

2. 西北工业大学 自动化学院, 陕西 西安 710072
云计算的优势之一, 在于弹性计算和资源的高效整合利用[1]。通过虚拟化技术, 可将原有的物理主机的资源划分为不同的虚拟机资源, 以实现资源的按需分配和使用[2-5]。但是, 在实际的云环境下, 由于传统的资源分配机制不能完全适应云资源动态变化和不确定等特性, 容易引发负载不均衡, 从而对云环境下的服务性能和资源利用效率产生影响。为了进一步改善云资源的使用性能, 需要对云资源进行动态优化。解决资源分配的这类问题, 通常用启发式算法。然而传统启发式算法自身的局限性, 不能解决大型、复杂、动态的资源分配问题[6]。传统的启发式算法由于自身的局限性, 不能圆满解决大型、复杂、动态的资源分配问题[7]。本文旨在结合云计算资源分配的实际情况, 且充分考虑到云计算环境下的任务处理时间、网络带宽和网络时延等约束, 设计了一种基于深度学习和强化学习的智能资源调度算法。可以验证该算法能够有效解决分布式环境下, 动态资源分配问题。
1 深度强化学习资源调度的总体框架如图 1所示, 基于深度强化学习算法设计的核心思想是, 将深度学习和强化学习2种启发式算法在恰当的时机融合, 汲取各自的优点, 克服固有的缺陷, 取长补短, 在时间效率和求解精度上共同达到最优。其具体的工作原理如下:

|
| 图 1 基于深度强化学习资源调度的总体框架 |
1) 首先在分布式环境下, 对各分支节点采集流量数据作为训练样本;
2) 根据样本的规模及实时性要求, 确定深度学习网络的隐藏层数量及其节点数量, 并初始化网络参数;
3) 用深度学习方法对数据流量进行拟合, 并对拟合结果偏差进行分析;
4) 如果拟合偏差较大, 说明现在的训练属于欠拟合状态, 需要扩大训练次数, 并转向第3)步;
5) 再次采集各个节点数据作为测试样本, 并运用现有的神经网络对数据进行预测和方差分析;
6) 如果拟合方差较大, 说明现在样本处于过拟合状态, 需要对深度学习网络进行正则化处理, 处理完成后转向第2)步;
7) 根据训练好的深度学习网络, 设置相应的超参数;
8) 由于在分布式环境下, 数据流量峰值较高, 且流量具有动态性的特点。因此, 运用蒙特卡罗模拟, 来对抽样数据最大流方向进行预测, 并给出预测结果;
9) 根据蒙特卡罗给出的预测结果, 设置强化学习的回报函数;
10)运用强化学习策略, 对网络资源进行分配, 并给出分配结果。
2 基于深度学习的流量预测模型 2.1 多隐层前馈神经网络沿用单隐层前馈神经网络的分析, 当隐藏的层数超过2层时, 称为深度前馈神经网络, 其网络结构如图 2所示。

|
| 图 2 多隐层前馈神经网络 |
设输入x∈Rm, 输出y∈Rs, 则隐层的输出可记为:

|
(1) |
对应的超参数为:
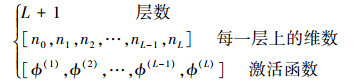
|
(2) |
于是, 得到输入、输出关系为:
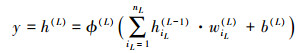
|
(3) |
对于训练集:
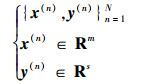
|
(4) |
所得到的优化目标函数为:
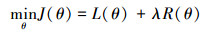
|
(5) |
式中,yn=f(xn, θ), 且:

|
(6) |
欲对优化目标函数公式(5)求解, 需要确定目标函数的凸性, 如果可行域是凸集, 定义在该凸集上的凸函数为凸优化, 由此可以得到全局最优解。但是, 在实际问题中, 深度前馈神经网络的优化目标函数并非凸函数, 于是参数的求解依赖于初始参数的选择, 需要进行反复迭代。通常, 可用梯度下降算法来更新参数, 具体描述如下。
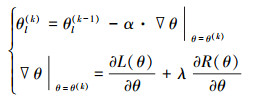
|
(7) |
式中, α为学习速率, 对于每一层上的参数, 按下式进行更新:
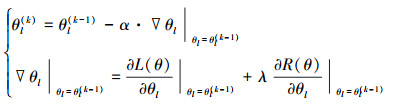
|
(8) |
式中, θl(k)为第l层第k次迭代的更新。对于核心梯度下降量的求解, 可引入误差传播项, 根据链式法则, 将其展开为:

|
(9) |
式中, 传播误差项标记为:
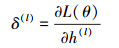
|
(10) |
本文采用蒙特卡罗模拟方法来降低数据的复杂度。蒙特卡罗模拟法是工程应用中的一种数学计算方法, 主要用来解决降低数据复杂度问题。其基本原理是根据随机变量样本空间的概率分布, 通过模拟实验的手段, 计算样本某一事件发生的概率, 或者样本某一事件属性的平均值, 并以此作为所求事件发生的概率估计或随机变量期望的估计, 能以较低的计算代价, 枚举出概率值更高、更符合数据观察结论的结果。其计算公式为:
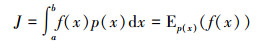
|
(11) |
根据上面的公式进行求解, 在f(x)中选取一系列独立同分布的样本x1, x2, …, xn, 就可以得到
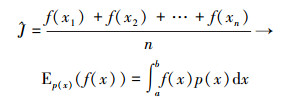
|
(12) |
同样也可以得出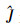
对J做相应的变化, 即

|
(13) |
我们同样在q(x)中抽取x1, x2, …, xn。令w(x)=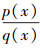
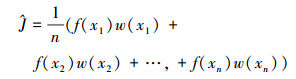
|
(14) |
产生带权值的样本。
在前面的分析中, 我们对J做了相应的改进, 目的是为了计算随机变量的数学期望。若注意到Eq(x)[w(x)]=1, 则可将公式(13)、(14)分别改写为

|
(15) |
和
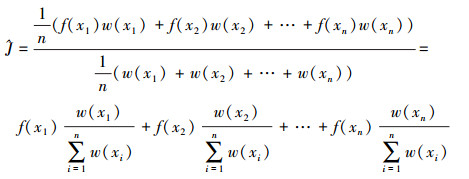
|
(16) |
实际上, 就相当于对样本进行重新赋予权值。即利用非均匀的离散分布来近似概率密度函数f(x), 再进行抽样及均匀化。归一化, 从而可视为离散的均匀分布。于是, 便产生了带权重的样本, 其方差可以通过选择适当的q(x)来降低。
下面我们通过蒙特卡罗方法进行随机模拟来实现递归的贝叶斯估计。为此利用一系列通过抽样得到的随机样本, 对它们所表示的后验概率密度函数进行加权,得到状态的估计值。这里, 采用序贯重要性抽样来完成递归模式, 以取得递归后的状态估计值。
根据Bayesian原理, 现设系统模型为p(xk|xk-1)和p(x0k|xk), 它们分别代表系统中2个方程的模型。同时, 再做以下假设:
1) 系统状态符合隐马尔可夫过程;
2) 系统所得量测值之间是相互独立的;
3) 系统状态的先验概率密度函数可设为p(x0)。
根据蒙特卡罗方法, 这里的后验概率密度函数的表达式为:

|
(17) |
对于非线性系统来说, 最理想的情况是样本都能从p(x0:k|Z1k)得到的。然而, 要在贝叶斯估计中发现解析解和系统状态难度很大。不过由于每个样本点所对应的权值并不需要具体的数值, 只需在一定的比例下, 求得其值的大小即可, 这就使得后验概率密度函数可以得到相应的近似。
引入相对容易进行抽样的概率密度函数q(x0:k|Z1k)。通过重要性抽样可得到一系列样本x0:ki, 它们应满足:
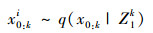
|
(18) |
为了能够实现递归估计, 现在假设重要性概率密度函数的分解式为:
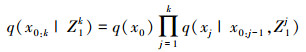
|
(19) |
实际上就是通过q(x0)和q(xj|x0:j-1, Z1j)来构造q(x0:k|Z1k)。
再假设给定的系统符合隐马尔科夫过程, 又可得出:
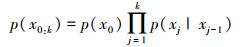
|
(20) |
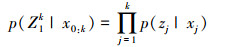
|
(21) |
于是要获得的样本集合x0:ki ~q(x0:k|Z1k), 便可通过将新测量值zk加入x0:k-1i~q(x0:k-1|Z1k-1), 得到p(x0:k|Z1k)。
我们先从第k-1层所得的概率密度函数中提取一系列的随机样本{xk-1k|k=1, 2, …, N}, 当样本很多时, 概率密度函数可以表示为:
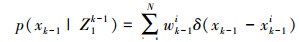
|
(22) |
由贝叶斯估计可知, 第k时刻状态对应的概率密度函数可以表示为:
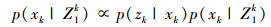
|
(23) |
即重要性密度函数可以满足:
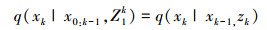
|
(24) |
并有xkk ~q(xk|xk-1i, zk), 则可得到校正的后验概率密度函数为:
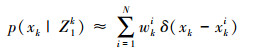
|
(25) |
式中
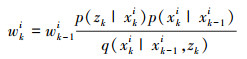
|
(26) |
这里的权值都要经过归一化处理。在实施序贯重要性抽样时, 应注意权值的变化, 所产生的随机样本也应根据权值的变化进行选取, 以使抽出的各个样本的权重值不会随着递归的过程, 逐渐趋近于同一个样本。
4 基于Q学习的强化学习模型强化学习是受生物能够有效适应环境的启发, 以试错的机制与环境进行交互, 通过最大化积累奖赏的方式, 来学习最优策略。其目的是解决计算机从感知到决策的控制问题, 从而实现通用人工智能。

|
| 图 3 强化学习的框架 |
将Q学习和深度学习相结合, 可以解决高维数据的输入问题。对于基于分布式的网络资源分配问题, 可将其拆分为一系列的步骤(最后一步为输出结果)。其中, 每一步都包括竞技双方根据当前自己的观测所做的行动或行为, 同时期望该行为带来累积奖赏(即该行为及以前行为的奖赏之和), 即对方为自己最终获胜增添筹码。如果用数学分式来量化这一过程需要给出必要的假设:资源分配问题中每一步所对应的观测, 可执行的行动或行为是有限的; 不可能仅靠当前这一步的观察来执行某一行为, 需要充分结合该布置前的观测行为来采取行动。
为了描述方便, 引入下列记号:
1) 符号xt∈Rm×n为游戏进行到第t(t=1, 2, …, T)步时, 所对应的观测。
2) 符号at∈Λ为观测xt下所执行的动作, 其中Λ为游戏规则下合理行动集合。
3) 符号rt为观测xt下执行动作at后, 所获取的奖赏(或惩罚), 另外:

|
(27) |
式中,γ∈(0, 1)为折扣因子, Rt为第t步到终止时刻T, 所获取的累积奖赏和。
4) 符号Q(s, a)为状态动作值函数, 其中t时刻的状态s为:

|
(28) |
下面, 给出Q学习的主要思路, 即根据如下的迭代公式实现状态动作值函数的优化学习:
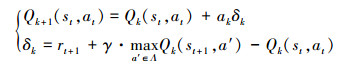
|
(29) |
式中,ak为学习速率, 另外st、at分别为第t步所对应的状态和行到, δk为时间差分, γ为折扣因子, a′为Λ中使得第k次迭代下的状态动作值函数在st+1下可执行的动作。已经证明, 上式满足以下2个条件时:
1)
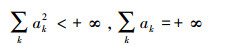
|
(30) |
2) 所有的状态动作都能被无限次地遍历时, 则有

|
(31) |
即随着迭代次数趋于无穷时得最优控制策略下的状态动作值函数, 类似中西方任务, 总结出一套从播种到结果其中每一个状态下的最优执行策略。
最后, 由上面的描述, 可知在某一状况下选择最可执行动作的策略, 辨识最大化如下的期望值:
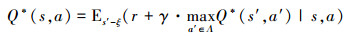
|
(32) |
式中,ξ为环境, 所有的状态都包含在内; s′分别为状态s执行动作a之后的状态, a′为符合游戏规则下针对状态s′所有可能执行的动作。
注意(32)式采用的是期望来分析状态动作值函数, 而在实际应用中, 常使用函数逼近的策略来实现状态动作值函数的估计, 即
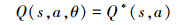
|
(33) |
在强化学习中, 常用的逼近方式有线性的和非线性之分, 待优化的权值参数为θ。假设对于每一次迭代k, Q网络通过最小化如下的目标函数来实现参数更新:
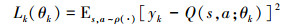
|
(34) |
这里的ρ(·)为行为分布, 即ρ(s, a)为状态s和行为a的概率分布, 另外yk为第k次迭代所对应的目标, 且有:
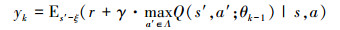
|
(35) |
依据上式有:
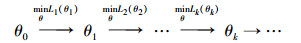
|
即在参数θ0已知的前提下, 可以得到目标函数y1; 再通过优化目标函数式更新参数, 得到θ1; 如此类推, 最终可实现参数的收敛, 即:

|
(36) |
式中, 对于(36)式参数的更新求解采用梯度下降法, 其中偏导数为:
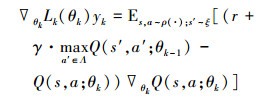
|
(37) |
注意这里参数θk-1是固定的。
5 实验仿真预算法性能比较在云计算仿真平台Cloud Sim进行模拟, 云计算资源节点数为5, 资源节点的资源分配情况见表 1所示, 为了使本文的算法更具有说服力, 在相同的实验条件下, 采用DVFS(dynamic voltage and frequency scaling)算法进行实验对比。
1) 算法收敛速度比较
为验证本文算法的性能, 采用Cloud Sim自有的无迁移策略以及DVFS策略、MVDS算法进行模拟实验, 实验采用上一章介绍的云计算仿真软件Cloud Sim进行仿真。
本文的算法和DVFS算法求解的最优解变化曲线见图 4。从图 4可知, 相对于DVFS算法, 本文的算法的收敛性能具有明显的优势, 在100 ms左右, 本文的算法便找到了云计算系统资源调度最优方案, 远远快于DVFS算法的400 ms, 对比结果表明, 深度学习算法保证了分析数据的快速、准确性、能够防止局部最优解的出现, 为资源调度提供更好的决策。

|
| 图 4 本文算法与DVFS算法收敛速度对比 |
2) 不同节点上的负载量分析
从实验室中各分布式节点计算能力来分析, 计算性能的排名情况是2、1、3、5、4。如果资源调度合
理的话, 就应该按照计算能力大小来对各个节点进行任务分配。从图 5中可知, 不同节点的负载是不同的, 本文的算法对各个节点进行任务分配是按照节点的能力大小进行分配的, 但是DVFS算法将处理能力强的节点分配到较少的任务, 而处理能力差的节点任务繁重, 各节点上的负载极不均衡。

|
| 图 5 不同节点数据量分配情况表 |
本文在结合深度学习和强化学习的基础上, 设计了基于深度强化学习的资源调度算法的框架。该框架首先利用大量从网络节点获取的先验数据训练深度学习网络; 然后采用基于蒙特卡罗模拟方法, 对数据进行降维分析, 接着利用强化学习来分配网络资源, 也可以认为是智能决策程序的自我对弈学习; 最后通过大量的自我对弈, 实现基于深度强化学习的价值网络学习。最后通过仿真实验, 验证了该算法的有效性。
| [1] | Deng Zhenghong, Ma Chunmiao, Mao Xudong. Historical Payoff Promotes Cooperation in the Prisoner's Dilemma Game[J]. Chaos, Solitons & Fractals, 2017, 104: 1-5. |
| [2] | Gao Bo, Deng Zhenghong, Zhao Dawei. Competing Spreading Processes and Immunization in Multiplex Networks[J]. Chaos Solitons & Fractals, 2016, 93: 175-181. |
| [3] | Xiao Luxin. Research on the Optimization of Enrollment Data Resources Based on Cloud Computing Platform[J]. International Information and Engineering Technology Association, 2015, 2(2): 9-12. |
| [4] |
尹宝才, 王文通, 王立春. 深度学习研究综述[J]. 北京工业大学学报, 2015(1): 48-59.
Yin Baocai, Wang Wentong, Wang Lichun. Review of Deep Learning[J]. Journal of Beijing University of Technology, 2015(1): 48-59. (in Chinese) |
| [5] |
刘建伟, 刘媛, 罗雄麟. 深度学习研究进展[J]. 计算机应用研究, 2014(7): 1921-1930.
Liu Jianwei, Liu Yuan, Luo Xionglin. Research and Development on Deep Learning[J]. Application Research of Cernputers, 2014(7): 1921-1930. (in Chinese) |
| [6] |
张浩, 吴秀娟, 王静. 深度学习的目标与评价体系构建[J]. 中国电化教育, 2014(7): 51-55.
Zhang Hao, Wu Xiujuan, Wang Jing. Study on the Evaluation Theoretical Structure Building of Deep Learning[J]. China Educational Technology, 2014(7): 51-55. (in Chinese) |
| [7] |
邓正宏, 薛静. 基于数量化Ⅱ类的数据分析库的设计与实现[J]. 计算机工程与应用, 2003, 39(28): 42-45.
Deng Zhengheng, Xue Jing. The Design and Implementation of QuantityⅡ Class Based Analysis Library System[J]. Computer Engineering and Applications, 2003, 39(28): 42-45. DOI:10.3321/j.issn:1002-8331.2003.28.013 (in Chinese) |
2. School of Automation, Northwestern Polytechnical University, Xi'an 710072, China
