

现有的水声目标识别方法主要是利用先验知识和专家知识对目标进行特征提取和训练分类器。由于特定水声目标 (如各类潜艇、鱼雷等) 的数据获取困难、代价巨大, 现有的水声目标识别方法大多建立在对少量有类标数据学习的基础上, 是小样本识别问题[1], 这些因素在一定程度上制约了现有方法的准确性和泛化性。因此, 从水声目标辐射噪声中挖掘出目标的固有特性和变化规律, 提取有效辐射噪声特征, 构建水下目标识别系统, 提高水声目标识别系统的准确性、抗噪性和鲁棒性仍然是急需解决的问题。
深度学习是一种利用非线性信息处理技术实现多层次、有监督或无监督的特征提取和转换, 并进行模式分析和分类的机器学习理论和方法。利用深度学习理论可以打破现有水声目标识别方法依赖大量先验知识和专家知识进行特征提取和训练分类器的固定模式, 直接从原始信号中自动学习、定义和揭示潜在的类别信息, 消除噪声影响, 从数据中自学习蕴含丰富类别信息的特征, 并在学习特征的同时自适应构建决策分类系统[2-4]。
深度置信网络 (deep belief network, DBN) 是一种典型的深度学习模型, 但是仍面临一些问题。DBN的基础模型受限玻尔兹曼机 (restricted Boltzmann machine, RBM) 在学习过程中存在隐含单元相关性强的问题, 使得学习到的特征相似导致冗余[5-6]。而且训练深度网络属于非凸优化问题, 特别是在水声目标小样本学习情况下, 复杂的网络参数给学习带来了困难[7]。针对上述问题, 本文提出了基于混合正则化深度置信网络 (hybrid regularization deep belief network, HR-DBN) 的水声目标深度特征学习及识别方法。第一种正则化策略针对RBM隐含单元的强相关性, 利用最大互信息组正则化机制对RBM的目标函数进行修正, 提高隐含层的稀疏度; 第二种正则化策略针对深度网络参数搜索困难的问题, 利用大量无类标样本进行网络预训练, 获得先验知识引导特征学习。最后利用少量有类标样本对网络进行全局优化, 构建识别系统。采用实测舰船辐射噪声数据实验表明, 提出的方法可以改善RBM隐含单元相关性强的问题, 同时利用大量无类标样本, 提取水声目标深度增强特征并提高水声目标识别性能。
1 HR-DBN水声目标特征学习和识别模型DBN采用多个RBM级联的方式逐层贪婪训练, 再利用反向传播算法进行微调, 从而得到特征学习和识别模型。
在水声目标有类标样本数量有限的条件下, 针对RBM隐含单元的强相关性和深度网络参数搜索困难的问题, 提出融合了最大互信息组正则化与无监督预训练数据驱动正则化的HR-DBN, 结构如图 1所示。该模型不仅能实现单层RBM隐含单元的稀疏惩罚, 同时在无监督地逐层贪婪训练过程中实现参数的全局优化, 从而实现水声数据多层特征的稀疏表达和目标分类。

|
| 图 1 HR-DBN特征学习和识别模型 |
RBM学习到的特征间通常存在强的统计相关性, 然而对目标函数添加稀疏惩罚通常假设特征之间相互独立[5]。为解决这个问题, 根据互信息衡量隐含单元之间的统计相关性, 提出最大互信息隐含单元分组策略, 然后加入L1/L2混合范数正则化项, 作为惩罚机制训练RBM。算法流程如图 2所示:

|
| 图 2 最大互信息组正则化RBM训练流程 |
RBM是一个2层概率图模型, 其中可见层v=(v1, v2, …, vn)T表示观测数据, 隐含层h=(h1, h2, …, hm)T表示学习到的特征, 层内无连接, 层间全连接。为了处理实值的水声数据, 引入包含二值隐含单元和含高斯噪声的线性可见单元的高斯伯努利受限玻尔兹曼机 (Gaussian-Bernoulli RBM, GB-RBM), GB-RBM通过如下能量函数进行定义[8]
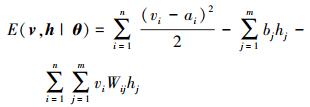
|
(1) |
式中,θ={Wij, ai, bj}, Wij表示可见单元i和隐含单元j的连接权重, ai和bj分别表示其偏置, n和m分别表示可见单元数和隐含单元数。
已知可见层时, 隐含层的条件概率为
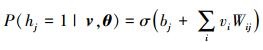
|
(2) |
式中,σ(x)=1/(1+e-x), 类似地, 已知隐含层时, 可见层的条件概率为
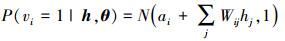
|
(3) |
式中,N (μ, V) 是均值为μ方差为V的高斯分布。利用极大似然估计方法得出参数更新式为
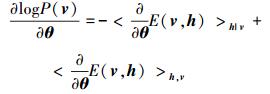
|
(4) |
式中,<·>表示期望, 利用对比散度算法近似计算梯度来有效近似期望值。无监督训练RBM旨在增加训练数据在RBM所定义的分布的似然度, 降低模型在训练数据处的能量, 从而挖掘数据的内在分布特性。给定训练数据, RBM中的隐含单元的激活概率条件独立, 因此所有的隐含单元均会独立地表示训练数据, RBM部分的隐含单元会学习到类似的特征, 导致冗余。因此我们根据隐含单元之间的统计相关性加入稀疏惩罚, 避免多数隐含单元学习到相似的特征。
1.1.2 最大互信息分组策略互信息提供了直接度量隐含单元相关性的方法。2个变量间的互信息是已知一个变量情况下, 另一个变量不确定性的减少量[9-10]。可以使用KL散度进行定义, 如公式 (5) 所示

|
(5) |
KL[p||q]是2个概率分布函数p和q的KL距离, 对于离散随机变量

|
(6) |
分组策略如表 1所示。
使用无监督的方法训练完GB-RBM以后, 根据隐含单元间的互信息, 将隐含单元及其对应的权重和偏置进行分组。将第1个隐含单元作为第1组, 选择与该组隐含单元平均互信息最大的隐含单元, 合并为1组, 当该组隐含单元数目达到规定值时, 进行下一组分组, 如此循环, 直到全部隐含单元均实现分组。
1.1.3 RBM的正则化利用互信息将隐含单元分为K组, 其中第k组记做Gk, 引入L1/L2范数的对数概率为
|
(7) |
式中,λ为正则化系数
|
(8) |
为L1/L2范数。已知观测数据v和重构数据v′, 对应隐含单元j的权重W·j和偏置Δb·j的更新梯度为
|
(9) |
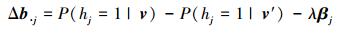
|
(10) |
式中
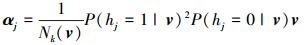
|
(11) |
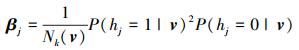
|
(12) |
该正则化方法通过考虑隐含单元的统计相关性, 使得同一个组内的隐含单元互相竞争, 从而限制大部分隐含单元的激活程度, 实现隐含层的对数据的稀疏表达[5-7]。
1.2 DBN数据驱动正则化策略训练深度网络属于非凸优化问题, 存在大量局部极小点, 只采用有类标样本进行有监督训练深度网络, 当网络层数较深时, 不同的参数初始化方式将使得梯度算法收敛到不同的局部极小点, 尤其在有类标训练样本数量有限的情况下, 训练算法很难搜索到最优参数空间。同时大量未知类别的舰船辐射噪声包含与目标舰船辐射噪声类似的基本模式。因此我们在使用深度网络对水声目标进行有监督分类任务前, 利用大量的无类标数据进行逐层贪婪训练无监督预训练, 获得有关水声目标的普遍特性的描述和先验知识, 引导特征学习, 从而解决水声目标小样本识别的问题。该无监督预训练过程可认为是一种特殊的数据驱动的正则化机制, 帮助优化训练准则, 使网络学习到更好的特征[11]。
假设有界参数空间为S⊂Rd, 将S划分为k个区域, 分别记做Rk。有∪kRk=S, 且对任意i≠j, Ri∩Rj=ø。使用vk=∫1θ∈Rkdθ表示区域Rk的体积。rk表示随机使用初始化网络的方法使得参数收敛到Rk区域的概率, πk表示使用无监督预训练的方法使得网络参数收敛到Rk区域的概率。且有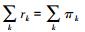
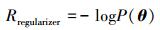
|
(13) |
无监督预训练相当于在参数空间外部施加了一个特殊的惩罚, 通过无监督学习获得由数据驱动的参数θ的先验概率, 对于预训练的模型该先验概率为

|
(14) |
对于未使用预训练的随机初始化模型, 先验概率为
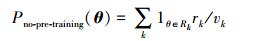
|
(15) |
容易验证Ppre-training(θ∈Rk)=πk, Pno-pre-training(θ∈Rk)=rk; 使用无监督预训练的方法初始化参数, 当πk很小且θ∈Rk时, 则惩罚很大。将无监督预训练后的参数空间视为隐式地约束函数, 由于指定了目标函数期望达到的极小点, 从而跳出大量的局部极小点, 使得有监督随机梯度下降可以顺利搜索到全局最优参数。不同于传统的正则化方法使用范数对权重和偏置进行惩罚, 采用无监督预训练的方法假设目标数据的条件分布与输入数据的分布结构共享, 是一种由数据驱动的正则化方法[12-13]。
2 实验和讨论 2.1 实验数据和方法为了验证所提出的HR-DBN方法针对水声目标小样本识别问题的有效性, 本文使用实测水声数据进行实验验证。实验数据包括无类标样本和有类标样本。其中无类标样本数共25 063, 包含海洋背景噪声样本数6 954, 未知类别的舰船辐射噪声数据样本数18 109。有类标样本包含2类船辐射噪声数据样本数1 000, 第1类目标数据样本数500, 第2类目标数据样本数500, 其中每类随机选择70%作为训练数据, 其数30%作为测试数据。
为了验证所提出的HR-DBN方法的优越性, 本文采用BP网络和DBN进行对比实验。在实验设置中, BP网络使用少量有类标样本进行训练, 且未使用任何正则化方法。DBN首先使用大量无类标样本进行预训练, 然后使用少量有类标样本进行微调, 即仅使用数据驱动正则化方法。而HR-DBN使用本文提出的混合的正则化策略。
2.2 特征可视化构建包含3个隐含层的HR-DBN, 隐含单元个数分别为100-50-20, 利用混合正则化方法无监督训练网络后, 将参数作为BP网络的初始化参数, 使用有类标样本进行有监督微调, 第3层隐含单元的箱线图如图 3所示。构建相同结构的BP网络, 随机初始化网络参数, 第3层隐含单元的箱线图如图 4所示。对比可知, HR-DBN学习到的特征使得2类目标的可分性更强。

|
| 图 3 HR-DBN隐含单元箱线图 |

|
| 图 4 BP网络隐含单元箱线图 |
分别在二维平面使用t-SNE方法[14]可视化图 3和图 4对应的特征, 如图 5和图 6所示, t-SNE采用梯度下降算法, 通过最小化原始高维数据与低维重构数据之间的KL距离, 实现高维数据的可视化。

|
| 图 5 HR-DBN特征散点图 |

|
| 图 6 BP网络特征散点图 |
相比图 5、图 6,图 6中2类样本分别聚集在不同的区域, 说明相比BP网络, HR-DBN学习到的特征能有效区分2类样本。
2.3 识别实验分别使用随机初始化的BP网络, 有类标样本预训练的DBN、HR-DBN 3种方式构建1~3层的网络进行识别实验。其中每层隐含单元数均为100, 学习率为0.1, 预训练学习率为0.01, HR-DBN的正则化系数为0.1。识别正确率如表 2所示, 当包含一个隐含层时, 随机初始化参数的BP网络可以得到最高的识别正确率, 但是随着网络层数的加深, 识别正确率几乎保持不变, 甚至下降。使用DBN和HR-DBN, 均使得随着网络层数的加深, 识别正确率逐渐提高。对比BP网络与DBN的实验结果, 当网络层数较深时, 使用大量的无类标样本对网络进行预训练能较大地提高识别正确率, 从而解决水声目标小样本识别的问题。对比DBN与HR-DBN的实验结果, 本文提出的混合正则化策略能有效提高深度网络的识别正确率, 得到更好的识别结果。
| 隐含层数 | 识别正确率 | ||
| BP网络 | DBN | HR-DBN | |
| 1层 | 0.782 | 0.776 | 0.781 |
| 2层 | 0.796 | 0.793 | 0.805 |
| 3层 | 0.789 | 0.845 | 0.868 |
本文提出融合了最大互信息组正则化与深度网络无监督预训练的混合正则化方法, 通过互信息衡量隐含单元的相关性引入稀疏惩罚参数, 从而实现隐含单元对输入数据的稀疏表达。通过大量无类标数据预训练初始化深度网络, 在参数空间外部施加特殊惩罚, 获得由数据驱动的参数的先验概率, 使得有监督随机梯度下降可以顺利搜索到全局最优参数。实验表明应用该混合正则化方法训练的深度置信网络能够有效实现水声数据多层特征的稀疏表达, 相比随机初始化参数的BP网络与DBN有更高的识别正确率。
| [1] |
杨宏晖, 孙进才, 袁骏.
基于支持向量机和遗传算法的水下目标特征选择算法[J]. 西北工业大学学报, 2005, 23 (4): 512–515.
Yang Honghui, Sun Jincai, Yuan Jun. A New Method for Feature Selection for Underwater Acoustic Targets[J]. Journal of Northwestern Polytechnical University, 2005, 23(4): 512–515. (in Chinese) |
| [2] |
杨宏晖, 申昇.
模式识别之特征选择[M]. 北京: 电子工业出版社, 2016.
Yang Honghui, Shen Sheng. The Feature Selection of Pattern Recognition[M]. Beijing: Publishing House of Electronics Industry, 2016. (in Chinese) |
| [3] | LeCun Y, Bengio Y, Hinton G E. Deep Learning[J]. Nature, 2015, 521(7553): 436–444. DOI:10.1038/nature14539 |
| [4] | Schmidhuber J. Deep Learning in Neural Networks: An Overview[J]. Neural Networks, 2015, 61: 85–117. DOI:10.1016/j.neunet.2014.09.003 |
| [5] | Luo H, Shen R, Niu C. Sparse Group Restricted Boltzmann Machines[C]//AAAI Conference on Artificial Intelligence 2011. Sam Francisco, USA, 2010 |
| [6] |
刘凯, 张立民, 张超.
受限玻尔兹曼机的新混合稀疏惩罚机制[J]. 浙江大学学报 (工学版), 2015, 49 (6): 1070–1078.
Liu Kai, Zhang Limin, Zhang Chao. New Hybrid Sparse Penalty Mechanism of Restricted Boltzmann Machine[J]. Journal of Zhejiang University, 2015, 49(6): 1070–1078. (in Chinese) |
| [7] | Shen Sheng, Yang Honghui, Yao Xiaohui, et al. Learning Robust Features from Underwater Ship-Radiated Noise with Mutual Information Group Sparse DBN[C]//International Congress and Exposition on Noise Control Engineering, Hamburg Germany, 2016 |
| [8] | Hinton G E. A Practical Guide to Training Restricted Boltzmann Machines (Version 1)[J]. Momentum, 2010, 9(1): 599–619. |
| [9] |
申昇, 杨宏晖, 王芸, 等. 联合互信息水下目标特征选择算法[J]. 西北工业大学学报, 2015, 33(4): 639-643
Shen Sheng, Yang Honghui, Wang Yun, et al. Joint Mutual Information Feature Selection for Underwater Acoustic Targets[J]. 2015, 33(4):639-643 (in Chinese) |
| [10] | Cover T M, Thomas J A. Elements of Information Theory[M]. Hoboken: New Jersey Wiley-Interscience, 2006. |
| [11] | Raina R, Battle A, Lee H, et al. Self-Taught Learning: Transfer Learning from Unlabeled Data[C]//International Conference on Machine Learning Corvalli, USA, 2007:759-766 |
| [12] | Erhan D, Bengio Y, Courville A, et al. Why Does Unsupervised Pre-Training Help Deep Learning?[J]. Journal of Machine Learning Research, 2010, 11(3): 625–660. |
| [13] | Erhan D, Manzagol P A, Bengio Y, et al. The Difficulty of Training Deep Architectures and the Effect of Unsupervised Pre-Training[C]//AISTATSm, Cleanwater Beach, USA, 2009 |
| [14] | Laurens V D M, Hinton G. Visualizing Data using T-SNE[J]. Journal of Machine Learning Research, 2008, 9(11): 2579–2605. |
