



2. 陕西思科锐迪网络安全技术有限责任公司, 陕西 西安 710072;
3. 成都卫士通信息产业股份有限公司, 四川 成都 610000
互联网技术的出现使得工控行业面临一个更快速发展的契机,互联网的接入使得工业控制系统(industrial control systems, ICS)与其他业务系统的协作成为可能。然而,在享受工业互联网带来便利的同时,还要面临复杂的网络环境所带来的威胁。工业互联网往往是和工业生产直接相关的,工业互联网受到攻击的影响程度较之传统互联网更大,工业互联网的安全不仅关系到工业生产是否能够正常进行,更关系到人身财产安全,甚至是国家安全。
工业互联网与传统的网络在安全防护技术上是相通的。入侵检测作为重要的防护手段,是当前网络安全研究的热点。网络流数据是由不同字段组成的序列化数据,这些字段决定着网络流的传输源、传输目标、传输内容以及传输方式等。从捕获的数据包中提取数据包元数据,并在收集的数据中执行特定的查询和匹配来检测攻击[1]。但是,以往的研究只是单纯使用数据流进行入侵检测,缺乏对数据流特征自身的挖掘和分析,这使得在检测过程中存在较高的误报和漏报率。文献[2-7]利用机器学习方法建立异常检测系统(anomaly detection systems, ADS), 在一定程度上提高了检测的效率。如支持向量机(support vector machine, SVM)等监督学习方法和K-means等无监督学习方法,可以在计算成本较低的情况下有效区分出网络流的异常数据。然而,这些研究主要都是对网络流数据直接进行处理,缺乏对网络流数据特征的深度分析与挖掘,而且使用的网络数据维度也相对有限。
随着KDD99和NSL-KDD等网络流数据集的引入,研究者更加重视基于高维网络流数据特征的入侵检测研究[8]。Rodda等人使用多种分类方法比较分析NSL-KDD数据的特征分类及平衡问题,该研究结果表明,NSL-K*DD数据可以作为标准测试数据,验证工业互联网入侵检测系统的性能[9]。伴随着对数据特征研究的不断深入,一些研究者逐渐开始利用机器学习和神经网络等人工智能技术分析网络流特征,研究网络流数据中所存在的一般规律,以实现更加有效的入侵检测技术[10-17]。与此相应的,为提高基于高维网络流数据特征的智能检测效率,很多研究在硬件技术的实现方面也取得了突破[18-21]。尽管这些研究通过各种智能计算方法对网络流数据特征进行了分析,但是却缺乏对特征的深度挖掘(如特征抽取),无法达到跨维度更深层的网络流数据分析,造成入侵检测应用范围相对狭窄,无法对广域网络流实现入侵检测。
本文深入分析网络流中所具有的特征,在语义层面对网络流进行深度解析,提出一种网络流数据挖掘方法。设计基于深度学习的算法,融合不同维度的网络流数据,构建深度分析网络流数据特征机制,针对工业互联网安全实际,研究入侵检测技术。本文基于传统IT网络数据集和工控网络数据集分别进行分析和测试,说明了方法的有效性。
1 工业网络入侵检测与互联网的连接使工业控制系统面临严峻的通信安全威胁,因此,在工业控制系统网络环境中应当建立网络入侵检测系统进行安全防护[22]。工业控制系统网络是以具有通信能力的传感器和执行器等设备为节点,以现场总线和以太网等为通信介质来完成自动控制的网络,图 1是工业控制系统网络架构的示意图[23]。互联网和工业园区网之间应建立网络入侵检测系统,用来防御来自外部的网络攻击;在工业园区网和工业生产网之间也要设立网络入侵检测系统,保障工业生产设备不受异常通信的侵袭。

|
| 图 1 工业控制系统网络架构 |
无论是传统的互联网还是工业互联网,在它们的网络流中往往具有多个特征属性,如目的地址、数据包长度、协议类型等。这些属性共同标识着每一条网络流,即不存在2个属性完全相同的网络连接。因此,通过对网络流中的各个属性进行特征挖掘,可以区分出网络流量中的异常行为,从而达到入侵检测的目的,本文所设计的网络入侵检测模型如图 2所示。分别对传统互联网和工业互联网进行网络抓包,在对比分析之后发现,传统互联网和工业互联网的网络流属性具有较高的一致性,尽管每个属性的数据内容存在差异,但是属性的类型和含义大致相同。因此,可以从网络流属性的数据类型层面出发,研究一种普适于传统互联网和工业互联网的网络流量特征挖掘方法。

|
| 图 2 网络入侵检测系统模型 |
网络入侵检测就是对网络流数据进行行为识别和分类,然而,面对如此高维的网络流数据,如果进行全维度统一分析,势必会消耗大量的计算资源,而且难以保证入侵检测的实时性。此外,如果无法把握数据特征之间的联系,将可能影响到入侵检测系统的有效性和可扩展性。
2 网络流数据特征挖掘本文针对传统IT网络和工控网络提出一种统一的网络数据流特征挖掘方法,该方法的执行流程如图 3所示。首先,通过网络镜像的方式获取异构网络数据流;其次,对网络数据流进行处理,具体包括对网络数据流特征的分析、选择以及融合3个步骤;最后,基于统一的数据特征形式实行网络数据流的异常识别。具体的步骤将在本章的2.1和2.2节详细介绍。

|
| 图 3 网络数据流特征挖掘流程 |
对于一条网络中的连接数据,其各个属性之间的数据类型差别较大,如KDD99数据集中每条网络流都有41个基本属性,这些属性包括了网络连接的基本特征、流量特征以及内容特征。连接的基本特征包括了可从TCP/IP连接中提取的所有属性;流量特征为过去一段时间内与当前连接具有相同目标主机或相同服务的连接特征;内容特征是数据中可以用来辨别各种攻击类型的部分,例如尝试登陆的失败次数等。除了这些属性以外,在每条数据的最后都有相应的标签,标签表示这些网络流数据所属类别,即是否含有攻击行为。面对如此高维的网络数据,很难直接度量每个属性对网络攻击行为分析的影响。因此,对网络流的各个属性进行特征处理。图 4和图 5分别是从KDD99数据集与工控网络数据中所抽取的两部分数据,图中的每一行代表一条网络流数据,每一列代表一个属性,其中最后一列就是每条数据所对应的标签。本文根据网络流各个属性数据类型的不同对数据集进行划分,在图 4和图 5中用了3种不同灰度程度来表示3种数据类型,其中灰度较深的字段皆为符号型数据,灰度居中字段皆为整型数据,灰度较浅的字段皆为浮点型数据,这样的分组将作为特征选择的依据。对每一个分组利用卷积神经网络(convolution neural network, CNN)进行特征提取和分类。之所以选择CNN算法,是因为该算法在网络异常检测中性能优越,而且其在特征提取方面有着良好的性能[24]。此外,本文旨在利用分类算法来验证所提出的网络流特征挖掘方法,因此,以CNN作为一种基准算法进行评估。CNN模型的架构如图 6所示[25]。

|
| 图 4 KDD99部分数据 |

|
| 图 5 工控网络数据样例 |

|
| 图 6 CNN模型架构 |
相比RNN等其他深度学习方法, CNN可以在大量的数据中挖掘数据特征。CNN的核心是一系列的卷积运算和非线性映射, 每一个卷积层都利用卷积核进行卷积操作, 然后利用激活函数进行非线性映射, 如(1)式所示。
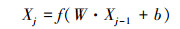
|
(1) |
式中,Xj-1和Xj分别为当前卷积层的输入和输出, W为卷积核, b为偏置项, f为激活函数, 常用的激活函数有Sigmoid、tanh以及ReLu等。为了提高CNN的计算效率, 常常会加入池化层处理[25]。
本文按照数据类型将网络流量的所有属性划分为3个子属性集合:描述型字段、统计型字段以及比例型字段, 具体的划分如表 1所示。
| 数据来源 | 描述型字段 | 统计型字段 | 比例型字段 |
| 传统IT 网络数据 |
Protocol type, Service, Flag, Land, Logged in, Root shell, Su attempted, Is hot login, Is guest login | Duration, Src bytes, Dst bytes, Wrong fragment, Urgent, Hot, Num failed logins, Num compromised, Num root, Num file creations, Num shells, Num access files, Num outbound cmds, Count, Sry count, Dst host count, Dst host sry count | Serror rate, Srv serror rate, Rerror rate, Srv rerror rate, Same srv rate, Diff srv rate, Srv diff host rate, Dst host same srv rate, Dst host diff srv rate, Dst host same src port rate, Dst host srv diff host rate, Dst host serror rate, Dst host srv serror rate, Dst host rerror rate, Dst host srv rerror rate |
| 工控网络 数据 |
Type, Protocol | Epoch time, Frame length, Capture length, IP source, DSF, IP total length, ID, Flags DF, Flags MF, Time to live, IP Payload, Source port, Destination port, Sequence nubmer, Acknowledgment number, TCP header length, CWR, ECE, URG, ACK, PSH, RST, SYN, FIN, Window size value, Urgent pointer, Option, TCP payload | 连接数比例 (可由IP destination, IP header length, MAC destination, MAC source计算而得) |
描述型字段皆为符号型数据, 这些数据较为离散, 并且数据之间没有直接联系, 因此难以直接对其进行刻画和度量。在数据挖掘领域有一种对文本数据进行量化处理的常用方法, 那就是One-Hot编码[26]。One-Hot编码又称一位有效编码, 主要是采用N位状态寄存器来对N个状态进行编码, 当需要表示某一个状态时, 只需要将代表该状态的位置1, 同时将其他位置0即可。比如对于工控数据集, 其协议类型有TCP, UDP以及Modbus, 则TCP对应的One-Hot编码为[1,0,0], 其他2种分别可以表示为[0,1,0]和[0,0,1]。同理, 可以对其他的Symbolic属性进行编码。本文利用One-Hot编码方式对描述型字段中的每个属性进行特征处理, 将所有的离散型数据进行量化, 以便于特征度量和分析。对处理后所得到的量化结果利用CNN进行特征提取。最终得到描述型字段的特征向量CS, 如(2)式所示。
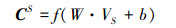
|
(2) |
式中,VS为描述型字段经One-Hot编码后的值。
统计型字段皆为整型数据, 每个属性的数据范围不同, 无法直接对其分析。本文分别采用2种方法对统计型字段进行归一化处理, 一种是用每个数据在某个属性上的值除以所有数据在该属性上的平均值; 另一种是用每个数据在某个属性上的值除以所有数据在该属性上的最大值。这2种方法都可以在尽可能保持原来数据分布的基础上对统计型字段进行处理, 使得每个属性的数据范围尽可能接近, 以便于横向对比和分析。设一共有n条数据, 对于第i条数据, 其统计型字段中的第j个子属性值为aij, 则2种归一化方式如(3)至(4)式所示。
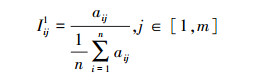
|
(3) |
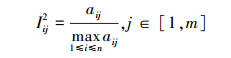
|
(4) |
式中,Iij1和Iij2分别表示2种归一化的结果, m为统计型字段中的属性总数。通过这种归一化处理, 使得各个特征的数据分布尽可能接近, 以便于进行统一度量和分析。利用CNN对归一化处理后的结果进行特征提取, 得到其特征向量CI, 如(5)式所示。
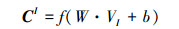
|
(5) |
式中,VI为统计型字段经归一化处理后的值。
比例型字段皆为浮点型数据。根据网络连接的IP地址和MAC地址等信息, 可以得到一段时间内与当前连接具有相同目标主机或相同服务的连接数, 从而可以得到多种比例型数据。在这些数据中, 有一部分数据是处于[0, 1]之间的, 这些数据由于数值相近, 所以予以保留。而另一部分则是大于1的数据, 这些数据分布广泛, 且难以把握其规律, 因此不能直接将这部分数据与[0, 1]之间的数据进行同步分析。本文针对比例型字段中属性值大于1的数据进行处理, 利用Sigmoid函数将其映射到(0, 1)之间, 然后再与原来属性值在[0, 1]之间的数据进行联合分析。Sigmoid函数的定义式如(6)式所示。
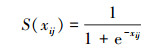
|
(6) |
式中,xij为比例型字段中第j条属性对应于第i条数据的值, S(xij)表示该属性值经过Sigmoid函数映射后的值。将处理后的结果输入到CNN模型中进行特征提取, 得到该集合的特征向量CF, 如(7)式所示。

|
(7) |
式中,VF为比例型字段经Sigmoid函数映射后的值。
2.2 数据特征融合对高维的网络流数据进行基于数据类型的特征选择, 在此基础上, 选择不同的特征子集进行组合和特征融合, 研究各类特征对网络行为识别与分类的影响。
利用(1)、(4)、(6)式分别得到描述型、统计型以及比例型字段这3个特征子集的特征向量CS, CI和CF。其中描述型字段主要包括网络协议类型、网络服务类型以及连接状态等属性, 考虑到这些属性对网络连接的具有非常重要的意义, 因此, 在对特征进行组合时, 每一组都包含了CS, 具体共设计有下面4种组合:CS, {CS, CI}, {CS, CF}以及{CS, CI, CF}。
对于只有CS的情况, 直接利用分类模型对其进行特征学习和分类即可, 而对于2个及以上的特征组合, 本文采用级联的方式将每个特征集中的数据进行连接, 然后再利用CNN分别提取每个组合的特征向量, 如(8)至(10)式所示。
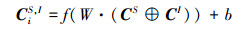
|
(8) |
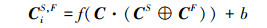
|
(9) |
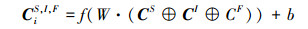
|
(10) |
式中,⊕为级联符号, 用来将2种或多种特征串联在一起, CiS, I表示将第i条数据的CS与CI级联后的特征集, CiS, F表示将第i条数据的CS与CF级联后的特征集, CiS, I, F表示将第i条数据的CS, CI以及CF全部级联后的特征集。整体网络流数据特征提取流程如图 7所示, 其中⊕为级联符号, 表示将2种或多种特征进行连接。

|
| 图 7 网络流数据特征提取流程 |
利用CNN特征提取的方式对不同的属性组合进行特征融合, 得到4个特征集的特征向量分别为CS, CS, I, CS, F以及CS, I, F。然后, 即可利用分类模型分别对这些特征集进行识别和分类的测试, 验证不同属性组合方式对网络入侵检测效果的影响。
3 实验设计、结果与分析 3.1 CNN模型设计和评价度量本文利用CNN来进行网络流量特征的提取和异常行为的分类。根据待分析的网络流量数据构建CNN模型, 然后利用CNN模型提取出网络流量数据的特征, CNN模型提取特征的流程如图 8所示。将完成分组并预处理后的网络流数据输入到CNN模型中, 模型的输入层先对数据进行初始化, 然后通过卷积、池化以及全连接等操作得到数据的特征向量。在提取出描述型、统计型以及比例型字段这3个子集的特征向量之后, 按照设计的组合方式, 对这些特征向量分别进行级联, 将级联后的特征再次输入到同样的CNN模型中, 进一步做特征融合与提取, 最终得到每种属性组合特征向量。

|
| 图 8 CNN模型特征提取流程 |
网络入侵检测的最后一步是对网络流进行分类, 即判别网络流中是否含有异常行为, 若有, 则具体加以区分。将CNN所提取的网络流特征输入到分类器中, 通常情况下用到的分类器是Softmax分类器, 如(11)式所示。
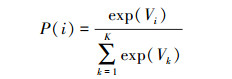
|
(11) |
式中,P(i)为该分类器所输出的概率值, 即分类器会给出网络流数据属于每种类别的概率, 对应最大概率的类别即为分类器所判别的结果。Vi为分类器前级神经网络的输出, Softmax分类器根据CNN的输出预测数据对应每个类别的概率。
针对CNN模型的优化, 本文通过多次实验和调参, 进行CNN的模型优化。最终设计出CNN模型中较优的主要参数如表 2所示。
| 参数名称 | 参数值 |
| 卷积核尺寸 | 2, 3, 4, 5, 7, 9 |
| 卷积核数量 | 200, 200, 300, 200, 200, 100 |
| dropout率 | 0.5 |
| batch size | 1 024 |
| 训练epoch | 100 |
| 学习率 | 4×10-4 |
本文基于Intel(R) Xeon(R) E5-2660 v2, NVIDIA GeForce GTX TITAN Xp等硬件条件, 通过TensorFlow深度学习框架设计和实现CNN模型。
本文通过分类的正确率(Accuracy Rate)来度量分类模型的优劣, 正确率公式可以用(12)式表示。
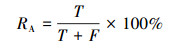
|
(12) |
式中,T表示所有分类结果中分类正确的数量, F表示所有分类结果中分类错误的数量。
在对正常网络流和异常网络流进行二分类时, 本文还另外引入了召回率RR, F1值、误报率RFR以及漏报率RMR这4个指标进行度量, 如(13)~(15)式所示。
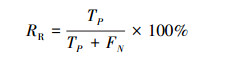
|
(13) |
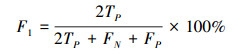
|
(14) |
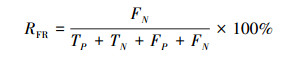
|
(15) |
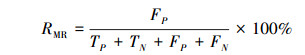
|
(16) |
式中,TP表示将正常类样本的分类正确的数量, TN表示将异常类样本分类正确的数量, FP表示将异常类样本误分为正常的数量, FN表示将正常类样本误分为异常的数量。召回率是二分类中常用的度量指标, 反映模型对异常数据的查全率; F1值是综合反映模型分类效果的指标; 误报率和漏报率是入侵检测系统的常用度量指标, 反映系统对网络攻击事件判别和响应的能力。
3.2 传统IT网络数据实验及结果分析本文首先对传统IT网络数据进行网络流量行为检测的实验。KDD99是一种被广泛应用于网络入侵检测研究的数据集, 该数据集是在DARPA 1998数据集的基础上通过数据挖掘而产生的, 它为网络入侵检测方面的研究奠定了基础[8]。Tavallaee等人对KDD99数据集做了全面的分析, 该数据集总共由500万条记录构成, 它还提供了一个10%的训练子集和测试子集[27]。利用提出的网络流数据特征挖掘方法对该传统IT网络数据进行实验。将4种组合所对应的特征向量, 即CS, CS, I, CS, F以及CS, I, F, 分别利用CNN分类模型进行分类测试。此外, 本文还对统计型字段的2种归一化方法进行了比较, 对比(3)至(4)式2种方法的分类结果, 研究2种方法对数据特征挖掘的影响。上述实验结果如表 3和4所示。
| 特征组合 | 正确率 | 召回率 | F1值 | 误报率 | 漏报率 | 方差 |
| CS | 91.04 | 70.90 | 80.11 | 5.32 | 3.64 | 0.02 |
| CS, F | 93.93 | 71.42 | 81.22 | 2.87 | 3.20 | 0.08 |
| CS, I | 95.63 | 71.90 | 82.21 | 2.98 | 1.39 | 0.11 |
| CS, I, F | 98.86 | 73.76 | 85.47 | 0.91 | 0.23 | 0.008 |
| 特征组合 | 正确率 | 召回率 | F1值 | 误报率 | 漏报率 | 方差 |
| CS | 84.59 | 67.03 | 74.95 | 11.06 | 4.35 | 0.18 |
| CS, F | 89.16 | 69.63 | 78.90 | 5.93 | 4.91 | 0.57 |
| CS, I | 91.23 | 70.42 | 80.32 | 5.09 | 3.68 | 0.79 |
| CS, I, F | 89.67 | 70.57 | 79.47 | 6.72 | 3.61 | 0.19 |
从实验结果可以看出, 不同的特征组合方式带来的分类效果也不同, 只有描述型字段时的分类正确率最低, 而将3个特征集合组合在一起时的分类正确率最高。但总的来说, 4种不同的特征组合方式都取得了不错的分类结果, 即使在正确率最差的描述型字段上也能够达到86%以上, 这是因为描述型字段在一定程度上已经对网络流的行为进行了标识, 正常的网络流数据与各种含有攻击行为的网络流数据在这些属性上有着一定的差别。将CS, I和CS, F这2个特征组合的实验结果进行对比可以看出, 在CS, I分类效果更好, 这是由于网络数据中的统计型字段包含了比例型字段更加鲜明的特征, 因此, 前者比后者更有利于区分网络流行为。当把3个集合组合在一起时, 分类效果最好, 正确率达到了98%以上。另外, 通过对比可以看出, 针对统计型字段不同的归一化方式取得的结果也明显不同, 采用平均值法明显要优于采用最大值法, 这与网络流数据在这些属性上的分布有关。
3.3 工控网络数据实验及结果分析由表 1可知, 传统IT网络数据和工控网络数据均可按数据类型分为描述型、统计型以及比例型3个字段, 因此, 以传统IT网络为源域进行数据挖掘方法迁移, 将其运用到目标域, 也就是工控网络中。
由于工控网络安全研究领域面临着缺乏数据的问题, Lemay等人利用SCADA沙箱搭建了SCADA系统仿真环境, 并进行数据的产生和采集, 从而得到可用于工控网络入侵检测的数据集[28]。这些数据集有着较高的理论价值, 对缺乏公开数据集的工控网络安全领域有着重要意义, 目前已逐渐被运用于工控网络入侵检测研究[29]。在Lemay等人所建立的若干工控数据集中, 大多数是样本分布极不均衡, 即正常样本数量远远大于异常样本数量, 在这种情况下模型极易出现过拟合现象。本文在若干数据集中选择了exploit ms08 netapi modbus 6RTU with operate数据集, 因为该数据集正负样本较为均衡, 共有1 856条网络流数据, 其中异常样本量有1 199条。但是考虑到真实网络环境中异常数据比例较低, 因此本文对该数据集进行处理, 将其分为2个数据集, 每个数据集含有全部的正常数据和一半异常数据, 即包含657条正常网络数据和600条异常网络数据。然后对2个数据集分别进行异常行为分类, 将2个结果的均值做为最终结果。实验结果如表 5和6所示。
| 特征组合 | 正确率 | 召回率 | F1值 | 误报率 | 漏报率 | 方差 |
| CS | 83.42 | 71.58 | 77.87 | 7.42 | 9.03 | 1.29 |
| CS, F | 85.07 | 73.51 | 79.81 | 4.10 | 4.88 | 1.01 |
| CS, I | 91.67 | 78.70 | 85.70 | 2.31 | 3.15 | 0.82 |
| CS, I, F | 95.11 | 80.33 | 88.26 | 1.37 | 1.95 | 0.69 |
| 特征组合 | 正确率 | 召回率 | F1值 | 误报率 | 漏报率 | 方差 |
| CS | 80.13 | 68.70 | 74.29 | 9.85 | 11.17 | 2.82 |
| CS, F | 82.51 | 72.22 | 77.61 | 7.10 | 8.94 | 1.77 |
| CS, I | 88.43 | 78.10 | 82.73 | 4.96 | 5.22 | 1.02 |
| CS, I, F | 89.02 | 78.58 | 83.42 | 2.43 | 3.60 | 0.90 |
从结果来看, 工控网络数据同样是采用的特征组合方式不同, 其所对应的分类效果也不同, 只有描述型字段时的分类正确率最低, 而将3个特征集合组合在一起时的分类正确率最高。从正确率来看, 模型在工控网络数据上的分类效果较之传统IT网络数据更低, 这是因为用于模型训练的IT网络数据量远远超过工控网络数据量。从召回率来看, 结果刚好相反, 工控网络数据上的分类召回率要优于传统IT网络, 这是因为经过对数据集的处理, 使得用于模型训练的2个工控网络数据集更加均衡, 从而使模型具有更好的泛化能力和查全能力。通过F1值综合来看, CS与CS, F这2种特征组合所对应的异常检测能力较低, 相较于传统IT网络数据中2种组合的分类结果较差。这是因为在传统IT网络数据中, 描述型字段有10个, 而在工控网络数据中, 这样的字段只有2个, 而且比例型字段也相差较大, 这就导致后者2种特征组合所包含的信息不足, 难以准确的对网络行为进行判别。而其他2种组合则要优于传统IT网络, 当把3个集合组合在一起时, F1值接近90%。
结合表 3和4中的结果可以看出, 2种网络流量异常检测均有着较低的误报率和漏报率。整体而言, 在传统IT网络数据上的分类准确率要优于工控网络数据, 这是因为用于模型训练的IT网络数据量远远超过工控网络数据量。但即使如此, 本方法在工控网络数据上的异常分类结果依然较为良好。从5次重复实验的方差可以看出上述这些实验结果的有效性, 这也更加证明这种特征挖掘的方法在网络入侵检测中具有良好的效果。
此外, CNN在进行工控网络异常分类任务中表现出了较低的时间复杂度, 通过对分类过程中的耗时统计, 训练好的CNN模型鉴别异常所用时间很短, 对于包含了600条异常数据的工控网络数据集只需要0.9 s左右的时间即可完成检测。
虽然目前已有很多有关网络入侵检测方面的工作, 特别是像文献[16, 24]中利用神经网络来进行网络流量的特征提取和分类, 都取得了非常不错的效果。但是, 本文的网络入侵检测方法在正确率上依然占有优势。最重要的是, 本文经过分析对比, 发现工业网络流与传统网络流的特征属性规则详细, 本文所提出的网络入侵检测方法可以迁移到工业网络环境中的流量异常检测, 并取得较为理想的效果。
4 结论本文从深度学习的角度研究网络流数据特征提取, 为实现深度的入侵检测提供技术实现方案。实验表明, 提出的特征处理算法可以充分挖掘和利用网络流数据的特征, 并能准确地判别网络流中的异常行为。提出的方法从传统IT网络拓展到了工业互联网安全入侵检测领域, 证明了这两者之间的可迁移性。
在未来的工作中, 我们将会着重于研究从传统IT网络到工控网络的迁移学习技术, 将已有的海量传统IT网络数据知识迁移到工控网络中, 解决工控网络数据量稀少的问题。对于工控网络数据中存在的样本不均衡问题, 我们将会从数据扩充的角度进行研究, 进一步提高工控网络入侵检测的能力。
| [1] | RATNER A S, KELLY P. Anomalies in Network Traffic[C]//2013 IEEE International Conference on Intelligence and Security Informatics, 2013: 206-208 |
| [2] | CAMACHO J, MACIA-FERNANDEZ G, DIAZ-VERDEJO J, et al. Tackling the Big Data 4 Vs for Anomaly Detection[C]//IEEE Conference on Computer Communications Workshops, Toronto, 2014: 500-505 |
| [3] | XU W, HUANG L, FOX A, PATTERSON D A, et al. Detecting Large-Scale System Problems by Mining Console Logs[C]//The 27th International Conference on Machine Learning, Haifa, 2010: 37-46 |
| [4] | YEN T F, OPREA A, ONARLIOGLU K, et al. Beehive: Large-Scale Log Analysis for Detecting Suspicious Activity in Enterprise Networks[C]//The 29th Annual Computer Security Applications Conference, New York, 2013: 199-208 |
| [5] | THERDPHAPIYANAK J, PIROMSOPA K. Applying Hadoop for Log Analysis toward Distributed IDS[C]//The 7th International Conference on Ubiquitous Information Management and Communication, New York, 2013: 1-3 |
| [6] | BAMAKAN S M H, WANG H, YINGJIE T, et al. An Effective Intrusion Detection Framework Based on MCLP/SVM Optimized by Time-Varying Chaos Particle Swarm Optimization[J]. Neurocomputing, 2016, 199: 90-102. DOI:10.1016/j.neucom.2016.03.031 |
| [7] | AMBUSAIDI M A, HE X, NANDA P, et al. Building an Intrusion Detection System Using a Filter-Based Feature Selection Algorithm[J]. IEEE Trans on Computers, 2016, 65(10): 2986-2998. DOI:10.1109/TC.2016.2519914 |
| [8] | LIPPMANN R P, FRIED D J, GRAF I, et al. Evaluating Intrusion Detection Systems: the 1998 Darpa Off-Line Intrusion Detection Evaluation[J]. Discex, 2000, 2(1): 1012-1026. |
| [9] | RODDA S, EROTHI U S R. Class Imbalance Problem in the Network Intrusion Detection Systems[C]//2016 International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, 2016: 2685-2688 |
| [10] | GUPTA G P, KULARIYA M. A Framework for Fast and Efficient Cyber Security Network Intrusion Detection Using Apache Spark[J]. Procedia Computer Science, 2016, 93(1): 824-831. |
| [11] | DESHMUKH D H, GHORPADE T, PADIYA P. Intrusion Detection System by Improved Preprocessing Methods and Naive Bayes Classifier Using Nsl-Kdd 99 Dataset[C]//2014 International Conference on Electronics and Communication Systems, Coimbatore, 2014: 1-7 |
| [12] | PAJOUH H H, DASTGHAIBYFARD G, HASHEMI S. Two-Tier Network Anomaly Detection Model: a Machine Learning Approach[J]. Journal of Intelligent Information Systems, 2015, 48(1): 1-14. |
| [13] | DESHMUKH D H, GHORPADE T, PADIYA P. Improving Classification Using Preprocessing and Machine Learning Algorithms on Nsl-Kdd Dataset[C]//2015 International Conference on Communication, Information Computing Technology, Mumbai, 2015: 1-6 |
| [14] | PERVEZ M S, FARID D M. Feature Selection and Intrusion Classification in Nsl-Kdd Cup 99 Dataset Employing SVMS[C]//in the 8th International Conference on Software, Knowledge, Information Management and Applications, Dhaka, 2014: 1-6 |
| [15] |
高妮, 高岭, 贺毅岳, 等. 基于自编码网络特征降维的轻量级入侵检测模型[J]. 电子学报, 2017, 45(3): 730-739.
GAO Ni, GAO Ling, HE Yiyue, et al. A Lightweight Intrusion Detection Model Based on Autoencoder Network with Feature Reduction[J]. Acta Electronica Sinica, 2017, 45(3): 730-739. (in Chinese) DOI:10.3969/j.issn.0372-2112.2017.03.033 |
| [16] | DELA HOZ E, ORTIZ A, ORTEGA J, et al. Network Anomaly Classification by Support Vector Classifiers Ensemble and Non-Linear Projection Techniques[J]. Hybrid Artificial Intelligent Systems, 2013, 8073(1): 103-111. |
| [17] | SHAHBAZ M B, WANG X, BEHNAD A, et al. On Efficiency Enhancement of the Correlation-Based Feature Selection for Intrusion Detection Systems[C]//2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference, Vancouver, 2016: 1-7 |
| [18] | AGHDAM M H, KABIRI P. Feature Selection for Intrusion Detection System Using Ant Colony Optimization[J]. Internaltiral Jeurnal of Network Security, 2016, 18(3): 420-432. |
| [19] | INGRE B, YADAV A. Performance Analysis of Nsl-Kdd Dataset Using Ann[C]//2015 International Conference on Signal Processing and Communication Engineering Systems, Guntur, 2015: 92-96 |
| [20] | POTLURI S, DIEDRICH C. Accelerated Deep Neural Networks for Enhanced Intrusion Detection System[C]//2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation, Berlin, 2016: 1-8 |
| [21] | SUBBA B, BISWAS S, KARMAKAR S. A neural Network Based System for Intrusion Detection and Attack Classification[C]//2016 Twenty Second National Conference on Communication, Guwahati, 2016: 1-6 |
| [22] |
赖英旭, 刘增辉, 蔡晓田, 等. 工业控制系统入侵检测研究综述[J]. 通信学报, 2017, 38(2): 143-156.
LAI YingXu, LIU Zenghui, CAI Xiaotian, et al. Research on Intrusion Detection of Industrial Control System[J]. Journal on Communications, 2017, 38(2): 143-156. (in Chinese) |
| [23] |
金忠峰, 李楠, 刘超, 等. 工业控制系统入侵检测技术研究综述[J]. 保密科学技术, 2018(3): 18-25.
JIN Zhongfeng, LI Nan, LIU Chao, et al. Review of Research on Intrusion Detection Technology of Industrial Control System[J]. Secrecy Science and Technology, 2018(3): 18-25. (in Chinese) |
| [24] | BLANCO R, CILLA J J, MALAGON P, et al. Tuning Cnn Input Layout for Ids with Genetic Algorithms[C]//Hybrid Articial Intelligent Systems, Cham, 2018: 197-209 |
| [25] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-Based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. DOI:10.1109/5.726791 |
| [26] | DECLERAQ D, AMARICAI A, SAVIN V, et al. Check Node Unit for Ldpc Decoders Based on One-Hot Data Representation of Messages[J]. Electronics Letters, 2015, 51(12): 907-908. DOI:10.1049/el.2015.0108 |
| [27] | TAVALLAEE M, BAGHERI E, LU W, et al. A Detailed Analysis of the Kdd Cup 99 Data Set[C]//2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, 2009: 1-6 |
| [28] | LEMAY A, FERNANDEZ J M. Providing SCADA Network Data Sets for Intrusion Detection Research[C]//in The 9th Workshop on Cyber Security Experimentation and Test, Austin, TX, 2016 https://www.ixueshu.com/document/6abef91ac3da8fc4318947a18e7f9386.html |
| [29] | MARSDEN T. Probability Risk Identification Based Intrusion Detection System for SCADA Systems[C]//International Conference on Mobile Networks & Management, Cham, 2017 https://link.springer.com/chapter/10.1007/978-3-319-90775-8_28 |
2. Shaanxi SecureCon Technologies, Co. Ltd, Xi'an 710072, China;
3. Chengdu Westone Information Industry INC, Chengdu 610000, China
