

2. 中国空间技术研究院 西安分院, 陕西 西安 710100
现阶段为了在地球探测卫星中使用高效的自适应编码调制技术,太空数据系统咨询委员会(consultative committee for space data systems, CCSDS)131.3-B-1标准[1]给出了采用DVB-S2标准[2]来传输CCSDS传输帧的方案解决了DVB-S2与CCSDS的格式兼容性问题。众所周知DVB-S2是欧洲第二代数字卫星电视广播标准,它给出了高功率高频谱效率的自适应编码调制系列解决方案,且已经获得了广泛应用,然而,由于卫星广播系统的最大传输吞吐量只有135 Mbit/s(兆比特每秒,Million bits per second),而地球探测卫星需要高达几个Gbit/s(千兆比特每秒,Giga bits per second)的吞吐量。可见DVB-S2标准中的自适应编译码器芯片不能直接应用于CCSDS,而迫切需要研究千兆比特每秒的高速LDPC编译码器方案,另外地球探测卫星与地面接收站的距离会周期性变化,且其Ka波段的载频受雨衰影响较大,这就需要其具有码率兼容的自适应特性。因此,DVB-S2标准中的高吞吐率码率兼容LDPC编译码器设计技术是地球探测卫星系统升级的关键技术。
虽然DVB-S2标准中的LDPC码具有特定的结构,但是由于其校验矩阵右边双对角矩阵的存在会导致译码中间信息的存储器访问冲突。现阶段已经有一些文献[3-6]考虑了双对角矩阵的存储器访问冲突解决方案,然而对于分层译码器需要2个桶形移位寄存器来修正,这占用了大量的额外硬件资源。文献[7]中称其为“硬件补丁法”;为了降低硬件资源,另外一种方法是采用“控制补丁法”解决方案,如文献[7-9],由于仅使用一个桶型移位寄存器,所以极大降低了“硬件补丁法”的复杂度和延迟,但是会导致译码性能或吞吐量损失。在文献[8]中,通过降低并行度来大量减少双对角的更新行数,会造成较大的误帧率损失。在文献[9]中,在重复的分层中采用适当的存储控制来抵消双对角的更新行数减少的影响,但当并行度较高时,由于流水线的处理导致分层重复更新而极大地约束了解决冲突的效果。文献[7]提出了一种优化的简化存储控制方法来抵消未更新的双对角行数对性能的影响,即使采用全并行译码,其带来的译码性能损失也几乎是微乎其微的。可见“硬件补丁法”需要大量的额外硬件资源,而“控制补丁法”会导致译码性能的损失,且随着吞吐量的增加,性能损失急剧增大。另外,文献[10]采用IP核的方法来设计DVB-S2译码器,但吞吐量较低,只有40.9~71.7 Mbit/s。
针对升级版的地球探测卫星对DVB-S2标准LDPC码兼容设计及高吞吐量译码器的需求,与现有传统DVB-S2应用不同,为了解决存储器访问冲突,本文提出一种采用矩阵变换的方法,该方法既不占用额外的硬件资源也不带来译码性能的损失。在硬件实现之前先对原始下三角双对角结构的IRA校验矩阵进行初等变换为准循环和行变换下三角双对角结构的组合矩阵。而对这种新的校验矩阵进行FPGA实现,左边准循环子矩阵可以采用现阶段成熟的技术来实现高速自适应码率兼容的架构,而右边行变换下三角双对角结构子矩阵设计时只需要兼容现有成熟的准循环硬件实现方案即可,这样就保证了现阶段LDPC译码器研究成果能在设计的译码器上成功使用。
1 DVB-S2 LDPC结构及译码算法 1.1 DVB-S2标准的LDPC码特性DVB-S2标准中LDPC码的校验矩阵H包含两部分,如公式(1)所示
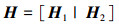
|
(1) |
H由H1和H2两部分组合而成, 分别为M×K和M×M。其中, H2是一个下三角双对角结构的矩阵, 如图 1给出了DVB-S2标准中16 200码长7/9码率的LDPC码H矩阵非零元素分布图。如图 1所示,子矩阵H1的行的规律性为每q行(DVB-S2标准中给出的5种码率q值如表 1所示)作为一块整体向右循环移动一次得到下q行, 共右循环移动了360次。

|
| 图 1 码率为7/9的LDPC码H矩阵非零元素分布图 |
硬件实现中最常用的软判决迭代译码算法是归一化最小和算法(normalized min-sum algorithm, NMSA)[5], 当变量节点传递给校验节点信息(variable to check messages, V2C)Qmn(0)初始化为信道信息Cn(见公式(2))时, NMSA的校验节点更新单元(check node update, CNU)在第i次上半次迭代进行校验节点传递给变量节点信息(check to variable messages, C2V)Rmn(i)的更新, 见公式(3):

|
(2) |
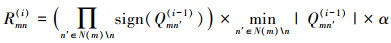
|
(3) |
N(m)是连接校验节点m的变量节点集合, N(m)\n表示在集合N(m)中去掉变量节点n的子集合, α为NMSA算法的归一化因子。
变量节点处理单元(variable node update, VNU)计算Qmn(i)和Qn(i)处理第i次下半次迭代, 公式如下:
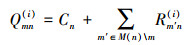
|
(4) |
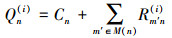
|
(5) |
同理, 集合M(n)表示连接变量节点n的校验节点, M(n)\m表示从集合M(n)中去掉一个校验节点m之后形成的子集。
上面的C2V和V2C统称为外信息。迭代译码一直重复直到校验方程满足或达到预先设定的最大迭代次数, 校验方程满足与否由校验方程计算模块(parity check update, PCU)来判定。
2 提出的高速码率兼容DVB-S2的LDPC码译码器架构现阶段文献中研究最多的LDPC高速译码器是准循环QC-LDPC译码器, 因为块内循环QC特性可以降低存储器访问复杂度, 分块特性有利于实现部分并行的译码器。但DVB-S2标准的LDPC码不是QC-LDPC码, 本节将详细介绍DVB-S2标准的LDPC码与QC-LDPC码的关系, 并借助QC-LDPC译码器架构提出本文的高速码率兼容DVB-S2的LDPC码译码器架构。
2.1 DVB-S2标准的LDPC码与QC-LDPC码的关系通过对H的行按0, q, …, 359q, 1, q+1, …, 359q+1, ……, q-1, …, 359q+q1的顺序变换, 左边得到一个q×45分块, 每个块为L×L准循环矩阵, 记为H1t, 右边双对角结构的矩阵H2也要经过同样的行变换, 得到一个新的行变换下三角双对角矩阵(简称为TST), 记为H2t。
图 2给出了DVB-S2标准中16 200码长7/9码率的LDPC码H矩阵的变换矩阵, 如公式(6)所示:

|
| 图 2 码率为7/9的LDPC码变换H矩阵非零元素分布图 |

|
(6) |
可见, H1t是一个基矩阵大小L×L的q×(45-q)循环QC子矩阵, 而H2t是一个qL×qL的TST子矩阵, 如图 3所示。其中的q值, 见表 1, 本文选用DVB-S2标准中L=360对应的16 200码长的5个码率LDPC码进行硬件实现, 来验证本文提出的架构具有的优势。为了实现码率兼容资源的最大复用率, 表 2给出了16 200码长的5个校验矩阵对应的行重dc和列重dv, 其中的12(6)表示列重为12的有6个。

|
| 图 3 Ht矩阵的结构图 |
| 码率 | H1t的dv | H2t的dv | Ht的dc |
| 2/5 | 12(6), 3(12) | 2(27) | 6(27) |
| 3/5 | 12(9), 3(18) | 2(18) | 11(18) |
| 2/3 | 13(3), 3(27) | 2(15) | 10(15) |
| 7/9 | 3(35) | 2(10) | 12(3), 11(1), 13(6) |
| 8/9 | 4(5), 3(35) | 2(5) | 27(5) |
见1.2节, 处理单元CNU和VNU占用了译码器的大部分资源, 为了有效地对码率兼容LDPC码译码器进行设计, 不同码率之间应该最大程度地共享处理单元资源。通过对表 2进行分析, 可以得到2种处理单元CNU和VNU的最小数量。校验节点单元CNU用来进行行信息的更新, 将行重设计为13可以兼容10, 11, 12, 13行重情况, 所以码率兼容译码器需要3种行重情况{6(27), 13(18), 27(5)}, 译码器需要27p个6输入的CNU, 18p个13输入和5p个27输入的CNU, 分别记为CNU6, CNU13和CNU27, 这里p表示块内的并行度数。同理, 变量节点更新单元VNU用来进行列信息的更新, 列重为{2, 3}和{12, 13}可分别设计为列重为3和13情况的VNU。可见VNU需要设计为3种列重的情况{3(45), 4(5), 13(6)}, 即译码器需要45p个(3+1)输入, 5p个(4+1)输入和9p个(13+1)输入的VNU, 分别记为VNU3, VNU13和VNU4, 如表 3所示。
| 码率 | CNU6 | CNU27 | CNU13 | VNU4 | VNU13 | VNU3 |
| 2/5 | 27p | 0 | 0 | 0 | 6p | 39p |
| 3/5 | 0 | 0 | 18p | 0 | 9p | 36p |
| 2/3 | 0 | 0 | 15p | 0 | 3p | 42p |
| 7/9 | 0 | 0 | 10p | 0 | 0 | 45p |
| 8/9 | 0 | 5p | 0 | 5p | 0 | 40p |
| 多码率 | 27p | 5p | 18p | 5p | 9p | 45p |
处理单元在计算过程中产生了大量的中间数据需要存储, 本文采用存储块RAM_M和MCt分别来存储QC准循环矩阵H1t和TST矩阵H2t所对应的外信息。H2t的非零元素采用数组E[c][d]来表示, 其中, 列标为c(1≤c≤q×L), 因为H2t的行重为1或2, 令d(0≤d≤1)表示H2t的第d个非零元素。从图 2中可见H2t共有2q个非零元素, 分别为:
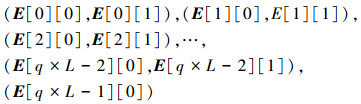
|
(7) |
它们与原始矩阵H2的行号相对应。为了更明确地描述TST子矩阵H2t的2q个非零元素, 如表 4所示。
| 行块号 | 子行号 | E[c][d] | |
| s=0 | r=0 | [0][0] | |
| r=1 | [q×1-1][1] | [q×1][0] | |
| … | … | … | |
| r=L-1 | [q×(L-1)-1][1] | [q×(L-1)-1][0] | |
| s=1 | r=0 | [0][1] | [1][0] |
| r=1 | [(q+1)×1-1][1] | [(q+1)×1][0] | |
| … | … | … | |
| r=L-1 | [(q+1)×(L-1)-1][1] | [(q+1)×(L-1)-1][0] | |
| s=q-1 | r=0 | [q-2][1] | [q-1][0] |
| r=1 | [(2q-1)×1-1][1] | [(2q-1)×1][0] | |
| … | … | … | |
| r=L-1 | [(2q-1)×(L-1)-1][1] | [(2q-1)×(L-1)-1][0] | |
从表 4可以看到, TST子矩阵包括q个行块, 每个行块s(0≤s≤q-1)由L=360个子行r(0≤r≤L-1)组成, 其非零元素均采用2个深度为L的存储器来存储, 所以TST子矩阵总共需要2q个存储器来存储外信息, 与之对应的存储器定义为MCt, x, (1≤x≤2q), 这2q个存储器的标号分别为(s=0|MCt, 1, MCt, 2), …, (s=q-1|MCt, 2q-1, MCt, 2q)。
通过分析TST处理单元的工作流程, 发现TST的校验节点处理阶段, 需要读取每个行块s所对应的2个存储块, 即MCt, 2s-1, MCt, 2s, 而TST的变量节点处理阶段, 其读取的是s所对应的2个存储块MCt, (2s)%(2q), MCt, (2s+1)%(2q)。为了能使CNU和VNU交错地读取这两块存储器, 不产生存储器访问冲突问题, 我们引入一个2q×2q的TST网络交换模块, 存储器MCt, x对应的输入端口为(2, 3), (4, 5), …(2q, 1), 输出端口号为(1, 2), (3, 4), …(2q-1, 2q)。可见, 本文提出的表 4中的TST存储方式可以有效地解决存储器访问冲突问题。
TST子矩阵对应的信道信息存储在存储器Ft中, 假设按列的顺序进行信道信息的存储。从存储器MCt, x的内容可知, 与其对应的列号分别为0+y, q+y, 2q+y, …, q×(L-1)+y, y(0≤y≤q-1), 所以VNU处理单元工作阶段, Ft需要与2个存储器MCt, x进行数据交互。
2.4 提出的DVB-S2标准的码率兼容LDPC码译码器的存储器设计本文提出的码率兼容DVB-S2标准LDPC译码器架构需要3种存储器资源:信道信息存储器(RAM_QC, RAM_TST)、外信息存储器(RAM_M, RAM_C)和硬判决存储器, 每个存储器采用的深度均为
DVB-S2标准中不同码率基矩阵的列数相同均为n, 所以可以复用信道信息存储器, 总共需要n=45个存储器来存储信道信息, 复用时需要n-q个RAMF和q个Ft。然而, 由于不同码率校验矩阵差别较大, 外信息的复用方式较复杂, 对于LDPC译码器, 外信息存储器个数与基矩阵非零元素数成正比, 因为不同码率的QC子矩阵对应的基矩阵有不同的非零元素, 表 5给出了每种码率所占使用的存储器数量。如表 5所示, 令g表示多码率QC子矩阵基矩阵的非零元素的个数, gmax=162, 考虑到TST子矩阵部分存储器的个数为2q, 所以码率兼容译码器存储外信息的总数为gmax+2q=198。按照上面的分析, 得出5种DVB-S2码率兼容LDPC译码器总共需要198+45=243块存储器。
| 码率 | RAMF | Ft | RAMMC | MCt | 信道信息 | 外信息 |
| 2/5 | 18 | 27 | 108 | 54 | 45 | 162 |
| 3/5 | 27 | 18 | 162 | 36 | 45 | 198 |
| 2/3 | 30 | 15 | 120 | 30 | 45 | 150 |
| 7/9 | 35 | 10 | 105 | 20 | 45 | 125 |
| 8/9 | 40 | 5 | 125 | 10 | 45 | 135 |
按照上文的描述, DVB-S2的LDPC校验矩阵经过矩阵变换后的新矩阵Ht由准循环QC子矩阵和TST子矩阵组成, 为了使TST与QC矩阵所对应的译码器架构兼容, 本节针对HHt提出了一种QC-TST译码器架构, 如图 4所示。

|
| 图 4 提出的DVB-S2标准的QC-TST译码器架构框图 |
p>1的并行度对应高吞吐量情况, 该架构可以简单地应用到p=1的低吞吐量情况。关于QC子矩阵的架构采用本文作者前期工作[11]中的方法, TST子矩阵的处理需要与QC子矩阵兼容, TST部分通过采用位宽和深度与QC部分同样规格的RAM模块, 便于码率兼容设计时存储资源的复用, 为了避免各个处理单元访问TST存储器导致的访问冲突问题引入TST网络交换模块。提出的QC-TST译码器的具体译码步骤如下:
输入信号包括帧同步指示信号syn, 因为对于分组码, 在译码之前还需要获得帧同步信号syn, 该信号由帧同步器模块来提取, 见文献[12]; 码率信号rate, 对于n种LDPC码的情况, rate的位宽为 
输出信号包括译码码字输出datout和伴随该输出的帧同步信号synout及码率信号rate, 之所以需要这2个信号是因为LDPC译码器后端还需要其他处理, 例如在DVB-S2标准中, LDPC译码器后端还需要BCH译码器。datout是位宽为p比特的信号。
1) 初始化;
当译码帧到来, 即帧同步信号为高电平时, 将接收到的帧数据所对应的信息位和校验位信息分别存储到信息存储块RAM_QC和校验存储块RAM_TST中, 同时, 将外信息存储块RAM_C和RAM_M初始化为零, 初始化迭代次数Titer=1;
2) 变量节点更新(VNU-VTU);
首先VNUi, 1≤i≤45-q从RAM_QC和RAM_M中分别读出H1t矩阵对应的信道信息和外信息, VTUi, 1≤i≤q分别RAM_TST和RAM_C中读取H2t矩阵部分对应的p个信道信息和外信息存储块MC(2i)%(2q)和MCt, (2i+1)%(2q)中的2p个外信息; 然后各自进行变量节点外信息更新计算和码字判决; 最后, 将结果写回到RAM_M和RAM_C中, 更新后的信息回写至相同的RAM_TST存储器地址中, 同时码字判决结果也写入RAM_OUT, 用于译码的待输出。
3) 校验节点的更新和校验方程的计算(CNU-PCU);
首先CNUi, 1≤i≤q和PCUi, 1≤i≤q从RAM_C和RAM_M读出变量节点更新后的外信息和码字判决结果; 然后, 来自存储器RAM_M的(n-2)p个H1t矩阵外信息和来自存储器MC2s-1, MC2s的2p个H2t矩阵外信息, 同时发送给CNU进行校验节点外信息计算, PCU仅获取码字判决结果根据校验阵读出对应的译码判决比特, 计算将各方程的校验值, 组成伴随式向量s; 最后, CNU将结果回写到存储器RAM_M和MCt, 2s-1, MCt, 2s的相同地址和RAM_C中; 迭代次数Titer加1;
4) 判决;
若伴随式向量s=0或Titer达到预设的最大迭代次数MAX_ITER, 转步骤5);否则, 转步骤2)继续下一轮迭代处理;
5) 从RAM_OUT读出译码判决比特, 输出译码码字。
现阶段处理模块的实现技术研究较多(见文献[11-13]), 为了提高时钟频率均采用降低关键路径延迟的方法, 即在CNU和VNU计算过程中插入多级流水线。本文假设在CNU和VNU中分别插入c级和v级流水线。列重dv越重, v越大, 同理行重dc越重, c越大。本文提出的译码流程的译码器一次迭代所需要的时钟周期为v+c+
采用本文提出的这种矩阵变换方法加QC-TST译码器架构, 在Xilinx XC7VX485T FPGA上实现了DVB-S2标准中兼容5种码率的一个LDPC译码器, 综合和布局布线采用Vivado 2015.1。
本文提出的译码器并行度可以被任意配置, 考虑到本文使用的FPGA资源情况, 并行度配置为p=5的情况。如表 4所示, 可见分别需要的校验节点处理单元的个数分别为27p=135个CNU6, 18p=90个CNU13和5p=25个CNU27;变量节点处理单位的个数分别为45p=90个VNU3, 9p=45个VNU13和5p=25个VNU4。
从表 5中可以看到, 需要243块双端口18 kbits BRAM来存储信道信息和外信息, 而硬判决RAMC需要大小为
考虑到最大列重和行重分别为13和27, 为了平衡设计, VNU和CNU均采用v=6和c=6和流水线, 所以本文提出的译码器完成一次迭代需要v+c+ 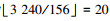

|
| 图 5 码率兼容DVB-S2译码器结合高阶调制性能图 |
为了进一步提高吞吐量, 采用CNU和VNU交替对2帧不同的数据进行译码, 所以译码器可以同时接收并行10路信道信息输入的情况。现阶段的LDPC一般与MPSK或MAPSK等二维调制方式相结合, 此时译码器同时接收I, Q 2路数据对应的帧, 所以I/Q路均采用并行5路输入的情况, 每路用6比特表示, 并行10路共输入60比特。本文提出的译码器方案支持连续输入的情况时, 是一个输出连续的实时译码器, 译码器迭代处理模块的时序如图 6所示, 当然本译码器也支持对于2个译码块之间有一定的时钟间隔的情况, 此时时序更宽松所以译码迭代次数能进一步增加, 与图 5相比, 可进一步改进系统的纠错性能。

|
| 图 6 提出的译码器迭代处理工作时序图 |
通过布局布线, 本文设计的码率兼容LDPC译码器的最大工作时钟频率为250 MHz, 由于同时处理10路连续帧, 且是一个输出连续的实时译码器, 所以提出的码率兼容译码器的最大吞吐量为250 MHz×10=2.5 Gbit/s。
表 6给出了提出的DVB-S2标准5种码率兼容LDPC译码器占用的资源, 同时还给出了文献[3-9]实现的高速译码器结果。其中不同的文献采用不同的术语来描述译码算法, 但都是软判决和积译码算法及其衍生算法。表 6保留原文献算法记法。
| 文献 | 码率 | 算法 | 迭代次数 | 量化比特/bits | 处理器 | 时钟频率/MHz | 吞吐量/bps | 存储器 | 面积 |
| [3] | 9/10 | C-NMS | - | 6 | - | - | 2.25G | - | - |
| [4] | - | F-SPA | 25 | - | 90 nm COMS |
300 | 520M | 8.4Mb | 12.4mm2 |
| [5] | 2/3 | R-NMS | 20 | 5 | Virtex 5 xq5vlx110 |
200 | 90M | 182个18kb | LUT:11005 |
| [6] | - | F-NMS | 30 | - | Virtex 7 xc7vlx485t |
293 | 1G | 232个36kb | LUT:92301 FF: 63637 |
| [7] | 9/10 | R-NMS | 35 | 8/6 | Stratix Ⅴ 5sgxea7n2f45c2 |
250 | 1.4G | 3Mb | ALUs:63694 FF:75372 |
| [8] | 2/3 | R-MS | - | - | Stratix Ⅲ EP3SL340 |
200 | 120M | 1.96Mb | ALU:73880 FF:10855 |
| [9] | 3/5 | R-NMS | 15 | 5 | 65 nm COMS |
400 | 720M | 2.2Mb | 5.89mm2 |
| 本文 | 5种 | F-NMS | 20 | 5 | Virtex 7 xc7vlx485t |
250 | 2.5G | 132个36kb | LUT:131205 FF:206097 |
本文提出的译码器优势在于:兼容多种码率, 可在连续输入数据情况下不丢失数据且具有逐帧切换LDPC码的自适应功能, 每帧可变的码率切换形式可以使得DVB-S2标准中逐帧可切换的传输帧结构形式获得更优异的自`适应传输性能。现有文献中并没有考虑这个设计问题。而对于多码率的实现现阶段大部分采用bit程序刷新的方法来实现, 这些方法不能实现在连续输入数据情况下逐帧切换不丢帧的功能。文献中给出的是某固定码率下的资源占用情况及其吞吐量。为了有效比较对应指标, 本文的译码器在单个码率情况下的资源占用量简单折算为5种码率兼容情况下的五分之一, 实际减去自适应控制部分的额外资源消耗后单码率的资源占用量将更低。经折算后本文中单个译码器在2.5 Gbit/s情况下的资源占用量为, 36 kb BRAM存储器27个(或18 kb BRAM 54个)、LUT为26 241个和FF寄存器41 219个。
文献[3]采用HSS译码策略和简单的校验节点更新算法, 采用节省存储资源的架构实现了dc(行重)路并行, 码率为9/10时, 吞吐量为2.25 Gbit/s。由于文献[3]中没有给出其他指标, 只能比对吞吐量情况, 与文献[3]相比, 本文的吞吐量更高。
文献[4]采用桶形移位寄存器来避免存储器访问冲突, 90 nm的ASIC实现结果显示, 时钟频率为300 MHz时, 可实现520 Mbit/s的吞吐量, 占用的存储器资源为8.4 Mb。而本文2.5 Gbit/s吞吐量的译码器占用52.8个18 kb的BRAM为0.95 Mb。由于ASIC的面积与FPGA的资源暂时没有有效的换算比对方法[13], 本文暂不做比较。但与文献[4]相比本文译码器的吞吐量资源和存储器资源利用效率更高。
文献[5]设计了一个同时具有VNU和CNU功能的模块B/CFM, 能使VNU和CNU充分共享资源, 实现的译码器最大吞吐量为1 020 Mbit/s。本文的译码结构采用图 6的CNU和VNU交替对两帧不同数据进行译码的方法来防止处理模块的空闲的处理方法。文献[5]的设计在1.02 Gbit/s吞吐量时, 使用的硬件资源为11 005个LUT和182个18 kb的BRAM存储资源。由于本文提出的译码器吞吐量约为文献[5]的2.5倍, LUT资源的使用量也大约为文献[5]译码器的2.5倍, 但在BRAM存储资源的利用效率上, 本文译码器具有明显优势, 在2.5 Gbps吞吐量下本文译码器仅占用54个18 kb的BRAM存储资源, 较文献本[5]的182个18 kb BRAM有明显优势。
文献[6]也是采用桶形移位寄存器来避免存储器访问冲突, ISE综合结果显示, 当时钟频率为297.3 MHz, 迭代30次时, 吞吐量为1 Gbit/s, 占用的硬件资源为LUT 92 301个、FF 63 637个、36 kb BRAM存储器232个。本文译码器的吞吐量为2.5 G, 为文献[4]译码器吞吐量的2.5倍, 但从资源的使用情况上看, 本文的译码器实现的资源占用量要小于文献[6]译码器的2倍, 其实现效率更高, 这主要是由于文献[6]译码器的桶形移位寄存器部分占用了大量的硬件资源, 而本文译码器并没有类似结构。
文献[8]采用通过降低并行度来大量减少双对角的更新行数, 会造成较大的误帧率损失。当吞吐量为120 Mbit/s, FF为10 855, 存储器资源1.96 Mb, 而本文2.5 Gbit/s单个译码器占用52.8个18 kb的BRAM为0.95 Mb, FF为41 219。与文献[8]相比, 本文译码器可以实现更高的吞吐量, 且资源利用效率更高。
文献[7]在文献[8]的基础上提出了一种优化的控制方法来抵消译码性能损失。当吞吐量为1.4 Gbit/s、ALUs为63 694、FF为75 372、存储器资源3 Mb, 而本文2.5 Gbit/s单个译码器占用LUT为26 241、FF为41 219、52.8个18 kb的BRAM为0.95 Mb。与文献[7]相比, 本文译码器的吞吐量资源、逻辑资源和存储器资源均有优势。
文献[9]采用FPGA实现了一个译码器, 当并行45路, 时钟频率为300 MHz时, 吞吐量为200 Mbit/s, 当并行120路, 时钟频率为400 MHz时, 吞吐量为720 Mbit/s。这些方法并行路数较大, 至少为45和360最大公约数, 这将导致ASIC芯片面积较大。从表 6中可以看到, 720 Mbit/s时存储器资源为2.2 Mb, 而本文2.5 Gbit/s译码器占用52.8个18 kb的BRAM为0.95 Mb。由于ASIC的面积与FPGA的资源暂时没有有效的换算比对方法[13], 本文暂不做比较。但与文献[9]相比本文译码器的吞吐量资源和存储器资源利用效率更高。
通过上面的对比分析, 可以看到本文设计的码率兼容译码器在纠错性能、吞吐量资源、逻辑资源和存储器资源与现有设计相比均具有优势, 这主要是由于本文在设计译码器之前采用了矩阵变换的方法, 该方法既不占用额外的硬件资源也不带来译码性能的损失。而且经过变化后的矩阵在硬件实现上具有较大的优势, 对于变换后矩阵的左边准循环子矩阵可以采用现阶段成熟的QC-LDPC译码器架构设计技术来实现高速自适应码率兼容的架构, 而右边行变换下三角双对角结构子矩阵设计时只需要兼容现有成熟的准循环硬件实现方案即可, 这样就保证了现阶段LDPC译码器研究成果能在设计的译码器上进行充分的应用。
由于借鉴了QC-LDPC译码器架构设计优势, 本文提出的译码器架构非常容易实现码率兼容性, 消耗的硬件资源更少, 而且如果想进一步提高LDPC译码器的吞吐量, 这种设计仅需要提高块内的并行路数。另外也可以灵活地调节LDPC译码器占用的硬件资源, 满足不同硬件平台不同吞吐量的传输需求。
5 结论为了有效地实现多码率码长兼容的DVB-S2译码器, 本文将DVB-S2标准中的矩阵进行初等变换后得到了QC和TST子矩阵, QC子矩阵采用现阶段具有丰富研究成果的QC-LDPC译码器架构进行实现, 而仅需重点解决TST子矩阵部分与QC-LDPC兼容性设计问题。提出的译码器能适应DVB-S2标准所有码率和分组长度, 且这种实现方法并行度可以灵活调节, 以实现不同吞吐量的译码器, 可满足不同系统的需求, 具有较强的实用性。而且在高吞吐量自适应上具有明显的优势, 能应用于地球探测卫星的最大传输速率高达几个千兆比特每秒的情况。
| [1] | CCSDS. CCSDS Space Link Protocols Over ETSI DVB-S2 Standard[S]. CCSDS 131.3-b-1, 2013 https://public.ccsds.org/Pubs/131x3b1.pdf |
| [2] | ETSI. Second Generation Framing Structure, Channel Coding and Modulation Systems for Broadcasting, Interactive Services, News Gathering and Other Broadband Satellite Applications(DVB-S2)[S]. EN 302307 V1.2.1, 2009 |
| [3] | KIM T H, PARK T D, PARK G Y, et al. High Throughput LDPC Decoder Architecture for DVB-S2[C]//Proceedings of Fifth International Conference Ubiquitous and Future Networks, Da Nang, 2013: 430-434 |
| [4] | KIM S W, PARK C S, HWANG S Y. Design of a High-Throughput LDPC Decoder for DVB-S2 Using Local Memory Banks[J]. IEEE Trans on Consumer Electronics, 2009, 55(3): 1045-1050. DOI:10.1109/TCE.2009.5277954 |
| [5] | KIM S W, PARK C S, HWANG S Y. A Novel Partially Parallel Architecture for High-throughput LDPC Decoder for DVB-S2[J]. IEEE Trans on Consumer Electronics, 2010, 56(2): 820-825. DOI:10.1109/TCE.2010.5506007 |
| [6] |
安宁.兼容DVB-S2X标准的全速率高速LDPC译码器设计与FPGA实现[D].西安: 西安电子科技大学, 2016 AN Ning. Design and FPGA Implementation of Full-Rate High-Speed LDPC Decoder Compatible with DVB-S2X Standard[D], Xi'an, Xidian University, 2016(in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10701-1016214534.htm |
| [7] | MARCHAND C, BOUTILLON E. LDPC Decoder Architecture for DVB-S2 and DVB-S2X Standards[C]//Proceedings of IEEE Workshop on Signal Processing Systems, 2015: 14-16 |
| [8] | SU J, LU Z. Reduced Complexity Implementation of Quasi-Cyclic LDPC Decoders by Parity-Check Matrix Reordering[C]//Proceedings of IEEE 10th International Conference, ASIC (ASICON), Shenzhen, 2013: 1-4 |
| [9] | MARCHAND C, CONDE-CANENCIA L, BOUTILLON E. High-Speed Conflict-Free Layered LDPC Decoder for the DVB-S2, -T2 and-C2 Standards[C]//Proceedings of IEEE Workshop on Signal Processing Systems, 2013: 118-123 |
| [10] |
兰亚柱, 杨海钢, 林郁. 动态自适应低密度奇偶校验码译码器的FPGA实现[J]. 电子与信息学报, 2015, 37(8): 1937-1943.
LAN Yazhu, YANG Haigang, LIN Yu. Design of Dynamic Adaptive LDPC Decoder Based on FPGA[J]. Journal of Electronics & Information Technology, 2015, 37(8): 1937-1943. (in Chinese) |
| [11] | XIE T J, LI B, YANG M, et al. Memory Compact High-Speed QC-LDPC Decoder[C]//IEEE International Conference on Signal Processing, Communications and Computing, 2017: 22-25 |
| [12] | HAILES P, XU L, ROBERT G M, et al. A Survey of FPGA-Based LDPC Decoders[J]. IEEE Communications Surveys & Tutorials, 2016, 18(2): 1098-1122. |
| [13] | TSATSARAGKOS I, PALIOURAS V. A Reconfigurable LDPC Decoder Optimized for 802.11n/ac Applications[J]. IEEE Trans on Very Large Scale Integration (VLSI) Systems, 2018, 26(1): 182-195. DOI:10.1109/TVLSI.2017.2752086 |
2. China Academy of Space Technology(Xi'an), Xi'an 710100, China
