

2. 中国科学院大学, 北京 100049
近些年来,随着计算机技术的快速发展,视觉目标跟踪逐渐成为基于连续图像的目标识别和检测的高级应用之一。它被广泛应用在无人驾驶、视频监控、机器人视觉等领域[1-3]。而在目标跟踪场景中经常涉及到部分遮挡、背景干扰、旋转、光线变化、形变等情况。
针对以上问题,一些目标跟踪算法被相继提出,根据跟踪过程中有无检测参与,这些算法可分为生成式和判别式。前者基于模板匹配的思想,首先对目标进行建模,在之后的视频帧中使用目标模型搜索相似度最高的区域来确定目标的位置。在这一类算法中,针对目标被短时遮挡导致失跟的问题,Perez等[4]提出了基于颜色特征的概率跟踪算法;该算法使用HSV(hue-saturation-value)颜色直方图建立目标模型,通过粒子滤波器(particle filter,PF)从后验概率中抽取随机状态粒子来表达目标位置的概率分布情况,减小了搜索范围,同时增强了网络对环境光线变化的处理能力。Wang等[5]使用Camshift算法对粒子滤波器进行优化,提高了算法在位置和尺度空间上的采样效率。李冠彬等[6]结合颜色直方图和局部二元模式(local binary pattern,LBP)的纹理特征表征目标物体,采用均值漂移(meanshift,MS)算法逐步迭代目标各分块得到最佳跟踪位置,该方法在目标被部分遮挡场景中有一定的鲁棒性。虽然上述生成式方法能准确地刻画目标外观,但是当画面分辨率低、目标剧烈形变、背景存在相似干扰项时,常常发生目标漂移导致跟踪失败。判别式方法结合目标检测,将目标跟踪视为二分类问题,通过训练集中的正负样本训练网络对视频中的目标和背景进行区分,相比生成式方法能充分利用背景和目标信息,更不易受到干扰。
在传统的判别式方法中,Hare等[7]使用了Haar特征和拥有结构化输出的支持向量机(support vector machine,SVM),提高了对目标和背景的分类准确度,但由于使用单一特征,导致对背景中存在严重干扰,目标尺度剧烈变化的情况缺乏鲁棒性。Henriques等[8]提出基于核函数的相关滤波器方法;通过目标物体周围的循环矩阵采集训练的正负样本,使用多通道的方向梯度直方图特征(histogram of oriented gradient, HOG)进行表征,并结合岭回归算法训练目标检测网络,同时运用了傅里叶变换有效降低计算复杂度,实现了实时的跟踪表现。但其过于依赖循环矩阵,导致对多尺度的目标跟踪表现并不理想。Babenko等[9]提出基于多实例学习(multiple instance learning,MIL)的跟踪算法,根据样本的Haar特征采样生成正负实例集,在线训练多个弱分类器,经过加权组合生成强分类器对目标和背景进行区分;该方法对部分遮挡和目标尺度变化表现出较好的鲁棒性。
近几年来,深度学习方法在计算机视觉领域特别是图像分类任务中展现出了优良的性能[10],一些学者相继提出了基于深度特征和深度神经网络的目标跟踪算法。Danelljan等[11]使用物体的第一层卷积深度特征代替HOG,并利用了主成分分析法(principal component analysis, PCA)对目标的高维特征进行降维,实验证明深度特征能准确地对目标进行表征,实现了跟踪效果的极大提升。在此之后,Nam等[12]提出了基于卷积神经网络(convolutional neural network, CNN)端到端的目标跟踪网络,该网络通过在标注的视频序列上进行多域训练,获得对物体深度卷积特征提取的能力;在测试阶段利用初始帧和之后跟踪过程中采集到的目标深度特征进行微调,提高了网络的鲁棒性和适应性;但是由于CNN对类内语义目标不敏感,仅利用视觉特征表征目标,因此导致存在类内干扰物和严重遮挡时网络性能下降。另一方面,上述传统方法对于当前时刻目标位置的估计,均是基于上一时刻目标位置随机生成候选目标框,并没有利用目标的动态信息和历史轨迹,这导致在目标发生剧烈位移时,出现目标丢失的情况。
针对以上问题,本文提出一种基于目标动态特征和深度卷积特征的单目标跟踪网络。首先使用长短期记忆网络提取目标在时间序列上的动态特征,获得当前时刻预处理目标框,该阶段未使用图像信息,避免了图像中干扰因素对目标运动状态估计的影响;随后基于生成的预处理目标框生成多个候选框,对候选框中的图像信息使用卷积神经网络提取目标的深度卷积特征,得到当前目标位置;跟踪过程中,使用短期和长期更新2种方式对卷积网络进行参数更新以提高网络对目标变化的适应性和环境中多种干扰情况的鲁棒性;最后,将本文提出的方法与一些代表性的跟踪方法进行了对比实验。
1 长短期记忆网络在传统的神经网络结构中,同一时间节点中不同层之间的神经元相互连接,而前后时间节点之间的神经元相互独立,因此难以处理基于时间序列数据。循环神经网络(recurrent neural network,RNN)凭借其独特的跨时间序列神经元连接的结构特性,有效地解决了上述问题,被应用于跨语种翻译、语音识别中[13-14]。
跟踪任务中,视频数据具有时间序列特点,前后视频帧之间目标的变化存在着紧密联系,因此利用循环神经网络解决视频目标跟踪问题逐渐成为趋势。Cui等[15]学者有效地利用了多方向的循环神经网络(multi-directional recurrent neural networks)对目标随时间变化进行建模,有效解决了跟踪过程中误差积累和前向传播导致的漂移问题,并在实验中取得了令人满意的跟踪效果,展现出循环神经网络在跟踪任务中的潜力。本文基于上述思想,运用了长短期记忆网络提取跟踪目标的动态特征。
长短期记忆网络是循环神经网络的变体之一,门结构的引入解决了循环神经网络中长期依赖的问题[16]。其结构由输入层、隐藏层和输出层3个部分构成,图 1展示了一个长短期记忆网络的隐藏层结构。

|
| 图 1 长短期记忆网络隐藏层结构图 |
对于该网络的前向过程可以使用以下公式进行表示:
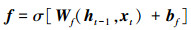
|
(1) |
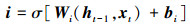
|
(2) |
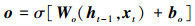
|
(3) |
式中, 使用前一个时间t-1时刻输出的隐藏状态ht-1和当前t时刻输入xt经过sigmoid激活函数σ[·]分别得到输入门i、输出门o、和遗忘门f的状态值, 各式中W和b分别为相应的权重系数矩阵和偏置项; 基于上一时刻的细胞状态Ct-1,当前细胞状态Ct通过以下公式结合输入门、遗忘门求出
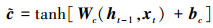
|
(4) |
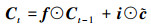
|
(5) |
式中, ⊙表示矩阵元素之间乘积操作。使用(6)式可以得到当前时刻的隐藏层的输出ht

|
(6) |
隐藏层的输出和细胞状态将会传递到下一个时刻的网络中, 重复以上的过程直到最后一个时刻。当前时刻网络的输出由隐藏层的状态ht结合与任务相关的激活函数获得; 在本文中, t时刻时长短期网络的输出为每个预处理候选框的概率值, 对概率值最大的前5个候选框进行处理得到预处理目标框,选取图像的待卷积区域。
2 本文跟踪方法设计本文构建的基于动态信息和卷积特征目标跟踪网络使用基于上一帧图像的位置信息为输入, 通过长短期网络提取视频序列上的目标动态特征, 产生预处理目标框; 使用卷积神经网络提取预处理框内图像的深度卷积特征, 最终得到当前目标的位置信息; 为了提高模型对目标变化的适应性和复杂场景中干扰因素的鲁棒性, 在跟踪过程中采集成功跟踪时目标的卷积特征对网络参数进行微调。图 2展示了算法在线跟踪阶段的网络架构。接下来介绍本方法跟踪过程、模型离线训练以及在线更新。

|
| 图 2 本文算法结构 |
由于跟踪任务中, 连续的视频片段属于时间序列数据, 因此本节中使用长短期记忆网络能够访问目标历史动态, 对基于时间序列的特征进行提取, 准确地获得当前时刻预处理目标框, 可以有效地解决跟踪过程中目标快速运动、运动模糊以及运动过程中被遮挡的问题。
本文中使用了单隐层的LSTM网络, 隐藏层中单元个数为256;其后跟随全连接层对隐藏层状态进行线性映射。前一帧目标框lt-1的位置信息为[st-1, rt-1, wt-1, kt-1], 分别表示目标框的左上角坐标、宽度和高度; 以该目标框为中心使用高斯分布产生N个候选框并构建N×4维的候选框矩阵Lt-1={lt-11, lt-12, …, lt-1N}, 作为当前时刻长短期记忆网络的输入, 网络的输出为隐藏层状态ht和细胞状态Ct, 由下式定义
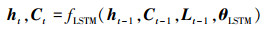
|
(7) |
式中, ht-1和Ct-1分别为上一时刻隐藏层状态和细胞状态; 函数fLSTM (·)为第一节中(1)~(4)式展示的计算过程, θLSTM表示长短期记忆网络中各参数项包括权重系数矩阵W和偏置项b。经过(7)式提取目标物体的时序特征, 本次跟踪任务中则为物体的运动特征。
为了产生准确的预处理目标框, 基于提取到的运动特征状态和上一帧目标框, N个候选框的概率分布p(lt-11, lt-12, …, lt-1N|l < t)通过下述公式产生
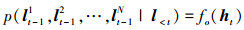
|
(8) |
式中, fo(·)为输出函数, 由以下公式定义
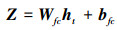
|
(9) |
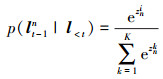
|
(10) |
(9) 式中, 将当前隐藏层状态ht经过全连接层线性映射得到特征响应值Z={z1, z2, …, zN}, Wfc和bfc分别为全连接层的权重系数矩阵和偏置项; (10)式使用softmax函数计算每个候选框的概率分布情况。根据产生的概率值对N个候选框降序排列, 求取前5项候选框平均值得到框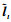
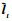
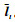
本小节使用卷积神经网络提取预处理框区域内图像的深度卷积特征, 在复杂场景中, 相比于传统的人工特征, 卷积特征实现了更加准确和紧凑的目标定位。
本文所使用的卷积神经网络主要包括卷积层和全连接层2个部分, 各层参数设置如图 2所示; 其中卷积层由Conv1、Conv2和Conv3构成, 紧接着是2个全连接层FC4和FC5, 输出目标和背景的分数, 以此确定目标框的坐标。给定t时刻的视频图像It像素尺寸为WI×HI, 使用上一阶段预处理目标框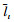

|
| 图 3 t时刻预处理框的获取 |
为了能够准确地覆盖目标可能出现的区域, 以生成的图像块为中心利用高斯分布产生N(N=256)个候选区域, 卷积网络的任务是找到N个候选区域中第i个区域, 满足其对应的图像区域得到正分数最大值, 即为t时刻目标所在的位置, 该过程由以下公式定义
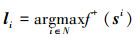
|
(11) |
式中, si表示第i个候选框所对应的图像块, f +(·)函数计算图像块的正分数即目标分数。
具体步骤如下:在N个候选区域中, 每个区域图像经过网络映射处理得到Wi×Hi×P维的特征张量作为卷积神经网络的输入; 其中张量尺寸Wi和Hi由卷积网络结构决定, P表示该张量的特征通道数, 由于实际跟踪任务中输入视频通常为RGB图像, 因此P值为3, 同时确定了图 2中第一层卷积Conv1的卷积核数量; 每一层的卷积输入为上一卷积层的输出, 具体定义如下
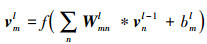
|
(12) |
式中, vml和vnl-1分别表示l层第m个通道输出的特征矩阵和l-1层第n个通道的输出特征矩阵, Wmnl和bml分别表示相应的第m个输出通道的卷积权重矩阵和偏置项, “*”代表卷积操作。将输出的卷积特征经过线性整流函数(rectified linear unit, ReLU)和批规范化(batch normalization, BN)层以避免反向传播过程中梯度爆炸和消失问题, 加快网络的训练; 由此得到的特征矩阵通常维度较高, 不便于直接进行处理, 因此使用最大特征值池化(max-pooling)方法对特征矩阵各区域进行聚合统计, 降低矩阵维度和运算复杂度。
在经过卷积层之后, 特征矩阵输入全连接层进行映射变换为目标和背景的置信度分数。在最后一层全连接层(FC5)获得N个候选框内背景和目标分数f(s)=[X1, X2, …, Xi, …, XN], 其中Xi为第i个候选框所对应的背景和目标分数; 由此取得分数最高者所对应的目标框li为t时刻的目标位置lt。
2.3 模型离线训练本小节介绍模型的离线训练过程。由于所提出的方法由2种深度网络组成, 离线训练过程将分成2个阶段进行:
1) 长短期记忆网络的训练
在规模为M的小批量训练数据集中, 时间序列长度为T帧的损失函数定义为
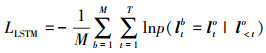
|
(13) |
式中, p(ltb=lto|lo< t)表示在第t帧时模型所预测的目标框为真实值的概率值; 通过使用随机梯度下降(stochastic gradient descent, SGD)最小化该损失函数, 得到长短期记忆网络的参数值。
2) 卷积神经网络的训练
首先使用大型分类数据集ImageNet[17]对卷积神经网络进行预训练, 通过迁移学习初始化本文的卷积网络参数; 然后使用基于时间序列的视频数据集, 利用多域学习方法[8]调整网络参数。每个训练批次包含m个样本, 每个样本由样本图像xi (i=1, 2, 3, …, m)和对应的类标签yji(j∈{+, -})构成, 其中j取“+”时yi=1表示正样本标签, 反之yi为0表示负样本标签, 损失函数定义如下
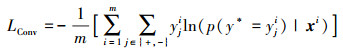
|
(14) |
式中, y*为前向推断过程模型预测的标签值; 同样使用SGD算法最小化该损失函数, 得到卷积层权重系数矩阵和偏置项的最优值。离线训练过程中, 长短期网络学习率αLSTM为10-2, 模型内权重系数矩阵W使用正态分布随机采样初始化, 对偏置项b采用零值初始化, CNN的学习率αconv设置为10-4。
2.4 模型更新在线跟踪阶段, 为了保持跟踪网络的适应性和鲁棒性, 实现对视频中背景和目标的准确分类, 通过2种方式对卷积神经网络全连接层参数进行在线更新。
1) 短期更新
在跟踪过程中, 目标物体时常出现尺度及运动姿态的快速变化, 为了提高网络对短时间内目标变化的适应性, 采用短期更新对网络参数进行微调。每当模型检测到潜在的跟踪失败, 即当前时刻目标分数f +(st) < 0.5时, 执行短期更新; 以最近20帧中实现成功跟踪(f +(st)>0.5)时, 网络产生的目标框为中心, 利用高斯分布生成S个样本, 其中与网络目标框重叠率≥0.7为正样本, 重叠率≤0.3为负样本, 采用反向传播算法对CNN全连接层参数进行更新。
2) 长期更新
与短期更新不同, 该阶段每隔10帧对网络参数进行调整; 通过选取最近100帧中成功跟踪时的目标框, 按照短期更新中正样本产生方法生成正样本; 由于跟踪早期的负样本对当前阶段过于冗余, 且相关性较低, 则选择短期更新过程中的负样本作为本阶段的负样本数据。采用长期更新目的在于保持网络对物体运动过程中光线剧烈变化、目标旋转等干扰因素的鲁棒性。
在更新过程中, 网络学习率设置为10-4, 为加快更新时收敛速度, 动量值设置为0.9, 权重衰减率为5×10-4。第三节展示了本文方法在对比实验中的跟踪效果以及对实验结果的分析。
3 实验结果与分析实验基于以下平台实现:CPU为Intel(R) Core(TM)i5-4590 @ 3.30G Hz, 16GB RAM, GPU为Nvidia GTX1080Ti, 程序基于MATLAB平台实现, 使用了MatConvNet深度学习工具库[18]。
3.1 实验数据集本文训练数据来源于TrackingNet跟踪数据集[19], 该数据集包含了12个视频子集, 从每个子集中选取50段视频序列, 按照4:1的比例划分为训练集和测试集。
从目标跟踪数据集OTB100[20]选取了15段具有代表性的视频序列(Basketball, Bolt, ClifBar, FaceOcc1, Human3, Human9, Ironman, Jump, Matrix, MotorRolling, MoutainBike, Skating2-2, Skiing, Tiger1, Woman)构建对比实验数据集; 该数据集包含了多个类别的跟踪目标, 并且涵盖了跟踪任务中目标的多种运动模式和不同的跟踪场景, 例如:光线变化、遮挡、运动模糊、快速运动等, 图 4展示了数据集中部分视频片段。

|
| 图 4 视频数据集示例 |
将本文提出的跟踪算法与当前目标跟踪领域内的一些代表性方法进行比较(CPF[4], KCF[8], SRDCF[21], DeepSRDCF[11]以及CFNet[22])。其中CPF属于基于粒子滤波的目标跟踪算法, 采样粒子数目为100;KCF, SRDCF DeepSRDCF 3种方法均为基于相关滤波器的跟踪算法; CPF, KCF和SRDCF使用了传统的目标特征, 而DeepSRDCF, CFNet和本文方法利用了目标的卷积特征; 其中CFNet网络使用非对称孪生网络(siamese network)整合相关滤波器和卷积特征。
本文展示并分析了以上6种算法在测试集中2段视频上的跟踪表现; 选取的视频涵盖了目前目标领域中多个难点, 例如:目标物体的快速运动、由快速运动导致的图像模糊、目标的旋转、运动过程中对目标的部分遮挡。对跟踪算法的表现评价指标主要分为2种:精准率和成功跟踪率, 前者通过预测的目标框和真实目标框的中心误差进行评估, 误差越小精准度越高; 后者是基于预测目标框和真实目标框重叠率, 通过下式定义
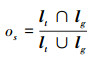
|
(15) |
式中, lt和lg分别表示算法得到的目标框和真实的目标框, os为目标框重叠率, 该比例大于0.5时视为算法实现了成功跟踪, 实现成功跟踪的帧数越多表明算法的成功跟踪率越高。
1) 跟踪结果展示和分析
MotorRolling视频涉及到目标物体的多种运动模式, 例如:目标的快速运动、旋转、尺度变化、环境光线变化以及快速运动造成的画面模糊, 对于跟踪算法要求较高。图 5给出了6种方法在该段视频上部分帧的跟踪结果; 从跟踪结果上观察可以发现:在第10帧中, 3种基于相关滤波器的算法(DeepSRDCF, SRDCF, KCF)和基于粒子滤波器算法(CPF)开始出现目标框漂移的现象, 这是由于使用传统特征算法对目标快速旋转缺乏鲁棒性导致; 在随后一段时间中, 目标一致处于快速旋转状态并伴随着位置的不断变化。在第38帧时, 上述4种算法均出现了严重的失跟现象, 这是由于丢失目标后, 算法没有及时对目标重识别, 导致目标逐渐远离算法的搜索窗口, 最终失去了目标; 由于CFNet使用了高层的卷积特征暂时没有出现目标丢失, 但也开始发生漂移情况。第120帧时, 目标经过几段旋转之后, CFNet算法出现严重目标漂移, 将后方同样为三角形的建筑识别为目标, 直至视频最后丢失目标; CPF算法由于背景中强烈的灯光干扰出现失跟现象; 而本文提出的方法在该段视频上一直保持对目标的稳定跟踪, 通过利用目标的深度卷积特征和目标动态特征, 克服了视频片段中目标旋转时的形态变化和背景光线变化导致的跟踪难点。

|
| 图 5 MotorRolling视频跟踪结果 |
选取的另一段视频Ironman是跟踪任务中最具有挑战性的视频片段之一, 其中包含了光线剧烈变化、由目标快速运动造成的模糊、旋转等复杂的跟踪属性; 图 6展示了参与对比实验的算法在该段视频上部分关键片段的跟踪结果, 从中可以看出:被跟踪物体为图中人物头部, 目标尺寸较小并且处于不断地运动和旋转之中, 同时周围光线持续变化并伴随类内物体的干扰; 在第17帧中, 基于相关滤波器的SRDCF算法由于目标左侧强烈的光线变化, 开始出现目标漂移情况, CPF算法由于目标姿态剧烈变化也出现了相同的情况; 在第50帧时, 目标物体经历了多次旋转, SRDCF和KCF已经完全丢失了目标并陷入局部区域, 直到视频结束; 仅利用第一层卷积特征的DeepSRDCF算法和基于粒子滤波器的CPF算法, 分别错认目标的手臂和左侧人物为目标, 说明上述方法对快速旋转和光线剧烈变化缺乏鲁棒性; 第104帧时, 由于人物低头动作目标被部分遮挡, CFNet算法出现漂移情况; 而本文方法在上述片段中始终保持对目标物体的跟踪状态, 体现出本文方法对上述视频中出现的各类干扰因素的鲁棒性。

|
| 图 6 Ironman视频跟踪结果 |
2) 综合性能分析
为了分析以上方法在上述每段视频上的整体表现, 逐帧绘制了6种算法的跟踪性能曲线, 图 7对其进行了展示。从图中可以看出, 相比于其他5种方法, 本文方法的性能曲线振幅最小, 并且在中心误差曲线上始终保持最低误差, 在大部分视频帧上获得了最高目标框重叠率; 在图 7a)中, CFNet在保持了一段时间低误差表现后, 目标物体出现旋转下落, 导致CFNet定位误差上升, 最终失去目标, 图 7b)目标框重叠率曲线在相应的部分也展现了相同的情况; 在Ironman视频的中心误差曲线(见图 7c))中, 虽然DeepSRDCF方法在110帧附近一度取得较小的误差值, 但这一优势并未得到保持, 之后随着误差值持续增加, 最终和另外2种基于相关滤波器的方法SRDCF、KCF同样丢失了目标; 基于粒子滤波器的CPF算法表现略优于上述3种方法, 但未能适应目标的复杂运动状态, 对背景中相似物体干扰和光线剧烈变化缺乏鲁棒性。而CFNet和本文方法保持了较低的误差值, 在部分帧上, 本文方法的表现优于CFNet; 同样的情况在重叠率曲线(见图 7d))上得到了印证。

|
| 图 7 跟踪性能曲线 |
表 1和表 2对性能曲线中每种方法的综合表现进行统计, 其中成功跟踪率表示算法实现成功跟踪的帧数占视频总帧数的比例。从表中可以看出, 本文方法相比于其他方法得到了最优的平均中心误差和平均目标框重叠率, 实现了最高的成功跟踪率; 在第一段视频的综合性能统计上, 相比于表现第二的CFNet方法, 本文方法的平均误差降低了87%, 平均重叠率提高了65%, 成功跟踪率提高了84%;在第二段视频上也取得了最优的跟踪性能, 验证了本文方法的有效性。
| 方法 | 平均中心误差/像素 | 平均重叠率 | 成功跟踪率 |
| 本文方法 | 7.034 0 | 0.669 4 | 0.850 2 |
| CFNet | 55.556 1 | 0.404 2 | 0.463 4 |
| DeepSRDCF | 200.846 2 | 0.095 6 | 0.073 2 |
| SRDCF | 247.054 3 | 0.093 1 | 0.073 2 |
| KCF | 230.029 3 | 0.094 0 | 0.079 3 |
| CPF | 149.659 3 | 0.121 7 | 0.085 3 |
| 方法 | 平均中心误差/像素 | 平均重叠率 | 成功跟踪率 |
| 本文方法 | 9.826 9 | 0.603 2 | 0.789 1 |
| CFNet | 14.313 9 | 0.569 1 | 0.680 7 |
| DeepSRDCF | 111.156 8 | 0.201 3 | 0.259 2 |
| SRDCF | 270.947 6 | 0.031 4 | 0.030 1 |
| KCF | 194.939 1 | 0.141 0 | 0.150 6 |
| CPF | 149.805 4 | 0.496 7 | 0.042 1 |
表 3和表 4分别为6种方法在测试集中全部视频序列上的平均中心误差和平均重叠率, 从两表中看出, 本文算法在测试集上实现了相对较优的跟踪精度和目标框重叠率; 在表 4中最后一行展示了各算法在测试集上的平均跟踪帧率, 可以看出本文算法跟踪速度有待提升, 计算耗时主要集中在目标特征提取和模型在线更新, 下一步工作将对上述两阶段的计算复杂度进行优化, 提高算法的跟踪实时性。
| 视频序列 | 本文方法 | CFNet | DeepSRDCF | SRDCF | KCF | CPF |
| Basketball | 4.529 4 | 14.859 8 | 19.816 7 | 10.808 7 | 7.888 7 | 55.584 1 |
| Bolt | 3.970 0 | 386.734 6 | 6.324 1 | 402.509 7 | 6.364 0 | 14.308 1 |
| ClifBar | 3.573 7 | 31.765 0 | 10.406 6 | 10.715 8 | 36.720 6 | 36.358 2 |
| FaceOcc1 | 10.978 9 | 17.795 4 | 12.900 2 | 14.767 3 | 15.981 5 | 28.809 5 |
| Human3 | 3.039 2 | 264.644 1 | 3.457 0 | 240.565 2 | 260.187 0 | 159.268 3 |
| Human9 | 2.405 0 | 4.651 3 | 40.478 8 | 10.515 8 | 14.767 5 | 22.793 1 |
| Jump | 37.571 6 | 87.745 9 | 168.216 8 | 195.579 5 | 84.114 4 | 55.503 7 |
| Matrix | 18.839 8 | 116.202 6 | 138.511 9 | 59.837 4 | 76.422 6 | 108.966 9 |
| MoutainBike | 6.539 9 | 6.358 5 | 9.749 6 | 8.988 6 | 7.658 8 | 211.023 1 |
| Skating2-2 | 19.703 9 | 58.194 7 | 51.946 0 | 29.006 1 | 42.345 8 | 34.944 9 |
| Skiing | 4.090 6 | 270.236 0 | 262.078 2 | 263.429 4 | 260.046 4 | 256.513 6 |
| Tiger1 | 8.109 0 | 24.323 4 | 8.380 7 | 10.613 8 | 15.796 1 | 37.256 6 |
| Woman | 2.820 3 | 134.518 6 | 3.676 9 | 4.811 9 | 10.061 6 | 124.583 6 |
| 视频序列 | 本文方法 | CFNet | DeepSRDCF | SRDCF | KCF | CPF |
| Basketball | 0.776 6 | 0.542 1 | 0.390 8 | 0.530 2 | 0.676 5 | 0.496 3 |
| Bolt | 0.774 3 | 0.015 8 | 0.575 6 | 0.011 0 | 0.678 6 | 0.476 3 |
| ClifBar | 0.695 9 | 0.369 8 | 0.581 1 | 0.549 6 | 0.259 8 | 0.198 7 |
| FaceOcc1 | 0.791 8 | 0.720 3 | 0.789 0 | 0.766 8 | 0.753 9 | 0.528 5 |
| Human3 | 0.545 8 | 0.014 3 | 0.451 6 | 0.025 5 | 0.005 2 | 0.036 2 |
| Human9 | 0.774 7 | 0.732 6 | 0.203 6 | 0.478 1 | 0.393 1 | 0.279 8 |
| Jump | 0.282 8 | 0.082 2 | 0.038 6 | 0.026 6 | 0.097 9 | 0.158 8 |
| Matrix | 0.521 8 | 0.246 9 | 0.252 0 | 0.267 9 | 0.119 0 | 0.062 4 |
| MoutainBike | 0.775 0 | 0.726 6 | 0.692 1 | 0.692 7 | 0.711 6 | 0.107 0 |
| Skating2-2 | 0.600 8 | 0.348 1 | 0.345 0 | 0.517 0 | 0.379 8 | 0.406 6 |
| Skiing | 0.539 4 | 0.090 9 | 0.094 7 | 0.050 8 | 0.051 1 | 0.029 3 |
| Tiger1 | 0.757 5 | 0.511 0 | 0.750 2 | 0.713 3 | 0.645 2 | 0.390 6 |
| Woman | 0.755 7 | 0.133 8 | 0.720 9 | 0.674 0 | 0.705 2 | 0.068 4 |
| 平均帧率/(f·s-1) | 2.008 0 | 50.580 0 | 0.376 0 | 5.612 0 | 170.564 0 | 55.401 0 |
综上所述, 本文方法可以充分利用目标的动态特征, 为之后目标具体位置的判断提供精确的预处理区域; 基于前一步提供的预处理目标框, 卷积神经网络能够对目标区域进行准确判定, 同时通过在线更新策略保持了算法的适应性和鲁棒性。另一方面, 虽然CFNet和DeepSRDCF方法也利用了目标的卷积特征, 但并没有使用动态特征提供预处理区域, 这也进一步说明两种特征的使用对跟踪效果提升的有效性, 表明本文利用动态特征和卷积特征的方法能够对视频中目标的快速运动、旋转、部分遮挡及场景中光线变化做出有效地处理, 实现对目标的稳定跟踪。
4 结论本文提出一种基于动态信息和卷积特征的单目标跟踪算法, 该算法结合两种深度学习网络, 首先长短期记忆网络提取目标的动态特征, 获得当前时刻预处理目标框; 然后对预处理目标框内图像, 运用卷积神经网络提取目标深度卷积特征, 对目标的位置进行准确判定; 跟踪过程中, 采集实现成功跟踪时的目标样本, 通过短期和长期方式对网络参数进行更新, 提高算法对目标变化的适应性和环境中干扰因素的鲁棒性。通过对比实验表明, 该方法在所选取的视频上实现了稳定、准确的跟踪表现, 对视频中出现的目标的快速运动、运动模糊、旋转、光线变化和目标被遮挡时具有较好的鲁棒性。下一步工作将对模型的计算复杂度进行优化, 引入更加高效的特征提取方法和更新策略, 提高算法实时性, 并应用于复杂环境下运动目标的跟踪任务中。
| [1] | LAURENSE V A, GOH J Y, GERDES J C. Path-Tracking for Autonomous Vehicles at the Limit of Friction[C]//Proceedings of the American Control Conference(ACC), 2017: 5586-5591 |
| [2] | SIVANANTHAM S, PAUL N N, IYER R S. Object Tracking Algorithm Implementation for Security Applications[J]. Far East Journal of Electronics and Communications, 2016, 16(1): 1-13. DOI:10.17654/EC016010001 |
| [3] | ONATE J M B, CHIPANTASI D J M, ERAZO N R V. Tracking Objects Using Artificial Neural Networks and Wireless Connection for Robotics[J]. Journal of Telecommunication, Electronic and Computer Engineering, 2017, 9(1/2/3): 161-164. |
| [4] | PEREZ P, HUE C, VERMAAK J, et al. Color-Based Probabilistic Tracking[C]//Proceedings of European Conference on Computer Vision, 2002: 661-675 |
| [5] | WANG Z, YANG X, XU Y, et al. CamShift Guided Particle Filter for Visual Tracking[J]. Pattern Recognition Letters, 2009, 30(4): 407-413. DOI:10.1016/j.patrec.2008.10.017 |
| [6] |
李冠彬, 吴贺丰. 基于颜色纹理直方图的带权分块均值漂移目标跟踪算法[J]. 计算机辅助设计与图形学学报, 2011, 23(12): 2059-2066.
LI Guanbin, WU Hefeng. Weighted Fragments-Based Meanshift Tracking Using Color-Texture Histogram[J]. Journal of Computer-Aided Design and Computer Graphics, 2011, 23(12): 2059-2066. (in Chinese) |
| [7] | HARE S, SAFFARI A, TORR P H S. Struck: Structured Output Tracking with Kernels[C]//Proceedings of the IEEE International Conference on Computer Vision, 2011: 263-270 |
| [8] | HENRIQUES, JOÃO F, CASEIRO R, MARTINS P, et al. High-Speed Tracking with Kernelized Correlation Filters[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2014, 37(3): 583-596. |
| [9] | BABENKO B, YANG M H, BELONGIES S. Robust Object Tracking with Online Multiple Instance Learning[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619-1632. DOI:10.1109/TPAMI.2010.226 |
| [10] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]//Proceedings of International Conference on Neural Information Processing Systems, 2012: 1097-1105 |
| [11] | DANELLJAN M, GUSTAV HÄGER, KHAN F S, et al. Convolutional Features for Correlation Filter Based Visual Tracking[C]//Proceedings of IEEE International Conference on Computer Vision Workshop, 2016: 621-629 |
| [12] | NAM H, HAN B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitionm, 2016: 4293-4302 |
| [13] | SUTSKEVER I, VINYALS O, LE Q V. Sequence to Sequence Learning with Neural Networks[C]//Proceedings of Advances in Neural Information Processing Systems, 2014: 3104-3112 |
| [14] | GRAVES A, MOHAMED A, HINTON G. Speech Recognition with Deep Recurrent Neural Networks[C]//Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, 2013: 6645-6649 |
| [15] | CUI Z, XIAO S, FENG J, et al. Recurrently Target-Attending Tracking[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1449-1458 |
| [16] | GREFF K, SRIVASTAVA R K, KOUTNÍK J, et al. LSTM:A Search Space Odyssey[J]. IEEE Trans on Neural Networks and Learning Systems, 2017, 28(10): 2222-2232. DOI:10.1109/TNNLS.2016.2582924 |
| [17] | RUSSAKOVSKY O, DENG J, SU H, et al. Image Net Large Scale Visual Recognition Challenge[J]. International Journal of Computer Vision, 2014, 115(3): 211-252. |
| [18] | VEDALDI A, LENC K. Matconvnet: Convolutional Neural Networks for Matlab[C]//Proceedings of the 23rd ACM International Conference on Multimedia, 2015: 689-692 |
| [19] | MVLLER M, BIBI A, GIANCOLA S, et al. Tracking Net: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild[C]//Proceedings of European Conference on Computer Vision, 2018: 310-327 |
| [20] | WU Y, LIM J, YANG M H. Object Tracking Benchmark[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834-1848. DOI:10.1109/TPAMI.2014.2388226 |
| [21] | DANELLJAN M, HAGER G, SHAHBAZ KHAN F, et al. Learning Spatially Regularized Correlation Filters for Visual Tracking[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 4310-4318 |
| [22] | VALMADRE J, BERTINETTO L, HENRIQUES J, et al. End-to-End Representation Learning for Correlation Filter Based Tracking[C]//Proceedings of Computer Vision and Pattern Recognition, 2017: 5000-5008 |
2. University of Chinese Academy of Sciences, Beijing 100049, China
