

大数据时代下,基于ACID模型的传统关系型数据库不适合存储和分析大规模数据集。基于CAP模型的NoSQL数据库应运而生,其扩展性很好地解决了这个问题,但弱化了数据一致性,不适合一些应用场景,如银行业务。为兼顾这2种数据库的优势,NewSQL数据库[1]基于NoSQL数据库设计存储层,基于传统数据库设计事务层,达到高扩展同时满足ACID的目的,如MemSQL[2]、VoltDB[3]、Oceanbase[4]等。
读写分离机制[5]是NewSQL数据库常用的一种策略,其将写操作定位到单个事务节点(事务层),将读操作定位到分布式存储节点(存储层),实现传统关系型数据库的ACID特性,并支持并行数据读取。这种架构下,为缓解事务节点压力以及提升查询效率,需要将其上的更改数据(包括更新的数据,插入的数据和修改的修改)同步到分布式存储节点,与基线数据融合成最新的数据,并进行持久化,类似于LevelDB[6]中将“MemTable”中的数据同步到“SSTable”中。为减少记录数据分布信息的元数据大小,通常将数据拆分为多个粗粒度的分区,例如Oceanbase[4]中默认的分区大小为256 MB。在数据同步过程中,以分区为单位,首先将分区对应的更改数据从事务节点拉取到存储节点,然后读取这个分区对应的基线数据到内存,并将其与更改数据进行合并形成新的分区,最后将新的分区持久化到磁盘。由于对于数据是否更改无感知,因此每个分区都需要参与同步。如果基线数据较大,但实际需要同步的分区较少,则会浪费大量额外的网络代价、本地IO代价以及占用大量存储空间。为提出有效解决方案,总结问题如下:
1) 更改数据拉取过程中消耗不必要的网络传输代价;
2) 存储节点加载本地参与同步数据粒度过大,导致需要消耗大量不必要的IO和内存空间处理不参与合并的数据。
为解决这些问题,本文提出一种细粒度数据同步策略,在不改变原始分区的情况下,建立细粒度逻辑分区,将原始粗粒度分区在逻辑上进行细化,提供更精确的分区控制。为使系统感知发生更改的分区,引入更改感知策略,形成更改分区列表。更改发布机制基于更改分区列表驱动同步的进行,限制同步仅发生在更改的分区,解决第一个问题。细粒度逻辑分区能够在加载本地合并数据时,根据更改数据精确定位需要合并的数据,避免读取整个数据到内存,节省磁盘IO代价和内存空间,解决第二个问题。经过测试,细粒度数据同步策略能够大幅提升同步效率,并节省空间开销。
1 相关工作对于传统集中式数据库系统,如PostgreSQL[7]、MySQL[8]、DB2[9]等,更改操作发生在本地,不涉及跨节点数据同步。NoSQL数据库系统,如BigTable[10]、HBase[11]等,牺牲一致性,追求高扩展。HBase将大表切分成多个子表,分布存储在多个物理节点,只支持行级别事务,但能够节点内本地更改。大数据时代应运而生的NewSQL数据库系统,如MemSQL[2]、Oceanbase[4]、VoltDB[3]等,在兼容大数据分析和传统事务处理能力的同时,面临数据同步的性能问题,特别是读写分离情况下,提升性能挑战巨大。如Oceanbase中数据同步过程为:以分区为单位,首先通过网络到事务节点拉取更改的数据到存储节点,然后存储节点将分区(默认256 MB)的数据全部加载到内存,执行合并操作,最后将合并后的数据落盘。
读写分离架构下数据同步执行过程中需要优化的部分包括:获取更改数据到同步执行地点的网络通信代价和本地合并时加载数据的IO代价。因此从这两方面讨论相关的研究。
网络通信:分布式环境下执行连接查询,由于数据的分布存储,需要将一部分数据从一个节点传递到另一个节点,由于无法感知对方数据,因此可能需要传递全部数据,包括不需要进行连接的数据,浪费大量网络代价。为优化这种情况,通常采用半连接[15]的方式降低网络传输量。本研究根据这种思想将传统的更改数据“拉”模式改为更改感知的“推”模式,降低网络传输的次数。实现策略参考文献[17]给出的通过记录更改数据驱动同步的进行。
本地数据加载:更改量很小情况下,存储节点本地只需要加载原始分区数据的一小部分到内存完成合并任务。由于分区数据的粗粒度,导致需要加载全部数据到内存,通过扫描获取需要合并的数据,面临大量不必要的IO消耗以及内存消耗[4]。产生这种问题的原因是无法根据更改数据精确定位数据块。根据多层索引的思想,参考文献[18]中B+Tree思想以及文献[19]中利用B-Tree平衡CPU和磁盘IO代价的策略,本研究将粗粒度的数据库进行细粒度化,为不影响粗粒度带来的优势,建立细粒度逻辑分区,即添加一层索引结构,帮助精确定位需要合并的磁盘数据。
一些其他同步策略,如基于驱动数据的自动同步策略[13],异构数据库之间的同步策略[14]等,适应于某些场景,但不适合分布式读写分离系统的数据同步操作。
因此,现有分布式读写分离系统欠缺高效策略降低事务节点和存储节点之间数据同步的网络代价以及存储节点本地进行数据合并的IO代价和内存占用代价,需要一种新的策略提升数据同步效率并降低空间开销。
2 细粒度同步策略分布式读写分离系统中,大量基线数据分片、分布存储在分布式存储节点中,对这些数据的更改存储于事务节点中。对于数据读取操作,为获取最新数据,需要融合更改数据和基线数据。为提升读取效率,定期将更改数据同步到基线数据中。使用图 1解释整个同步过程(①~⑤)。
① 存储节点根据节点内所有分区(p1~p3)到事务节点拉取对应的更改数据;
② 将拉取的数据(u)存储在内存;
③ 将更改的分区(p3)对应的基线数据(d3)全量读取到内存;
④ 将更改数据和基线进行合并产生新的分区数据(d);
⑤ 将新产生的分区持久化到磁盘。
图 1是以一个存储节点,3个分区为例阐述整个同步过程,实际场景下,规模远大于此。比如有10 GB的基线数据和10 MB的更改数据,假设分区大小为100 MB,则存在103个分区,其中被更改的分区假设为4个,一次磁盘IO读取2 MB数据。一次数据同步操作,至少需要消耗103次网络通信(①),4*(100/2)次本地IO(②),占用4*100 MB内存空间。实际上,参与同步的分区为4个,因此,仅需消耗4次网络通信,而每一个分区中实际参与同步的数据比例很小,不需要全部读取到内存。为实现这个目的,提出细粒度数据同步策略,在原始分区之上构建细粒度逻辑分区,并引入更改感知机制和更改发布机制。

|
| 图 1 分布式读写分离系统中数据同步过程示意图 |
图 2阐述了基于此策略的数据同步过程(①~⑤)。

|
| 图 2 细粒度数据同步过程示意图 |
① 驱动器根据更改感知器生成的更改列表,主动发送需要同步的数据(u1)给对应的存储节点(S5),并指定参与同步的分区(p3);
② 存储节点根据p3对应的块索引定位到需要参与同步的块数据地址(b1, b3);
③ 根据块地址将需要同步的数据块加载到内存;
④ 将块数据与对应更改数据合并生成新的分区数据(d)。
⑤ 将新产生的分区持久化到磁盘。
步骤①将更改数据主动发给对应的更改分区,限制只有更改分区参与数据同步,减少网络开销;步骤②和③避免读取不参与同步的分区数据到内存,降低本地IO和内存开销,同时降低磁盘开销。因此细粒度同步策略能够实现高效的数据同步且降低空间开销。下面章节将详细介绍分布式读写分离的数据模型、细粒度逻辑分区、更改感知机制(由图 2中更改感知器实现)和更改发布机制(由图 2中驱动器实现)。
2.1 数据模型分布式读写分离系统对应数据模型如图 3所示。表数据分为基线数据和更改数据,两部分数据合并形成最新数据。基线数据根据主键进行分区(这里只考虑范围分区),被拆分成多个不重叠的分区(p),分布在存储节点中;同样,更改数据也依据主键拆分成不同的块(a)。更改数据块和基线数据分区不是一一对应关系,而是多对多的关系。

|
| 图 3 分布式读写分离系统数据模型 |
p和a为逻辑分区,使用键值范围表示。如TPC-H[14]中的表ORDER,大小为1 GB,假设分区大小为256 MB,将其按照主键进行范围分区,得到4个分区,分别为p1:[1, 2 212 781], p2:[8 851 110, 17 628 134], p3:[17 628 135, 2 191 795], p4:[26 395 329, 2 192 228]。对其中的分区p2和p3实施更改操作,假设更改的数据范围为a1:[17 620 000, 17 630 000],则p2和p3都需要和a1中的数据进行合并。
2.2 细粒度逻辑分区粗粒度分区利于降低元数据大小,但在数据同步过程中消耗大量额外本地IO和存储空间。细粒度逻辑分区策略在不改变原始分区前提下,将分区(p)细化成多个逻辑块(b),并对其建立块索引,每一个逻辑块对应分区数据中的一个数据块(d),即:
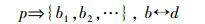
|
(1) |
为避免没有更改的分区参与同步,需要感知更改的分区。更改操作由事务节点完成,因此需要在事务节点缓存2次同步之间更改操作影响的数据范围。这里,我们引入更改列表(LΔ),结构如下。
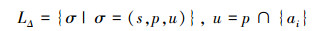
|
(2) |
LΔ包括多项记录,每项记录(σ)由存储节点地址(s),更改的分区(p)以及这个分区对应的更改数据(u)组成。其中s和p可通过元数据信息得到,u由属于这个分区的更改数据组成。引入更改感知机制的目的是填充LΔ。
2.4 更改发布机制为减少网络开销,将基于分区驱动的更改数据拉取操作变为基于LΔ驱动的更改数据分发机制。当数据同步发生时,由事务节点根据CL中的各个记录分发更改数据,过程如下:
1) 依次读取CL中各个记录σ;2)针对每一个σ,根据其记录的存储节点地址(s),将σ发送到对应的存储节点;3)存储节点接受到σ后,根据记录的更改分区(p),通过块索引定位到分区数据中更改的块。
3 算法本章给出2种算法,包括Oceanbase中数据同步算法(O-DS)以及基于细粒度数据同步策略的算法(F-DS)。算法均以伪代码表示。

|
算法输入和输出涉及的分区集合都为逻辑分区集合,即为2.1小节给出的分区概念。O-DS算法实际为全量分区同步策略,针对每一个逻辑分区(p),首先将其对应的更改数据(D(p))拉取到本地,如果对应的更改数据不为空,则加载此分区的数据到内存,进而与更改数据进行合并,生成新的分区数据(M(p′)),最后将此数据持久化到磁盘。当P的基数很大,而其更改的元素数目较少时,O-DS算法将消耗大量额外的网络代价,本地IO代价以及空间资源。针对这些问题,提出F-DS算法,其伪代码描述如下。

|
F-DS的输入为更改列表(LΔ, 参见公式2)和原始分区集合(P),区别于O-DS, F-DS以LΔ为驱动,只同步更改的分区。针对LΔ中每一个记录(σ),异步将它们分发到对应的存储节点(行2),对应存储节点首先根据本地的分区集合(P)以及σ,依据块索引定位到有更改数据的块集合(B),然后将块数据(M(B))加载到内存,与存储在σ中的更改数据(D(B))合并生成新的分区。LΔ驱动保证只同步发生改变的分区,降低F-DS因全量分区拉取更改数据的网络开销;块索引保证读取分区中确实更改的数据,而不是整个分区数据,降低本地IO开销以及空间占用。
4 实验 4.1 实验环境实施F-DS于Oceanbase[4]开源版本0.4.2, Oceanbase架构如图 4所示。

|
| 图 4 Oceanbase架构 |
建立一个九节点集群,其中1台更改服务器,8台存储服务器,其中更改服务器同时充当管理节点,每一个存储节点同时充当查询节点。单个存储节点配置:主频为1 400 MHz的AMD Opteron(TM)处理器和16G内存;物理CPU个数为2,物理核数8个,逻辑核数16个;操作系统为Red Hat 6.2。更改节点将存储节点内存扩展到32G,其他配置相同。
4.2 实验数据由于数据同步和表模式没有关系,因此我们只生成90 GB的LINEITEM表[14]数据。分区大小设置为256 MB,细粒度逻辑分区大小为2 MB。经过对某银行业务进行调查,得出如表 1所示的更改数据比例。D1表示更改数据占基线数据的比例,D2表示D1发生在实际业务中的比例。可以看出,对大量基线数据进行少量更改的情况最常见。
设计2组实验,包括测试F-DS算法的同步效率以及测试F-DS算法的空间占用量。
4.3.1 同步效率本实验设计2个子实验,包括:固定更改率,随着基准数据量的增长,测试数据同步效率,目的是证明在更改率低的情况下(D1(< 1%)),F-DS算法效率优于O-DS算法。测试方法为将更改比例固定在0.1%,通过增加基线数据,观察2种算法的同步执行时间,这里基线数据量使用行数表示,原因是数据同步以行为单位进行,测试结果如图 5;固定基准数据量,增长更改率,测试目的是证明F-DS算法适合数据更改率低的场景。测试方法为固定基准数据量在5 000万行,观察随着更概率的增长,2种算法的同步执行时间,测试结果如图 6所示。

|
| 图 5 固定更改率,随着基准数据量的增长,测试数据同步效率 |

|
| 图 6 固定基准数据量,随着更改率的增长,测试数据同步效率 |
实验分析。如图 5所示,可以看出:随着基准数据量的增长,基于O-DS算法的同步执行时间增长较快,并且远远高于F-DS算法。这里,同步执行时间包括:获取更改数据的时间和存储节点本地合并的时间,我们将从这两方面分析实验结果。O-DS算法是基于全量分区驱动数据同步。随着基线数据的增加,分区数量随之增加,因此以分区为单位拉取更改数据消耗的网络代价随之增加;反之,F-DS算法基于CL驱动数据同步,只有发生更改的分区才会消耗网络代价。而对于参与同步的分区,即使这个分区只更改了小部分的数据,O-DS算法仍然将分区数据一次性全部读取到内存,消耗额外的本地IO;F-DS算法将原始分区进行细粒度化,形成多个逻辑分区,并且基于块索引,结合分区的更改数据,能够准确定位到更改的块,进而避免不必要的本地IO和内存占用。
如图 6所示,可以看出:随着更改率的增长,2种算法的数据同步执行时间都呈现增长的趋势。当更改率≤1%时,基于F-DS算法的同步执行时间远远小于基于O-DS算法的同步执行时间,测试结果和图 5是一致;当>1%且≤10%时,基于F-DS算法的同步执行时间虽然比O-DS算法高,但差别已经不是很大了;当≥30%时,基于F-DS算法的执行时间反而比基于O-DS算法的执行时间高。原因是随着更改率的增长,涉及同步的分区数量随之增长,F-DS算法将更改数据由事务节点“推”到存储节点的优势逐渐降低,并且由于细粒度化底层存储,在检索某个分区中存在数据块的时间也随之增加,而O-DS算法始终将整个分区数据加载到内存,因此当更改率较大时,2种算法的执行效率差别不大,F-DS算法甚至低于O-DS算法。但实验结果证明F-DS算法适合更改率的场景,和预期一致。
4.3.2 空间占用量测试目的是证明基于F-DS算法的数据同步操作对于空间的占用量优于基于O-DS算法的数据同步操作。测试方法为固定更改比例为1%,通过增加分区数目,观察2种算法对于空间的利用率。这里空间利用率表示为数据同步之后,磁盘的空间大小变化,测试结果如图 7所示。根据测试结果可以看出:随着分区个数的增加,基于F-DS算法的空间占用量低于基于O-DS算法的空间占用量。

|
| 图 7 测试空间占用量 |
只要分区被更改,O-DS算法会将分区数据全部读取到内存,然后与更改数据进行合并,生成的新的分区会包含很多没有被更改的数据。而F-DS算法基于块索引,只会将更改的数据块读取到内存,合并产生的新的分区只包含更改的块,因此持久化后的磁盘占用空间将远远小于O-DS算法。同样原理,在内存空间占用量上,F-DS算法低于O-DS算法。
经过对测试结果的分析,可以得出结论:基于F-DS算法的数据同步在空间占用量上低于O-DS算法。
5 结论分布式读写分离系统下的数据同步操作是一种耗时、耗资源的操作。针对大量基线数据,如果更改数据量很小,则需要更细致地控制参与同步的数据。本文提出的细粒度数据同步策略能够利用细粒度分区,更改感知机制以及更改分发机制将参与同步的数据限制在发生更改的数据上,大幅降低网络开销、本地IO开销以及内存占用。
在今后的工作中,我们将依据更改数据的特征,动态调整细粒度分区的大小,以期更细致地控制同步内容,并在更改列表信息过时后,保证数据同步的完备性,以适应各种场景。
| [1] | MONIRUZZAMAN A B M. NewSQL:Towards Next-Generation Scalable RDBMS for Online Transaction Processing(OLTP) for Big Data Management[J]. Computer Science, 2014, 7(6): 121-130. |
| [2] | CHEN J, JINDEL S, WALZER R, et al. The MemSQL Query Optimizer:a Modern Optimizer for Real-Time Analytics in a Distributed Database[J]. Proceedings of the VLDB Endowment, 2016, 9(13): 1401-1412. DOI:10.14778/3007263.3007277 |
| [3] | VOLT D B. VoltDB[EB/OL].(2010-04-11)[2019-01-05]. https: //www.voltdb.com/ |
| [4] |
阳振坤. Oceanbase关系数据库架构[J]. 华东师范大学学报, 2014(5): 141-148.
YANG Zhenkun. The Architecture of Oceanbase Relational Database System[J]. Journal of East China Normal University, 2014(5): 141-148. (in Chinese) DOI:10.3969/j.issn.1000-5641.2014.05.012 |
| [5] | LIN X. System, Method and Database Proxy Server for Separating Operations of Read and Write[P]. USA, Patent Application 15/015, 911 https://nepis.epa.gov/Exe/ZyPURL.cgi?Dockey=P100JEAJ.TXT |
| [6] | Google. LevelDB[EB/OL].(2011-05-01)[2019-01-13]. https: //github.com/Level/levelup/blob/master/README.md |
| [7] | The PostgreSQL Globsal Development Group. PostgreSQL[EB/OL]. (1995-05-01)[2019-01-13]. https: //www.postgresql.org/ |
| [8] | MySQL. MySQL[EB/OL]. (2018-01-30)[2019-01-13]. https: //github.com/mysql/mysql-server/releases/tag/mysql-cluster-7.6.12 |
| [9] | IBM. DB2[EB/OL]. (2009-06-30)[2019-01-13]. https: //public.dhe.ibm.com/software/hk/cobral/ |
| [10] | CHANG F, DEAN J, Ghemawat S, et al. Bigtable:a Distributed Storage System for Structured Data[J]. ACM Trans on Computer Systems, 2008, 26(2): 1-26. |
| [11] | Apache. HBase[EB/OL]. (2018-06-24)[2019-01-05]. http://www-eu.apache.org/dist/hbase/stable |
| [12] | FRIDMAN L, BROWN D E, ANGELL W, et al. Automated Synchronization of Driving Data Using Vibration and Steering Events[J]. Pattern Recognition Letters, 2016, 75: 9-15. DOI:10.1016/j.patrec.2016.02.011 |
| [13] | DAR S A, IQRA J. Synchronization of Data Between SQLite(Local Database) and SQL Server(Remote Database)[J]. IUP Journal of Computer Sciences, 2016, 10(4): 7. |
| [14] | TPC. TPC-H[EB/OL]. (2018-06-02)[2018-09-17]. http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.17.2.pdf |
| [15] | ZHOU L, CHEN Y, LI T, et al. The Semi-Join Query Optimization in Distributed Database System[C]//National Conference on Information Technology & Computer Science, 2012: 606-609 http://cpfd.cnki.com.cn/Article/CPFDTOTAL-SHYZ201211001154.htm |
| [16] | GE C, LI S, YEBAI L I. Research on Query Optimization Technology in Distributed System Based on Semi-Join[J]. Computer & Modernization, 2011, 12(12): 106-108. |
| [17] | ARAKI Y, ISHIZUKA S. Data Synchronization System and Data Synchronization Method[P]. USA, Patent 8, 775, 374, 2014-7-8 |
| [18] | ZHANG D, BACLAWSKI K P, TSOTRAS V J. B+Tree[J]. Encyclopedia of Database Systems, 2009, 288(22): 15537-15546. |
| [19] | MITCHELL C, MONTGOMERY K, NELSON L, et al. Balancing {CPU} and Network in the Cell Distributed B-Tree Store[C]//2016 Annual Technical Conference, 2016: 451-464 |
