨损状态具有密切的关系,定义力信号特征,并将其划分为n个级别。记录刀具的磨损量,按磨损量的范围划分3种磨损状态,分别为:初始、正常与剧烈。当刀具处于某一磨损状态时,其力信号特征处于第i个级别的概率为pi。在这种情况下,本文研究的问题可以描述为:已知观测的力信号特征序列,如何判断是由哪种刀具磨损状态序列产生的观测信号特征序列。
针对刀具磨损识别问题,定义隐马尔可夫模型(HMM):λ=(π,A,B)。根据刀具磨损有限状态集S,定义取值于S的马尔可夫链为{qt:t≥1},其中{qt:t≥1}的初始分布q1为π,状态转移矩阵为A。事实上,刀具磨损状态链qt的值、初始概率分布π与状态转移矩阵A都不能直接得到。对于刀具磨损识别问题而言,能够直接通过观测获取的是取值于有限观测集Ω的变量序列{ot:t≥1},将其称之为观测链。通过直接观测得到的观测链与未知状态链一起构成了隐马尔可夫模型(HMM),并定义观测链与状态链的关系矩阵B,将其称为观测值概率矩阵。由以上可以看到参数矩阵A与B,以及参数向量π都是未知的,使用λ=(π,A,B)来表示隐马尔科夫模型。
2.2 面向刀具磨损状态识别HMM的基本算法在建立HMM时,HMM中初始概率分布矢量π、状态转移概率矩阵A与观测值概率矩阵B都是未知的。在本文中,通过流形学习方法LTSA进行特征约简之后的d维特征向量是用于训练的观测序列{ot:t≥1}。
已知存处于刀具磨损状态si的训练观测序列{ot:t≥1}以及HMM的初始模型λ0使用Baum-Welch算法[15],训练得到第i个磨损状态的马尔可夫模型λi,i=1,2,…,N,N为刀具磨损状态数目,本文中磨损状态数N为3。
使用Viterbi算法计算未知磨损状态的观察序列{ot:t≥1}的在各个状态HMMλi下的概率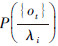 ,选取最大的所对应的磨损状态为观察序列{Ou}的磨损估计状态,进而完成未知刀具磨损状态的识别[16];
,选取最大的所对应的磨损状态为观察序列{Ou}的磨损估计状态,进而完成未知刀具磨损状态的识别[16];
除了Baum-Welch算法与Viterbi算法之外,Baum等人提出了前向算法与后向算法用于解决HMM中的概率计算问题,即在给定观测序列{ot:t≥1}与模型λ的情况下,有效地计算观测序列在模型λ下中出现的概率。Baum-Welch算法与Viterbi算法的详细步骤参见文献[15, 16]。
为了实现最终的刀具磨损状态的分类,需要提取与刀具磨损状态相关的信号特征,由于刀具在进给方向的切削力信号与刀具切削状态具有密切的联系,很多研究将进给方向的切削力作为信号特征提取的对象。本文使用流形学习方法(LTSA算法)对进给方向的切削力信号的时域特征与频域特征进行特征约简。由于LTSA算法从原始的特征空间中提取出的低维子流形拥有能够代表原始数据结构的能力,所以使用LTSA算法进行特征约简后,不但能够有效降低信号特征维数与计算复杂度,而且能够得到与刀具磨损状态密切相关的新信号特征,在本文的实验中也证明了LTSA算法的有效性。本文进行信号特征约简的实现过程如下所述:
1) 原始特征空间的构成。构造原始特征空间的信号特征为时域特征与频域特征。其中时域特征分别为均值、均方根值、波形指标、波峰指标、脉冲指标、裕度指标以及峭度指标等7个时域特征,频域特征为使用db4小波包函数进行3层正交小波分解得到的8个子频带信号的功率谱能量。
2) 特征压缩的目标维数d与局部邻域中特征点的个数k选择。LTSA方法中目标维数的选择会影响特征的敏感性,而局部邻域中特征点的个数会影响低维流形的提取效果。本文将降维后特征空间中不同磨损状态下的分类质量作为测度函数,使用网格搜索算法来选取LTSA方法的最优参数。
3) 获取低维特征。对于选定的目标维数d与局部邻域中特征点的个数k,计算每个特征点的邻域,计算中心化矩阵中心化矩阵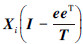 的d个最大左奇异向量构成d维切空间。计算特征点在邻域切空间的投影。将特征点的局部投影进行整合,通过最小化全局重构误差,获取经过约简后的刀具磨损特征的全局坐标。
的d个最大左奇异向量构成d维切空间。计算特征点在邻域切空间的投影。将特征点的局部投影进行整合,通过最小化全局重构误差,获取经过约简后的刀具磨损特征的全局坐标。
本文提出的基于HMM的刀具磨损状态识别流程主要包含生成任务、训练任务以及识别任务,如图 1所示。
 |
| 图 1 基于HMM的刀具磨损状态识别流程 |
生成任务将训练集中经过LTSA方法特征约简的刀具磨损特征矢量转化为观察值符号序列。首先基于LTSA方法对原始的刀具磨损切削力信号的时域与频域的特征进行维数约简,形成新的特征矢量;然后使用K-means算法对训练集中不同刀具磨损状态的特征矢量训练出离散码本[17];再利用离散码本将训练集中的各个特征矢量量化为观察值符号序列。
训练任务使用Baum-Welch算法对不同刀具磨损状态的观察值符号序列进行训练,得到每一种磨损状态的HMM[15]。
识别任务中首先遍历训练样本中的每一个样本,分别使用样本的码本将待识别刀具磨损原始序列特征转化为观察值符号序列,并使用对应样本的HMM计算待识别观察值符号序列的Viterb评分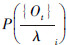 ,将具有最高Viterb评分的HMM所对应的刀具磨损状态作为识别的结果[16]。其中按照铣刀主切削刃后刀面的磨损量(VB),将刀具磨损过程划分为的3个不同状态:状态1-初期磨损状态:VB < 0.1 mm;状态2——正常磨损状态: 0.1 mm≤VB < 0.35 mm;状态3——剧烈磨损状态:VB≥0.35 mm。
,将具有最高Viterb评分的HMM所对应的刀具磨损状态作为识别的结果[16]。其中按照铣刀主切削刃后刀面的磨损量(VB),将刀具磨损过程划分为的3个不同状态:状态1-初期磨损状态:VB < 0.1 mm;状态2——正常磨损状态: 0.1 mm≤VB < 0.35 mm;状态3——剧烈磨损状态:VB≥0.35 mm。
从切削原理可知,进给方向的切削力信号包含了刀具磨损运行状态的丰富信息。本文使用KISTLER公司生产的测力仪来采集株洲钻石PM-4E-D6.0-G整体螺旋立铣刀的切削力,采样频率为200 kHz,采样长度为0.5 s。实验详细信息如表 1所示。本文采集的进给方向的切削力信号的实验平台如图 2所示。
 |
| 图 2 实验平台示意图 |
为了保证所采集的进给方向的切削力信号处于对应的磨损状态中,本文根据实验经验选定了一定的时间间隔,使用Alicano公司的Infinite focus测刀仪对后刀面的磨损量进行测量。在本文所设定的切削加工参数下,对每一把刀具均在一定的时间间隔下进行6次后刀面的测量,前2次测量的间隔时间为进行铣削加工30 s,第3次与第4次测量的间隔时间为进行铣削加工20 s,第5次与第6次测量的间隔时间为10 s。本文在实际加工过程中为了避免工件的结构形式以及刀具的加工路径对切削过程的进给方向切削力信号的特征影响,实验所有的铝合金工件都是预先处理为15 cm×10 cm×10 cm尺寸。为了保证实验过程的一致性,本文在实验过程中选择相同的刀具以及工件,按照本实验所设定轴向切深、径向切深进行直线走刀,每次直线走刀的长度为10 cm。
在本文中,根据3.2节中所述,在刀具磨损的不同状态采集了3类切削力信号,每类磨损信号包含30组数据,一共90组数据。
4.2 基于网格计算的LTSA的参数寻优按照3.1节所描述的步骤实现基于LTSA的刀具磨损信号特征提取。首先构造原始特征空间,本文所建立的原始特征空间中包含了:均值、波形指标、峰值指标、脉冲指标、裕度指标、峭度指标、子频带1的能量、子频带2的能量、子频带3的能量、子频带4的能量、子频带5的能量、子频带6的能量、子频带7的能量、子频带8的能量。
使用网格搜索算法来选取LTSA方法的最优目标维数m-best与最优局部邻域点数k-best,将降维后特征空间中3种磨损状态下的特征点最小包含球的平均半径作为测度函数。其中,1≤m≤15,1≤k≤20,设定搜索步长为1。使用网格搜索算法进行LTSA方法参数寻优结果,当测度函数在降维目标维数m为7(原始信号特征维数为15),局部邻域点数k为11的时候取得最高的测度函数值21.987。
对实验样本数据使用LTSA方法进行维数约简,经过维数约简之后得到维数为7的数据。原始磨损特征空间中冗余特征已经被约简,基于LTSA方法得到新的数据结构更加紧凑,有效改善了同一磨损状态的数据特征的内聚度。而且经过特征约简之后的信号样本特征主要分布在3个不同的数量级,能够提高原始特征矢量量化的速度与准确率。
4.3 磨损状态识别实验在完成基于LTSA方法的特征约简之后,按照如3.2节所示的方法,对本文实验所采集的3种刀具磨损状态的信号求解码本,并利用码本将信号的特征矢量量化为观察值符号序列。经过LTSA方法进行特征约简后的3种刀具磨损状态的HMM模型训练结果如图 3所示。从图 3中可以看到,3种刀具磨损状态的HMM对数似然估计在30步迭代之后就可以达到收敛误差范围,并且3种刀具磨损状态具有不同的收敛值。
 |
| 图 3 3种磨损状态的HMM训练迭代曲线 |
在完成3种刀具磨损状态的HMM建立之后,根据3.2节中所陈述的基于HMM的分类方法进行刀具磨损状态的识别。对于3种刀具磨损状态的实验条件下分别选取5次观测样本进行分类测试,其分类结果如表 4所示。
| 采样磨损状态 | 样本编号 | 3种磨损状态HMM输出的对数似然概率 | 识别结果 | ||
| 初始磨损 | 正常磨损 | 剧烈磨损 | |||
| 初始磨损 | 1 | 95.894 5 | 94.845 2 | 94.360 5 | 初始磨损 |
| 2 | 95. 935 6 | 94.889 1 | 94.404 4 | 初始磨损 | |
| 3 | 95.964 2 | 94.937 8 | 94.453 1 | 初始磨损 | |
| 4 | 95.921 0 | 94.923 0 | 94.438 3 | 初始磨损 | |
| 5 | 95.959 9 | 94.923 0 | 94.438 3 | 初始磨损 | |
| 正常磨损 | 1 | 95.058 9 | 95.937 9 | 94.583 5 | 正常磨损 |
| 2 | 93.819 1 | 94.814 9 | 93.343 7 | 正常磨损 | |
| 3 | 94.836 1 | 95.668 4 | 94.360 7 | 正常磨损 | |
| 4 | 95.194 5 | 95.958 0 | 94.719 1 | 正常磨损 | |
| 5 | 94.771 7 | 95.596 5 | 94.296 3 | 正常磨损 | |
| 剧烈磨损 | 1 | 94.301 3 | 93.310 6 | 94.983 6 | 剧烈磨损 |
| 2 | 94.660 4 | 94.669 7 | 95.280 9 | 剧烈磨损 | |
| 3 | 94.463 9 | 94.473 2 | 95.043 5 | 剧烈磨损 | |
| 4 | 94.548 4 | 94.557 7 | 95.116 1 | 剧烈磨损 | |
| 5 | 94.504 6 | 94.513 9 | 95.117 7 | 剧烈磨损 | |
为了评价本文所提出的刀具磨损识别方法的效果,在本节中针对3类刀具磨损信号使用LTSA方法进行特征约简后的识别结果与未特征约简后的识别方法进行对比。其中LTSA方法的邻域参数k为11,目标维数为7。表 5为基于LTSA方法约简与未经约简的特征向量进行隐马尔科夫模型识别的结果。从表 5中可以看出LTSA方法能够有效区分3类刀具磨损状态,与未经约简的识别方法相比,前者具有更加优秀的识别效率与精度。
| 方法 | 初始磨损/% | 正常磨损/% | 剧烈磨损/% | 平均识别精度 | 平均识别时间/s |
| 基于LTSA的HMM识别 | 96.67 | 93.33 | 93.33 | 94.44 | 7.5 |
| 未经特征约简的HMM识别 | 73.33 | 76.67 | 70 | 73.33 | 11.3 |
本文提出了基于LTSA方法和隐马尔可夫模型的刀具磨损状态识别方法。本文将金属铣削过程中进给方向的铣削力信号的时域特征与频域特征构建样本点的特征空间。由于LTSA方法能够在保持数据局部几何结构的同时降低数据的维数,将其用于分类问题能够获得较好的分类结果。本文在使用LTSA方法进行维数约简之后,通过Lloyds算法将特征矢量转化为观察值符号序列,并将其代入HMM中进行分类识别。HMM通过Viterbi算法对观察序列进行了优化,并使用Baum-Welch算法重新估计了HMM参数,通过比较样本的对数似然概率值的大小实现了状态识别。本文用3种刀具磨损状态的识别实例验证了经过LTSA方法进行特征约简的进给方向力信号识别不同磨损状态的可行性与有效性。
本文提出的方法利用了LTSA方法在特征约简与信息化简的优势,对进给方向的切削力信号的时域特征与以小波包函数子频的信号功率谱能量为主的频域特征组成的特征空间进行维数约简,并应用HMM实现了不同磨损状态的识别。本文的方法按照“特征提取”、“特征化简”、“模式识别”的流程,实现了刀具磨损状态识别自动化与高精度的统一。
| [1] | Wang G F, Yang Y W, Zhang Y C, et al. Vibration Sensor Based Tool Condition Monitoring Using v Support Vector Machine and Locality Preserving Projection[J]. Sensors and Actuators A: Physical, 2014, 209: 24-32 |
| Click to display the text | |
| [2] | Wang Guofeng, Guo Zhiwei, Yang Yinwei. Force Sensor Based Online Tool Wear Monitoring Using Distributed Gaussian ARTMAP Network[J]. Sensors and Actuators A: Physical, 2013, 192: 111-118 |
| Click to display the text | |
| [3] | Ravindra H C, Srinivasa Y G, Krishnamurthy R. Acoustic Emission for Tool Condition Monitoring in Metal Cutting[J]. Wear, 1997, 212(1), 78-84 |
| Click to display the text | |
| [4] | Zhou J M, Andersson M, Stahl J E. The Monitoring of Flank Wear on the CBN Tool in the Hard Turning Process[J]. Int J Adv Manuf Technol, 2003, 22: 697-702 |
| Click to display the text | |
| [5] | Ai C S, Sun Y J, He G W, et al. The Milling Tool Wear Monitoring Using the Acoustic Spectrum[J]. Int J Adv Manuf Technol, 2012, 61: 457-463 |
| Click to display the text | |
| [6] | Susanto V, Chen J C. Fuzzy Logic Based In-Process Tool-Wear Monitoring System in Face Milling Operations[J]. Int J Adv Manuf Technol, 2003, 3:186-192 |
| Click to display the text | |
| [7] | 张翔, 富宏亚, 孙雅洲, 等. 基于隐Markov模型的微径铣刀磨损监测[J]. 计算机集成制造系统, 2012, 18(01): 141-148 Zhang Xiang, Fu Hongya, Sun Yazhou, et al. Hidden Markov Model Based Micro-Milling Tool Wear Monitoring[J]. Computer Integrated Manufacturing Systems, 2012, 18(1): 141-148 (in Chinese) |
| Cited By in Cnki (1) | Click to display the text | |
| [8] | Kuo R J, Cohen P H. Intelligent Tool Wear Estimation System through Artificial Neural Networks and Fuzzy Modeling[J]. Artificial Intelligence in Engineering, 1998, 12(3): 229-242 |
| Click to display the text | |
| [9] | Silva R G, Reuben R L, Baker K J, et al. Tool Wear Monitoring of Turning Operations by Neural Network and Expert System Classification of a Feature Set Generated from Multiple Sensors[J]. Mechanical Systems and Signal Processing, 1998, 12(2): 319-332 |
| Click to display the text | |
| [10] | Li Xiaoli, Yuan Zhejun. Tool Wear Monitoring with Wavelet Packet Transform-Fuzzy Clustering Method[J]. Wear, 1998, 219(2): 145-154 |
| Click to display the text | |
| [11] | Tomas Kalvoda, Hwang Yeanren. A Cutter Tool Monitoring in Machining Process Using Hilbert-Huang Transform[J]. International Journal of Machine Tools & Manufacture, 2010, 50(5): 495-501 |
| Click to display the text | |
| [12] | 徐创文, 陈花玲, 程仲文, 等. 基于时序分析与模糊聚类的铣削刀具磨损状态识别[J]. 机械强度, 2007, 29(4): 525-531 Xu Chuangwen, Chen Hualing, Cheng Zhongwen, et al. Recognition of Milling Tool Wear Based on Time Series Analysis and Fuzzy Cluster[J]. Journal of Mechanical Strength, 2007, 29(4): 525-531 (in Chinese) |
| Cited By in Cnki (13) | Click to display the text | |
| [13] | Leonard E B, Ted P. Statistical Inference for Probabilistic Functions of Finite State Markov Chains[J]. The Annals of Mathematical Statistics, 1966, 37(6): 1554-1563 |
| Click to display the text | |
| [14] | Zhang Zhenyue, Zha Hongyuan. Principal Manifolds and Nonlinear Dimensionality Reduction via Tangent Space Alignment[J]. SIAM Journal on Scientific Computing, 2004, 26(1): 313-338 |
| Click to display the text | |
| [15] | Leonard E B, Ted Petrie, Norman Weiss. A Maximization Technique Occurring in the Statistical Analysis of Probabilistic Functions of Markov Chains[J]. The Annals of Mathematical Statistics, 1970, 41(1), 164-171 |
| Click to display the text | |
| [16] | Andrew J V. Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm[J]. IEEE Trans on Information Theory, 1967, 13(2): 260-269 |
| Click to display the text | |
| [17] | MacQueen J. Some Methods for Classification and Analysis of Multivariate Observations[C]//Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, 1967, 1(14): 281-297 |
| Click to display the text |