

近年来, 随着无线通信技术、移动定位技术的快速发展及智能手机的迅速普及, 移动社交网络(mobile social networks, MSN)已经成为人们生活中不可缺少的一部分。在临近的区域内, 根据用户特征的相似性发现潜在的朋友, 并建立适当的社交关系, 是移动社交网络所提供的最为基础的服务。其中, 用户特征相似度计算, 是最为核心的步骤。在一种典型场景中, 用户特征表现为用户主观描述的一组属性, 比如年龄、性别、爱好等。用户之间以属性的相似度为依据, 决定是否建立社交联系。在另外一种场景中, 用户特征表现为用户的社交关系, 比如人脉、好友圈等。用户以彼此间的社交关系相似度为依据建立联系。和现实社交相似,“物以群分, 人以类聚”, 相比第一种场景, 社交关系相似度能够为用户的社交决策提供更强的信任依据。
考虑以下场景, 用户A和用户B试图计算彼此之间的社交相似度。最简单易行的方式是通过比对好友列表判断共同朋友的数量。显然, 共同朋友的数量越多, 意味A和B的社交相似度越大, A和B能够成为朋友的可能性也越大。但在此过程中, A和B至少有一方会暴露自己的朋友列表, 这就会导致个人隐私的泄露。为了保护用户的个人隐私, 最直接的方式是通过部署在互联网上的第3方服务器进行相似度检测。但这种方式的缺点在于:首先, 虽然避免了用户之间彼此暴露个人社交关系, 但用户的社交关系完全暴露给服务器。在服务器不能完全可信的情况下, 就会引发更加严重的隐私泄露风险。其次, 从可用性的角度而言, 在这种集中式的解决方法中, 服务器可能成为影响服务质量的瓶颈。例如在一些移动社交场景中, 用户可能无法稳定地访问互联网。因此, 不需要第3方服务器的参与, 可保护隐私的分布式特征相似度检测方法更加适用于移动社交网络。目前, 此类方法大部分基于安全交集运算(private set intersection, PSI)[1-2]。通过PSI, 在特征相似度检测过程中, 用户A和用户B无法获得除了相同特征以外的其他任何信息, 从而能有效地保护用户隐私。
然而, 对于社交相似度检测, 现有的可保护隐私的分布式特征相似度检测方法无法解决社交关系的认证问题, 即用户之间无法确认彼此的朋友列表是否可信。和现实生活中的情况类似,用户有可能伪造朋友关系。比如A将C写入自己的朋友列表, 但其实C并不认识A。缺乏对社交关系的认证, 社交相似度检测的结果就无法为用户社交提供可信的依据。为了解决该问题, Nagy等人提出了名为CF(common friends)的方案[3]。在该方案中, 除了利用布隆过滤器保护用户隐私外, 共享随机数被用作朋友关系的证据, 从而实现可信检测。这个方案最大的不足在于, 做为证据的随机数并没有将证据的拥有者和证据本身关联在一起。对于用户C来说, 其所有的朋友共享相同的关系证据, 证据泄露的风险较大。同样是实现可保护隐私的可信社交关系检测, Cristofaro等人提出了CDS(contact discovery scheme)方案[4]。在该方案中, 朋友关系的证据由朋友间相互颁发的证书体现, 在进行社交关系相似度检测时, 检测双方通过验证证书实现关系认证。这种方法建立了关系证据和证据所有者之间的一一对应关系, 但检测过程较为复杂, 通信和时间开销过大。
为了克服上述不足, 本文设计了一种利用基于身份加密的可保护隐私的可信社交关系相似度检测协议。与common friends相比, 我们的方案中所设计的社交关系证据和证据所有者具有强绑定关系, 在保护用户隐私的同时, 能够提供更安全可信的朋友关系认证。与CDS相比, 我们方案的检测过程更为简单, 通信和时间开销较小, 具有更高的实用价值。
1 系统模型及问题定义 1.1 系统模型及假设假设处于临近区域内的用户A和用户B, 试图在没有第3方服务器的帮助下, 进行基于共同好友的社交关系相似度检测。A和B可通过本地WiFi或蓝牙进行无线通信。用户A和用户B分别具有好友列表LA={(IDi, proofA-IDi)|i=1, 2, …, n}, LB={(IDj, proofB-IDj)|j=1, 2, …, m}。其中, IDi(IDj)表示A(B)的好友ID。proofA-IDi(proofB-IDj)表示A(B)与IDi(IDj)好友关系的证据。此外, 假设在系统中, 每个人的ID都是唯一的。并且好友关系证据proof通过可信方式预先获得。
1.2 问题定义在本文中, 为了确保在社交关系相似度检测过程中, 用户隐私的安全以及检测的可信度, 协议的设计应该满足如下安全需求:
1) 令LA(ID)={ID1, ID2, …, IDn}, LB(ID)={ID1, ID2, …, IDm}。在检测结束后, 用户A和用户B除了知道LA(ID)∩LB(ID)以外, 不能获得有关对方朋友列表的其他任何信息。
2) 用户A和用户B无法伪造并不存在的朋友关系。任意IDk∈LA(ID)∩LB(ID)都是可信的, 即A和B可以通过分别验证proofB-IDk和proofA-IDk确认IDk为对方真实好友。
3) 在检测过程中, 攻击者无法利用所窃听到的A与B之间传送的信息推导出LA和LB。
1.3 攻击者模式在本文中, 假定攻击者为诚实并好奇的(honest-but-curious, HBC)。即所有的参与者都严格遵循协议的步骤, 但不排除有的参与者试图利用从协议执行过程中所获得的信息推导更多有关对方朋友关系的信息。同时, 还假定合法的参与者不会泄露和共享秘密信息。
2 协议设计 2.1 基本原理本方法的核心在于生成能够与用户ID具有强绑定关联的朋友关系证据, 然后通过对此证据的挑战-响应验证来进行共同朋友检测。为此, 我们采用了基于身份的加密方案(identity-based encryption, IBE)[5-7]。其基本原理如下:假如C是A的好友, C会根据A的ID为A生成其身份私钥KIDA。相同, 若C也是B的好友, B也会得到C根据其ID生成的身份私钥KIDB。这里, 身份私钥就是一种强绑定关联证据。当A和B进行朋友关系检测时, A利用C的公开信息, 以IDB为公钥来加密一段挑战信息, 并发送给B, 若B能正确解密, 则A能确认C是B的好友。反之, B利用C的公开信息, 以及IDA为公钥加密一段挑战信息, 并发送给A, 若A能正确解密, 则能证明C也是A的好友。在此过程中, A和B并没有直接交换好友信息, 且能通过挑战-响应方式验证对方是否具有C颁布的证据, 因而可以保护隐私, 并确保检测结果是可信的。
2.2 IBE结构本文所采用的IBE方案由Naccache[7]提出。与其他IBE方案相比, 该方案更加实用和高效, 并已验证在标准模型下的语义安全性。该方案的结构描述如下:设G为素数阶为p的群, g为G的生成元。同时设e:G×G→GI为从群G到GI的双线性映射。身份由n维向量υ=(υ1, υ2, …, υn)表示, 其中, υi为一个l-bit的整数。n和l与p没有关联。该IBE方案由以下几个算法组成。
1) setup:该算法由身份私钥生生方(private key generator, PKG)执行, 用以生成公开参数和主密钥。身份私钥生成者随机选取秘密α∈Zp。设g1=gα并从G中随机选取g2。选取随机数u′∈G。生成随机n维向量U=(u1, …, ui), 其中, u1为G中的随机数。令身份私钥生成者的公开参数PU={g, g1, g2, u′, U}, 主密钥MK=g2α。
2) keygen(υ, PU, MK):该算法由身份私钥生成方执行, 用以根据输入的身份生成对应的身份私钥。参数υ=(υ1, υ2, …, υn)为输入的身份。选取随机数r∈Zp。令dυ为身份υ所对应的私钥, 则:dυ=(g2α(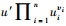
3) encryption(m, υ, PU):该算法由消息发送方执行。根据接收方的身份υ和接收方身份私钥生成者的公共参数PU, 对消息m进行加密。具体而言, 消息发送方选择随机数t∈Zp, 生成的密文为c=(e(g1, g2)t·m, gt, (
4) decryption(dυ, c):该算法由消息的接收方执行。消息接收方利用自己的身份私钥dυ对密文c进行解密。令dυ=(d1, d2), c=(c1, c2)。则解密过程为
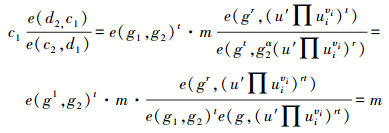
|
朋友列表是社交关系相似度检测的基础数据结构。在本文所提出的检测协议中, 每一个参与方的朋友列表中, 不仅有其朋友的ID, 还提供了与朋友ID对应的朋友关系证据proof。以用户A为例, 设A的好友列表为LA={(IDi, proofA-IDi)|i=1, 2, …, n}。其中, IDi为A的第i位朋友, proofA-IDi为A与IDi是朋友的证据。假设C是A的朋友, 其ID为IDC。proofA-IDC由如下方式生成:C充当PKG的角色, 其公共参数为PUIDC, 主密钥为MKIDC。则C依据A的ID(IDA)调用keygen(IDA, PUIDC, MKIDC)生成da-IDC, 并将PUIDC和dA-IDC传回给A。因此, proofA-IDC=(PUIDC, dA-IDC)。假定以上证据生成和交付过程在安全可信的计算和通信环境中进行, 则最终A的好友列表的可表示为:LA={(IDi, (PUIDi, dA-IDi))|i=1, 2, …, n}。
2.4 提示向量本方案设计了一种称之为提示向量的数据结构。在之后描述的共同朋友检测协议中, 提示向量可以极大地提高检测的效率。以用户A为例子, 若A的朋友列表中有n位朋友, 则选定一个预先设定的哈希函数H, 并选取一个大于n的素数γ。A的提示向量RA由LA中的所有朋友ID的哈希值对γ取余的结果组成。即
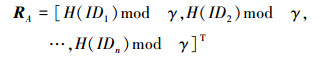
|
假定hi=H(IDi), hj=H(IDj), ri=himodγ, rj=hjmodγ。显然, 如果ri≠rj, 则hi≠hj, 最终可推导出IDi≠IDj。利用此性质, 在检测协议的初始步骤中, A可以将RA和γ发送给B。利用相同的哈希函数H和γ, B对LB中的朋友ID进行同样的哈希求余计算。通过将其计算结果与RA进行比对, 可以快速判断是否有相同的朋友, 并求出可能是相同朋友的ID集合。
2.5 关系检测如图 1所示, 本文的社交关系相似度检测协议主要由3个相继的阶段构成, 分别为快速检测阶段, 挑战响应阶段和验证阶段。设A为协议的发起者, 首先, 在快速检测阶段, 用户B利用A的提示向量, 快速判断是否与A有可能相同的朋友。接着, 在挑战响应阶段, A和B分别向对方发送基于对方ID的加密挑战信息。最后, 在验证阶段, A和B通过对加密挑战信息的应答进行验证, 最终获得可信的共同朋友集合。具体过程描述如下。

|
| 图 1 协议过程 |
阶段1 快速检测
步骤1 用户A依据自己的朋友列表LA中的好友ID, 生成提示向量RA=[r1, r2, …, rn], 将IDA、RA和γ发送给用户B。同时, 用户A生成字典DA={(r1, I1), (r2, I2), …, (rn′, 其中ri∈RA, n′, Ii={IDk|IDk∈LA(ID), H(IDk)mod γ=ri}, 且令DA(ri)=Ii。
步骤2 收到IDA、RA和γ后, 利用相同的哈希函数H和γ, B对LB中的朋友ID进行同样的哈希求余计算, 得到提示向量RB。随后, B计算集合PC=RA∩RB。若PC=Ø, 则说明无共同朋友, 协议结束。否则, B将IDB和PC发送给A。同时, B保留字典DB={(r1, P1), (r2, P2), …, (rm′, 其中ri∈RB, m′≤m, Pi={IDk|IDk∈LB, H(IDk)modγ=ri}, 且令DB(ri)=Pi。
阶段2 挑战响应
步骤3 A收到IDB和PC后, 对于每一个rj∈PC, A查询DA找到It=DA(rj)。紧接着, 对于每一个IDk∈It, A根据其对应的公参PUIDk和IDB加密一个即时生成的挑战随机数nA, 生成密文emIDB-IDk=Encryption(nA, IDB, PUIDk)。最终, A生成挑战密文集合CESB={(r1, EMB1), (r2, EMB2), …, (rw, EMBw)}。
其中, ri∈PC, w=|PC|, EMBi={emIDB-IDk|IDk∈DA(ri)}。A将CESB发送给B。
步骤4 B收到CESB后, 对于每一个(ri, EMBi)∈CESB, B首先查询DB, 对于每一个emIDB-IDk∈EMBi, B用全部IDj∈DB(ri)所对应的身份私钥dB-IDj对其进行尝试解密, 得到结果n′a=Decryption(dB-IDj, emIDB-IDk)。随后, B根据IDA及PUIDj对n′A进行重新加密, 得到ackIDA-IDj=Encryption(n′A, IDA, PUIDj)。同时, B也根据IDA及PUIDj加密一个即时生成的随机数nB, 并生成密文emIDA-IDj=Encryption(nB, IDA, PUIDj)。最终, B生成响应密文集合ACKA={(r1, KA1), (r2, KA2), …, (rw, KAw)}。
其中, ri∈PC, KAi={(ackIDA-IDj, emIDA-IDj)|IDj∈DB(ri)}。B将ACKA发送回A。
阶段3 双向验证
步骤5 A收到ACKA。对于每一个(ri, KAi)∈ACKA, A首先查询DA, 对于每一个(ackIDA-IDj, emIDA-IDj)∈KAi, A尝试用所有IDk∈DA(ri)所对应的身份私钥dA-IDk, 对ackIDA-IDj进行解密。若解密结果和挑战随机数nA相等, 则将IDk添加进集合CFA中, 并继续用dA-IDk对emIDA-IDj进行解密, 得到结果n′B=Decryption(dA-IDk, emIDA-IDk)。若所有的尝试解密结果都不正确, 则说明A和B无共同朋友, 协议结束。随后, A根据IDB及PUIDk对n′B进行重新加密, 生成ackIDB-IDk=Encryption(n′B, IDB, PUIDk)。最终, A生成和B的共同朋友列表CFA以及对B的响应密文集合ACKB={(r1, KB1), (r2, KB2), …, (rw, KBw)}。其中, ri∈PC, KBi={ackIDB-IDk|IDk∈DA(ri)且IDk∈CFA}。A将ACKB回传给B。
步骤6 B收到ACKB后, 对于每一个(ri, KBi)∈ACKB, B首先查询DB, 对于每一个ackIDB-IDk∈KBi, B尝试用IDj∈DB(ri)所对应的身份私钥dB-IDj对其进行尝试解密, 若解密结果与挑战随机数nB相等, 则将IDj添加至集合CFB中, 最终形成的CFB便是B所获得的与A的共同朋友列表, 并且CFB=CFA。
在以上步骤完成后, A和B都获知了彼此的共同好友。此时, 加入一定的基于阈值的判断, A和B可建立信任关系, 并进一步相互发布朋友关系证据。
3 安全性分析首先, 本文所采用的IBE方案, 已经在文献[7]中被证明在标准模型下是完全安全的。在此基础上, 本节将从隐私保护和可信认证2个角度进行分析, 说明本文所提出的共同朋友检测协议能满足1.2节所列出的安全性需求。
3.1 隐私保护在快速检测阶段, 用户B获得用户A的提示向量RA。显然, 通过RA, B只能模糊推断出可能与A相同的好友ID集合, 且无法推断出A的好友列表信息。在挑战响应阶段, B收到A的挑战密文集合CESB={(r1, EMB1), (r2, EMB2), …, (rw, EMBw)}。由于本文采用的IBE方案是完全安全的, B无法从任意emIDB-IDk∈EMBi中推出挑战随机数nA, 也无法推断出其对应的PUIDk, 因此, B无法得知尝试解密是否正确。这意味着在此阶段, B无法得知是否与A具有相同的好友。在双向验证阶段, A首先获得B的响应密文集合ACKA={(r1, KA1), (r2, KA2), …, (rw,, KAw)}。通过对ackIDA-IDj进行尝试解密, 并将解密结果和nA进行对比, A可以判断解密的正确性, 进而可以获知与B的共同好友列表CF。但对于无法正确解密的ackIDA-IDj, 基于IBE方案的完全安全特性, A无法推测出其对应的PUIDj, 这意味着A无法获知除了LA(ID)∩LB(ID)外有关LB的其他信息。根据以上分析可知, 在检测结束后, 用户A和用户B除了知道LA(ID)∩LB(ID)以外, 不能获得有关对方朋友列表的其他任何信息。此外, 与以上分析同理, 对于一个窃听者而言, 其无法利用所窃听到的A与B之间传送的信息推导出LA和LB。因此, 本文所提出的协议能够很好的保护用户的隐私。
3.2 可信认证假设IDC是A的真实朋友, 是B的伪造朋友。则根据系统模型, A拥有proofA-IDC=(PUIDC, dA-IDC), 而B没有。因此, 对于A所生成的挑战密文emIDB-IDC, B无法正确解密, 因此, 在双向验证阶段, A可排除IDC。假设IDC是B的真实朋友, 是A的伪造朋友, 则B拥有proofB-IDC=(PUIDC, dB-IDC), 而A没有。假定PUIDC没有泄露, 则A无法生成针对IDC的挑战密文, 因此无发通过验证。假定A知道PUIDC, 由于A没有对应的身份私钥dA-IDC, 从而无法解密B的挑战密文emIDA-IDC, 因此无发通过B的验证。根据以上分析可知, 用户A和用户B无法伪造并不存在的朋友关系, 任意IDk∈LA(ID)∩LB(ID)都是可信的。
4 性能评估为了评估本方案的执行效率, 我们利用基于Python的CHARM[8]库构建了协议原型。对协议的仿真测试在一台笔记本上执行, 其配置为Intel CORE i5 2.30GHz处理器, 2GBRAM, Ubuntu 14.04 OS及Python 3.4.3。
4.1 IBE效率IBE是整个协议的核心, 协议的计算效率依赖于IBE的加解密效率。为此, 我们首先测试了所采用的IBE算法在不用用户ID长度下的密钥生成, 加密及解密的时间开销。测试结果如图 2所示。其中, 用户ID长度是指算法keygen(υ, PU, MK)及Encryption(m, υ, PU)中参数υ=(υ1, υ2…, υn)中υi的个数。其中, 每一个υi均为32 bit的整数。实验结果表明, 密钥生成及加密时间随着用户ID长度的增加线性增加, 而解密时间为常数。在之后的实验中, 我们设置len(υ)=5, 其对应的密钥生成时间开销约为0.013 s, 加密时间开销约为0.014 s, 解密时间开销约为0.002 s。

|
| 图 2 IBE效率 |
本方案中, 通过引入提示向量, 可以提高检测效率。如2.4节所述, 对于某位用户A, 其提示向量RA由LA中的所有朋友ID的哈希值对γ取余的结果组成。为了衡量γ值的大小与协议执行效率之间的关系, 我们进行了如下实验。首先, 我们选取了1组不同大小的γ值。之后, 对于每一个γ的取值, 我们生成20对随机朋友列表(LA, LB)(LA和的LB长度均为100), 将其作为协议的输入进行运算并记录其解密次数。实验结果如图 3所示。可见, 较大的能够明显降低协议的解密次数, 因此能够提高协议的执行效率。

|
| 图 3 γ对协议执行效率的影响 |
为了评估协议的通信效率及计算效率, 我们测试了在不同参数下协议完整执行所需要传输的字节数及所花费的时间。首先, 我们固定A和B的朋友列表长度均为100, 测试了随着A和B的共同朋友不断增加的情况下, 数据传输量(见图 5a))和时间开销(见图 5c))的变化情况。之后, 我们测试了随着A和B的朋友列表长度不断增加的情况下, 数据传输量(见图 5b))和时间开销(见图 5d))的变化情况。实验结果表明, 本方案的数据传输量及时间开销随着双方共同好友数量的增加而线性增加, 随着双方朋友列表长度的增加成指数型增加。此外, 较大的γ值能够显著降低数据传输量和时间开销。

|
| 图 4 协议的通信效率及计算效率 |
为了进一步评估本方案的效率, 我们选取文献[3]和文献[4]中所提出的方法作为比较对象, 测试了给定相同的输入集合, 执行各协议所产生的通信量和计算时间。对于CF, 我们设置布隆过滤器的误判率为1%。对于本文提出的方法, 我们设置γ=3571。对于所有的方法, 我们设置密钥长度均为512bits。实验数据集为随机生成的100对朋友列表, 每一个朋友列表的长度均为100, 每一对朋友列表均包含10个共同好友。实验结果如表 1所示。其中, CF的效率最高, 这是由于其采用了非密码学方案来实现共同朋友检测。然而, 如前文所述, CF中关系证据和证据拥有者并不是一对一的关系, 因而具有较大的证据泄露风险。CDS使用证书作为朋友关系证据, 证书和证书所有者是强绑定的, 但用于验证证书的握手过程比较复杂, 因而具有最大的通信和时间开销。与这2种方法相比, 本文所提出的方法既建立了证据和证据所有者的强绑定关系(一对一), 也具有良好的的通信和时间开销。
5 结论本文针对移动社交网络场景下社交关系相似度检测问题, 提出了一种利用基于身份加密的可信共同朋友检测方法。该方法可使用户之间在不需要可信第3方的情况下, 实现可保护隐私并且可信的共同朋友检测。与现有的方法相比, 我们的方法在朋友关系证据, 证据颁发者和证据拥有者之间建立了关联, 因而可以提供更加可信的关系认证。同时, 对协议原型的仿真测试结果表明, 该方法在保证安全性的同时, 也具备较好的计算效率, 具有较强的实用性。
| [1] | Li M, Cao N, Yu S, et al. Findu: Privacy-Preserving Personal Profile Matching in Mobile Social Networks[C]//2011 IEEE International Conference on Computer Commucations, 2011: 2435-2443 |
| [2] | Von Arb M, Bader M, Kuhn M, et al. Veneta: Serverless Friend-of-Friend Detection in Mobile Social Networking[C]//2008 IEEE International Conference on Wireless and Mobile Computing, Networking and Communications, 2008: 184-189 |
| [3] | Nagy M, De Cristofaro E, Dmitrienko A, et al. Do I Know You?: Efficient and Privacy-Preserving Common Friend-Finder Protocols and Applications[C]//Proceedings of the 29th Annual Computer Security Applications Conference, 2013: 159-168 |
| [4] | De Cristofaro E, Manulis M, Poettering B. Private Discovery of Common Social Contacts[C]//International Conference on Applied Cryptography and Network Security, 2011: 147-165 |
| [5] | Boneh D, Franklin M. Identity-Based Encryption from the Weil Pairing[C]//Annual International Cryptology Conference, 2001: 213-229 |
| [6] | Waters B. Efficient Identity-Based Encryption without Random Oracles[C]//Annual International Conference on the Theory and Applications of Cryptographic Techniques, 2005: 114-127 |
| [7] | Naccache D. Secure and Practical Identity-Based Encryption[J]. IETU Information Secutity, 2007, 1(2): 59-64. DOI:10.1049/iet-ifs:20055097 |
| [8] | Akinyele J A, Garman C, Miers I, et al. Charm: A Framework for Rapidly Prototyping Cryptosystems[J]. Journal of Cryptographic Engineering, 2013, 3(2): 111-128. DOI:10.1007/s13389-013-0057-3 |
