



2. 云南交通投资建设集团有限公司, 云南 昆明 650000
图像修复是用图像已知信息填充图像缺失区域的技术, 在分散目标、删除无用对象或生成遮挡区域等领域有广泛应用。
目前, 图像修复算法主要分为传统算法和基于深度学习的方法2类。传统算法中较早、较经典的有基于范例的方法[1], 该方法在补丁周围求解全局最优完成图像填充, 容易造成结构差异, 使填充区域与整体不一致, 且算法对初始化敏感, 容易陷入局部极值。Barnes等[2]于2009年提出PatchMatch算法, 利用随机搜索和快速传播找到图像块之间的最近邻匹配, 产生比较合理的细节纹理, 但不能很好捕获高级语义信息, 导致修复细节模糊。为避免以上复制邻近区域填充缺失区域的不足, Huang等[3]提出结合平面视角和平移规则2种中层结构约束的图像修复算法, 显著提高了缺失区域合成的质量, 但难免存在错误检测的纹理细节, 从而在缺失区域的纹理和边缘处产生伪影。
为了弥补传统修复算法语义一致性差、存在边缘模糊及伪影等不足, 深度卷积神经网络(deep convolutional neural networks, CNNs)在图像修复方面得到广泛应用[4-5], 对抗性网络[6]被用来改善修复结果的感知质量和自然性。Cai等[7]提出了一种新的风格提取器PiiGAN, 并引入一致性损失来指导生成器学习与输入图像语义相匹配的各种样式, 该方法能修复大面积规则缺失区域, 但是在处理随机分布、大面积不规则孔洞时, 会导致周围区域不一致的模糊纹理。Li等[8]提出了一种新的生成模型, 该方法嵌套了2个生成对抗网络, 在子对抗生成网络中引入了一种新的残差连接结构来传输信息, 有利于修复小面积规则的图像, 但在处理大面积、随机不规则孔洞时, 会产生伪影、结构扭曲等情况。Pathak等[5]提出特征学习驱动的(context encoder, CE)方法, 可以修复缺失面积规则的图像, 该方法在处理随机不规则孔洞时性能下降。Satoshi等[4]提出局部和全局一致的图像修复算法, 其主要实现缺失区域为中心矩形的图像修复, 该方法在处理大面积、随机不规则孔洞时, 不能根据孔洞尺寸、孔洞的随机位置自适应修复图像, 因此当孔洞覆盖边缘时, 会导致边缘模糊或失真。为了更好修复随机不规则孔洞的结构信息并增强细节, Yu和Yan等[9-10]将基于CNNs的方法与基于范例的方法结合, 用掩码引导编码器将特征从已知区域传播到缺失区域, 此类算法能处理随机分布、尺寸较小的不规则孔洞, 但是复制和增强操作只在一个编码和解码层进行, 因此处理大面积、随机不规则孔时性能较差。刘波宁等[11]等基于文献[4]提出的模型, 在全局判别器网络中增加了检测边缘结构信息的约束, 在局部判别器网络中增加了缓冲池技术, 该方法能使矩形掩码的修复结果更加符合视觉连贯性, 抑制过度学习, 但当孔洞随机分布、不规则时, 会出现失真、修复伪影等情况。此外, 以上模型都是采用标准卷积, 对所有输入像素均无区别地视为有效像素处理, 因此修复随机不规则孔洞时, 容易出现颜色差异、模糊或在孔洞周围产生明显的边缘效应。
为了更好地修复随机不规则孔洞并抑制视觉伪影, Liu等[12]提出了部分卷积(Pconv), 解决标准卷积的不足, 改进掩码更新机制, 能处理随机不规则形状的孔洞并抑制视觉伪影。但是, 当孔洞的面积变大时, 修复结果缺乏整体和细节的语义一致性。
为了有效修复大面积、随机不规则孔洞缺失, 提出了基于双判别生成对抗网络的不规则孔洞的图像修复算法, 其主要创新点在于: ①设计图像生成器为部分卷积定义的U-Net架构, 归一化的部分卷积仅对有效像素完成端到端的掩码更新, U-Net中的跳过链接将图像的上下文信息向更高层分辨率传播; ②提出了重建损失、感知损失和风格损失的加权损失函数, 优化训练模型; ③加权损失函数, 结合生成网络和双判别网络一起训练, 进一步增强待修复区域的细节和整体一致性。实验表明: 提出算法在修复大面积、不规则随机孔洞时, 生成的内容清晰、连贯, 孔洞区域的生成图像有合理的整体和细节语义一致性。
1 合成和全局一致的部分卷积 1.1 生成网络在填充随机不规则形状孔洞时, 为了保持孔洞区域的整体语义一致性, 以部分卷积网络为基础, 提出了一种新颖的修复结构, 该结构由3个网络组成: 生成网络、合成判别器、全局判别器。其网络结构如图 1所示。

|
| 图 1 网络模型 |
Pconv[12]层包括2个步骤: ①部分卷积运算;②掩码更新。第一个过程表示为
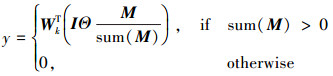
|
(1) |
式中:I是输入特征图;M是二进制掩码(1表示有效像素;0表示无效像素);Wk是第k层卷积滤波器的权值;Θ表示为逐元素乘法;y是第k层输出的新特征值。缩放因子1/sum(M)通过适当的不断缩放调整有效输入的变化量。
每次部分卷积操作之后, 进行掩码更新
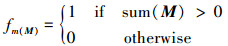
|
(2) |
只要有连续的卷积操作, 且掩码输入包含任何有效像素, 掩码端到端的更新确保缺失区域最终会被修复。
1.1.2 生成网络生成网络以U-Net的架构[13]为基础, 为了更好获取随机不规则边界的信息, 将所有卷积层替换为部分卷积层。
编码阶段包括7个部分卷积层, 步长均为2, 内核大小分别为5, 5, 3, 3, 3, 3, 3, 对应的通道大小为64, 128, 256, 512, 512, 512, 512, 采用ReLU作为激活函数。解码阶段包括7个最近邻上采样, 每一个上采样后面都有一个部分卷积层, 内核大小均为3, 通道大小分别是512, 512, 512, 256, 128, 64和3, 用α=0, 2的LeakyReLU作为激活函数, 在输出的最后一层采用标准卷积, 用Sigmoid作为激活函数。
U-Net网络的跳过链接可以使上采样得到的高维特征与对应编码阶段的特征图拼接, 使得输出更准确。此外, 在生成网络中, 除了第一层和最后一层的部分卷积之外, 在其余每个部分卷积和ReLU/LeakyReLU层之间均使用了批量归一化。
1.2 判别网络合成判别器和全局判别器的目标是识别真实图像与合成图像之间的差别, 并进一步缩小差距。该网络基于卷积神经网络, 将图像压缩成低维度的特征向量。网络的输出由一个连接层连接, 该连接层通过损失函数预测一个连续的值, 该值是图像接近真实图像的概率。
将未掩蔽区用真实图片覆盖, 掩蔽区不做任何处理作为合成判别器的输入, 将整张修复图作为全局判别器的输入。合成判别器和全局判别器均包括7个卷积层, 步长均为2, 内核大小均为5, 对应的通道为64, 128, 128, 256, 256, 256和256, 最后经过一个全连接层输出128维向量。
将合成判别器和全局判别器的输出连接成一个256维的向量, 然后由单个的全连接层进行处理, 输出一个连续的值表示图像接近真实图像的概率。
1.3 损失函数为了更好地恢复预测的孔洞值与周围环境的平滑程度及一致性, 加入了针对每像素的重建损失[12], 感知损失[14], 风格损失[15], 对抗性损失[6]以及全变差正则项作为平滑的惩罚项。
1.3.1 像素重建损失定义孔和非孔每像素在L2范式上的损失
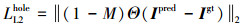
|
(3) |
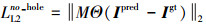
|
(4) |
式中:Ipred是生成网络的输出图像;Igt是真实图像, M是初始的二进制掩码(孔洞区为0), (3)式和(4)式分别表示孔洞区和非孔区的输出。
1.3.2 感知损失、风格损失为了获取高层语义, 比较生成图像的深层特征图与真实图像的差异, 在定义感知损失和风格损失时引入了在ImageNet上预先训练的VGG-16网络[16], 在实验中使用预先训练的VGG-16的pool-1、pool-2、pool-3层。
感知损失定义为

|
(5) |
风格损失定义为
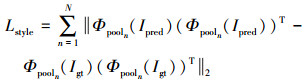
|
(6) |
式中:Ipred是生成网络的输出图像;Igt是真实图像;Φpooln是VGG-16中第n层池化层的特征图。
1.3.3 对抗性损失为了提升结果的真实性, 提高生成图像的视觉质量, 引入对抗性损失函数[6]
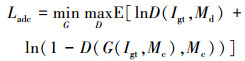
|
(7) |
式中:Igt是真实图像;Md是任意形状的掩码;G是生成网络;Mc是生成网络的输入掩码;D表示判别器。G(Igt, Mc)是生成网络的预测图。
1.3.4 惩罚项为了使图像在修复过程中能有效去除噪声, 同时保留图像的边缘结构, 使结果不会过度平滑, 引入全变差正则化(the total variation, TV)作为平滑性的惩罚项[17]
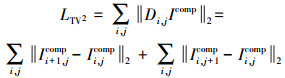
|
(8) |
式中,Di, jIcomp表示合成图像Icomp在像素(i, j)处沿水平和垂直方向的一阶有限差分。在L2范式下, 该公式是各向同性全变差, 具有旋转不变性, 在修复过程中能够很好地保持图像边缘信息。
加权上述损失函数, 提出修复模型的目标函数为
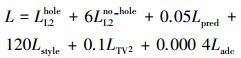
|
(9) |
网络训练的流程如算法1所示。
算法1 网络训练流程
输入: 受损原图X, 随机掩码M;
1) 从训练数据中批量采样图像x, 为每一批图像中的每一张图像生成随机掩码, 获得受损图像;
2) if stage==1:
3) 训练生成器=True; 训练判别器=False;
4) epochs为30, 每轮5 000次迭代, 在重建损失、感知损失、风格损失和TV惩罚项的加权损失函数下更新生成网络, 得到修复图;
5) elif stage==2:
6) 训练生成器=False; 训练判别器=True;
7) epochs为5, 每轮2 000次迭代, 在对抗性损失函数下更新判别器;
8) elif stage==3:
9) 训练生成器=True; 训练判别器=True;
10) 加权所有损失函数来更新整个网络, epochs为5, 每轮2 000次迭代。
2 实验及分析用Place365标准数据集的4个场景验证提出算法的有效性, 并将其与现有的5种经典算法进行对比。3个场景的类别是barn、barndoor、chalet, 每个类别有5 000个图像, 每类中随机选择16幅图像, 从训练集中删除, 构成验证集。实验在Win7系统单个NVIDIA GeForce RTX 2080(8 GB)的Pycharm平台上完成。
2.1 实验过程训练分为3个阶段: 首先, 使用公式(9)中去除Ladc部分的损失函数训练生成网络, 批处理大小设为6, 每轮5 000次迭代, 共30轮, 学习率为0.000 2。然后固定生成网络, 使用Ladc损失函数训练2个判别器, 批处理大小设为6, 每轮2 000次迭代, 共5轮, 学习率为0.05。合成判别器的输入图像的未掩蔽区域用原图覆盖, 掩蔽区域保持生成网络修复结果, 不做处理。全局判别器的输入图像是生成网络修复的图像。最后, 将生成网络和2个判别器联合训练, 批处理大小设为6, 每轮2 000次迭代, 共5轮, 学习率为0.000 2。
测试时, 加载训练的模型测试图像, 只需要生成网络, 不再进行判别网络的判断。
2.2 实验结果与分析图 2a)为待修复原图, 掩码区域面积大且密集。PM修复的房子细节模糊, 框内右侧区出现大面积失真, 无结构信息, 见图 2b)。GL的整体修复出现严重扭曲现象, 修复区域有明显的合成痕迹和大面积伪影, 见图 2c)。文献[11]的修复结果从周围索引信息时, 出现了结构偏差, 见图 2d)。Shift_net的修复结果无伪影, 但很多区域(见框中)的细节被过度平滑, 如草地部分, 修复结果的整体语义一致性较差, 见图 2e)。图 2f)是Pconv的结果, 框中区域的修复不平滑,平衡纹理的能力欠佳。本文算法修复的结果整体语义一致性好, 纹理和细节完整, 右侧区域的修复结果与周围环境平滑融入, 草地的纹理清晰, 见图 2g)。

|
| 图 2 对比实验1 |
图 3a)中的掩码位置随机且分散。PM的房子下部修复结果(框中内容)无结构信息, 无法准确获取图像语义信息。GL修复的房屋上部的结构存在伪影和扭曲, 有明显的合成痕迹。文献[11]在黄框内的修复结果出现了颜色失真以及结构信息的缺失。Shift_net的修复结果没产生伪影, 但框内的修复结果较模糊。Pconv在框内的修复结果未能体现图像颜色信息, 对色彩还原效果不足。本文算法的结果兼顾了纹理细节、结构和颜色信息, 在视觉上获得了更好的修复结果。

|
| 图 3 对比实验2 |
图 4a)为待修复的原图, 掩码区域疏密适中。PM对框内区域的修复结果无结构信息。GL的修复结果存在大面积伪影, 缺失区域有明显的修复痕迹, 如房屋上部的天空。文献[11]的修复结果出现局部的细节模糊(见框中)。Shift_net对框内区域过度平滑, 颜色单调的天空修复后包含了掩码痕迹。Pconv在框内的修复结果存在模糊的合成痕迹。本文算法的结果在天空区域无掩码痕迹, 对其余掩码区的修复在色彩、纹理细节上与周围区域一致性好。

|
| 图 4 对比实验3 |
从以上不规则、随机大面积掩码的修复结果可看出: PM修复的结果无结构信息, 修复区域与周围环境连贯性差。GL在待修复区域产生伪影和不同程度的扭曲。Shift_net的修复结果存在过度平滑导致的模糊、颜色信息丢失, 有时平衡结构、纹理细节的能力欠佳。Pconv方法对不规则掩码的修复效果好, 而对复杂的大面积掩码区域, 其修复结果的纹理细节与周围环境的语义一致性差。相比较而言, 本文算法的修复结果无过度平滑, 清晰度高, 在缺失区域无明显的边缘效应, 能更好地获取缺失区域的语义信息, 使修复结果清晰、连贯。
本文用峰值信噪比(peak signal to noise ratio, PSNR), 结构相似性(structural similarity index, SSIM), 梯度幅相似性偏差(gradient magnitude similarity deviation, GMSD), 计算时间4个指标对以上算法的所有组的平均修复结果进行定量评价。
对比表 1的实验结果可知, 本文在PSNR、SSIM和GMSD指标上均优于对比算法, 说明生成网络使用部分卷积和合成及全局双判别器, 能有效改善生成网络的预测判别能力。因为增加了判别网络, 将标准卷积层改为部分卷积层, 本文算法的运行时间优于文献[11], 但是比其他对比算法长。
本文提出了一种基于双判别生成对抗网络的随机、不规则大面积孔洞图像修复算法, 该算法将U-Net架构的卷积改进为归一化的部分卷积, 仅对有效像素完成端到端的掩码更新, 更好地将图像的上下文信息向高层分辨率传播; 提出了重建损失、感知损失和风格损失的加权损失函数, 优化训练模型, 增强了细节修复能力; 加权损失函数结合生成网络和双判别网络一起训练, 增强修复区域的整体和局部语义一致性。在公开数据集上对本算法与其余4个经典算法进行了定性和定量的实验对比, 实验结果表明: 本文算法能很好修复随机不规则大面积孔洞, 修复结果有很好的整体和局部语义一致性, 避免了过度平滑、纹理模糊、颜色失真、存在人工边缘等缺陷。后续研究中, 要进一步改进算法复杂度, 减少算法的运行时间。
| [1] | WEXLER Yonatan, SHECHTMAN Eli, IRANI Michal. Space-time completion of video[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2007, 29(3): 463-476. DOI:10.1109/TPAMI.2007.60 |
| [2] | BARNES C, SHECHTMAN E, FINKELSTEIN A, et al. Patchmatch: a randomized correspondence algorithm for structural image editing[J]. ACM Transactions on Graphics-TOG, 2009, 28(3): 24. |
| [3] | HUANG Jiabin, KANG Singbing, NARENDRA Ahuja, et al. Image completion using planar structure guidance[J]. ACM Transactions on Graphics, 2014, 33(4): 1-10. |
| [4] | SATOSHI Iizuka, EDGAR Simo-Serra, HIROSHI Ishikawa. Globally and Locally Consistent Image Completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14. |
| [5] | PATHAK Deepak, KRAHENBUHL Philipp, DONAHUE Jeff, et al. Context encoders: feature learning by inpainting[C]//Conference on Computer Vision and Pattern Recognition, 2016 |
| [6] | GOODFELLOW Ian, POUGET-ABADIE Jean, MIRZA Mehdi, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems, 2014 |
| [7] | CAI W, WEI Z. PiiGAN: generative adversarial networks for pluralistic image inpainting[J]. IEEE Access, 2020, 8(1): 48451-48463. |
| [8] | LI Z, ZHU H, CAO L, et al. Face inpainting via nested generative adversarial networks[J]. IEEE Access, 2019, 7: 1-1. DOI:10.1109/ACCESS.2018.2876146 |
| [9] | YU Jiahui, LIN Zhe, YANG Jimel, et al. Generative image inpainting with contextual attention[C]//Conference on Computer Vision and Pattern Recognition, 2018 |
| [10] | YAN Zhaoyi, LI Xiaoming, LI Mu, et al. Shift-net: image inpainting via deep feature rearrangement[C]//The European Conference on Computer Vision, 2018 |
| [11] |
刘波宁, 翟东海. 基于双鉴别网络的生成对抗网络图像修复方法[J]. 计算机应用, 2018, 38(12): 3557-3562, 3595.
LIU Boning, ZHAI Donghai. Image completion method of generative adversarial networks[J]. Journal of Computer Application, 2018, 38(12): 3557-3562, 3595. (in Chinese) DOI:10.11772/j.issn.1001-9081.2018051097 |
| [12] | LIU Guilin, FITSUM A REDA, KEVIN Shih, et al. Image Inpainting for irregular holes using partial convolutions[C]//The European Conference on Computer Vision, 2018 |
| [13] | RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer Assisted Intervention, 2015 |
| [14] | JOHNSON Justin, ALAHI Alexandre, LI Feifei. Perceptual losses for real-time style transfer and super-resolution[C]//The European Conference on Computer Vision, 2016: 694-711 |
| [15] | GATYS L A, ECKER A S, BETHGE M, et al. Image style transfer using convolutional neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2016 |
| [16] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//International Conference on Learning Representations, 2015 |
| [17] | RUDIN L I, OSHER S, FATEMI E. Nonlinear total variation based noise removal algorithms[J]. Physica D: Nonlinear Phenomena, 1992, 60(1): 259-268. |
2. Yunnan Communications Investment and Construction Group Co., Ltd, Kunming 650000, China
