

像分类是根据其所具有的属性对图像内容进行描述,并将图像划分到特定的语义类别中[1]。图像分类技术作为信息处理研究领域的1个重要课题,在图像检索、智能系统及医学研究领域具有广泛的应用。由于图像包含大量的信息,加之图像数据的规模海量,加剧了图像分类的难度。
多示例学习算法是由Dietterich等人针对药物活性分析提出的[2]。在多示例学习框架下,1幅图像可以视为由多个示例组成的包。包具有标记,而示例没有标记。当1个包中至少包含1个正示例时,包为正包。反之,包为负包。多示例学习在解决研究对象具有多义性问题时,有很大的优势[3]。传统的图像分类方法将整幅图像看作1个整体,通过对整幅图像进行标记获得训练样本集,并训练相应的分类器实现未知标记图像的分类。然而,大多图像都具有多义性,其既存在与标记有关的目标区域,也包含与标记无关的其他区域。比如,1幅图像中往往同时存在‘天空’、‘沙滩’和‘人’等多个目标区域。因此,如果仅使用单一的语义对图像进行分类,会因有限的语义造成分类性能的下降。鉴于整幅图像与其内部区域的关系符合多示例包的定义,因此,利用多示例学习算法同时包含图像中的多个语义信息,增强信息表达的能力,提高分类算法的性能。
基于多示例学习框架的分类算法大致可分为2类:基于示例级空间的算法和基于包级空间的算法[4-5]。前者首先训练1个使正负示例充分分离的示例级分类器,然后构造最终的包级分类器,其代表方法主要有diverse density(DD)[6]、EM-DD方法[7]及mi-SVM和MI-SVM[8]方法;该类方法只考虑训练样本的示例级信息,忽略样本包的全局信息。而后者在训练过程中将每个样本包视为1个整体,通过获取样本的包级特征训练相应的包级分类器。由于此类方法在包级空间求解多示例问题,故而不需要训练示例级分类器,代表方法主要有DD-SVM[9]及MILES[10]方法。
由于基于包级空间的多示例学习算法通常利用训练集中的所有示例构造包级特征,而多示例训练集是由包含多个示例的包组成。因此,其包级特征的维数远大于训练包的数目,而这种特征数目与训练包的差异将导致过拟合现象[4],影响算法的分类效果。因此,特征选择对于基于包级空间多示例分类算法的分类性能至关重要。
稀疏表示作为1种有效的特征提取方法,广泛应用于图像分类、图像检索及目标检测等领域。稀疏编码的目的,旨在通过求解训练样本获得能代表低层特征的基向量,并线性组合基向量实现对输入图像特征的表示[11-13]。因此,在稀疏编码过程中,需要解决训练样本基向量的求解问题及输入向量线性组合表示的问题。
针对基于包级空间多示例学习算法存在的问题,本文融合多示例学习算法和稀疏编码理论,提出1种基于包级空间多示例稀疏表示的图像分类方法。该方法利用稀疏编码的特征表示能力,有效地计算样本包的特征向量。首先,根据同类样本聚为一簇的特性,应用聚类算法构造每类图像的视觉词汇,并利用负包中所有示例都为负的特性,对视觉词汇进行约束,消除冗余信息。然后,计算训练样本与视觉词汇的相似度,获得每类训练样本的包特征向量。接着,利用稀疏编码理论对训练包的包特征向量进行稀疏编码,获得每类图像的字典矩阵和稀疏编码包特征向量。最后,对待分类样本特征进行稀疏线性组合,预测待分类样本的类别标签。实验结果表明,本文方法能较好地解决多示例图像分类问题,具有较高的分类精度。本文所提出的分类方法的执行流程如图 1所示。

|
| 图 1 本文分类方法的流程图 |
在多示例学习算法中,每幅图像由多个示例组成的包表示。设训练数据集I为n个图像包所组成的集合, 即I={(Bi, yi)|1≤i≤n}, yi∈Y={1, 2, …, C}为包Bi的类别标签。包Bi={xi1, …, xini}为I中由ni个示例组成的第i个训练图像, 其中, xij ∈Rk为k维特征向量。因此, 训练集I中所有属于第c类的训练样本包可表示为Bc=[B1c, B2c, …, Bnc], c∈{1, 2, …, C}, n为第c类训练样本包的数目。由第c类训练样本包中全部示例组成的训练数据集可表示为X=[x1, x2, …, xm}∈Rk×m, 其中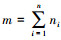
基于包级空间的多示例学习算法, 通过将训练样本集中的所有示例映射到特征空间, 获得相应的包级特征。由训练集中所有示例构成的特征空间, 其维数必然远大于训练包的个数, 这种数据不均衡的现象易导致过拟合现象[4]。对此, 传统的包级空间多示例学习方法[10, 14-16]通常采用阈值或特征排序的方法, 将包级特征进行划分获得特征子集。由满足条件的示例构成示例原型代表相应的目标。但是, 按照这种策略选择的特征子集往往忽略较小的目标区域且包含大量冗余的信息, 造成部分训练包信息的损失, 影响分类器的性能。因此, 本文同时考虑所有训练样本包的包级特征信息, 利用相似视觉区域的样本可聚为1类的特性, 对每类样本包进行聚类, 获得其对应的视觉词汇。并在聚类过程中, 利用负包中所有示例都为负的特性, 对视觉词汇进行约束, 以消除冗余信息。然后通过计算训练样本包中的示例与视觉词汇的相似度, 获得每类训练样本的包级特征向量, 使所构造的包空间特征向量包含所有包中的判别信息, 以提高算法的分类性能。
1.2.1 聚类中心的选取在包级空间多示例学习算法中, 图像Bi由若干区域组成, 设xij为第i幅图像的第j个图像区域。对于第c类训练样本包Bc=[(B1c, y1), (B2c, y2)…, (Bnc, yn)], 共n幅图像, yi=±1为图像的标注。yi=1, 表示该样本属于第c类, 否则, yi=-1, 表示该样本不属于第c类图像。将第c类训练集中所有yi=1的样本组成的集合记为S+={xk+ |k=1, 2, …, K}, 所有yi=-1的样本组成的集合记为S-={xk- |k=1, 2, …, q}, 其中, K、q为训练集中正负样本的个数。
首先随机选择k个聚类中心对S+中的示例进行K-means聚类, 获得相应的聚类中心。并计算训练样本xi与聚类中心的距离, 即
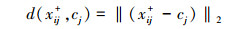
|
(1) |
式中, xij+为第j类的第i个待分类样本, cj为对应的聚类中心。
选取使(1) 式最小的样本xi, 更新相应的聚类中心
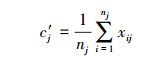
|
(2) |
式中, nj为属于第j类的样本个数。
循环上述过程, 直到类别中心不再发生变化或使(3) 式目标函数达到最小值, 即

|
(3) |
通过聚类, 获得第j类训练样本最终的聚类中心
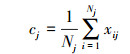
|
(4) |
式中, Nj为聚类后属于第j类的样本数目。
计算每个正包的聚类中心cj与负包示例xi的距离, d=‖(xi-cj)‖2, j=1, 2, …, k, i=1, 2, …, m。d越小, 表明该类图像与负样本xi的相似度越高。在此, 利用正负样本的距离对聚类中心进行约束, 达到消除冗余信息的目的, 即
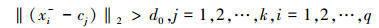
|
(5) |
式中, 阈值d0设为:d0=max‖(xij-cj)‖2, j=1, 2, …, k, i∈Nj。
1.2.2 包特征计算通过1.2.1聚类算法获得每类图像的视觉词汇, 即:V={v1, v2, …, vc}。图像Bi={xij|j=1, 2, …, ni}在视觉词汇V下的特征为

|
(6) |
式中, φ(Bi)为样本包Bi的包空间特征, xij为包Bi中的样本示例, ni为包Bi中样本的个数。通过(6) 式, 计算Bi中示例xij与视觉词汇的最小距离, 即样本与视觉词汇的相似程度。通过上述图像包空间的变换, 将图像转换为包空间中的1个点,从而利用包空间特征向量表示整幅图像。
因此,对于第c类训练样本包Bc=[B1c, B2c, …, Bnc],n为该类训练样本包的数目,根据公式(6) 计算该类训练样本包的包特征向量,构造相应的包空间特征集Tc=[s(vk, B1), s(vk, B2), …, s(vk, Bn)]。
1.3 稀疏编码经过1.2节包特征向量的计算,获得每类训练包的包空间特征集Tc=[s(vk, B1), s(vk, B2), …, s(vk, Bn)],c=1, 2, …, C。由K-means算法获得训练包的字典矩阵Dc=[d1, d2, …, dKc]∈Rk×Kc, Kc为字典的大小。相应的系数矩阵为Ac=[α1, α2, …, α2n]∈RKc×2n。对于任意示例x,稀疏编码旨在将x*表示为字典D的线性组合形式。因此,稀疏编码可表示为:
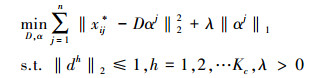
|
(7) |
式中, λ为规则项, ‖αj‖1为系数的l1范数。
稀疏编码的本质是通过寻找1组超完备基实现输入数据的表示。因此, (7) 式中优化问题的求解过程可表述为, 首先, 固定字典D, 求解稀疏系数α, 使(7) 式最小[17]。即
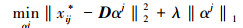
|
(8) |
然后, 固定系数矩阵α, 调整D, 使式(7) 最小。即
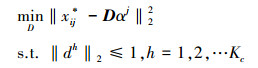
|
(9) |
按照(8) 式和(9) 式迭代计算, 获得第c类训练包的字典矩阵Dc。因此, 训练包Bc=[B1c, B2c, …, Bnc]中的任意示例xj的稀疏编码系数αj可按(8) 式计算得到。从而, 第c类训练包的稀疏编码包级特征可表示为
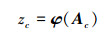
|
(10) |
式中, φ为合并函数。在此, 采用文献[12]的方法, 利用最大合并函数计算包级特征向量, 即
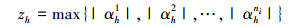
|
(11) |
式中, zh为zc中的第h个特征, αhni为第i个包Bi中第h行第n列的稀疏矩阵系数。
1.4 基于稀疏编码的分类器构造根据2.3节所述的方法, 获得每类训练样本包的稀疏编码包级特征向量zc。由全部训练数据所构成的稀疏编码包级特征可表示为z=[z1, z2, …, zC]。在此, 利用所构造的特征训练相应的SVM分类器[18]。即, 对于给定的训练样本{(zi, j, yi)}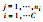
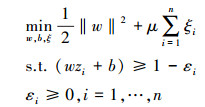
|
(12) |
式中, μ为惩罚因子, ξ为松弛变量。通过求解(12) 式的拉格朗日算子{βi, j}
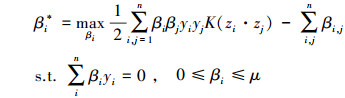
|
(13) |
式中, K(zi·zj)=zi·zj为核函数。通过求解(13) 式中的优化问题, 获得相应的分类判别函数
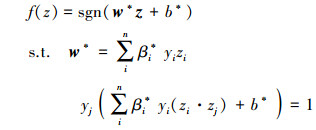
|
(14) |
w*为特征权向量, b*为分类阈值。
1.5 预测测试样本的类别标签对于未知类别的测试样本包B={x1, x2, …, xn}, 首先根据公式(6) 构造相应的包空间特征向量, 然后利用2.3节所构造的字典矩阵和稀疏系数矩阵对其进行线性表示, 即
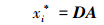
|
(15) |
式中, 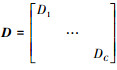
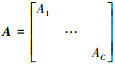
如果样本Bi属于第c类, 则样本包中存在示例x与第c类的字典Dc及稀疏系数Ac有关, 与其余类的系数及字典无关, 即, Ai=[0, …, 0, αc1, …, αcn, 0, …, 0]T, Di=[0, …, 0, dc1, …, αcn, 0, …, 0]T。
因此, 测试样本包Bi的特征向量zi, 在字典D上的稀疏线性组合, 可通过l1最小化求得, 即
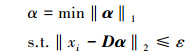
|
(16) |
对(16) 式进行约束, 可得
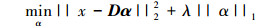
|
(17) |
获得稀疏系数αi后, 通过(10) 式得到测试包Bi的稀疏编码包级特征zi。并使用所训练的SVM对测试样本进行分类, 获得相应的类别标签。
2 算法步骤综上所述, 本文所提出的图像分类算法的具体步骤可描述为:
Step1 根据(6) 式计算包Bi的包特征向量, 获得每类训练包的包特征向量Tc, c=1, 2, …, C。
Step2 依据1.3节所述方法获得每类训练样本包的稀疏编码包级特征zc。并构造全部训练样本的稀疏编码包级特征z=[z1, z2, …, zC]。
Step3 利用所构造的包级特征训练相应的SVM分类器。
Step4 对测试包B应用公式(6) 计算其包特征向量, 并利用1.3节所构造的字典矩阵和稀疏系数矩阵对其进行线性表示, 获得相应的稀疏向量。
Step5 通过(10) 式获得测试包Bi的稀疏编码包级特征向量zi。
Step6 使用训练好的SVM分类器对测试样本进行分类, 获得相应的类别标签。
3 实验结果与分析为了评估本文所提出的分类方法的分类性能, 将该方法与其他多示例学习分类方法, 诸如MILES[10], MI-SVM[8], DD-SVM[9], MIGrahp[19]和miGrahp[19]进行对比, 实验数据选取多示例学习算法常用的COREL数据集。该数据集由20个不同类别的图像组成, 每类图像均含有100幅图像, 总共2 000幅, 大小为384*256、256*384。在实验过程中, 将每幅图像视为1个样本包, 按照文献[8]的方法, 将图像划分为若干个不重叠的图像块, 提取相应的特征, 使用K-means算法对特征向量进行聚类。每1个聚类区域对应分割图像的1个区域, 所有区域构成图像包中的示例, 其特征提取的具体过程参照文献[8]。对于每1类数据集, 随机选取50%的样本作为训练集, 另50%的数据作为测试集, 字典大小D=1 024, 规则项λ=0.01。
实验1 本文算法与其他多示例学习算法的对比
在此, 选择多示例学习分类算法的代表算法MIES, MI-SVM、DD-SVM、MIGrahp及miGrahp与本文算法进行对比。首先, 对COREL数据集的前10类图像组成的1 000幅图像进行测试, 然后对COREL数据集中所有20类图像组成的2 000幅图像进行实验, 其各种算法的平均分类正确率如表 1所示, 置信度区间设为95%。
| 算法 | 1 000-image | 2 000-Image |
| MILES | 0.826[0.814, 0.837] | 0.687[0.637, 0.701] |
| MI-SVM | 0.747[0.741, 0.753] | 0.546[0.531, 0.561] |
| DD-SVM | 0.815[0.785, 0.845] | 0.675[0.661, 0.689] |
| MIGrahp | 0.839[0.812, 0.857] | 0.721[0.710, 0.732] |
| miGrahp | 0.824[0.802, 0.826] | 0.705[0.687, 0.723] |
| 本文 | 0.847[0.84, 0.855] | 0.752[0.745, 0.76] |
从表 1可以看出, 本文分类算法在2组图像数据集上的分类正确率均高于其对比算法。本文分类算法的平均正确率在1 000-image图像集上较MILES, MI-SVM, DD-SVM, MIGrahp和miGrahp分别提高了2.1%、10%、3.2%、0.8%、2.3%。表 1表明, 本文算法在该数据集上的平均分类率达75.2%, 较MILES, MI-SVM, DD-SVM, MIGrahp和miGrahp分别提高了6.5%、20.6%、7.7%、3.1%、4.7%, 因此, 本文分类算法的分类性能优于其对比算法。
实验2 字典大小及训练样本数目对分类的影响
为了更好地分析字典大小与训练样本数目对本文算法分类性能的影响, 以COREL数据集中1 000-image图像的分类效果为例, 采用不同大小的字典对图像进行分类, 其平均分类正确率如表 2所示, 字典大小分别选取D=[256, 512, 1 024, 2 048, 4 096]。从实验结果可以看出, 字典大小对分类效果有一定的影响。当字典太小时, 由于包含有限的信息, 其分类正确率较低; 当字典太大时, 其包含大量冗余的信息, 算法分类精度并不随字典大小的增加而增加。当字典D=2 048时, 算法的分类精度仅比D=1 024时高0.3%。而当字典D=4 096时, 算法的分类正确率反而降低, 这是因为冗余的信息往往会造成分类器性能的下降。因此, 字典的大小对算法的分类性能有重要的影响。本文在实验过程中选取字典大小D=1 024。
表 3分析了训练样本数目对本文算法分类效果的影响。分别选取训练样本数目为30、50、70进行实验分析, 从实验结果可以看出, 随着训练样本数目的增加, 算法的分类正确率也在增加。当训练样本数目为50时, 分类精度比样本数为30时高8.2%, 比样本数为70时仅低1.8%。因此, 本文为了客观的与其他对比算法进行比较, 在实验过程中选取每类训练样本数目为50。
此外,为了更详细地分析本文算法的分类效果,表 4给出了本文算法在COREL数据集1 000-image图像上的分类混肴矩阵,其主对角线代表每1类的分类正确率,每1行除主对角线的其他值都表示该类的错分率,从表 4可以看出,本文算法在第3、4、6、7类上的分类正确率最高,均超过89%,在第1、2类上的正确率最低,但本文算法在该数据集上的分类正确率均高于70%,很好地说明了本文所提出的基于包级空间多示例稀疏编码的图像分类算法的有效性。
| 类别 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 0.76 | 0.2 | 0.04 | 0.03 | 0 | 0.05 | 0.02 | 0.03 | 0.03 | 0.02 |
| 1 | 0.01 | 0.71 | 0.04 | 0.05 | 0.01 | 0.07 | 0 | 0.01 | 0.09 | 0.01 |
| 2 | 0.04 | 0.05 | 0.7 | 0.03 | 0 | 0.05 | 0.04 | 0 | 0.07 | 0.02 |
| 3 | 0.01 | 0.01 | 0 | 0.92 | 0 | 0.01 | 0 | 0.02 | 0.03 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0.01 | 0.01 | 0.01 | 0.03 | 0 | 0.86 | 0 | 0.05 | 0.02 | 0.01 |
| 6 | 0.09 | 0 | 0 | 0 | 0 | 0 | 0.89 | 0.01 | 0 | 0.01 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0.01 | 0 | 0.95 | 0.01 | 0.03 |
| 8 | 0 | 0.06 | 0.02 | 0.03 | 0 | 0.02 | 0.03 | 0 | 0.8 | 0.04 |
| 9 | 0.08 | 0.01 | 0 | 0 | 0 | 0.04 | 0.07 | 0.01 | 0 | 0.79 |

|
| 图 2 本文算法在COREL图像集上的部分分类结果 |
为了有效地解决多示例图像分类问题,本文提出了1种融合稀疏编码理论及多示例学习框架的图像分类算法。该算法在特征选择过程中充分考虑了所有训练样本的信息,从每个训练样本包中选择相应的示例构造包级特征向量,并基于稀疏编码理论对训练包中的包特征向量进行稀疏编码,获得每1类训练样本的稀疏编码包特征向量。通过SVM分类器实现对测试样本类别标签的预测。在COREL数据集上的实验结果表明,本文分类算法的分类准确率高于其他基于多示例学习框架的分类算法。
| [1] | Pinz A. Object Categorization[J]. Foundations and Trends in Computer Graphics and Vision, 2005, 1(4): 255-353. DOI:10.1561/0600000003 |
| [2] | Dietterich T G, Lathrop R H, Lozano-Pérez T. Solving the Multiple Instance Problem with Axis-Parallel Rectangles[J]. Artificial Intelligence, 1997, 89(1/2): 31-71. |
| [3] | Zhou Z H, Zhang M L, Huang S J, et al. Multi-Instance Multi-Label Learning[J]. Artificial Intelligence, 2008, 176(1): 2291-2320. |
| [4] |
袁立明. 基于特征选择的嵌入空间多示例学习算法研究[D]. 哈尔滨: 哈尔滨工业大学, 2014: 2-11 Yuan Liming. Embedding Space Based Multiple Instance Learning Algorithms with Feature Selection[D]. Harbin Institute of Technology, 2014: 2-11 (in Chinese) http://cdmd.cnki.com.cn/Article/CDMD-10213-1014085088.htm |
| [5] | Amores J. Multiple Instance Classification: Review, Taxonomy and Comparative Study[J]. Artificial Intelligence, 2013, 201(4): 81-105. |
| [6] | Maron O, Lozano-Pérez T. A Framework for Multiple-Instance Learning[J]. Advances in Neural Information Processing Systems, 1998, 2000(2): 570-576. |
| [7] | Zhang Q, Goldman S A. EM-DD: An Improved Multiple-Instance Learning Technique[J]. Advances in Neural Information Processing Systems, 2002, 14: 1073-1080. |
| [8] | Andrews S, Hofmann T, Tsochantaridis I. Multiple Instance Learning with Generalized Support Vector Machines[C]//Eighteenth National Conference on Artificial Intelligence, 2002: 519-23 |
| [9] | Chen Y, Li J, Wang J Z. Categorization by Learning and Reasoning with Regions[M]. Springer US, 2004: 99-121. |
| [10] | Chen Y, Bi J, Wang J Z. MILES: Multiple-Instance Learning Via Embedded Instance Selection[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2006, 28(12): 1931-47. |
| [11] | Schölkopf B, Platt J, Hofmann T. Efficient Sparse Coding Algorithms[C]//NIPS, 2007: 801-808 |
| [12] |
宋相法, 焦李成. 基于稀疏编码和集成学习的多示例多标记图像分类方法[J]. 电子与信息学报, 2013(3): 622-626.
Song Xiangfa, Jiao Licheng. A Multi-Instance Multi-Label Image Classification Method Based on Sparse Coding and Ensemble Learning[J]. Journal of electronics & information technology, 2013(3): 622-626. (in Chinese) |
| [13] | Yang J, Yu K, Gong Y, et al. Linear Spatial Pyramid Matching Using Sparse Coding for Image Classification[C]//2014: 1794-1801 |
| [14] | Foulds J, Frank E. Revisiting Multiple-Instance Learning Via Embedded Instance Selection[C]//2008: 300-310 |
| [15] | Fu Z, Robles-Kelly A, Zhou J. MILIS: Multiple Instance Learning with Instance Selection[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2011, 33(5): 958-77. |
| [16] | Li W J, Yeung D Y. MILD: Multiple-Instance Learning via Disambiguation[J]. IEEE Trans on Knowledge & Data Engineering, 2009, 22(1): 76-89. |
| [17] | Tibshirani R. Regression Shrinkage and Selection via the Lasso[J]. J of the Royal Statistical Society, 1996, 58(1): 267-288. |
| [18] | Chang C C, Lin C J. LIBSVM: A Library for Support Vector Machines[J]. Acm Trans on Intelligent Systems & Technology, 2011, 2(3): 389-396. |
| [19] | Zhou Z H, Sun Y Y, Li Y F, Multi-Instance Learning by Treating Instances as Non-i.i.d. Samples[C]//International Conference on Machine Learning, 2009: 1249–1256 |
