

在传统的协同过滤推荐[1]方法中用户在非公共项目(没有被2个用户共同评测过的项目)上的评分通常都被剔除掉了,因为在传统的基于相关性的相似性度量方法中用户在非公共项目上的评分信息无法直接用于计算用户之间的相似性[2]。针对这个问题,最近几年,研究人员已经提出了许多利用用户在被忽略的项目上的评分信息的方法去提高推荐系统的质量。Sen等人[3]引入标签作为辅助信息,根据用户的历史记录获取用户对标签的偏好,然后根据用户对标签的兴趣预测用户对项目的偏好。Fatin等人[4]在Sen等人的工作之上,提出了一个根据用户在具体上下文环境下对标签的偏好进行推荐的新方法。Qi等人[5]使用推测出来的用户对标签的评分计算用户之间的相似性,并且设计了一个通过合并用户所有项目的标签上的评分计算用户在对项目评分的推荐方法,该方法利用了用户对非公共项目的评分记录,借助于标签数据提高了推荐算法的精度,实验结果表明,用户对非公共项目的评分对于提高推荐精度是很有价值的。
本文提出了一个借助用户对非公共评分项目的评分信息改进协同过滤推荐算法的方法。与已有的使用标签信息的推荐方法不同,本文的方法利用项目的内部子信息(例如电影的题材、论文的关键字、文章的主题等)推测用户的偏好。内部子信息刻画了项目的核心子特征,能够用于描述并且区分不同的项目。相对于单纯使用项目名称或者编号比对用户的评分记录,使用内部子信息能够利用项目之间的相似性,将用户对非公共项目的评分记录转换成用户对可比较的内部子信息的评分,从而能够利用用户对非公共项目的评分改进协同过滤推进方法。相较于标签信息,项目的内部子信息属于项目的内在特征,不需要用户的参与,并且由于用户生成的标签信息并不是由领域专家维护的,标签信息的准确性和完备性无法得到保证,而作为对项目进行描述和刻画的客观信息,内部子信息能够保证对项目刻画的准确性和完备性。因此,本文选择项目的内部子信息作为分析用户兴趣偏好进而提高推荐质量的有效信息来源。本文设计了从用户对所有项目的评分记录中抽取用户对项目内部子信息的偏好算法,然后计算了用户在内部子信息上兴趣偏好的相似性。不同于直接使用用户在标签上的相似性预测用户对项目标签的评分[5],本文设计了考虑用户之间共同评价过的项目在2个用户评价过的所有项目中所占比例的动态调节权重将传统的协同过滤推荐方法中基于用户对公共项目评分的相似性和基于用户对项目的内部子信息的相似性进行合并,并将合并后的相似性引入到基于邻居用户的协同过滤推荐算法中,用于预测用户对未评价项目的评分。
1 传统的协同过滤推荐方法传统的协同过滤方法中用户相似性的度量方法不能在稀疏的评分数据集上获得较好的推荐质量,因为它们只使用了用户对共同评价过的项目上的历史记录。但是在稀疏的数据集上,共同评价过的项目是稀少的,因此不足以产生精确的推荐。本文提出了能够使用用户在非公共项目上的评分记录的相似性度量方法,并且随后将该相似度方法应用到预测用户对未评价项目的评分。
为了利用隐含在用户对非公共项目的评价记录中的相关性提高推荐系统的精度, 用户在非公共项目上的偏好需要被引入到用户的相似性度量中并且被应用到基于用户的协同过滤方法中。之所以在传统的基于用户的协同过滤方法中, 只有用户在公共项目上的评分可以用于计算用户的相似性, 是因为用户之间的评分只能被成对地使用。给定用户u和用户v, 他们的相似性可以用皮尔逊相关性系数[6]计算如下:

|
(1) |
式中, Iu, v表示被用户u和用户v共同评价过的项目集合,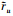
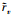
对于绝大多数用户,他们只共同评价过较小比例的项目,这就造成了通过公式(1)得到的用户间的相似度不精确。尽管用户对非公共项目的评分记录在传统的相似性度量方法中被忽略了,但是并不意味着这些信息对分析用户的偏好是毫无意义的,更重要的是,这些信息在提高基于用户协同过滤推荐方法的准确度中的有效性已经在许多文献[7-9]中得到了验证,然而用户对非公共项目的评分记录无法在公式(1)中得到应用。
2 基于项目内部子信息的推荐算法为了将用户对非公共项目的评分记录用于提高推荐算法的性能,本文将用户评分的项目分解成更小的子部分,从而使不同的项目可以进行比较。为了将项目进行分解,本文并没有选取用户生成的标签信息表示项目的子部分,因为为了得到用户生成的标签需要用户额外的标签输入,同时用户生成的标签也无法保证对项目描述的准确性和完备性,因此本文使用项目的内部子信息作为不同项目的可比较语义。这些内部子信息需要满足可枚举性和完备性,可枚举性是指项目的内部子信息具有有限的个数,而完备性表示使用内部子信息可以覆盖所有的项目,同时内部子信息应该能够准确地描述项目,并且能够用于容易地区分不同的项目。
2.1 用户对内部子信息的评分假定用户评价过的项目的所有内部子信息的集合为IDI={idi1, idi2, …, idin},项目i可以表示成内部子信息的集合IDIi⊆IDI。借助于项目的内部子信息,本文可以根据用户所有的评分记录,计算出用户对每个内部子信息的评分。用户u对某个内部子信息idi的偏好可以通过如下公式计算:
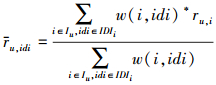
|
(2) |
式中,Iu表示用户u评价过的项目的集合,ru, i表示用户u对项目i的评分,w(i, idi)是一个表示项目i是否具有内部子信息idi的函数,它被定义为如下的公式:

|
(3) |
通过公式(2)和公式(3),可以根据用户对所有项目的评分计算出用户对项目内部子信息的评分。
2.2 基于用户对内部子信息的偏好的相似度通过改造公式(1),本文可以通过以下的公式获取基于用户对项目的内部子信息的偏好的相似度:
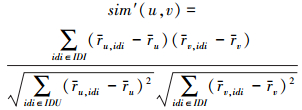
|
(4) |
式中,ru, idi表示根据公式(2)估算的用户u对内部子信息idi的评分,ru和rv分别表示用户u和用户v对所有项目内部子信息的平均评分。
基于用户对项目的内部子信息的偏好的相似度sim′(u, v)使用了用户对所有评价过的项目的评分记录,不只包含了对公共项目的评分,而且包含了对非公共项目的评分。
2.3 基于动态调节权重的相似度混合方法基于用户对项目的内部子信息的偏好的相似度由于使用了用户的全部评分信息,在分析用户相似性的时候不可避免引入了更多的噪音数据,此外,项目内部子信息的划分和选取也会对用户相似性的计算产生影响,如果单纯依靠基于用户对项目内部子信息偏好的相似性进行推荐,预测用户评分的精度将受影响,这也将在本文的实验部分进行验证。传统的协同过滤推荐系统中基于用户对公共项目的评分信息的相似性对保证评分预测精度上的作用是不能取代的,因此就有必要将基于公共项目评分的相似性与基于项目内部子信息的相似性进行混合,提高用户相似度分析的准确度。在混合多种相似性的时候,加权线性混合是最常用的方法。传统的方法中,每种相似性的权重需要根据数据集的特征进行优化调整,这不仅增加了线性混合方法使用的难度,同时也限制了相似度计算的精度。本文根据用户间公共项目占2个用户所有评价项目的比例,设计了一个动态调节权重来混合2种相似性,该动态调节权重根据如下公式获得:
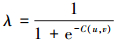
|
(5) |
式中,C(u, v)表示用户u和用户v的评价项目上的杰卡德相似性系数[10-11],由以下公式获得:
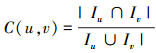
|
(6) |
式中,Iu表示用户u评价过的项目集合,Iv表示用户v评价过的项目集合。根据公式(6)可以知道,C(u, v)∈[0, 1], 那么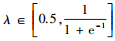
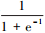
借助于动态调节权重,本文可以使用以下公式(7)将基于用户对公共项目的偏好相似性与基于用户对项目内部子信息的偏好相似性进行加权混合:
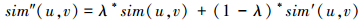
|
(7) |
根据公式(5),本文可以发现随着用户间公共项目比例的增加,动态调节权重也随着增大,那么公式(7)中基于用户公共项目上评分的相似性在混合相似性中所占的比重也将增大。
2.4 使用非公共项目评分的推荐算法根据混合相似性,用户对项目的评分可以通过以下公式进行预测:
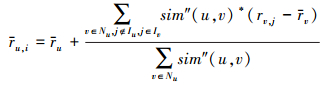
|
(8) |
式中,Nu表示用户u的邻居用户,邻居用户的选取采用top-N策略[12-13],选取跟用户u相似度最高并且评价过项目j的N个用户作为邻居用户,
为了评估本文所提方法的性能,本文在数据集movielens latest small[15-16]上进行了实验,将本文方法与基于公共评价项目的传统协同过滤推荐方法进行了比较。此外为了验证本文所提动态调节权重的效果,本文分别使用动态调节权重和静态权重将基于公共评价项目的相似度和基于全部评价项目的相似度进行混合,对比了它们的推荐精度。
3.1 数据集描述movieLens latest small数据集[16]是由GroupLens Research从MovieLens网站采集的数据集。鉴于GroupLens Research在推荐系统领域开创性的工作,该数据集已经被广泛应用于各种推荐方法的评测中。该数据集包含用户对自己所看过电影的评分,评分分值是1~5的评分。除了评分文件,MovieLens数据集还包含每部电影的题材信息,本文将电影的题材作为电影的内部子信息,因为电影的题材满足了可枚举性和完备性的要求。本文实验使用MovieLens数据集中的评分数据和电影的题材数据用于基于项目内部子信息的推荐算法。
3.2 评价指标在本文的实验中,推荐系统的精度使用平均绝对误差MAE和均方根误差RMSE测量,这2个评价指标是在评测推荐算法评分精度的2个常用的指标[17-18],2个指标越小,表示误差越小,推荐精度也越高。平均绝对误差MAE可以用以下公式计算:
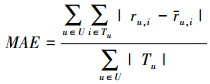
|
(9) |
式中,U表示测试集中所有的用户,Tu表示在测试集中被用户u评价过的所有项目,ru, i表示测试集中用户u对项目i的真实评分, ru, i表示用户u对项目i的估测评分。
均方根误差RMSE可以用以下公式计算:
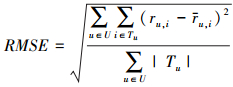
|
(10) |
在实验中,我们将本文提出的使用项目内部子信息的推荐方法称作NCCF,传统的基于用户的协同过滤推荐方法称作CCF。我们将数据集按照80%和20%划分,分别作为训练集和测试集,同时为了避免过拟合问题,我们执行了5-fold交叉验证实验。我们的实验是在LibRec[19]的基础上实现的,LibRec是一个受GPL协议授权的推荐系统的Java库,支持多种推荐算法的快速实现和评测。本文中我们使用top-N策略选取邻居用户,为了研究实验方法在不同规模的邻居用户下的表现,我们将邻居用户的数量设置为从10~100之间增量为10的数字。
3.4 实验结果和讨论1) NCCF和CCF的推荐精度对比
NCCF和CCF 2种推荐方法的绝对平均误差MAE如图 1所示,从图中我们可以看出本文所提方法比传统的基于用户的协同过滤推荐方法在预测评分上具有较小的平均绝对误差,从图 2所示的NCCF和CCF 2种推荐方法在RMSE上的对比可以看出,本文所提方法NCCF比传统的基于用户公共评分的协同过滤推荐方法在预测评分上具有较小的均方根误差。因此,我们可以说,本文所提出的推荐方法方法NCCF比传统的基于用户的协同过滤推荐方法具有较好的推荐精度。通过将项目分解为内部子信息,使得不同项目间可以进行比较,从而能够利用上用户对项目的所有的评分记录,相比只能使用用户对公共评价项目的评分的传统推荐方法,本文方法确实能够显著提高推荐算法的效果。

|
| 图 1 NCCF和CCF在不同数量的邻居用户下MAE的对比 |

|
| 图 2 NCCF和CCF在不同数量的邻居用户下RMSE的对比 |
2) NCCF中的混合权重分析
为了研究本文方法中所提出的动态调节权重对提高推荐精度的效果,本文设计了使用不同静态权重混合2种相似度提供推荐的对比实验,我们将λ分别设置为0.0、0.2、0.5、0.8、1.0和动态调节权重,分别表示传统的基于用户对公共项目评分相似度在混合相似度中的权重。
实验结果的MAE如图 3所示,从图中可以看出,在λ=0.0时,推荐效果的平均绝对误差最大,意味着推荐精度最低,因此单纯使用本文引入的基于用户所有评分记录得到的用户对项目内部子信息的偏好用于计算用户之间的相似度进行推荐无法提供较好的推荐精度。在λ=1.0的平均绝对误差尽管好于λ=0.0时的平均绝对误差,并且还好于λ=0.2时邻居用户数量超过10的平均绝对误差,但是明显比λ分别取0.5、0.8和动态调节权重时的平均绝对误差大。这就表明本文提出的基于全部评分项目的推荐方法比传统的基于用户之间公共评分项目的推荐方法具有较高的推荐精度,此外,在本文的推荐方法中,传统的基于公共项目评分的相似度的权重应该大于本文提出的基于全部项目评分的相似度,合适的混合权重比分别单独使用2种相似度都具有较好的推荐效果。

|
| 图 3 混合相似度中CCF权重对MAE的影响 |
从图 3我们还可以看到,取动态调节权重时NCCF能够取得最好的推荐精度,随着邻居用户数量增加,动态调节权重能够一直保证最小的平均绝对误差。虽然在邻居数量不超过20时,取0.5时的平均绝对误差与取动态调节权重时的平均绝对误差非常接近,但是随着使用更多的邻居用户,取0.5时的平均绝对误差与取动态调节权重时的平均绝对误差之间的差距逐渐增大并最终趋于平稳。此外,通过对比不同的静态混合权重下NCCF方法的平均绝对误差,我们可以发现,混合权重对NCCF推荐方法的平均绝对误差具有非常重要的影响。如果选取静态混合权重,为了获得最佳的推荐精度,设计人员应该根据推荐系统应用领域的特征对混合权重进行优化选择。本文所提出的动态调节权重能够动态适应用户评分项目之间公共项目的比例,因此能够保证较好的推荐精度,此外选取动态调节权重还能够节约用于测试不同静态混合权重的推荐精度的时间和资源,具有更好的实用性。
图 4展示了不同权重下混合相似度的均方根误差,从图中可以看出,用RMSE表示的推荐精度跟用MAE表示的推荐精度在不同相似度混合权重下具有相似的表现。虽然混合权重取0.8时在使用较多邻居用户(大于20)的时候具有最好的推荐精度,但是动态调节权重也获得了次佳的推荐精度,甚至在邻居用户较少时仍然能保证最佳的推荐精度,因此在实际应用中,可以直接选取动态调节权重作为2种相似度的混合权重,不仅能节约时间和资源,还能保证较好的推荐精度。从MAE和RMSE 2个度量指标可以看出,基于公共项目的相似度需要在NCCF方法中的混合相似度中占据较重的分量,但是为了取得较好的推荐精度,也需要考虑本文所提出的基于全部评分记录的相似度,单独使用任何一种相似度都无法获得最佳的推荐精度,而2种相似度的混合权重需要根据不同数据集和应用场景的特点进行优化,而为了节约优化混合权重的成本,直接使用本文设计的动态调节权重也能取得比较好的推荐精度。

|
| 图 4 混合相似度中CCF权重对RMSE的影响 |
本文提出了一种使用推荐系统中所有用户的全部评分记录提高推荐算法精度的方法。本文的主要贡献在于:①提出了用于描述和区别不同项目的内部子信息的概念。②设计了基于全部用户评分计算用户对项目内部子信息的评分的方法。③基于用户对项目内部子信息的评分计算了用户偏好的相似度,并提出了一个动态调节权重将该相似度与传统的协同过滤推荐系统中用户的相似度进行混合。④通过详实的实验验证了本文所提理论的有效性,并且探讨了相似度混合权重对推荐精度的影响。
在下一步的工作中,我们将研究从用户对项目的评论中抽取项目的内部子信息的方法,同时将用户生成内容(标签和评论等)的语义相似度和情感信息用于生成项目的内部子信息。
| [1] |
于洪, 李俊华. 一种解决新项目冷启动问题的推荐算法[J]. 软件学报, 2015, 26(6): 1395-1408.
Yu Hong, Li Junhua. Algorithm to Solve the Cold-Start Problem in New Item Recommendations[J]. Journal of Software, 2015, 26(6): 1395-1408. (in Chinese) |
| [2] | Patra B K, Launonen R, Ollikainen V, et al. A New Similarity Measure Using Bhattacharyya Coefficient for Collaborative Filtering in Sparse Data[J]. Knowledge-Based Systems, 2015, 82(2): 163-177. |
| [3] | Sen S, Vig J, Riedl J. Tagommenders:Connecting Users to Items through Tags[C]//18th International World Wide Web Conference, 2009:671-680 |
| [4] | Gedikli F, Jannach D. Improving Recommendation Accuracy Based on Item-Specific Tag Preferences[J]. ACM Trans on Intelligent Systems & Technology, 2013, 4(1): 43-55. |
| [5] | Qi Q, Chen Z, Liu J, et al. Using Inferred Tag Ratings to Improve User-Based Collaborative Filtering[C]//Proceedings of the 27th Annual ACM Symposium on Applied Computing, 2012:2008-2013 |
| [6] | He X S, Zhou M Y, Zhuo Z, et al. Predicting Online Ratings Based on the Opinion Spreading Process[J]. Physica A Statistical Mechanics & Its Applications, 2015, 436: 658-664. |
| [7] | Gan M. COUSIN:A Network-Based Regression Model for Personalized Recommendations[J]. Decision Support Systems, 2015, 82: 58-68. |
| [8] | Gao H, Tang J, Hu X, et al. Content-Aware Point of Interest Recommendation on Location-Based Social Networks[C]//Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015:1721-1727 |
| [9] | Liu H, Hu Z, Mian A, et al. A New User Similarity Model to Improve the Accuracy of Collaborative Filtering[J]. Knowledge-Based Systems, 2014, 56(3): 156-166. |
| [10] | Jabeen F, Khusro S, Majid A, et al. Semantics Discovery in Social Tagging Systems:A Review[J]. Multimedia Tools & Applications, 2014, 75(1): 1-33. |
| [11] | Chen L, Chen G, Wang F. Recommender Systems Based on User Reviews:the State of the Art[J]. User Modeling and User-Adapted Interaction, 2015, 25(2): 99-154. DOI:10.1007/s11257-015-9155-5 |
| [12] | Ning X, Karypis G. SLIM:Sparse Linear Methods for Top-N Recommender Systems[C]//201111th IEEE International Conference on Data Mining, 2011:497-506 |
| [13] | Albadvi A, Shahbazi M. A Hybrid Recommendation Technique Based on Product Category Attributes[J]. Expert Systems with Applications, 2009, 36(9): 11480-11488. DOI:10.1016/j.eswa.2009.03.046 |
| [14] | Liang H, Xu Y, Li Y, et al. Connecting Users and Items with Weighted Tags for Personalized Item Recommendations[C]//Proceedings of the ACM Conference on Hypertext and Hypermedia, 2010:51-60 |
| [15] | Goldberg K, Roeder T, Gupta D, et al. Eigentaste:A Constant Time Collaborative Filtering Algorithm[J]. Information Retrieval, 2001, 4(2): 133-151. DOI:10.1023/A:1011419012209 |
| [16] | Harper F M, Konstan J A. The MovieLens Datasets:History and Context[J]. ACM Trans on Interactive Intelligent Systems, 2016, 5(4): 1-19. DOI:10.1145/2866565 |
| [17] | Feng H, Tian J, Wang H J, et al. Personalized Recommendations Based on Time-Weighted Overlapping Community Detection[J]. Information & Management, 2015, 52(7): 789-800. |
| [18] |
孟祥武, 刘树栋, 张玉洁, 等. 社会化推荐系统研究[J]. 软件学报, 2015, 26(6): 1356-1372.
Meng Xiangwu, Liu Shudong, Zhang Yujie, et al. Research on Social Recommender Systems[J]. Journal of Software, 2015, 26(6): 1356-1372. (in Chinese) |
| [19] | Sun Z, Guo G, Zhang J. Exploiting implicit item relationships for recommender systems[C]//International Conference on User Modeling, Adaptation, and Personalization, 2015:397-402 |
