

2. 延安大学 数学与计算机科学学院, 陕西 延安 716000;
3. 徐州工程学院 数理学院, 江苏 徐州 221111
迭代学习控制(ILC)[1]是一种简单有效的学习控制策略, 适用于在固定有限时间间隔内重复运行的被控系统。在足够的学习时间, 可以用较少的先验模型知识和较少的在线计算来提高系统的跟踪性能。基于其优势, ILC已经成为研究热点, 广泛应用于移动机器人、工业过程控制、交通信号控制等多个领域[2-4]。2001年, Chen等[5]首次提出了PDα-型分数阶迭代学习控制算法, 在频域内讨论了算法的收敛性, 并将迭代学习控制的应用范围推广到分数阶系统, 即分数阶迭代学习控制(FOILC)。FOILC除了具有传统迭代学习控制的优点外, 还可以提高具有分数阶特性的被控系统的性能。近年来, FOILC在时域方面取得了丰硕的成果, Lazarevic等[6-7]证明了PDα-型、开闭环PDα-型分数阶迭代学习算法的收敛性和稳定性。Li等[8-9]提出了几种分数阶迭代学习算法, 并讨论了其收敛性和稳定性。lan等[10]研究了Dα-型分数阶迭代学习算法的收敛性问题。
在上述FOILC设计过程中, 一般都是假定所研究被控系统在每一次的迭代过程中初态都与期望初态一致。但是在实际问题中, 系统的期望初始状态通常是未知的, 不可能保证初始状态值等于期望的初始状态值。因此, 研究具有初始状态偏差的系统控制算法的鲁棒性是非常重要的。迄今为止, 关于分数阶系统的初态问题的研究还很少。对于一类具有固定初始状态误差的分数阶线性定常系统, 文献[11]首次提出了一种具有初始状态学习的开闭环P型ILC算法, 得到了算法收敛的充分条件。文献[12]设计了具有初始状态学习的开环和闭环P型ILC方案。文献[13]将上述算法应用于一类分数阶非线性时滞系统。文献[14]针对一类具有初始状态漂移的分数阶线性定常系统, 提出了一种新的修正PDα-型FOILC算法。
目前对分数阶系统的跟踪控制研究中, 主要是利用λ-范数对跟踪误差进行测量。与λ-范数相比, Lebesgue-p范数更适合分析控制算法的学习行为[15-18]。
基于上述问题, 本文针对一类具有任意初始状态的分数阶线性时不变系统, 提出了具有初始状态学习的开环和开闭环PDα-型FOILC算法, 并在Lebesgue-p范数意义下分析了算法的收敛性。
1 预备数学知识本节首先给出一些相关的数学知识。
定义1 对于连续时变向量函数
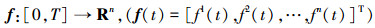
|
则λ-范数和Lebesgue-p范数分别为

|
引理1[18] 设函数g(t), h(t)(t∈[0, T])为勒贝格积分, 若函数g(t)与h(t)的卷积
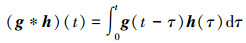
|
存在, 则卷积积分的广义Young不等式为
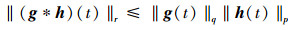
|
有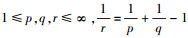
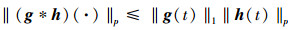
|
定义2 Riemann-Liouville′s(R-L)的左侧和右侧分数阶积分的定义为
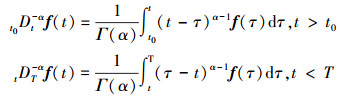
|
式中, α>0, Γ(·)为Gamma函数。
Caputo左侧和右侧分数阶微分的定义分别为
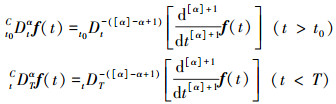
|
式中, α∈R+, [α]是α的整数部分。
性质1[19] 如果f(t)∈C[t0, ∞), 则
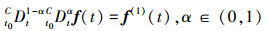
|
其中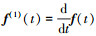
引理2[20] 如果函数f(t), g(t)在区间[0, T]上连续, tCDTαf(t), 0CDtαg(t)都存在, 且在[0, T]上连续, 则有分部积分法

|
定义3[19] 双参数的Mittag-Leffler函数的定义为
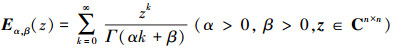
|
特别地, 当β=1时, 单参数的Mittag-Leffler函数的定义为
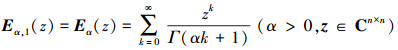
|
引理3[15] 设Φα, β(t)=tβ-1Eα, β(Atα), t∈[0, +∞), 其中, α>0, β>0, A∈Cn×n, 则
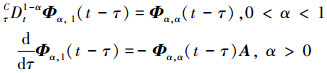
|
引理4[21] 初值问题
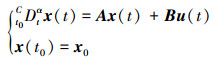
|
等价于下面的积分方程
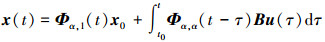
|
式中, A∈Cn×n, B∈Cn×p, 0 < α < 1。
引理5[22] 假设zi∈R, δi∈R(i∈Z+)为2个实数序列, 满足|zi+1|≤θi|zi|+|δi|, ∀i∈Z+。其中, 0<θi≤θ < 1, θ为常数。当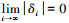
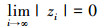
|
考虑一类分数阶线性时不变系统
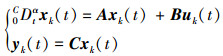
|
(1) |
式中, t∈[0, T], α∈(0, 1);xk(0)∈Rn, uk(t)∈Rp和yk(t)∈Rq分别为系统第k次重复操作的状态向量、控制输入向量和输出向量; A∈Rn×n, B∈Rn×p和C∈Rq×n都为常数矩阵。
下面给出了分数阶系统的一些基本假设。
假设1 对于给定的期望输出yd(t), 0CDtαyd(t)(t∈[0, T])存在, 且只存在期望的控制输入和理想状态, 使得
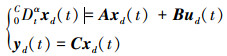
|
(2) |
假设2 CB为行满秩矩阵。
对于分数阶系统(1), 首先考虑具有初始状态学习的一阶开环PDα-型分数阶迭代学习控制算法
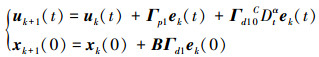
|
(3) |
式中:Γp1和Γd1分别为比例和微分学习增益矩阵;ek(t)=yd(t)-yk(t)为系统第k次迭代时的跟踪误差。
众所周知, 系统运行中的反馈信息可以加速学习过程的收敛速度。因此, 本文进一步研究了具有初始状态学习的开闭环PDα-型分数阶迭代学习控制算法。其表达式如下

|
(4) |
式中, L=(Γp2+Γd2), Γp2, Γd2分别为比例和微分反馈增益矩阵。
显然, 当Γp2=Γd2=0时, 控制算法(4)退化为具有初始状态学习的一阶开环PDα-型算法(3)。
定理1 设分数阶系统(1)满足假设1~2, 当控制律(3)作用于系统(1)时, 若
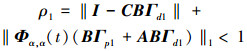
|
则可以得到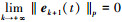
证明: 根据引理4, 系统(1)的状态有如下表达式
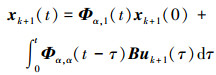
|
(5) |
因此
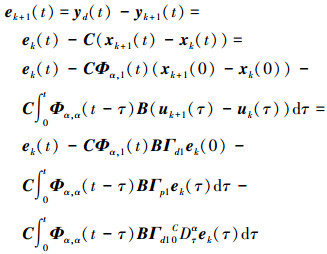
|
(6) |
由引理2和引理3可以得到

|
(7) |
把(7)式带入(6)式, 得
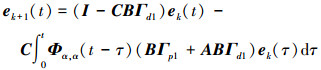
|
(8) |
在(8)式两边同时取Lebesgue-p范数, 采用卷积积分的广义Young不等式, 可以得到
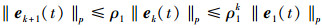
|
(9) |
利用定理1的条件, 取k→∞得到
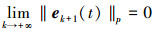
|
因此, 跟踪误差单调收敛到零, 系统的输出在Lebesgue-p范数意义下当k→∞时的[0, T]区间内收敛到期望输出。
定理证毕。
注1 可以看出, 在Lebesgue-p范数意义下, 对于具有任意初始状态的分数阶线性系统, 基于初始状态学习的开环PDα-型算法收敛的充分条件由比例学习和微分学习的学习增益矩阵确定。
注2 与λ-范数意义下的收敛条件相比, 定理1中PDα-型控制算法的收敛条件相对保守, 但度量跟踪误差不再依赖λ取值。
定理2 假设分数阶系统(1)满足假设1~2, 当控制算法(4)应用于系统(1)时, 若满足条件:
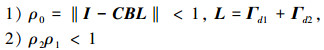
|
式中
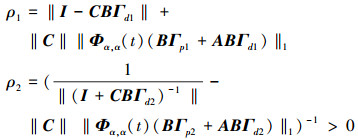
|
则
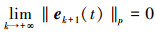
|
证明 将(4)式与(5)式结合, 得到
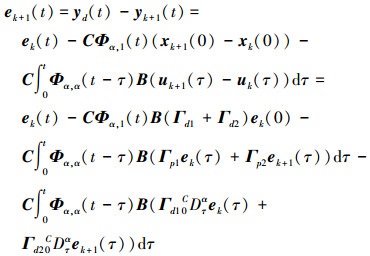
|
(10) |
与(7)式的推导类似, 可以得出这样的结论
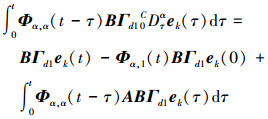
|
(11) |
和
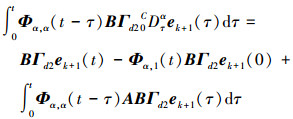
|
(12) |
将(11)式和(12)式代入(10)式可得
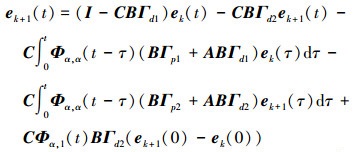
|
(13) |
将t=0代入(12)式可得

|
(14) |
在(14)式两边同时取范数, 可得
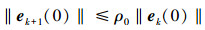
|
(15) |
式中, ρ0=‖I-CBΓd1-CBΓd2‖。
因此, 根据条件1), 可以得出结论
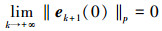
|
(16) |
因此, 表达式(13)采用这种形式

|
(17) |
根据假设2可知, 存在反馈增益微分矩阵Γd2, 使得矩阵I+CBΓd2是非奇异矩阵。因此, 在(17)式的两边左乘(I+CBΓd2)-1, 两边同时取Lebesgue-p范数, 采用卷积积分的广义Young不等式, 可得
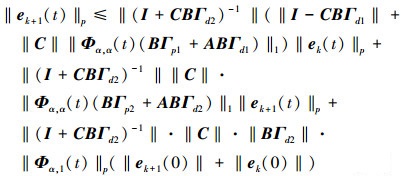
|
(18) |
进一步
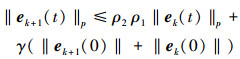
|
(19) |
式中
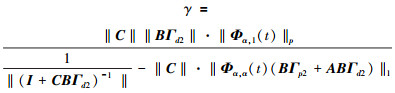
|
(20) |
根据定理2和引理5的条件, 取k→∞, 可以得出以下结论
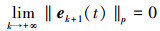
|
(21) |
定理证毕。
注3 定理2的收敛条件ρ2ρ1 < 1不要求满足ρ1 < 1或ρ2 < 1。因此, 在控制算法(4)中, 学习增益矩阵有了更多的选择。
注4 观察定理1和定理2的证明, 控制算法的收敛条件是充分的和不必要的。即当不满足收敛条件时, 在控制算法的作用下, 系统的跟踪误差仍可能趋于零。
注5 根据定理1和定理2的收敛条件, 当满足条件ρ2ρ1<ρ1 < 1时, 开闭环PDα-型算法(4)的收敛速度比开环PDα-型算法(3)的收敛速度快。
3 数值仿真考虑如下分数阶线性连续时不变系统

|
(22) |
系统(22)的重复操作区间设为[0, 1]: 所期望的输出为yd(t)=0.8tsin2πt, t∈[0, 1]。第一次迭代的初始状态x1(0)是随机选择的, 但不等于期望的初始状态xd(0)。此外, 初始控制输入u1(t)(t∈[0, 1])由Rand函数随机生成。
设置控制算法(3)的相关参数为: Γp1=0.9, Γd1=1.6, 计算可得ρ1=0.893 7 < 1, 满足定理1的收敛条件。
为了更好地说明所提出的具有初始状态学习的开环PDα-型算法的性能, 通过对比, 采用了传统的一阶开环PDα-型算法。将传统PDα-型算法应用于具有任意初始状态的系统(22)时, 系统(22)在第4次和第12次迭代时的输出以及从第1次迭代到第30次迭代的跟踪误差曲线分别如图 1和图 2所示。很明显, 随着迭代次数的增加, 系统输出与期望输出之间存在偏差。也就是说, 系统的实际输出不能准确地跟踪给定的期望输出, 只能渐进地落在期望输出的一个小邻域内。此时, 在Lebesgue-2范数和上确界范数的意义下, 系统在整个区间[0, 1]的跟踪误差都是收敛有界的。

|
| 图 1 一阶PDα-型控制算法跟踪曲线 |

|
| 图 2 一阶PDα-型控制算法的跟踪误差变化趋势 |
将提出的PDα-型算法(2)应用于任意初始状态的系统(22)时, 系统(22)第4次和第12次迭代的输出如图 3所示, 跟踪误差如图 4所示。

|
| 图 3 初态学习的一阶PDα-型控制算法跟踪曲线 |

|
| 图 4 初态学习的一阶PDα-型控制算法的跟踪误差变化趋势 |
显然, 系统的输出可以完全跟踪期望输出, 并且跟踪误差随着迭代次数的增加单调收敛到零。以上结果表明, 对于具有任意初始状态的系统(22), 所提出的算法(3)是可行和有效的。
控制算法(4)的相关参数设置为: Γp1=0.9, Γd1=1.9, Γp2=0.3, Γd2=2。计算可得ρ1=0.860 1 < 1, ρ2ρ1=0.670 2 < 1, ρ2ρ1 < ρ1 < 1。显然, 满足定理1和定理2中的收敛条件。
在上述条件下, 将本文提出的PDα-型算法(3)和(4)分别应用于任意初始状态的系统(22), 系统的跟踪误差如图 5所示。

|
| 图 5 算法(3)和算法(4)跟踪误差比较 |
可以看出, 在Lebesgue-2范数意义下, 随着迭代次数的增加, 本文算法(3)和(4)的跟踪误差单调地趋于零。此时, 当算法(4)迭代7次时, 跟踪误差达到误差范围0.004, 而算法(3)需要11次迭代才能达到上述效果。因此, 在给定适当的学习增益下, 算法(4)比算法(3)具有更快的收敛速度和更高的控制精度。
4 结论本文针对一类具有任意初始状态的分数阶线性连续系统, 为了消除任意初始状态对系统的影响, 提出了带初始状态学习的开环和开闭环PDα-型FOILC算法。在Lebesgue-p范数意义下, 利用卷积积分的广义Young不等式, 讨论了PDα-型算法的收敛性。理论分析和数值仿真表明, 该PDα-型算法应用于任意初始状态系统时, 随着迭代时间的增加, 跟踪误差单调收敛于零。
随着迭代学习控制和分数阶系统理论的进一步发展, 还可以将分数阶迭代学习控制应用于分布参数系统、多智能体系统和切换系统的控制之中。
| [1] | ARIMOTO S, KAWAMURA S, MIYAZAKI F. Bettering operation of robotics by learning[J]. Journal of Robotic System, 1984, 12(2): 123-140. |
| [2] | WANG W, CHEN J, MAO L. Two-wheeled mobile robot tracking based on iterative learning control[J]. Advanced Materials Research, 2012, 433: 5866-5870. |
| [3] | LIU T. Flexible closed-loop iterative learning control for industrial batch processes with state delay and time-varying uncertainties[J]. IFAC Proceedings Volumes, 2012, 45(13): 225-230. DOI:10.3182/20120620-3-DK-2025.00032 |
| [4] | YAN F, TIAN F L, SHI Z K. Iterative learning approach for traffic signal control of urban road networks[J]. IET Control Theory and Applications, 2017, 11(4): 466-475. DOI:10.1049/iet-cta.2016.0376 |
| [5] | CHEN Y Q, MOORE K L. On Dα-type iterative learning control[C]//Proceedings of the 40th IEEE Conference on Decision and Control, 2001 |
| [6] | LAZAREVIC M P. PDα-type iterative learning control for fractional LTI system[C]//Proceedings of the 16th International Congress of Chemical and Process Engineering, 2004 |
| [7] | LAZAREVIC M P, MANDIC P. Feedback-feedforward iterative learning control for fractional order uncertain time delay system-PD alpha type[C]//Proceedings of the International Conference on Fractional Differentiation and Its Applications, 2014 |
| [8] | LI Y, CHEN Y Q, AHN H S. Convergence analysis of fractional-order iterative learning control[J]. Control Theory and Applications, 2012, 29(8): 1031-1037. |
| [9] | LI Y, CHEN Y Q, AHN H S. Fractional-order iterative learning control for fractional-order linear systems[J]. Asian Journal of Control, 2011, 13(1): 54-63. DOI:10.1002/asjc.253 |
| [10] | LAN Y H, ZHOU Y. Dα-type iterative learning control for fractional-order linear time-delay systems[J]. Asian Journal of Control, 2013, 15(3): 669-677. DOI:10.1002/asjc.623 |
| [11] | LIU X H, Li Y F. The convergence analysis of p-type iterative learning control with initial state error for some fractional system[J]. Journal of Inequalities and Applications, 2017, 2017(1): 29. DOI:10.1186/s13660-017-1302-6 |
| [12] | LAN Y H. Iterative learning control with initial state learning for fractional order nonlinear systems[J]. Computers Mathematics with Applications, 2012, 64(10): 3210-3216. DOI:10.1016/j.camwa.2012.03.086 |
| [13] | LI Y, JIANG W. Factional-order nonlinear systems with delay in iterative learning control[J]. Applied Mathematics and Computation, 2015, 257(suppl): 546-552. |
| [14] | LI L. Rectified fractional order iterative learning control for linear system with initial state shift[J]. Advances in Difference Equations, 2018, 2018(1): 12. DOI:10.1186/s13662-018-1467-4 |
| [15] | LI L. Lebesgue-p norm convergence of fractional-order PID-type iterative learning control for linear systems[J]. Asian Journal of Control, 2018, 20(1): 483-497. DOI:10.1002/asjc.1561 |
| [16] |
张克军, 彭国华. 具有反馈信息的PDα-型迭代学习控制率在Lebesgue-p范数意义下的收敛分析[J]. 西北工业大学学报, 2017, 35(2): 310-315.
ZHANG Kejun, PENG Guohua. Convergence analysis of PDα-type iterative learning control with feedback information in the sense of lebesgue-p norm[J]. Journal of Northwestern Polytechnical University, 2017, 35(2): 310-315. (in Chinese) DOI:10.3969/j.issn.1000-2758.2017.02.022 |
| [17] |
张克军, 彭国华. PDα-型分数阶迭代学习控制在Lp范数意义下的收敛性分析[J]. 系统工程与电子技术, 2017, 39(10): 2285-2290.
ZHANG Kejun, PENG Guohua. Convergence analysis of PDα-type fractional-order iterative learning control in the sense of Lp norm[J]. Systems Engineering and Electronics, 2017, 39(10): 2285-2290. (in Chinese) |
| [18] | RUAN X, BIEN Z Z, WANG Q. Convergence properties of iterative learning control processes in the sense of the lebesgue-p norm[J]. Asian Journal of Control, 2012, 14(4): 1095-1107. DOI:10.1002/asjc.425 |
| [19] | PODLUBNY I. Fractional differential equations[M]. San Diego: Academic Press, 1999. |
| [20] | SAMKO S G, KILBAS A A, MARICEV O I. Fractional integral and derivatives: theory and applications[M]. Switzerland: Gordon and Breach, 1993. |
| [21] | KILBAS A A, SRIVASTAVA H, TRUJILLO J J. Theory and applications of fractional differential equations[M]. New York: Elsevier, 2006. |
| [22] |
卜旭辉, 侯忠生, 余发山. 一类线性连续切换系统的迭代学习控制[J]. 控制理论与应用, 2012, 29(8): 1051-1056.
BU Xuhui, HOU Zhongsheng, YU Fasha. Iterative learning control for a class of linear continuous-time switched systems[J]. Control Theory and Applications, 2012, 29(8): 1051-1056. (in Chinese) |
2. College of Mathematics and Computer Science, Yan'an University, Yan'an 716000, China;
3. School of Mathematics and Physical Sciences, Xuzhou Institute of Technology, Xuzhou 221111, China
