

2. 光电控制技术重点实验室, 河南 洛阳 471000
近年来, 基于相关滤波器的跟踪算法受到广泛关注, 该类方法属于判别式跟踪, 其实质是将跟踪问题转化成一个分类问题,通过在线训练的分类器将前景和背景进行分离, 实现目标跟踪的任务。
文献[1]提出了一种基于相关滤波器最小输出均方误差和的视频跟踪算法。文献[2]设计了2个一致并且相对独立的相关滤波器, 分别实现了目标位置跟踪和尺度变换。文献[3]将检测建议框架与相关滤波跟踪器框架相结合, 并采用了特征集成、鲁棒更新与建议拒绝等优化方法, 保证了各部分的有效整合。通过全局搜索, 文献[4]找出了利用轮廓特征标记出的建议候选样本, 得到较优的正负样本和更强的检测器, 来完成分类器测试和更新, 有效减少了分类器搜索空间, 降低虚假目标干扰。为了克服相关滤波器跟踪算法对于形变和旋转鲁棒性较差的问题, 文献[5]通过融合特征响应图的形式, 将相关滤波器框架和颜色模型框架进行融合, 提高了跟踪算法的鲁棒性。但是在互补特征的选择以及响应图的融合方式上还有待进一步研究。
本文将物体性检测理论引入到相关滤波跟踪和颜色模型跟踪的框架中, 多互补模型的分类器框架能够有效地对目标和背景进行分离, 克服跟踪器易受光照、背景干扰的问题, 降低跟踪虚假目标的概率。并且本文通过衡量不同模型预测响应图的置信度来推理该模型对目标和背景的分辨能力, 从而确定合适的加权权重, 提升跟踪性能。
1 融合多互补特征的跟踪算法Staple[5-6]算法通过相关滤波模型和颜色模型同时对目标和背景进行分类, 提高了跟踪器的泛化能力。然而, 跟踪模型还是易受到环境、光照等因素的干扰。基于上述问题, 本文在Staple算法的基础上融入了物体性检测模型[7], 充分利用样本信息多样化的特点。物体性检测模型基于物体边缘轮廓特征, 对光照、背景变换有良好的适应性。新算法通过结合3个互补模型分别对目标位置进行分类预测, 最后将得到的各个模型的预测响应图进行自适应加权融合来进一步提高跟踪器鲁棒性。算法整体框架如图 1所示。

|
| 图 1 多互补特征融合跟踪器框架 |
在第t-1帧, 得到最佳目标为Πt-1, 其中心位置矢量为pt-1, 大小为wt-1×ht-1。在t帧, 依据文献[5]提取搜索图像块zd, 中心位置矢量为pt-1, 大小为(wt-1+l)×(ht-1+l), l=(wt-1+ht-1)/2, 并通过插值法将zd等纵横比缩放为尺寸ψw0×ψh0的标准图像块zd, 使得ψw0×ψh0为一固定值C。然后通过滑动采样的方式, 得到样本边界框集合Ω。由于本文算法将目标的位移估计和尺度估计相分离, 所以滑动采样中的边界框Π, Π∈Ω, 大小固定为bw×bh
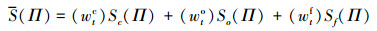
|
(1) |
式中, wtc, wto和wtf分别为对应模型的加权权重。最后选择得分最高的边界框的中心位置为最佳目标中心位置pt, 此过程同样等同于对模型各个响应图进行加权, 后取加权后响应中响应幅值最大的响应点作为目标中心位置。
1.1 平移滤波器模型与其响应图计算在训练过程中, 算法首先提取标准图像块zd及相应的d(d=28)维方向梯度直方图特征(HOG)fl, l∈(1, …, d)描述, 然后通过最小化目标函数, 训练一组d维滤波器h。目标函数公式为
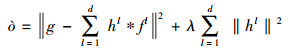
|
(2) |
式中,*表示循环相关, hl为第l维特征对应的滤波器系数, g为回归响应函数, 本文选择高斯函数。第二项λ表示正则化项。通过在频域下利用帕塞瓦尔定理进行快速求解, 得到滤波器的频域形式为:

|
(3) |
式中,G为高斯响应的DFT共轭项, Atl和Bt分别代表l维滤波器系数Hl的分子和分母项, Fk和Fk分别为k维特征图像块fk对应的频域形式以及对应共轭项。滤波器系数的更新策略如下:
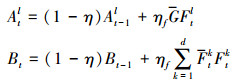
|
(4) |
式中,l=1, 2, …d, η为学习因子。
当获取到一帧新的图像序列后, 在上一帧目标中心位置矢量pt-1提取搜索图像块zd, 并按上文方法归一化为分辨率为固定值C的标准图像块zd, 然后提取zd的d维方向梯度直方图特征(HOG)ztl, l=1, 2, …d, 并得到各维度特征块的频域形式Ztl, 最后与训练好的相关滤波器进行卷积得到滤波器的权重分数响应yth
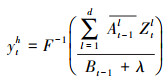
|
(5) |
式中,At-1l和Bt-1是上一帧训练得到的位置滤波器的分子项和分母项。
得到的滤波器响应图yth可等效地表示在滤波器模型下, 预测得到的不同位置固定尺寸(wt-1×ht-1)边界框Π的权重分数Sf(Π)。
1.2 物体性检测模型预测基于轮廓信息的物体性检测模型可以通过图像的轮廓信息对样本边界框集合Ω中所有边界框打分, 分数大小表示边界框内包含目标的概率。算法通过结构化边缘检测计算出标准检测图像块zd中每一个像素点p对应的边缘幅值mp和方向θp, 并将mp>0.1的像素点记作边界点。将形成相干边界点组成的一条边或曲线定义为轮廓并将边界群定义为属于相邻轮廓的边界像素的集合。因此边界群内的相邻点不仅应该距离靠近, 梯度方向也应该接近, 而那些未连接或通过高曲率的轮廓相连的边界像素就不太会属于同一边界群。基于此依据, 文献[7]定义了2个边界群之间的相似度。设任意2个边界群si和sj对应的平均中心位置分别为xi和xj, 平均梯度方向为θi和θj, θij为θi和θj之间的夹角, 那么si和sj的相似度a(si, sj)表示为:
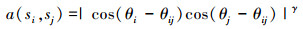
|
(6) |
式中,γ用来调节相似度对方向的敏感程度。当2个边界群之间的距离大于2个像素时, 则两者的相似度就为0。
算法首先计算标准检测图像块zd中所有的边界群, 对于位于zd中任意位置的一个边界框样本Π, 文献[7]中计算出每一个边界群si完全位于Π的权重分数分ζi, ζi∈[0, 1], 边界框b的物体性权重分数So(Π)可表示为:

|
(7) |
式中, bw和bh分别为边界框Π的宽和高。bin代表边界框Π的中心区域, 尺寸为(bw/2)×(bh/2);r表示边界框内的任意一个边界像素, mr为r的响应幅值, mi为边界群si中所有边界像素幅值之和, ζi为边界群si完全位于b的权重分数, 边界像素响应幅值和ζi的计算方法可见文献[7], ζi越高表示si完全位于Π内的可能性就越大; k为对目标长、宽大小的惩罚系数。
因此, 可以通过物体性模型有效地计算出边界框样本集合Ω中任意位置边界框的物体性分数So(Π), 由于响应图中每个点对应Ω中一个样本, 其响应值对应Ω的得分, 因此可以得到整个物体性响应图yto。
1.3 颜色模型预测基于颜色模型的目标跟踪方法具有旋转、平移和尺度不变性的优点。文献[5]中颜色频率的计算和像素权重分数的计算都是在映射空间中完成的。训练阶段算法将训练图像块分割为目标区域和背景区域两部分, 并将所有RGB像素映射到bin空间下的索引像素, 并分别统计任意索引像素j在目标区域的频率ρtj(O)和属于背景的频率值ρtj(B), 且每一帧分别对频率信息进行更新。
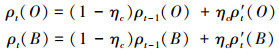
|
(8) |
式中,ρt(·)是由ρtj(·), j=1, …M,组成的M维向量, 其中M=2 048。
在预测阶段, 搜索标准图像块zd中的每一个像素点v属于目标的权重βtφ(v)和像素索引j=φ(v)出现在目标区域的频率值ρtφ(v)(O)以及像素索引j出现在背景区域的频率值ρtφ(v)(B)有关, βtφ(v)的计算表示为
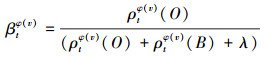
|
(9) |
式中, 任意的ρtj(O)和ρtj(B)已经在训练阶段计算得到, 所以ρtφ(v)(O)和ρtφ(v)(B)可通过查找表直接得到。λ用来保证分母非零。当计算出搜索图像块zd中的每一个像素点v属于目标的权重βtφ(v)后, 就得到了与zd尺寸相同的每个像素的分数响应图, 再通过计算滑动窗口产生的每一个边界框Π内所有像素权重平均值, 并用图像卷积进行加速计算。
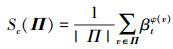
|
(10) |
式中,|Π|表示边界框Π的像素总数。最终可以得到边界框样本集合Ω中任意边界框的颜色权重分数Sc(Π), 进而同物体性检测模型相同, 可以得到颜色响应ytc。
1.4 基于响应图置信度的自适应融合算法文献[5]对于2个响应图的融合采用了固定权重的融合方式, 然而, 目标跟踪过程中各个时刻跟踪器中各个模型受干扰程度往往不尽相同, 固定权重不能准确有效地利用各个模型的预测信息, 导致跟踪器对目标跟踪的鲁棒性不高。对于融合多通道的跟踪器来说, 若不能对受不同程度干扰的模型动态加入合适的权重系数, 跟踪的稳定性难以得到保证。为此, 本文通过有效地计算不同模型预测响应图的置信度, 进而自适应地对模型权重进行调整, 进一步提高跟踪算法的鲁棒性。
文献[6]中用不同模板对正负样本的分别能力来表示跟踪的置信度, 其计算过程需要一定数量有对应标签的目标样本。然而, 目标样本标签的得到一般是通过跟踪器历时帧的跟踪结果来确定的, 因此跟踪结果发生飘逸将会导致置信度的计算错误, 跟踪器陷入循环的错误计算中。而文献[6]通过将上述问题转换为半监督的部分标签问题, 首先计算一个可能的部分带有标签的图像块样本集合:
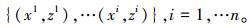
|
(11) |
候选目标边界框集合的获得, 需要分别计算滤波器模型响应图、颜色模型响应图以及物体性检测模型响应中响应权重较大的目标边界框集合v1, v2和v3, 并取其并集v=v1∪v2∪v3, 得到总的候选边界框集合v。同时, 通过迭代合并相邻位置点使得到的任意2个边界框之间的重合度小于0.5, 保证集合中只有一个边界框为真目标边界框。最终得到的这些边界框集合是基于各个模型估计的属于目标可能性高的边界框, 对于这些边界框是否属于目标的进一步的分辨能力往往决定了其跟踪目标的性能。设最终的边界框集合为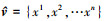
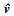
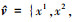
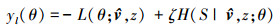
|
(12) |
最大似然概率L和损失熵H的计算公式分别为:

|
(13) |
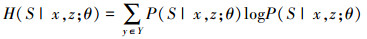
|
(14) |
这里假设目标所在位置概率模型P(li|ϕi)为高斯分布函数。并且假设P(li|ϕi, xi; θ)=P(li|ϕi; θ)成立, 则条件概率可以表示为
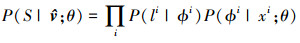
|
(15) |
同时令
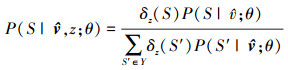
|
(16) |
式中,S′∈z时δz(S′)取1, 否则为0。详细过程可以参考文献[6]。得到复合特征响应图和滤波器响应图的置信度后, 就可以计算各个响应图的加权权重。
在预测结果的加权权重设计中, 本文通过考察不同模型对不同位置边界框是否属于目标的分辨能力强弱, 并结合模型对历史帧边界框分辨能力来决定该当前帧该模型预测结果的加权比重。在跟踪过程中, 当某一模型预测结果的置信度高时, 则保持该模型预测响应图加权权重不变, 当某一模型的预测结果置信度低时, 降低其预测响应图加权权重。模型预测结果置信度高低的判断方法如下:设yt*为t时刻不同模型的预测响应图, Et*为该模型的响应图, Et*为该模型响应图前Δ帧的平均置信度, Et*的计算公式分别为:
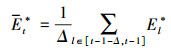
|
(17) |
基于上述讨论, 本文提出通过从以下方式对HOG模型在t时刻的加权权重wt*进行自适应调整
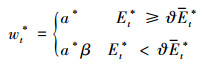
|
(18) |
式中, a*表示不同模型预测响应图的初始加权权重, β为当模型响应图置信度低时响应图加权权重的衰减系数, ϑ为预先设定的模型在t时刻置信度应高出前Δ帧平均置信度值的对比系数。最终的响应图yt的融合公式如下:

|
(19) |
式中, wtf, wtc和wto分别为滤波器响应图yth、颜色响应图ytc和物体性响应图yto的自适应加权权重。
1.5 尺度的计算和优化当平移滤波器确定出目标中心坐标后, 引用文献[5]的方法, 用一维尺度滤波器计算目标当前尺度。尺度金字塔建立如下
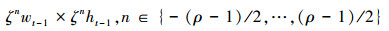
|
(20) |
式中, wt-1, ht-1分别为目标在上一帧的宽和高。ζ为尺度放缩因子, 本文选择1.02, ρ为尺度金字塔的层数, 本文选择33。具体计算可参考文献[5]。
1.6 算法实现本文算法可分为4个主要组成部分:初始化、位置估计、尺度估计和模型训练。具体步骤如下:
1) 初始化
初始设置算法的初始参数, 以及第一帧序列中目标的位置和尺度状态。
2) 位置估计
a) 在t帧序列中以上一帧目标中心位置矢量为pt-1和尺度(wt-1×ht-1)提取搜索图像块zd, 大小为(wt-1+l)×(ht-1+l), 并插值得到尺寸归一化后的图像块zd。
b) 提取zd的28维特征, 并通过Atl、Bt和公式(5)计算出滤波器响应图yth。
c) 分别计算zd的边界响应和图像块中所有的边界群, 并通过公式(7)计算出物体性响应图。
d) 根据公式(9)计算出zd的每个像素颜色响应图, 并通过积分图(公式(10))计算出颜色响应分数。
e) 根据公式(11)计算每个模型响应图置信度, 并通过公式(18)计算出每个响应图对应的自适应加权权重。最后通过(19)计算出最终的响应图yt, 选择响应值最大的位置作为新的目标中心位置。
3) 尺度估计
根据尺度金子塔对目标尺度进行估计。
4) 模型训练
根据新的目标中心位置矢量pt和尺度(wt×ht)提取训练图像块, 通过公式(4)更新滤波器系数, 利用公式(8)和(9)更新颜色模型的权重分数βtj。
2 实验结果本文在计算机处理器为i7, 主频为3.5GHz CPU, 内存为8G RAM的硬件配置下通过MATLAB2016b软件对算法在OTB2015提供的100个视频序列上进行了实验评估。测试视频序列包含的干扰特征包括特征有:遮挡, 光照变化, 尺度变化, 运动模糊, 快速运动, 平面外旋转, 变形等。实验中的参数设置如表 1所示。
| 参数名 | 取值 |
| 滤波器学习速率ηf | 0.01 |
| 尺度滤波器学习速率 | 0.035 |
| 初始滤波器模型加权权重al | 0.55 |
| 初始滤波器模型加权权重ao | 0.2 |
| 初始颜色模型加权权重ac | 0.25 |
| 固定区域 | 150 |
| 颜色空间 | RGB |
| bin颜色空间 | 32×32×32 |
| 颜色模型学习速率ηc | 0.04 |
| β | 0.6 |
| ϑ | 0.9 |
| 惩罚系数k | 1.5 |
| 调节因子γ | 2 |
| ζ | 0.7 |
| HOG特征胞元大小 | 4 |
| 历史帧数Δ | 5 |
如图 2所示, 本节选取了4个同时包含多种挑战因素的视频序列来对算法进行定性评估, 并列出了包括双线性支持向量机(DLSSVM)、具有通道和空间可靠性的判别相关滤波器(CSR-DCF)以及融合相关滤波器模板和颜色特征模板跟踪算法(Staple)以及本文算法在内的4种跟踪算法的跟踪结果。

|
| 图 2 各个算法在各测试序列上部分时刻的跟踪结果 |
Shaking序列中存在剧烈的光照变化, 并存在一定目标形变。如图 2a)所示, 由于CSR-DCF依赖颜色信息, 当第10帧时光照发生强烈变化时, CSR-DCF产生了严重的跟踪飘逸。在第64帧Staple算法已经跟踪失败, DLSSVM也已经产生了较大的跟踪误差。而本文算法能够较好地对目标进行跟踪。
Girl 2序列中存在着完全遮挡的干扰, 本文算法当目标出现后能及时捕获到目标, 同样在第1 384帧后目标又出现了完全遮挡的问题, 在第1 399帧, 本文算法依旧能够较准确地跟踪到目标。
Couple序列中存在着相似背景和运动模糊的干扰, 在第92帧和107帧时, Staple算法和CSR-DCF相继出现跟踪失败。而DLSSVM算法和本文算法能有效地提取正确的目标表观信息, 较好地适应目标表观变化, 完成目标跟踪的任务。
在Freeman 4序列中, 目标分辨率较低同时存在着一定的目标遮挡。如第207帧DLSSVM、CSR-DCF以及Staple算法都出现了跟踪飘逸, 在第271帧Staple和CSR-DCF算法甚至已经完全跟踪失败, 而本文算法能够较好地对目标跟踪进行跟踪。
2.2 定量分析本节采用中心位置误差(CLE)和重叠率(OR)进行性能评估。一般来说, 较小的平均误差和较大的重叠率意味着更准确的跟踪结果。表 2和表 3分别表示不同算法在各个测试序列中的中心位置平均误差和边界框重叠率平均值的比较结果。表 4给出了各个算法在OTB2015中100序列中的平均跟踪帧率。表 2、表 3以及表 4中最优及次优的结果分别用1和2进行标注。
| 序列 | 算法 | |||
| DLSSVM | CSR-DCF | Staple | 本文算法 | |
| Couple | 7.916 | 7.7412 | 34.588 | 6.1841 |
| Freeman 4 | 50.385 | 16.8362 | 21.212 | 5.0991 |
| Shaking | 11.2012 | 11.505 | 125.060 | 6.9721 |
| Girl 2 | 72.887 | 44.7202 | 111.738 | 12.1221 |
| 序列 | 算法 | |||
| DLSSVM | CSR-DCF | Staple | 本文算法 | |
| Couple | 0.589 | 0.6432 | 0.527 | 0.7211 |
| Freeman4 | 0.143 | 0.389 | 0.4052 | 0.5961 |
| Shaking | 0.668 | 0.6742 | 0.057 | 0.7691 |
| Girl2 | 0.3752 | 0.276 | 0.070 | 0.6801 |
本文采用一次性评估实验OPE通过OTB2015提供的100个视频序列对Staple、DLSSVM、CSR-DCF、基于循环特征映射的跟踪算法(LMCF)、空间正则化滤波跟踪器(SRDCF)、滤波网络跟踪器(DCFNet)、全卷积网络跟踪器(SiamFC)、卷积神经网络支持向量机跟踪器(CNN-SVM)和本文算法在内的9种跟踪器进行整体性能测试和对比。如图 3所示, 本文算法由于在Staple算法的基础上, 融合了物体性检测模型, 充分利用了样本信息的多样化的特性, 并采用自适应权重的融合方式来调整各模型加权比重, 有效提升了跟踪算法的鲁棒性。新算法在和OTB2015序列集下得到的精度和成功率相比较于其他跟踪算法均取得了最好的性能。其次, 引入的置信度计算本身复杂度较低, 所以保证新算法依然能够保持较高的跟踪实时性。通过表 4可得, 新算法和Staple算法相比, 依然有着较高的跟踪实时性。

|
| 图 3 跟踪器在OTB2015上的测试结果 |
为了提高跟踪算法适应复杂场景的能力, 本文在Staple算法的基础上融入了基于轮廓特征的物体性检测模型, 与原有基于HOG特征的滤波器模型和颜色模型结合形成一种融合多互补模型的跟踪算法。并针对该算法中对不同模型预测响应结果进行简单线性加权带来的跟踪性能不稳定的问题, 提出一种以最大似然概率和损失熵作为响应图置信度的自适应预测响应图加权权重计算方法。实验结果表明, 新算法在多种复杂场景中能有效地解决目标跟踪性能较低的问题, 并且实时性较强。
| [1] | BOLME D S, BEVERIDGE J R, DRAPER B A, et al. Visual Object Tracking Using Adaptive Correlation Filters[C]//Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition. Washington, 2010: 2544-2550 http://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf |
| [2] | DANELLJAN M, HäGER G, KHAN F S, et al. Accurate Scale Estimation for Robust Visual Tracking[C]//Proceedings of the British Machine Vision Conference, Durham, 2014: 65.1-65.11 http://www.cvl.isy.liu.se/research/objrec/visualtracking/scalvistrack/ScaleTracking_BMVC14.pdf |
| [3] | HUANG D. Enable Scale and Aspect Ratio Adaptability in Visual Tracking with Detection Proposals[C]//Proceedings of the British Machine Vision Conference, Durham, 2015: 185 http://www.bmva.org/bmvc/2015/papers/paper185/paper185.pdf |
| [4] | ZHU G, PORIKLI F, LI H. Beyond Local Search: Tracking Objects Everywhere with Instance-Specific Proposals[C]//Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, 2016: 943-951 https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Zhu_Beyond_Local_Search_CVPR_2016_paper.pdf |
| [5] | BERTINETTO L, VALMADRE J, Golodetz S, et al. Staple: Complementary Learners for Real-Time Tracking[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Washington, 2016: 1401-1409 http://www.robots.ox.ac.uk/~luca/staple.html |
| [6] | ZHANG J, MA S, SCLAROFF S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization[C]//Proceedings of the 2014 European Conference on Computer Vision, Berlin, 2014: 188-203 https://link.springer.com/chapter/10.1007/978-3-319-10599-4_13 |
| [7] | ZITNICK C L, DOLLÁR P. Edge Boxes: Locating Object Proposals from Edges[C]//Lecture Notesin Computer Science: 8693. Heidelberg: SpringerVerlag, 2014: 391-405 |
2. Science and Technology on Electro-Optic Control Laboratory, Luoyang 471000, China
